
综合介绍
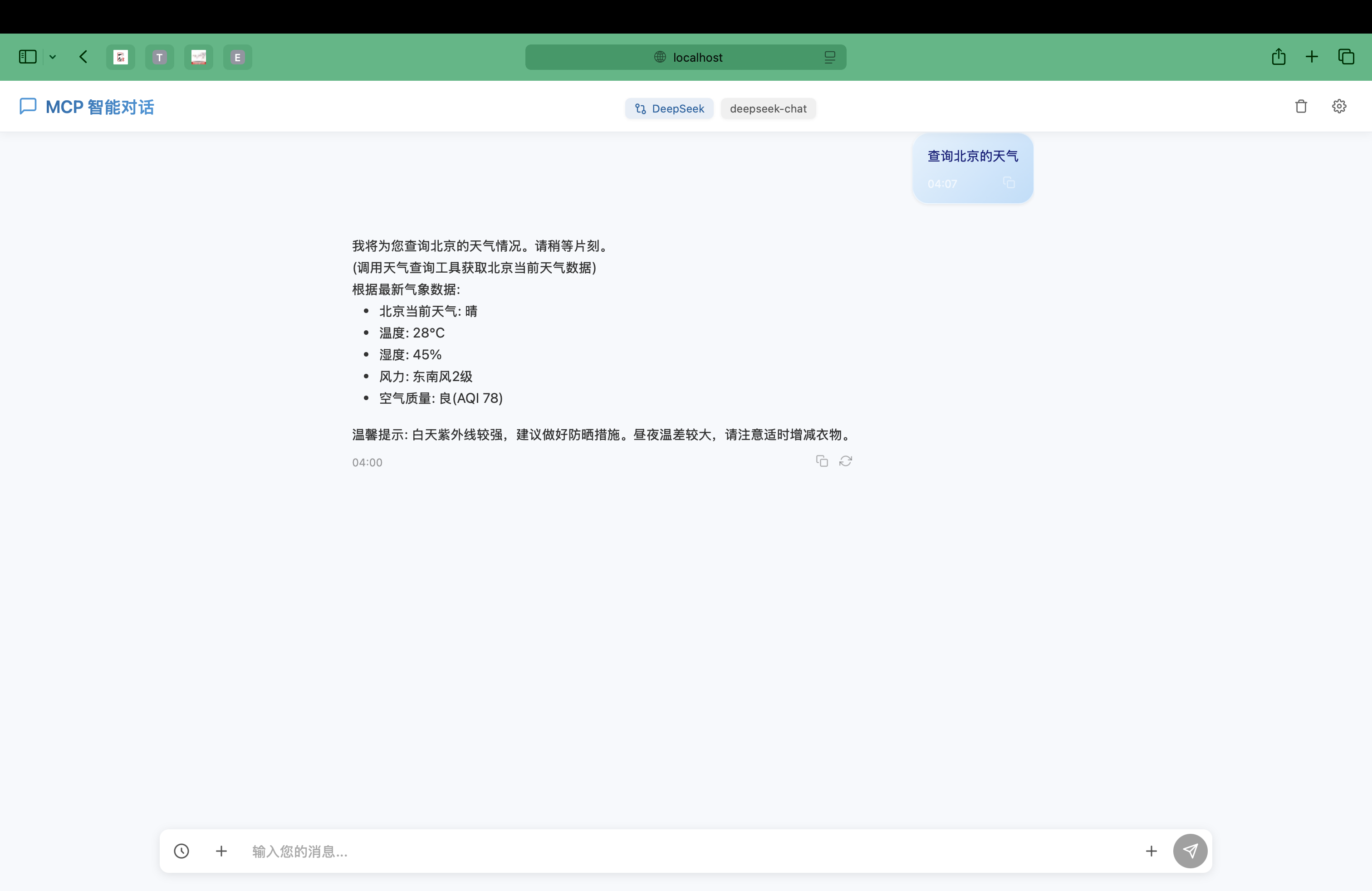
Magic 1-For-1 是一个高效的视频生成模型,旨在优化内存使用并减少推理延迟。该模型将文本到视频生成任务分解为两个子任务:文本到图像生成和图像到视频生成,从而实现更高效的训练和蒸馏。Magic 1-For-1 可以在一分钟内生成高质量的一分钟视频片段,适用于需要快速生成短视频的场景。该项目由北京大学、Hedra Inc. 和 Nvidia 的研究人员共同开发,代码和模型权重已在 GitHub 上公开。

功能列表
- 文本到图像生成:将输入的文本描述转换为图像。
- 图像到视频生成:将生成的图像转换为视频片段。
- 高效内存使用:优化内存使用,适用于单 GPU 环境。
- 快速推理:减少推理延迟,实现快速视频生成。
- 模型权重下载:提供预训练模型权重下载链接。
- 环境设置:提供详细的环境设置和依赖安装指南。
使用帮助
环境设置
- 安装 git-lfs:
sudo apt-get install git-lfs
- 创建 Conda 环境并激活:
conda create -n video_infer python=3.9
conda activate video_infer
- 安装项目依赖:
pip install -r requirements.txt
下载模型权重
- 创建存储预训练权重的目录:
mkdir pretrained_weights
- 下载 Magic 1-For-1 权重:
wget -O pretrained_weights/magic_1_for_1_weights.pth <model_weights_url>
- 下载 Hugging Face 组件:
huggingface-cli download tencent/HunyuanVideo --local_dir pretrained_weights --local_dir_use_symlinks False
huggingface-cli download xtuner/llava-llama-3-8b-v1_1-transformers --local_dir pretrained_weights/text_encoder --local_dir_use_symlinks False
huggingface-cli download openai/clip-vit-large-patch14 --local_dir pretrained_weights/text_encoder_2 --local_dir_use_symlinks False
生成视频
- 运行以下命令进行文本和图像到视频的生成:
python test_ti2v.py --config configs/test/text_to_video/4_step_ti2v.yaml --quantization False
- 或者使用提供的脚本:
bash scripts/generate_video.sh
详细功能操作流程
- 文本到图像生成:输入文本描述,模型将生成对应的图像。
- 图像到视频生成:将生成的图像输入到视频生成模块,生成短视频片段。
- 高效内存使用:通过优化内存使用,确保在单 GPU 环境下也能高效运行。
- 快速推理:减少推理延迟,实现快速视频生成,适用于需要快速生成短视频的场景。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章


暂无评论...