
综合介绍
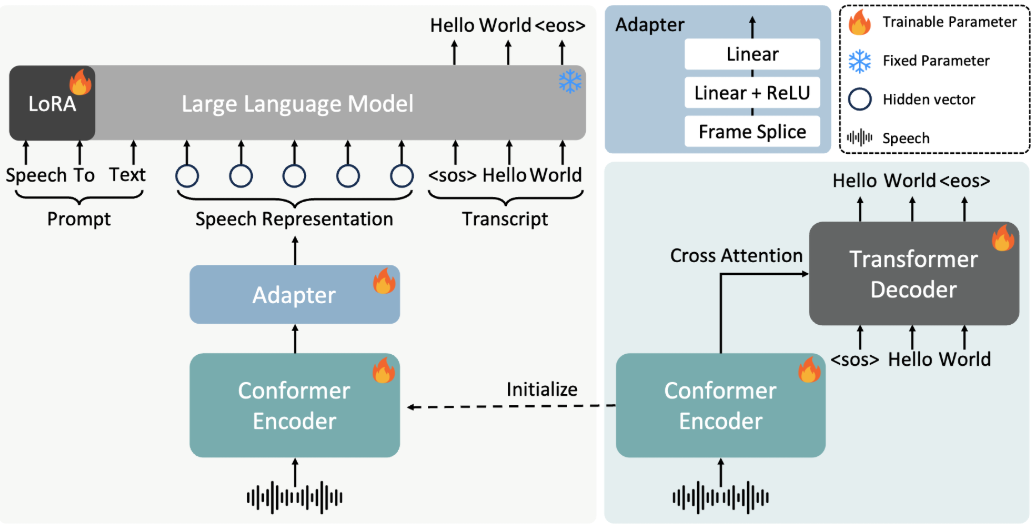
Long-VITA 是由 VITA-MLLM 团队开发的一款开源多模态大模型,专注于处理超长上下文的视觉和语言任务。它能够同时分析图像、视频和文本,支持高达 100 万 token 的输入,适用于视频理解、高分辨率图像解析和多模态智能体推理等场景。相比其他模型,Long-VITA 在短上下文任务中表现出色,同时在长序列处理上具有突破性优势。该项目由腾讯优图实验室、南京大学和厦门大学合作研发,完全基于开源数据集训练,支持 NPU 和 GPU 平台,旨在为开源社区提供强大的长上下文多模态研究工具。模型代码、训练方法和权重均已公开,适合研究者和开发者探索多模态 AI 的前沿应用。

功能列表
- 超长上下文处理: 支持高达 100 万 token 或 4K 帧的图像、视频和文本输入,适用于复杂场景分析。
- 多模态理解: 集成图像、视频和文本处理能力,可同时分析多种数据类型。
- 高效分布式推理: 通过上下文并行技术,实现超长输入的高效推理。
- 开源数据集训练: 使用 1700 万公开样本,确保模型可复现性和透明性。
- 跨平台支持: 兼容 Ascend NPU 和 Nvidia GPU,灵活适配不同硬件环境。
- 短上下文优化: 在传统多模态任务中保持领先性能,兼顾长短序列需求。
- Logits-Masked 语言建模: 创新的语言模型头设计,提升长序列推理效果。
使用帮助
Long-VITA 是一个开源项目,用户可以通过 GitHub 仓库获取代码和模型权重,并在本地或服务器上部署使用。以下是详细的使用指南,帮助用户快速上手并探索其强大功能。
安装流程
- 克隆仓库
打开终端,输入以下命令克隆 Long-VITA 仓库:git clone https://github.com/VITA-MLLM/Long-VITA.git cd Long-VITA
这将下载项目的所有代码和文档。
- 创建虚拟环境
使用 Conda 创建一个独立的 Python 环境,确保依赖隔离:conda create -n long-vita python=3.10 -y conda activate long-vita - 安装依赖
安装项目所需的 Python 包:pip install --upgrade pip pip install -r requirements.txt如果需要加速推理,可额外安装 Flash Attention:
pip install flash-attn --no-build-isolation - 下载模型权重
Long-VITA 提供了多个版本(如 16K、128K、1M token),用户可从 Hugging Face 下载: - 配置硬件环境
- Nvidia GPU: 确保安装 CUDA 和 cuDNN,设置环境变量:
export CUDA_VISIBLE_DEVICES=0 - Ascend NPU: 按照官方文档配置 MindSpeed 或 Megatron 环境。
- Nvidia GPU: 确保安装 CUDA 和 cuDNN,设置环境变量:
使用方法
Long-VITA 支持推理和评估两种主要操作模式,以下是具体步骤。
运行推理
- 准备输入数据
- 图像: 将图像文件(如
.jpg或.png)放入asset文件夹。 - 视频: 支持常见视频格式(如
.mp4),放置在指定路径。 - 文本: 编写问题或指令,保存为
.txt文件或直接在命令行输入。
- 图像: 将图像文件(如
- 执行推理命令
以图像理解为例,运行以下命令:CUDA_VISIBLE_DEVICES=0 python video_audio_demo.py \ --model_path [模型权重路径] \ --image_path asset/sample_image.jpg \ --model_type qwen2p5_instruct \ --conv_mode qwen2p5_instruct \ --question "描述这张图片的内容。"对于视频输入,添加
--video_path参数:--video_path asset/sample_video.mp4 - 查看输出
模型将在终端输出结果,例如图片描述或视频分析内容。
评估性能
- 准备评估数据集
下载基准数据集(如 Video-MME),并按要求组织文件结构。 - 运行评估脚本
使用提供的脚本进行评估:bash script/evaluate.sh [模型路径] [数据集路径]
特色功能操作
超长上下文处理
- 操作步骤:
- 选择 Long-VITA-1M 模型,确保输入数据(如长视频或多张高清图像)总 token 数不超过 100 万。
- 使用
--max_seq_len 1048576参数设置最大序列长度。 - 运行推理,观察模型如何处理长序列任务(如视频摘要生成)。
- 示例: 输入一小时视频,提问“总结视频主要情节”,模型将输出简洁的文本摘要。
多模态理解
- 操作步骤:
- 准备多模态输入,例如图像+文本或视频+问题。
- 在命令行中同时指定
--image_path和--question,如:--image_path asset/sample_image.jpg --question "图片中的人物是谁?" - 模型将结合视觉和文本信息生成答案。
- 示例: 输入一张名人照片和问题“他在做什么?”,模型会描述照片中的动作。
分布式推理
- 操作步骤:
- 配置多 GPU 环境,修改
CUDA_VISIBLE_DEVICES=0,1,2,3。 - 使用上下文并行选项运行:
python -m torch.distributed.launch --nproc_per_node=4 video_audio_demo.py [参数] - 模型将自动分配任务到多个设备,提升处理速度。
- 配置多 GPU 环境,修改
- 示例: 处理超长视频时,分布式推理可将耗时从数小时缩短至数分钟。
注意事项
- 确保硬件内存足够,1M token 输入可能需要 32GB 以上显存。
- 输入数据需预处理(如视频帧提取),以匹配模型要求。
- 检查网络连接,下载权重时需稳定高速网络。
通过以上步骤,用户可以轻松部署 Long-VITA 并体验其超长上下文和多模态理解能力,适合研究、开发或测试多模态 AI 应用。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章

暂无评论...