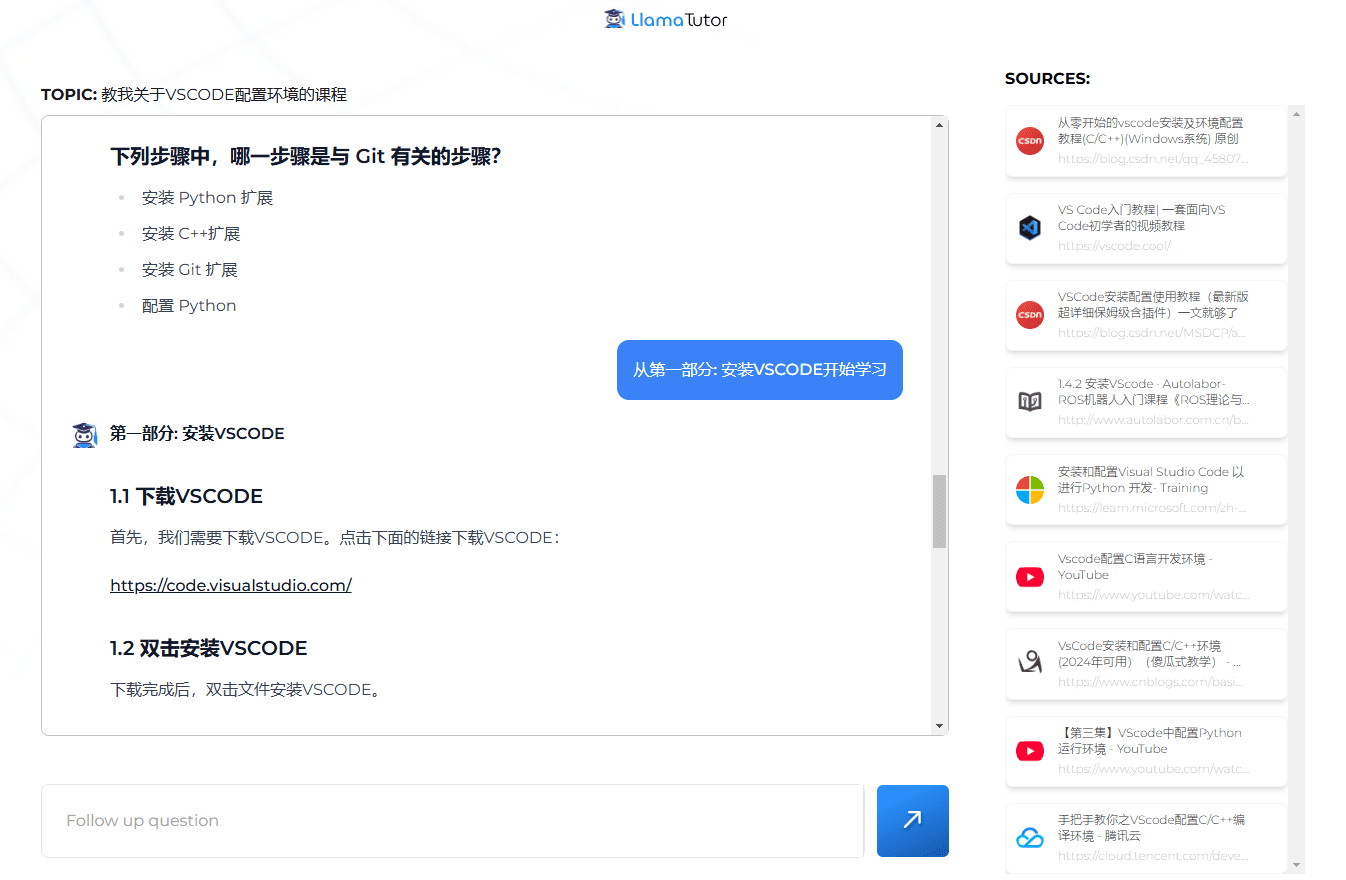

综合介绍
MegaPairs 是 VectorSpaceLab 团队在 GitHub 上开源的项目,通过大规模数据合成技术生成多模态嵌入模型,用于图像-文本到图像的检索任务。项目基于超过2600万个异构 KNN 三元组数据集,训练了 BGE-VL 系列模型,包括 BGE-VL-CLIP(base 和 large 版本)和 BGE-VL-MLLM(S1 和 S2 版本)。其中,BGE-VL-MLLM-S1 在 CIRCO 零样本图像检索基准上提升了 8.1% 的性能(mAP@5),在 MMEB 多模态嵌入基准中也表现出色。代码和模型已开源于 GitHub 和 Hugging Face,数据集计划后续发布,采用 MIT 许可证,数据源自 Recap-Datacomp(CC BY 4.0 许可)。

