

评估大模型在真实世界、长文本、多任务中的「深度理解与推理」能力
近年来,长文本大语言模型的研究取得了显著进展,模型的上下文窗口长度已经从最初的 8k 扩展到 128k 甚至 1M 个 tokens。然而,一个关键的问题仍然存在:这些模型是否真正理解了它们所处理的长文本?换句话说,它们是否能够基于长文本中的信息进行深入的理解、学习和推理?
为了回答这个问题,并推动长文本模型在深度理解与推理上的进步,清华大学和智谱的研究团队推出了 LongBench v2,一个专为评估 LLMs 在真实世界长文本多任务中的深度理解和推理能力而设计的基准测试。
我们相信LongBench v2将推动探索scaling inference-time compute(例如 o1 模型)如何帮助解决长文本场景中的深度理解和推理问题。
特点
LongBench v2 相比于现有的长文本理解基准测试,具有以下几个显著特点:
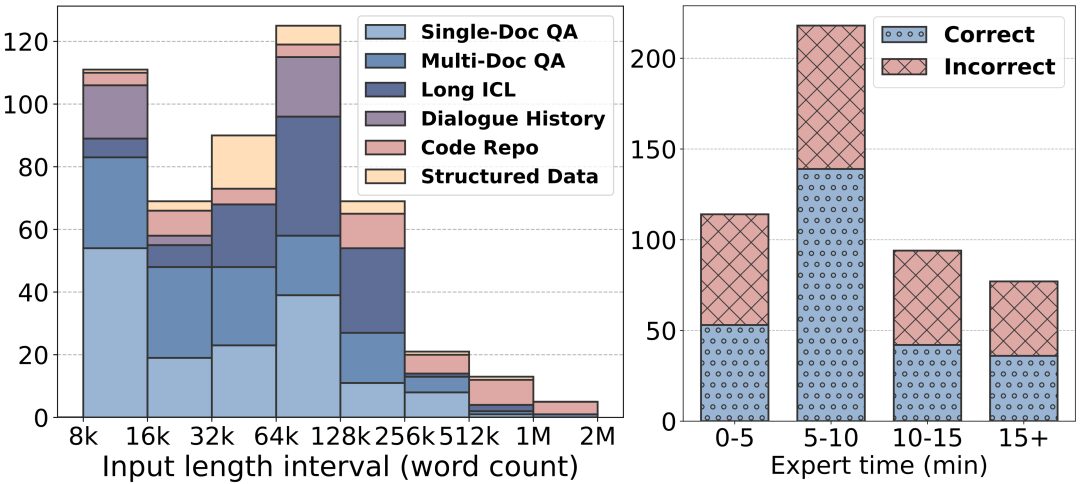
更长的文本长度: LongBench v2 的文本长度范围从 8k 到 2M 个词,其中大多数文本的长度小于 128k。
更高的难度: LongBench v2 包含了 503 个具有挑战性的四选一选择题——即使是使用文档内搜索工具的人类专家,也很难在短时间内正确回答这些问题。人类专家在 15 分钟的时间限制下,平均准确率仅为 53.7%(随机的准确率为25%)。
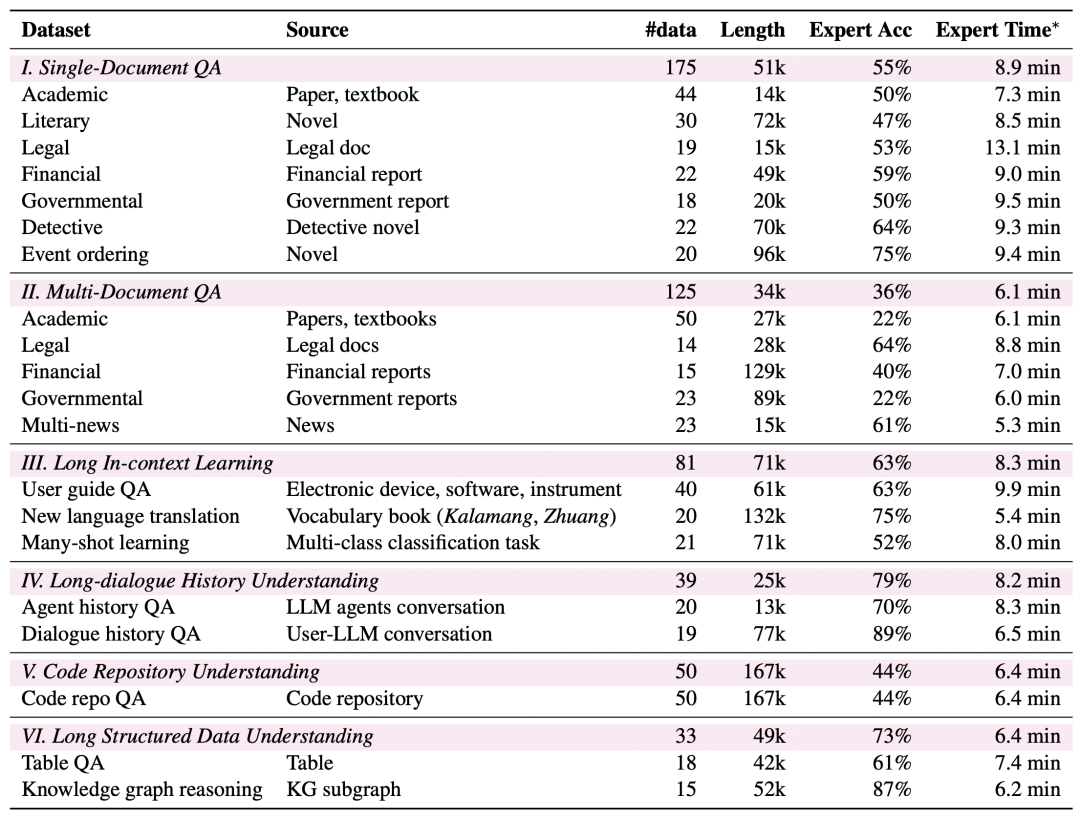
更广泛的任务覆盖: LongBench v2 涵盖了六个主要的任务类别,包括单文档问答、多文档问答、长文本语境学习、长对话历史理解、代码仓库理解和长结构化数据理解,共计 20 个子任务,覆盖了各种现实场景。
更高的可靠性: 为了保证评估的可靠性,LongBench v2 的所有问题都采用多项选择题的形式,并经过了严格的人工标注和审核流程,确保数据的高质量。
