
综合介绍
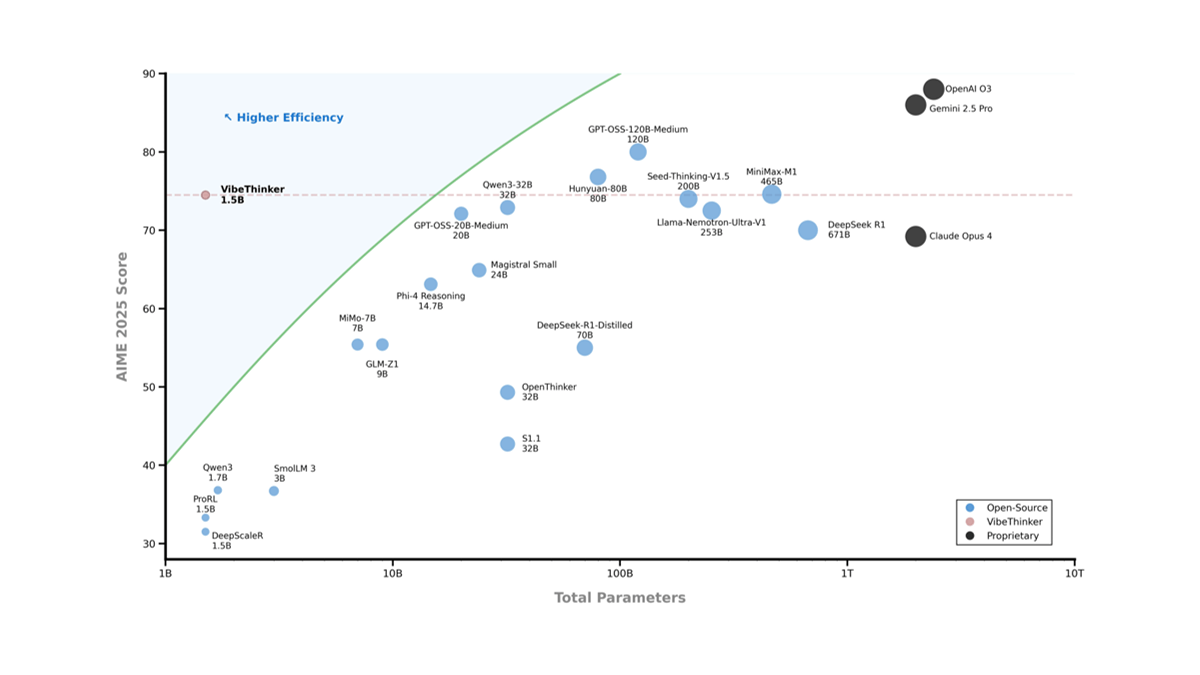
Light-R1 是由奇虎360(Qihoo360)团队开发的一款开源人工智能模型,专注于数学领域的长链推理(Chain-of-Thought, COT)。它基于 Qwen2.5-32B-Instruct 模型,通过独特的课程式监督微调(SFT)和直接偏好优化(DPO)训练方法,仅用约1000美元的成本(12台H800机器6小时训练),在数学竞赛 AIME24 和 AIME25 上分别取得了76.6和64.6的高分,超越了此前表现优异的 DeepSeek-R1-Distill-Qwen-32B(72.6和54.9)。Light-R1 的亮点在于从无长链推理能力的模型起步,结合去污染数据和模型融合技术,实现了高效且经济的性能突破。项目不仅发布了模型,还开放了所有训练数据集和代码,旨在推动长链推理模型的普及与发展。

功能列表
- 数学推理能力:针对 AIME 等高难度数学竞赛,提供精准的问题求解能力。
- 长链推理支持:通过硬编码
<think>标签,强制模型逐步推理复杂问题。 - 开源资源共享:提供完整的 SFT 和 DPO 训练数据集及基于 360-LLaMA-Factory 的训练脚本。
- 高效推理部署:支持 vLLM 和 SGLang 框架,优化模型推理速度与资源占用。
- 模型评估工具:集成 DeepScaleR 评估代码,提供 AIME24 等基准测试结果。
- 数据去污染:确保训练数据针对 MATH-500、AIME24/25 等基准无污染,提升公平性。
使用帮助
获取与安装流程
Light-R1 是一个开源项目,托管在 GitHub 上,用户可以通过以下步骤获取并部署模型:
- 访问 GitHub 仓库
打开浏览器,输入网址https://github.com/Qihoo360/Light-R1,进入项目主页。页面包含模型介绍、数据集链接和代码说明。 - 克隆仓库
在终端或命令行中输入以下命令,将项目克隆到本地:
git clone https://github.com/Qihoo360/Light-R1.git
克隆完成后,进入项目目录:
cd Light-R1
- 下载模型文件
Light-R1-32B 模型托管在 Hugging Face 上。访问https://huggingface.co/Qihoo360/Light-R1-32B,根据页面提示下载模型权重文件。下载后,将文件放置在本地仓库的合适目录(如models/),具体路径可参考项目文档。 - 安装依赖环境
Light-R1 推荐使用 vLLM 或 SGLang 进行推理,需安装相关依赖。以 vLLM 为例:
- 确保已安装 Python 3.8 或以上版本。
- 安装 vLLM:
pip install vllm - 如果需要 GPU 支持,确保 CUDA 已配置好(推荐 12 台 H800 或同等算力设备)。
- 准备数据集(可选)
如果需要复现训练或自定义微调,可从 GitHub 页面下载 SFT 和 DPO 数据集(链接在Curriculum SFT & DPO datasets部分)。解压后放置在data/目录。
主要功能操作流程
1. 使用 Light-R1 进行数学推理
Light-R1 的核心功能是解决数学问题,尤其是需要长链推理的复杂题目。以下是操作步骤:
- 启动推理服务
在终端中进入项目目录,运行以下命令启动 vLLM 推理服务:
python -m vllm.entrypoints.api_server --model path/to/Light-R1-32B
其中 path/to/Light-R1-32B 替换为实际模型文件路径。启动后,服务默认监听本地端口(通常为 8000)。
- 发送推理请求
使用 Python 脚本或 curl 命令向模型发送数学问题。以 curl 为例:
curl http://localhost:8000/v1/completions
-H "Content-Type: application/json"
-d '{
"model": "Light-R1-32B",