功能列表
- 生成大规模数据集: 提供超过2600万个异构 KNN 三元组,用于训练多模态嵌入模型。
- BGE-VL-CLIP 嵌入模型: 包括 base 和 large 版本,生成图像和文本的嵌入表示,支持高效检索。
- BGE-VL-MLLM 嵌入模型: 提供 S1 和 S2 版本,生成高性能多模态嵌入,支持零样本检索。
- 支持零样本检索: 无需训练即可生成嵌入并完成图像-文本检索任务。
- 模型开源与扩展: 在 Hugging Face 提供预训练模型,支持下载、使用和微调。
使用帮助
MegaPairs 通过 GitHub 和 Hugging Face 分发代码和模型,用户可以快速生成多模态嵌入并完成检索任务。以下是详细操作指南,基于 BGE-VL-MLLM-S1 的官方说明(Hugging Face)。
获取与安装
- 访问 GitHub 仓库: 打开
https://github.com/VectorSpaceLab/MegaPairs,查看项目详情。 - 克隆仓库: 在终端运行以下命令下载代码:
git clone https://github.com/VectorSpaceLab/MegaPairs.git
cd MegaPairs
- 安装依赖: 使用 Python 3.10,创建虚拟环境并安装必要库:
python -m venv venv
source venv/bin/activate # Linux/Mac
venv\Scripts\activate # Windows
pip install torch transformers==4.41.2 sentencepiece
Hugging Face 要求 transformers==4.41.2 和 sentencepiece。
4. 下载模型: 从 Hugging Face 获取 BGE-VL-MLLM-S1:
- 访问 https://huggingface.co/BAAI/BGE-VL-MLLM-S1
- 通过 Python 脚本自动下载(见下文)。
使用主要功能
1. 数据集使用
MegaPairs 数据集包含 2600 万个三元组,用于训练多模态嵌入模型,目前尚未完全发布,计划通过 Hugging Face 提供。
- 获取方式: 关注官方更新,下载后可用于模型训练或验证。
- 数据格式: 三元组(查询图像、文本描述、目标图像),支持嵌入生成和检索。
2. 生成多模态嵌入(BGE-VL-MLLM-S1)
BGE-VL-MLLM-S1 是核心嵌入模型,用于生成图像和文本的嵌入表示并完成检索。以下是官方代码:
- 加载模型:
import torch
from transformers import AutoModel, AutoProcessor
model_name = "BAAI/BGE-VL-MLLM-S1"
processor = AutoProcessor.from_pretrained(model_name, trust_remote_code=True)
model = AutoModel.from_pretrained(model_name, trust_remote_code=True)
model.eval()
model.cuda() # 使用 GPU 加速
- 生成嵌入并检索:
from PIL import Image # 准备输入 query_image = Image.open("./cir_query.png").convert("RGB") query_text = "Make the background dark, as if the camera has taken the photo at night" candidate_images = [Image.open("./cir_candi_1.png").convert("RGB"), Image.open("./cir_candi_2.png").convert("RGB")] # 处理查询数据 query_inputs = processor( text=query_text, images=query_image, task_instruction="Retrieve the target image that best meets the combined criteria by using both the provided image and the image retrieval instructions: ", return_tensors="pt", q_or_c="q" ) query_inputs = {k: v.cuda() for k, v in query_inputs.items()} # 处理候选数据 candidate_inputs = processor( images=candidate_images, return_tensors="pt", q_or_c="c" ) candidate_inputs = {k: v.cuda() for k, v in candidate_inputs.items()} # 生成嵌入并计算相似度 with torch.no_grad(): query_embs = model(**query_inputs, output_hidden_states=True).hidden_states[-1][:, -1, :] candi_embs = model(**candidate_inputs, output_hidden_states=True).hidden_states[-1][:, -1, :] query_embs = torch.nn.functional.normalize(query_embs, dim=-1) candi_embs = torch.nn.functional.normalize(candi_embs, dim=-1) scores = torch.matmul(query_embs, candi_embs.T) print(scores) # 输出相似度得分- 结果解释:
scores表示查询嵌入与候选嵌入的相似度,得分越高匹配度越高。
- 结果解释:
3. 使用 BGE-VL-CLIP 生成嵌入
BGE-VL-CLIP(base/large)也可生成多模态嵌入:
- 加载与运行:
from transformers import AutoModel model_name = "BAAI/BGE-VL-base" model = AutoModel.from_pretrained(model_name, trust_remote_code=True) model.set_processor(model_name) model.eval() with torch.no_grad(): query = model.encode(images="./cir_query.png", text="Make the background dark") candidates = model.encode(images=["./cir_candi_1.png", "./cir_candi_2.png"]) scores = query @ candidates.T print(scores)
4. 模型微调
用户可利用数据集微调模型:
- 数据准备: 准备图像-文本对或三元组。
- 微调流程: 微调代码待发布,可参考
transformers的TrainerAPI。 - 验证: 使用 CIRCO 或 MMEB 基准测试效果。
特色功能操作
零样本嵌入生成与检索
BGE-VL-MLLM-S1 支持零样本操作:
- 输入图像和文本,生成嵌入后直接检索,无需训练。
- 在 CIRCO 上提升 8.1% 的 mAP@5。
高性能与可扩展性
- 性能: 在 MMEB 上生成优异的多模态嵌入,S2 版本进一步优化。
- 扩展性: 数据量增加时嵌入质量提升,50 万样本已超越传统模型。
注意事项
- 硬件要求: 推荐 GPU(16GB 显存以上)。
- 依赖版本: 使用
transformers==4.41.2和sentencepiece。 - 文档支持: 查看 GitHub 和 Hugging Face 页面。
- 社区帮助: 在 GitHub Issues 或 Hugging Face Discussions 中提问。
通过以上步骤,用户可以生成多模态嵌入并完成检索任务。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章



暂无评论...