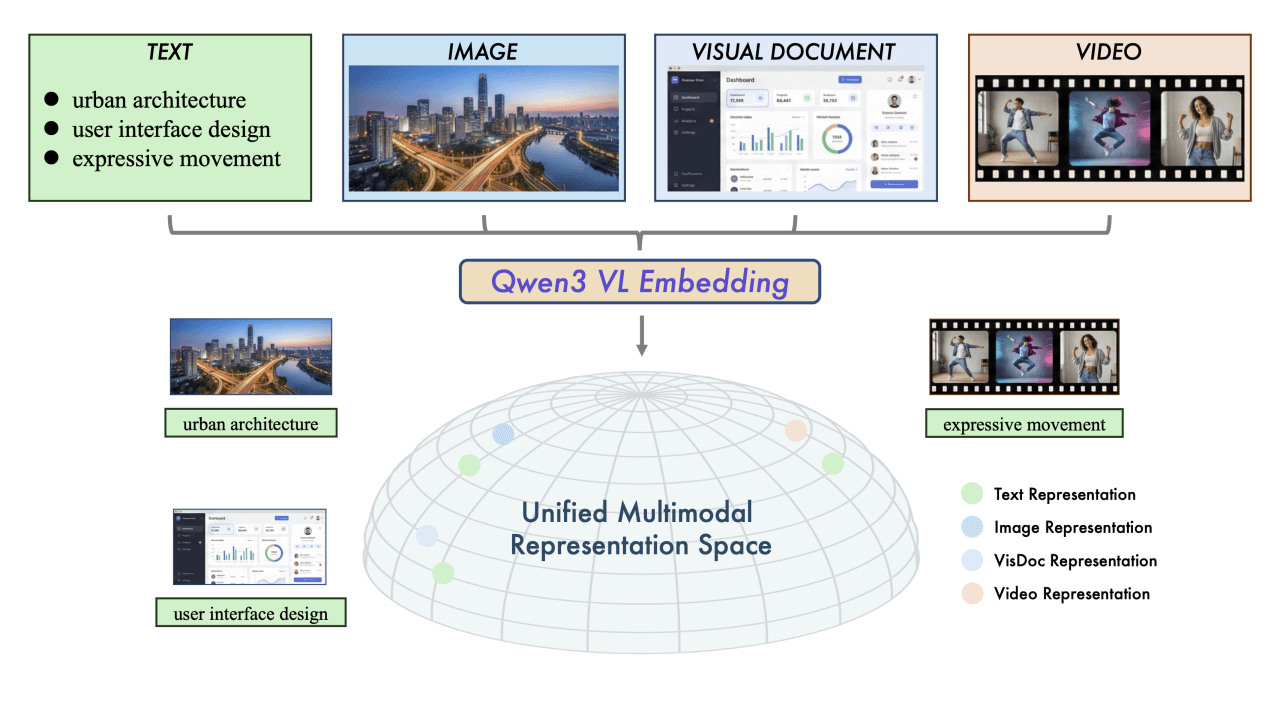
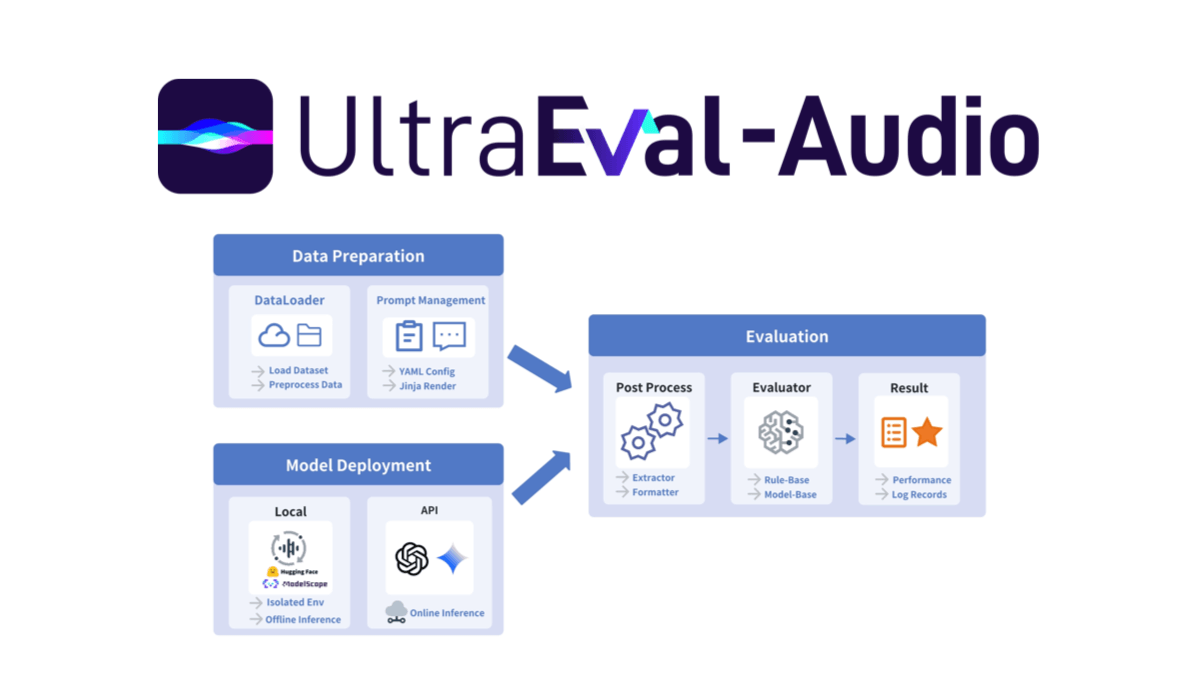
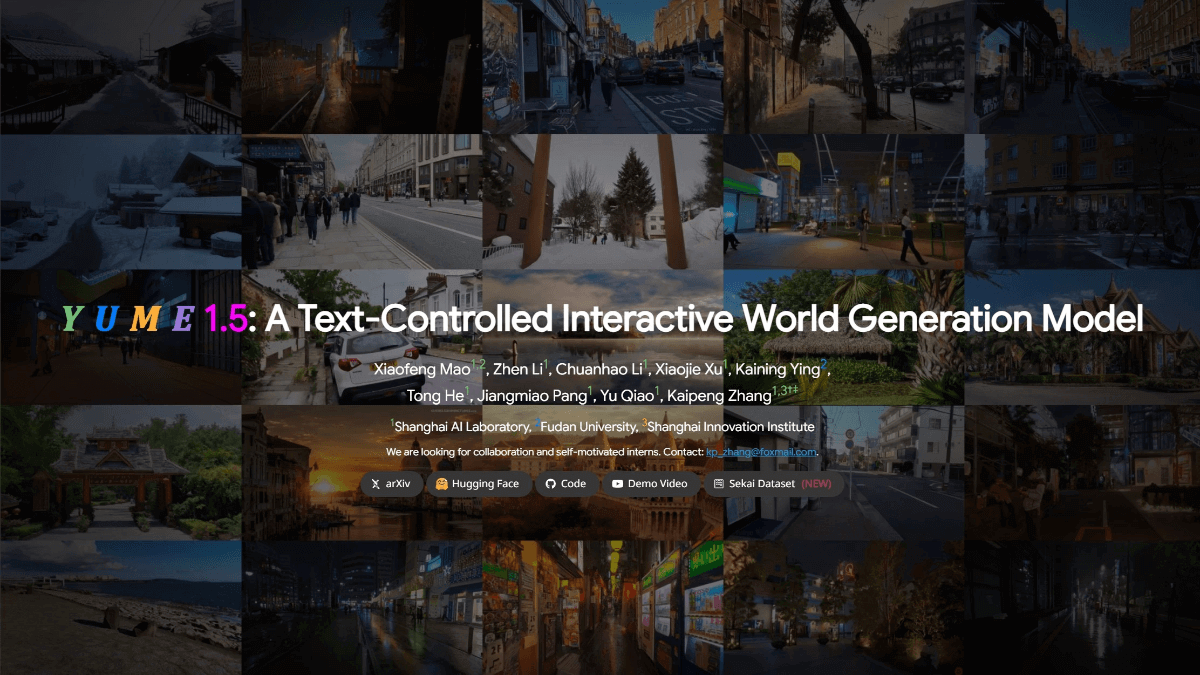
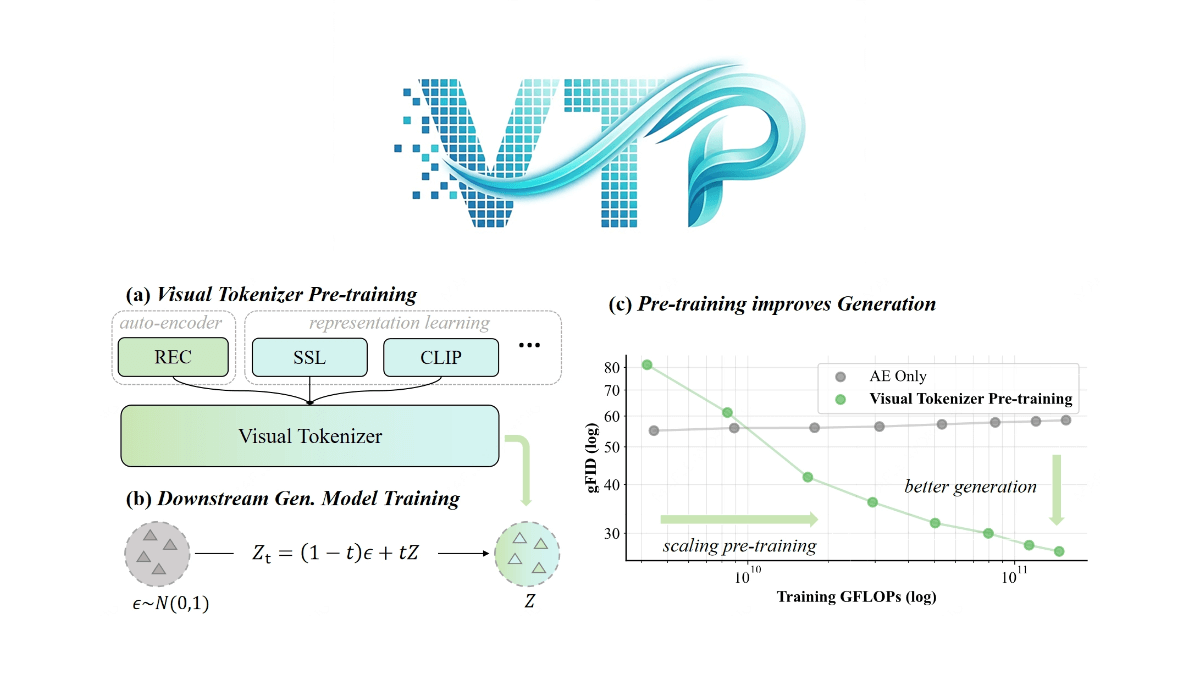
Yume 1.5는 상하이 인공지능 연구소, 푸단대학교, 상하이 혁신 연구소가 공동 개발한 오픈 소스 인터랙티브 월드 생성 모델로, 실시간 인터랙티브 렌더링(단일 카드에서 12FPS)이 가능합니다. 컨텍스트 길이가 증가하더라도 공동 시공간 채널 모델링(TSCM) 기술을 채택하여...
AutoMV는 M-A-P 팀이 여러 대학과 협력하여 개발한 오픈 소스 뮤직비디오 생성 시스템으로, 교육 없이도 완성된 곡을 기반으로 일관된 뮤직비디오를 자동으로 생성할 수 있으며, 음악 분석, 대본 작성, 연출 및 품질 관리 모듈을 포함한 다중 지능 협업 모델을 채택하여 가사, 비트 등을 정확하게 분석할 수 있습니다....
텐센트 하이브리드 오픈 소스 번역 모델 버전 1.5는 1.8B와 7B 두 가지 모델을 포함하여 33 개 국제 언어와 5 가지 중국어 및 중국어 / 방언 번역을 지원하는 텐센트 하이브리드 오픈 소스 번역 모델 버전 1.5입니다.1.8B 모델은 휴대 전화 및 기타 소비자 등급 장치에 특별히 최적화되어 있으며 1GB의 RAM 만 얻을 수 있습니다.