"prompt": "<think>Solve the equation: 2x + 3 = 7</think>",
"max_tokens": 200
}'
模型会返回逐步推理过程和答案,例如:
{
"choices": [{
"text": "<think>First, subtract 3 from both sides: 2x + 3 - 3 = 7 - 3, so 2x = 4. Then, divide both sides by 2: 2x / 2 = 4 / 2, so x = 2.</think> The solution is x = 2."
}]
}
- 注意事项
<think>标签是硬编码的,必须包含在输入中以触发长链推理。- 对于 AIME 级别难题,建议增加
max_tokens(如 500),确保推理完整。
2. 复现模型训练
如果想复现 Light-R1 的训练过程或基于其进行二次开发,可按以下步骤操作:
- 准备训练环境
使用 360-LLaMA-Factory 框架,安装依赖:
pip install -r train-scripts/requirements.txt
- 运行 SFT Stage 1
编辑train-scripts/sft_stage1.sh,确保模型路径和数据集路径正确,然后执行:
bash train-scripts/sft_stage1.sh
该阶段使用 76k 数据集,约需 3 小时(12 台 H800)。
- 运行 SFT Stage 2
类似地,运行:
bash train-scripts/sft_stage2.sh
使用 3k 更难数据集,提升模型性能。
- 运行 DPO
执行:
bash train-scripts/dpo.sh
DPO 基于 SFT Stage 2 结果,进一步优化推理能力。
- 模型合并
使用提供的合并脚本(如merge_models.py),将 SFT 和 DPO 模型融合:
python merge_models.py --sft-model sft_stage2 --dpo-model dpo --output Light-R1-32B
3. 评估模型性能
Light-R1 提供评估工具,可测试 AIME24 等基准:
- 运行评估脚本
在deepscaler-release/目录下,执行:
python evaluate.py --model Light-R1-32B --benchmark AIME24
结果将记录在日志中,64 次平均得分应接近 76.6。
特色功能详解
长链推理优化
Light-R1 通过 <think> 和 </think> 特殊标记,确保模型在数学问题上逐步推理。例如,输入:
<think>Find the number of positive integers less than 100 that are divisible by 3 or 5.</think>
模型输出:
<think>Let’s use inclusion-exclusion. Numbers divisible by 3: 99 ÷ 3 = 33. Numbers divisible by 5: 99 ÷ 5 = 19. Numbers divisible by 15 (LCM of 3 and 5): 99 ÷ 15 = 6. Total = 33 + 19 - 6 = 46.</think> Answer: 46.
数据去污染保障
训练数据经过严格去污染,确保 AIME24/25 等基准公平性。用户可通过检查数据集(data/ 目录)验证无重复题目。
低成本训练范例
Light-R1 证明了高效训练的可行性,用户可参考训练脚本,针对其他领域(如物理)定制模型。
使用技巧
- 提高推理准确性:增加
max_tokens或多次运行取平均值。 - 调试问题:查看评估日志,分析模型在特定题目上的推理过程。
- 社区支持:加入 GitHub 页面提供的 WeChat 群,与开发者交流。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章


暂无评论...