
Vanna 로컬 배포: 손쉬운 효율적인 Text2SQL 변환

Vanna는 자연어를 SQL 쿼리 문으로 변환하는 높은 평가를 받고 있는 Text2SQL 오픈 소스 프레임워크입니다. 이 문서에서는 Vanna를 로컬에 배포하고 이를 MySQL 데이터베이스와 결합하는 방법을 자세히 설명합니다. Deepseek 이 모델은 도구를 빠르게 시작할 수 있도록 구성 및 테스트되었습니다. 모든 작업은 실제 테스트를 기반으로 하여 단계가 명확하고 실행 가능한지 확인합니다.
Python 환경 설정
Vanna를 실행하려면 먼저 안정적인 Python 환경이 필요합니다. 다음은 미니콘다3를 예로 들어 Vanna를 구성하는 단계별 가이드입니다.
미니콘다3 설치하기
- 설치 패키지를 다운로드합니다:
wget https://repo.continuum.io/miniconda/Miniconda3-latest-Linux-x86_64.sh - 설치 스크립트를 실행합니다:
sh Miniconda3-latest-Linux-x86_64.sh - 환경 변수를 구성합니다:
vim /etc/profile파일에 추가합니다:
export PATH="/data/apps/miniconda3/bin:$PATH"구성을 저장하고 새로 고칩니다:
source /etc/profile - 제거해야 하는 경우 설치 디렉터리를 삭제하면 됩니다:
rm -rf /data/apps/miniconda3/
가상 환경 만들기
- Python 3.10 환경을 만듭니다:
conda create -n test python=3.10 - 환경을 활성화합니다(새 단말기 또는 재부팅 후 적용해야 함):
conda activate test - 기타 일반적인 명령:
- 환경 종료:
conda deactivate - 환경 정보 보기:
conda info --env
- 환경 종료:
위의 단계를 완료하면 Vanna 배포를 위한 기반이 되는 독립형 Python 가상 환경을 갖추게 됩니다.
Vanna 배포 및 구성
Python 환경이 준비되었으니 이제 Vanna의 핵심 구성으로 넘어가겠습니다. 다음 작업은 공식 문서(https://vanna.ai/docs/)를 참조하고 MySQL 데이터베이스를 예로 들어 설명합니다.
데이터베이스 연결 구성
먼저 MySQL 계정, 비밀번호, 포트로 데이터베이스에 제대로 로그인할 수 있는지 확인하세요. 연결이 성공적으로 테스트되면 공식 Vanna 설명서에서 MySQL 구성 페이지를 엽니다(왼쪽 메뉴 모음에서 MySQL 선택). 페이지에 아래와 같이 샘플 연결 코드가 표시됩니다:
데이터베이스 정보에 따라 코드의 매개변수(예: 호스트, 사용자, 비밀번호 등)를 조정하여 Vanna가 원활하게 연결되도록 합니다.
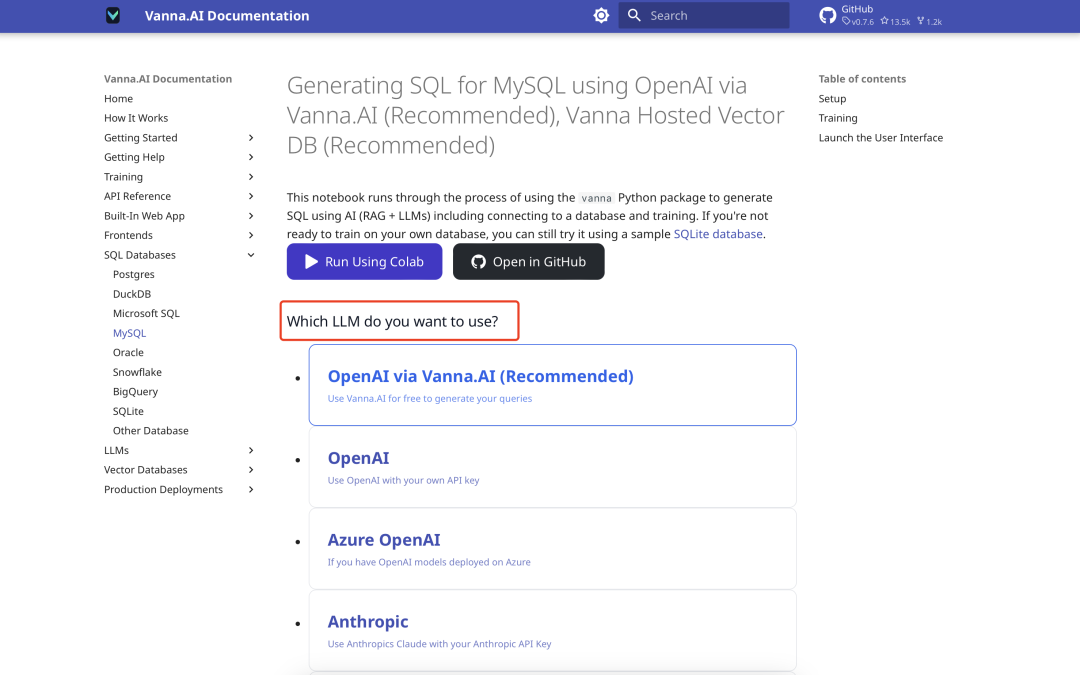
언어 모델 선택하기
Vanna는 다양한 대규모 언어 모델(LLM)을 지원합니다. 공식 페이지에서 다음과 같은 모델 선택 메시지가 표시됩니다. Ollama 또는 API 호출을 사용합니다. 실리콘 기반 흐름에 대한 딥시크 모델을 예로 들어 설명합니다.