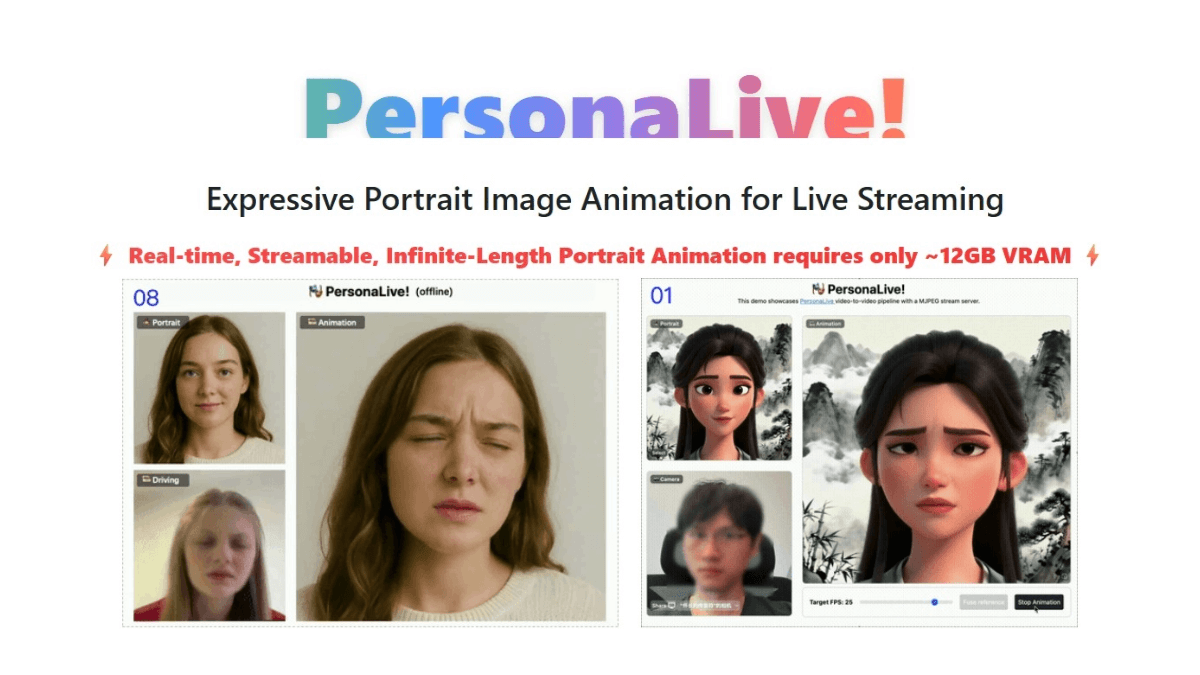
페르소나라이브는 마카오 대학교, dzine.ai, 그레이터 베이 지역 대학교의 GVC 랩이 공동 개발한 오픈 소스 실시간 AI 얼굴 교체 라이브 스트리밍 프레임워크입니다. 일반 소비자용 그래픽 카드(12GB 비디오 메모리)에서 지연 시간이 짧고 프레임 속도가 빠른 디지털 퍼스널 드라이브를 구현할 수 있으며 카메라를 통한 실시간 스트리밍을 지원합니다....
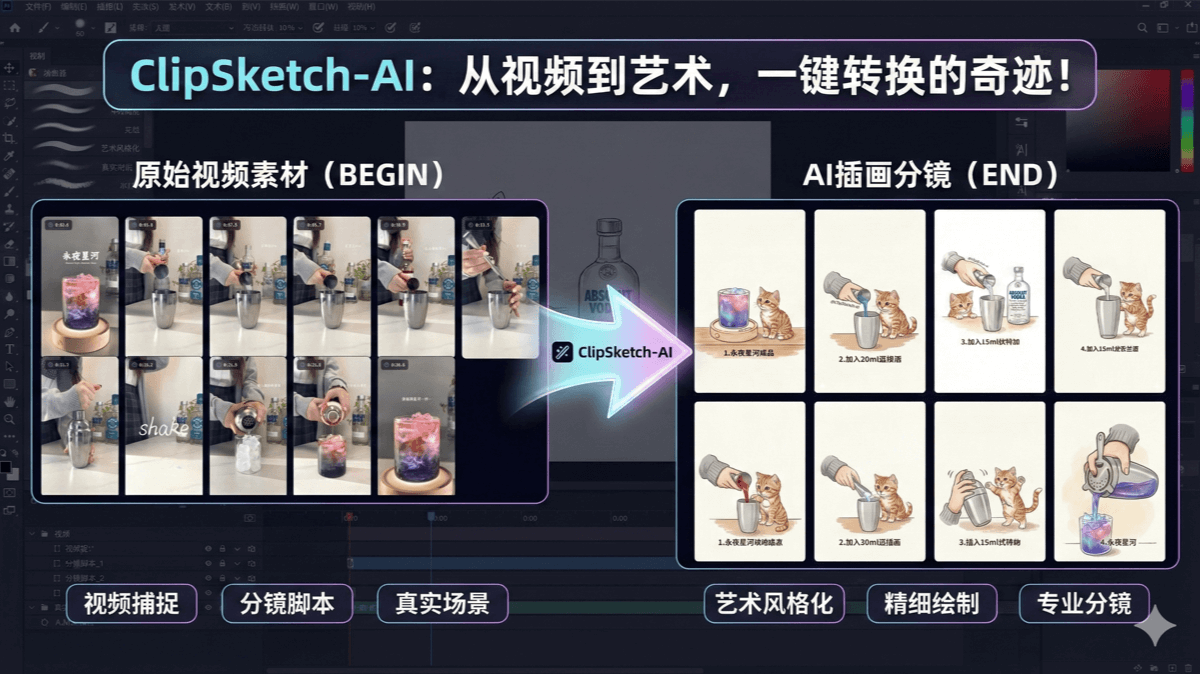
ClipSketch AI는 짧은 동영상 제작자를 위해 설계된 오픈 소스 동영상에서 손으로 그린 분할 화면 도구입니다. B 스테이션, 샤오홍슈 및 기타 플랫폼의 동영상을 한 번의 클릭으로 손으로 그린 스타일의 스토리보드로 변환하고, 키 프레임 표시, 서브 장면 자동 생성 및 소셜 카피를 지원하며, 사용자 정의 역할을 통합할 수 있습니다.