数据收集流程
为了确保数据的质量和难度,LongBench v2 采用了严格的数据收集流程,主要包括以下几个步骤:
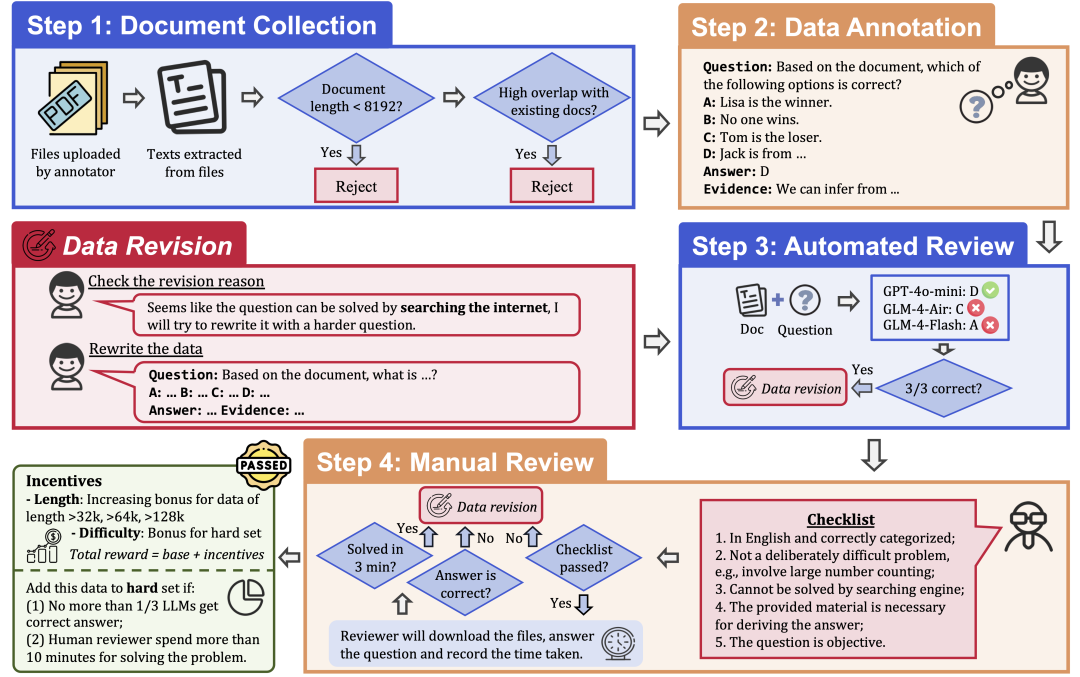
文档收集: 招募 97 名来自顶尖大学、具有不同学术背景和年级的标注员,收集他们个人阅读或使用过的长文档,例如研究论文、教科书、小说等。
数据标注: 标注员根据收集到的文档,提出一个多项选择题,并提供四个选项、一个正确答案和相应的证据。
自动审核: 使用三个具有 128k 上下文窗口的 LLMs(GPT-4o-mini、GLM-4-Air 和 GLM-4-Flash)对标注的数据进行自动审核,如果三个模型都能正确回答问题,则认为该问题过于简单,需要重新标注。
人工审核: 通过自动审核的数据会被分配给 24 位专业的人类专家进行人工审核,他们会尝试回答问题,并判断问题是否合适、答案是否正确。如果专家在 3 分钟内能够正确回答问题,则认为该问题过于简单,需要重新标注。此外,如果专家认为问题本身不符合要求或答案有误,也会退回重新标注。
数据修订: 未通过审核的数据会被退回给标注员进行修订,直到通过所有审核步骤。
评估结果
研究团队使用 LongBench v2 评估了 10 个开源 LLMs 和 6 个闭源 LLMs。评估中考虑两种场景:zero-shot与zero-shot+CoT(即先让模型输出chain-of-thought,再让模型输出所选答案)。
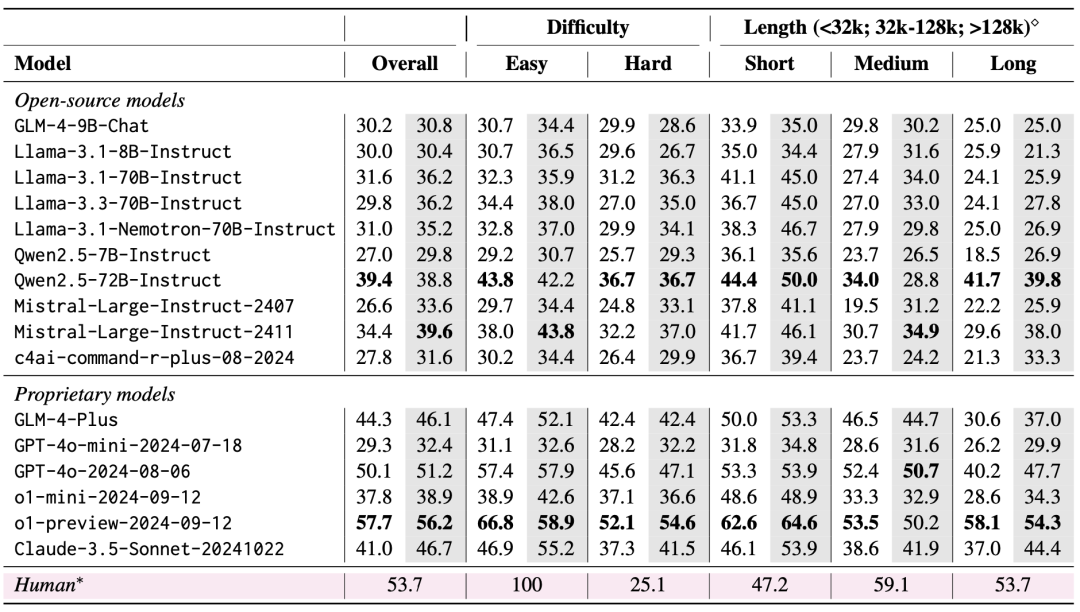
评估结果表明,LongBench v2 对当前的 LLMs 来说是一个巨大的挑战,即使是表现最好的模型,在直接输出答案的情况下,也仅取得了 50.1% 的准确率,而引入了更长推理链的 o1-preview 模型则取得了 57.7% 的准确率,超过了人类专家 4%。
1、Scaling Inference-Time Compute 的重要性