- 올라마 체험양자화된 Deepseek-7b 모델을 배포하려고 시도했지만 결과가 좋지 않았으므로 이 옵션은 건너뛰는 것이 좋습니다.
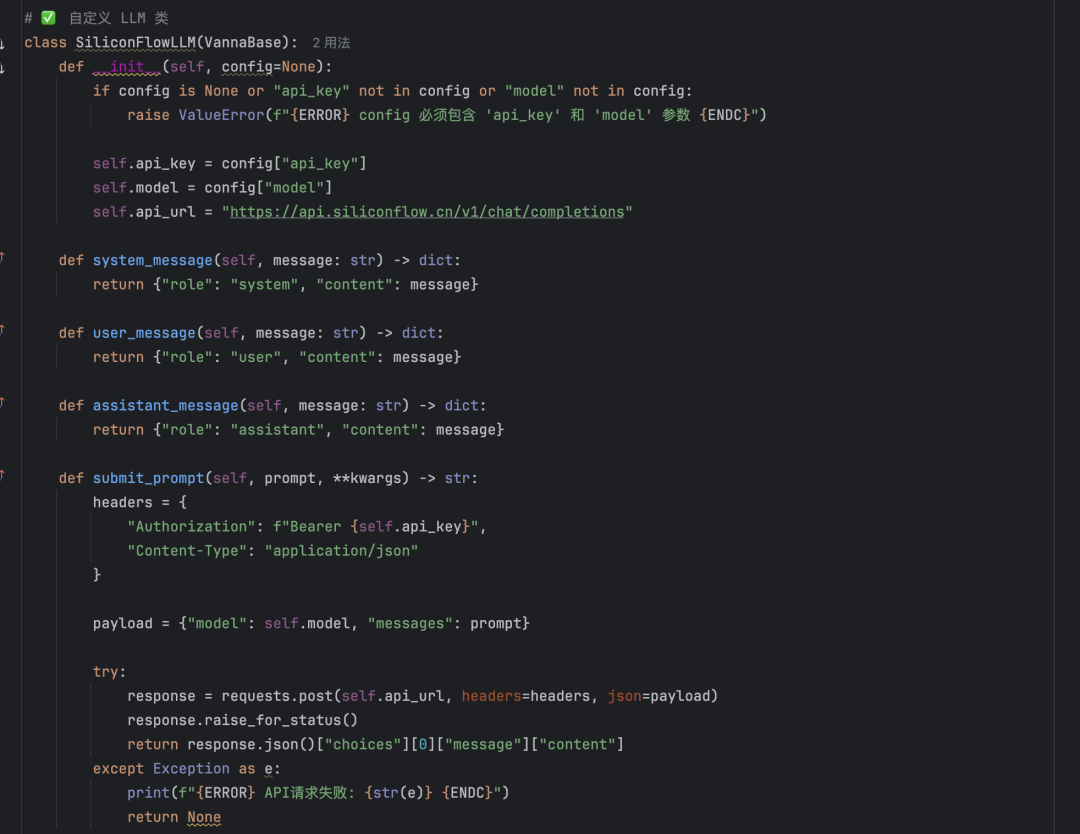
- 딥시크 API인실리코 플로우를 통해 Deepseek 모델을 호출하는 것이 더 나은 성능을 발휘합니다. 그러나 공식적으로 지원되지 않는 모델을 사용하려면 사용자 정의 LLM 클래스가 필요합니다. Vanna 오픈 소스 프로젝트의 미스트랄 구현(mistral.py)을 참조하여 그에 따라 Deepseek에 맞게 조정된 클래스를 생성하세요.
구성 화면은 다음과 같습니다:
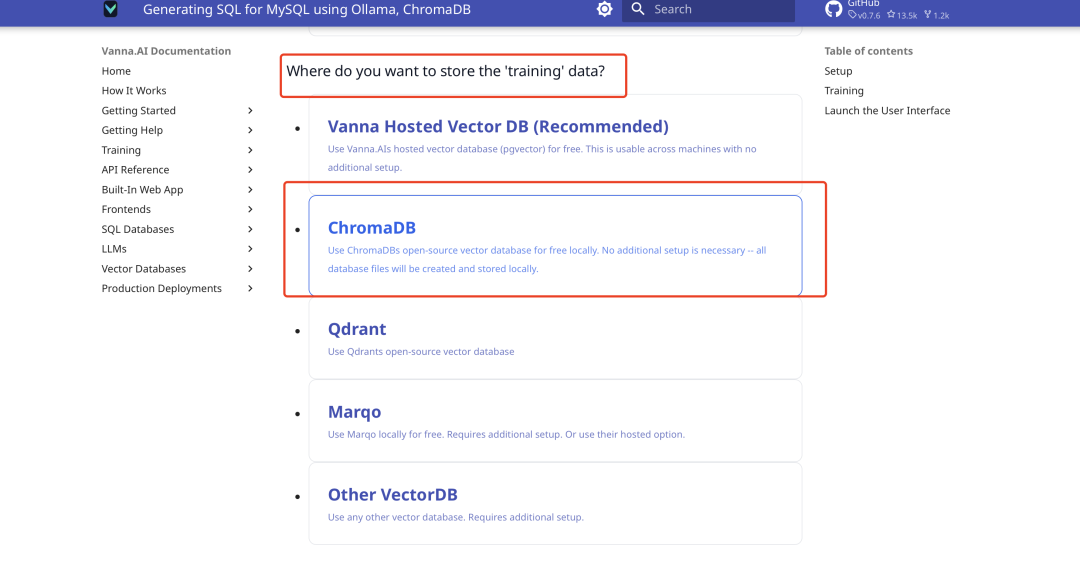
벡터 데이터베이스 설정
Vanna는 기본적으로 작은 벡터 데이터베이스로서 ChromaDB를 통합하므로 추가 설치가 필요하지 않습니다. 공식 문서에서는 아래와 같이 사용자의 선택에 따라 코드를 생성합니다:
종속성 설치 및 코드 준비
- 활성화된 가상 환경에 Vanna 및 해당 종속 요소를 설치합니다:
pip install vanna - 만들기
.py파일에 공식적으로 생성된 코드를 복사합니다. 