评估结果中一个非常重要的发现是,通过扩展推理时间计算(Scaling Inference-Time Compute),可以显著提升模型在 LongBench v2 上的表现。例如,o1-preview 模型相比于 GPT-4o,通过集成更多推理步骤,在多文档问答、长文本语境学习和代码仓库理解等任务上取得了显著的提升。
这表明,LongBench v2 对当前模型的推理能力提出了更高的要求,而增加推理时间的思考和推理似乎是解决此类长文本推理挑战的一个自然且关键的步骤。
2、RAG + Long-context实验

实验发现,Qwen2.5 和 GLM-4-Plus 两个模型在检索块数量超过一定阈值(32k tokens,约 64 个 512 长度的块)后,性能并没有显著提升,甚至出现下降的情况。
这表明简单地增加检索到的信息量并不总能带来性能的提升。相比之下,GPT-4o 能够有效利用更长的检索上下文,其最佳 RAG 性能出现在 128k 检索长度时。
总结来说,在面对需要深度理解和推理的长文本问答任务时,RAG的作用有限,特别是当检索块数量超过一定阈值后。模型需要具备更强的推理能力,而不仅仅是依赖检索到的信息,才能有效处理 LongBench v2 中的挑战性问题。
这也暗示了未来的研究方向也需要更多地关注如何提升模型自身的长文本理解和推理能力,而不仅仅是依赖外部检索。
我们期待 LongBench v2 能够推动长文本理解和推理技术的发展。欢迎阅读我们的论文,使用我们的数据并了解更多!
主页:https://longbench2.github.io
论文:https://arxiv.org/abs/2412.15204
数据与代码:https://github.com/THUDM/LongBench
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章




暂无评论...