다음은 MySQL 및 Deepseek을 적용하기 위한 샘플 코드 스니펫입니다(실제 상황에 따라 매개변수를 조정해야 함):from vanna.remote import VannaDefault vn = VannaDefault(model='deepseek', api_key='your_api_key') vn.connect_to_mysql(host='localhost', dbname='test_db', user='root', password='your_password', port=3306)
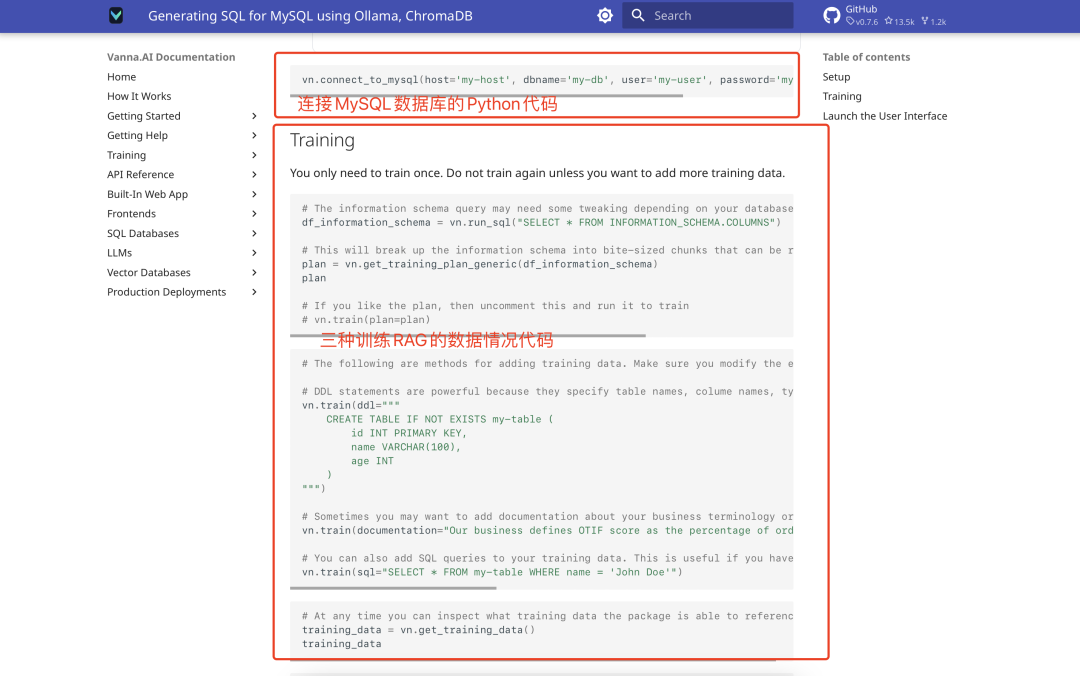
데이터 교육
Vanna는 SQL 문, 제품 문서, 데이터베이스 테이블 구조 설명의 세 가지 유형의 학습 데이터를 지원합니다. 여기서는 테이블 구조 설명을 사용하는 것이 더 직관적입니다. 훈련 단계는 다음과 같습니다:
- 테이블 구조 데이터(예: DDL 파일)를 준비합니다.
- 공식적으로 제공된 교육 코드를 사용하세요:
vn.train(ddl="CREATE TABLE employees (id INT, name VARCHAR(255), salary INT)") - 교육 과정은 아래와 같습니다:
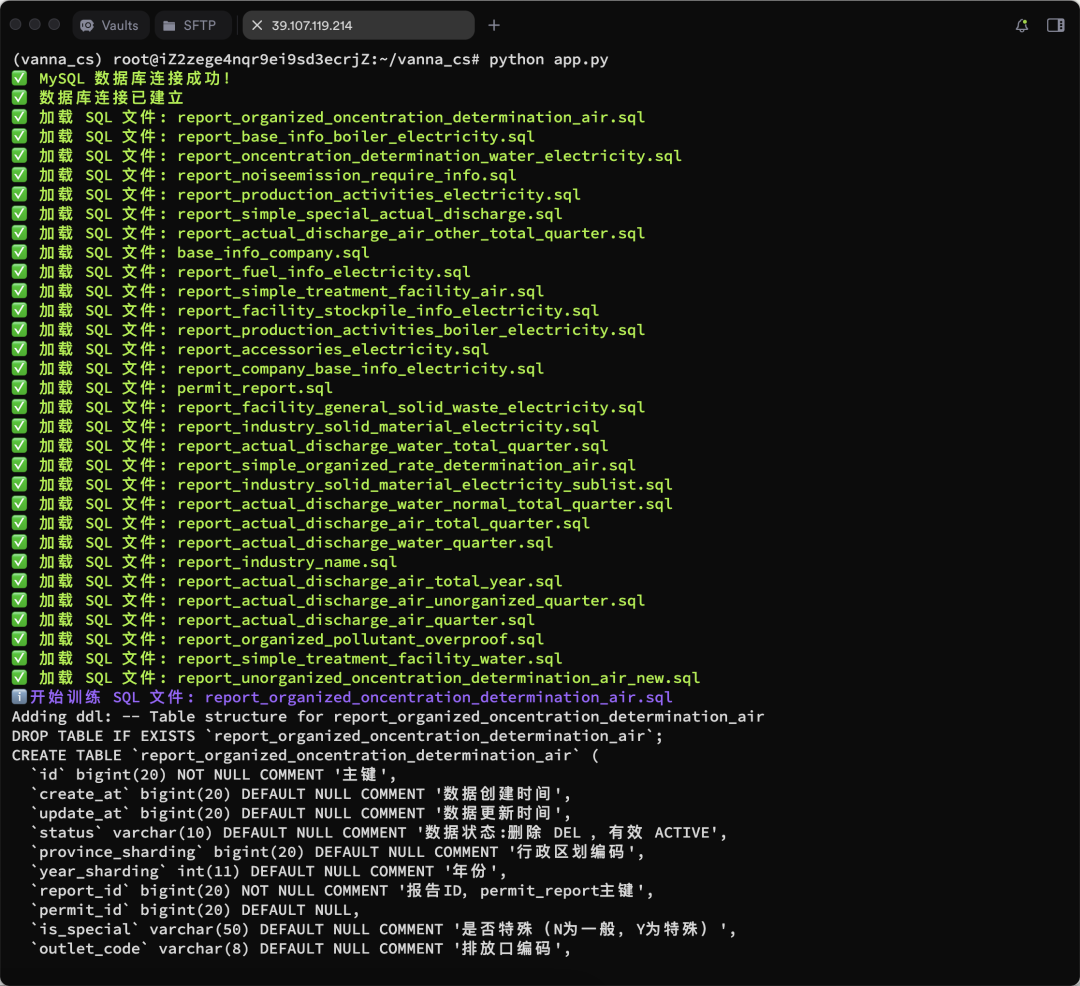
더 많은 교육 결과가 표시됩니다:
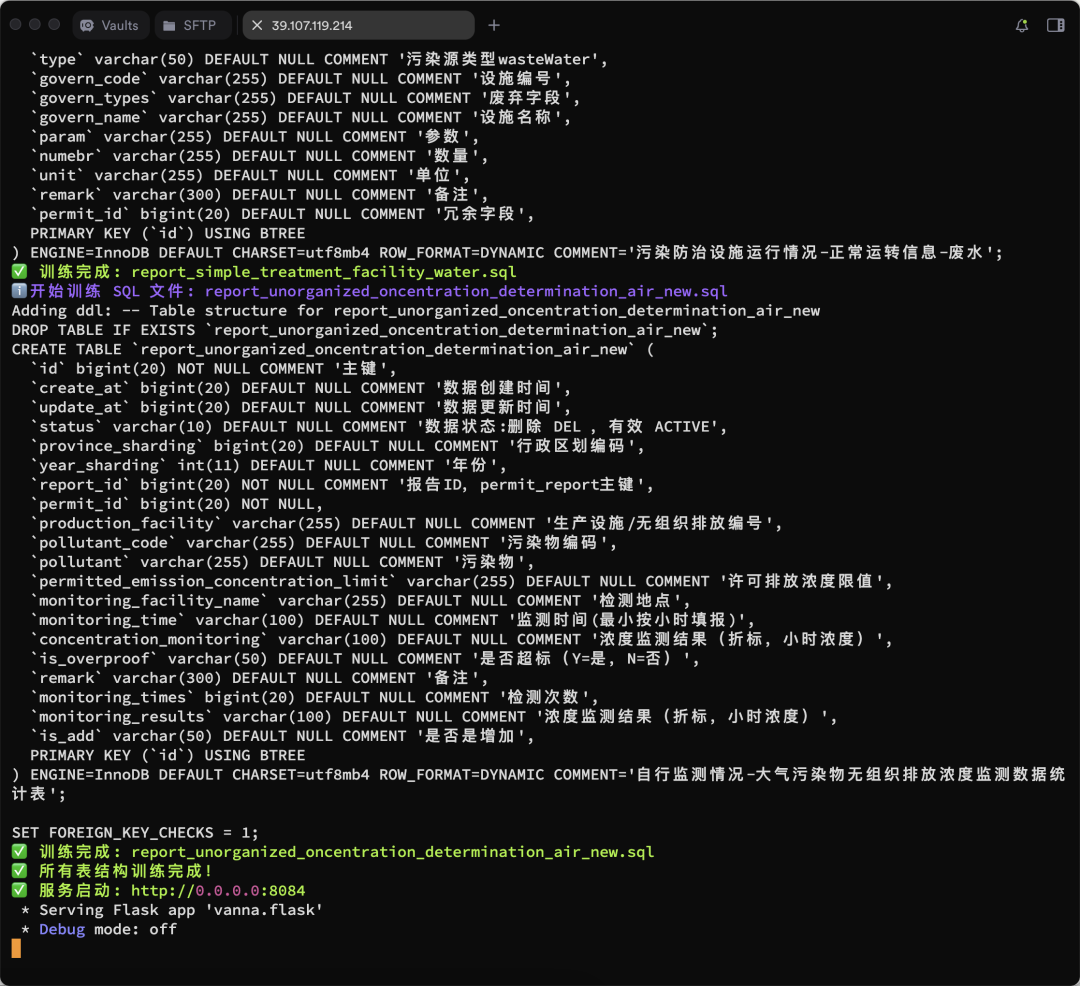
웹 인터페이스 실행
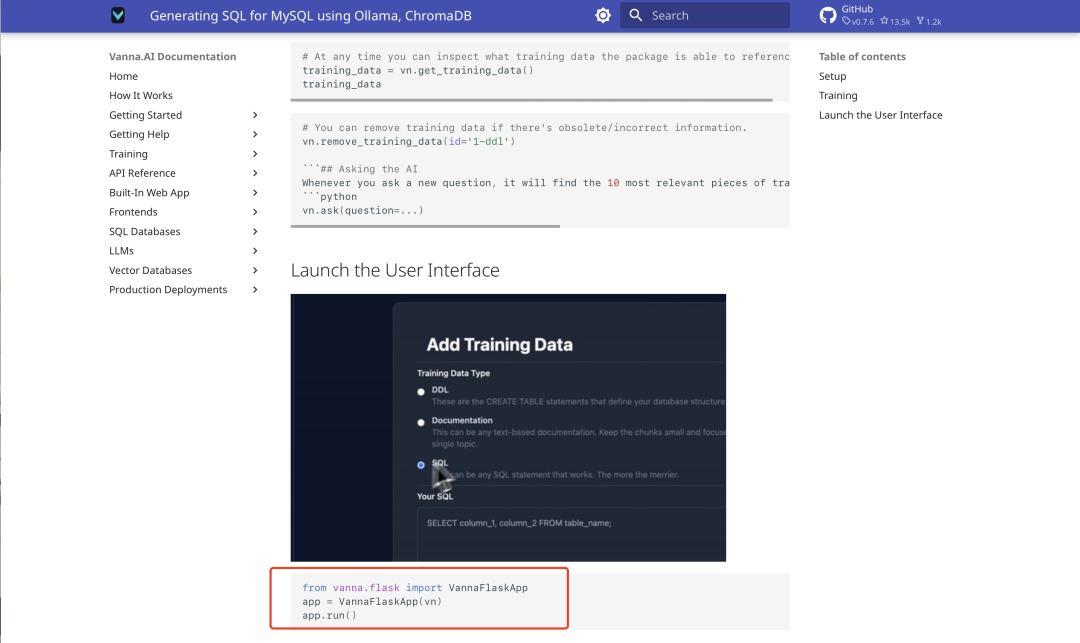
교육이 완료되면 다음 Flask API 코드를 실행하여 Vanna의 웹 UI를 실행합니다:
from vanna.flask import VannaFlaskApp
app = VannaFlaskApp(vn)
app.run()
로컬 주소에 액세스(일반적으로 http://127.0.0.1:5000), 인터페이스를 통해 SQL 쿼리를 수행할 수 있습니다.
조회 효과 표시
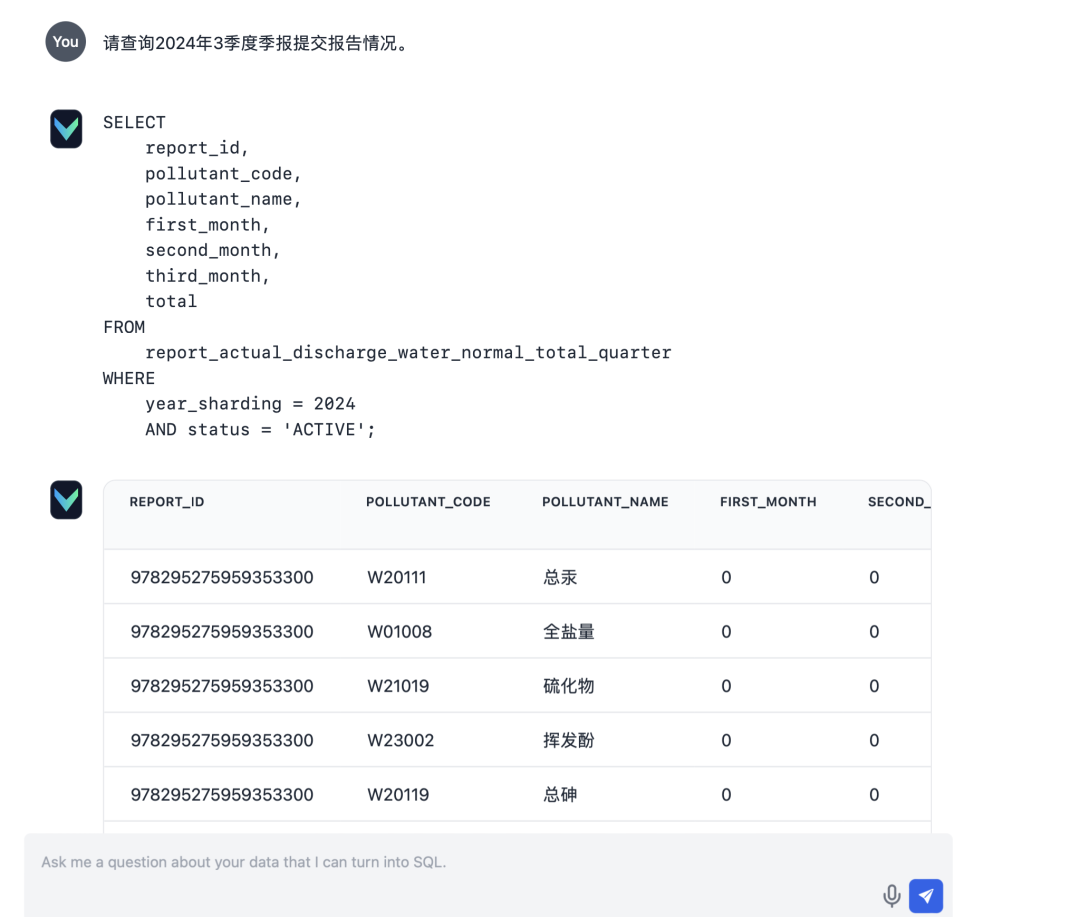
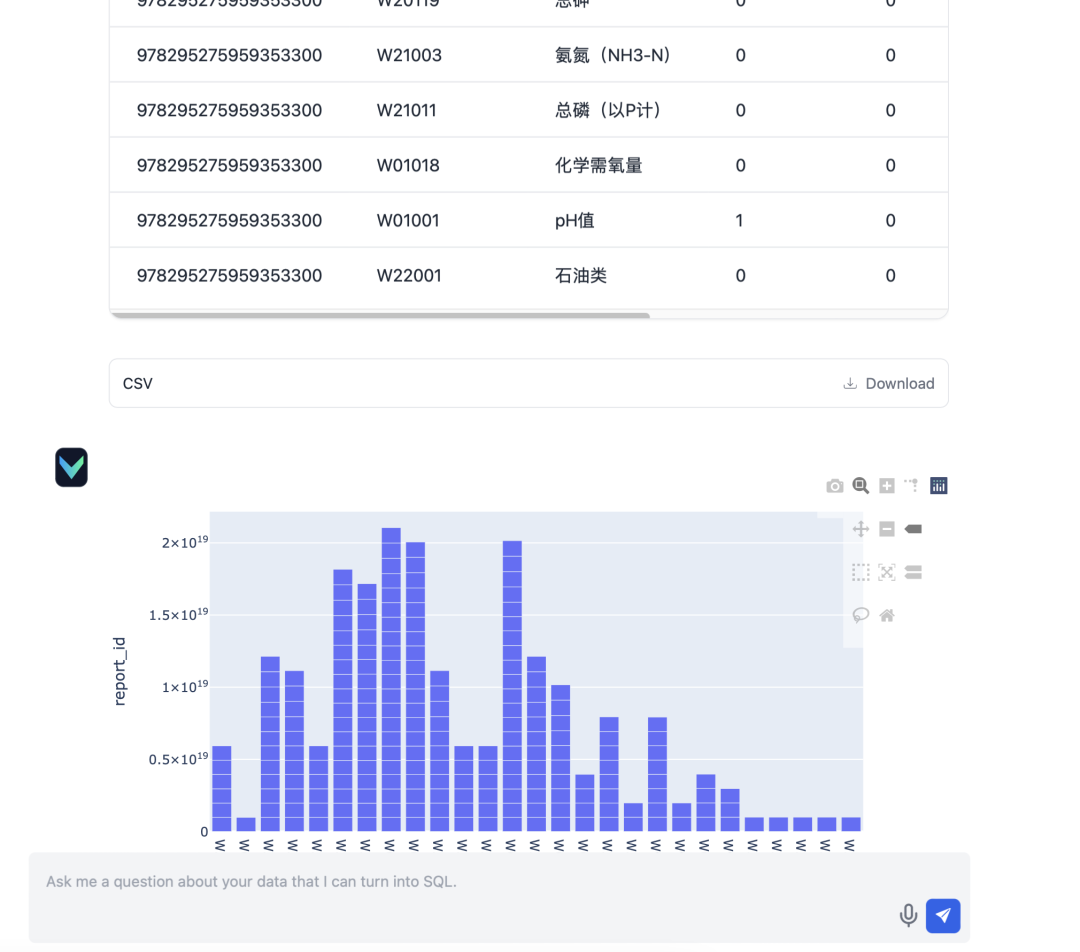
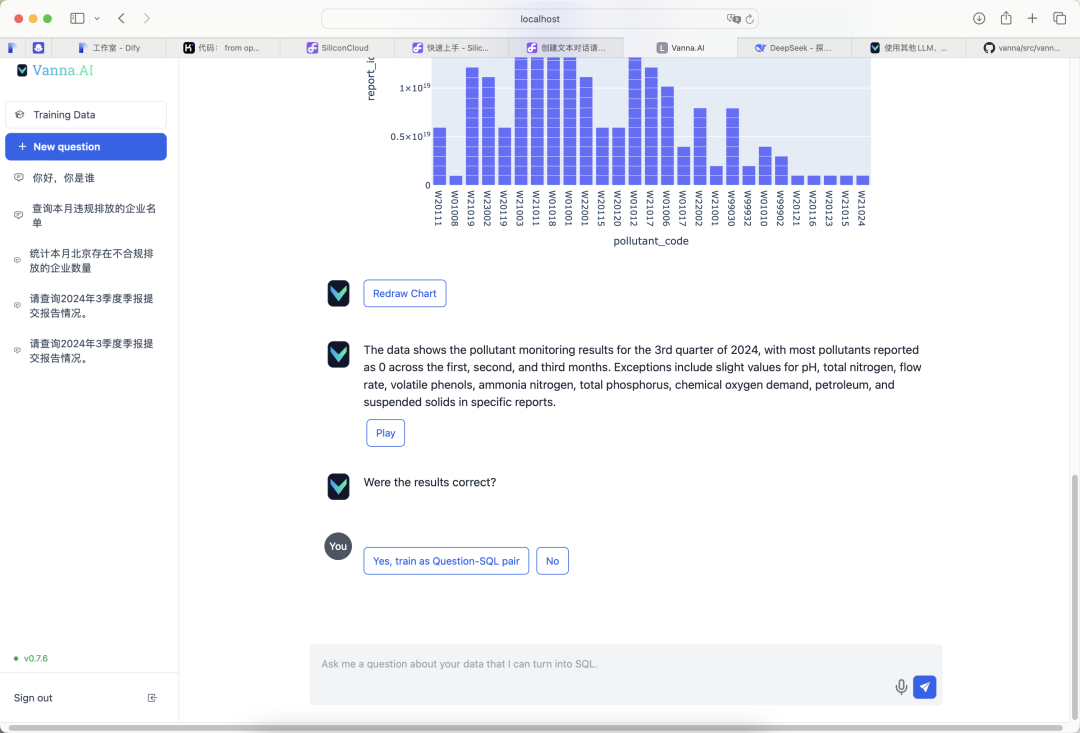
배포 후 Vanna의 Q&A 기능은 만족스럽게 작동했습니다. 다음은 몇 가지 실제 테스트 결과입니다:
- 입력: "2024년 3월 분기 보고서의 분기별 보고서 제출 현황에 대해 문의해 주세요."

- 입력: "통계 수"
- 입력: "오염 물질 통계"
요약 및 권장 사항
이 단계를 따르면 Vanna를 로컬에 성공적으로 배포하고 MySQL 및 Deepseek 모델과 함께 효율적인 Text2SQL 기능을 구현할 수 있습니다. 다른 도구와 비교했을 때, Vanna는 사용 편의성과 효율성 면에서 분명한 장점이 있습니다. 초보자는 테이블 구조를 사용하여 데이터를 훈련하고 실제 필요에 따라 언어 모델 구성을 조정하는 것을 우선적으로 고려하는 것이 좋습니다.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서



댓글 없음...