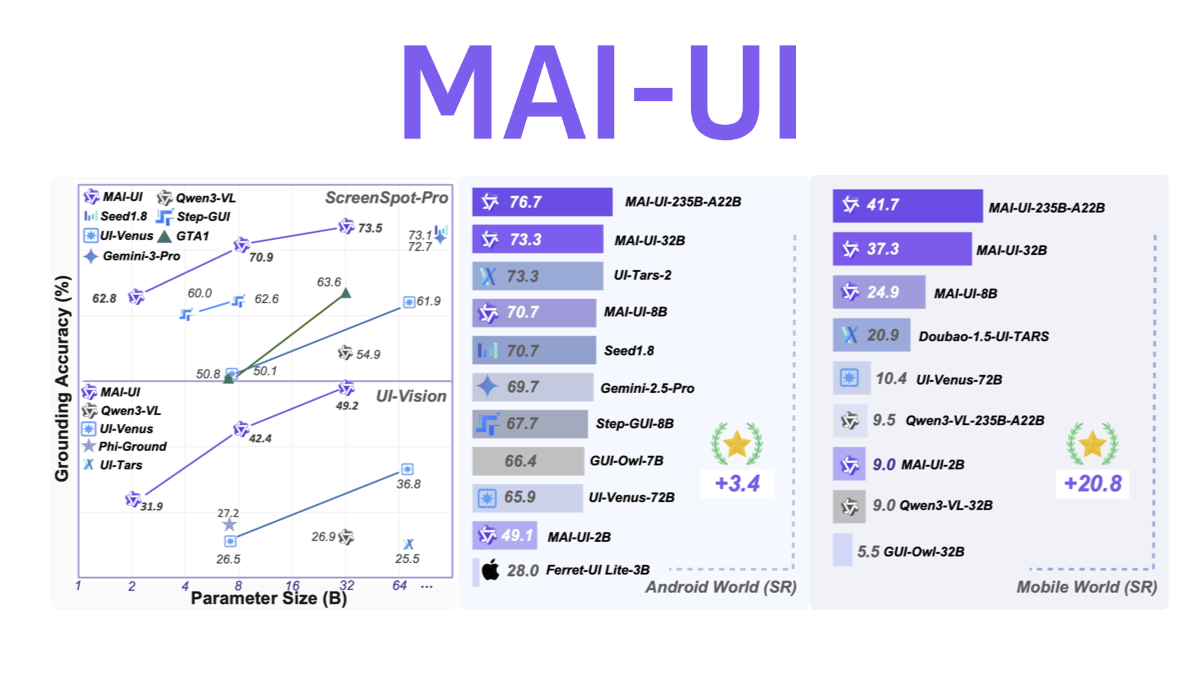
MAI-UI는 알리바바 통이 연구소의 오픈 소스 범용 GUI 지능형 바디 기반 모델로, 애플리케이션 간 작동, 퍼지 의미 이해, 능동적 사용자 상호 작용 및 다단계 프로세스 조정이라는 네 가지 주요 기능을 갖추고 있습니다. 엔드 클라우드 협업 아키텍처를 채택한 경량 모델은 장치에 상주하여 일상적인 작업을 처리하고 복잡한 작업은 클라우드를 대규모로 호출할 수 있습니다.
인스턴스어셈블은 샤오홍슈와 푸단대학교가 공동으로 오픈소스화한 레이아웃 제어 생성 기술로, '인스턴스 어셈블 주의' 메커니즘을 통해 단순한 레이아웃에서 복잡한 레이아웃, 희박한 레이아웃에서 조밀한 레이아웃까지 정확한 이미지 생성을 달성합니다. 먼저 이미지 배경에 2단계 캐스케이드 아키텍처를 채택한 다음 하나씩 하나씩 ...
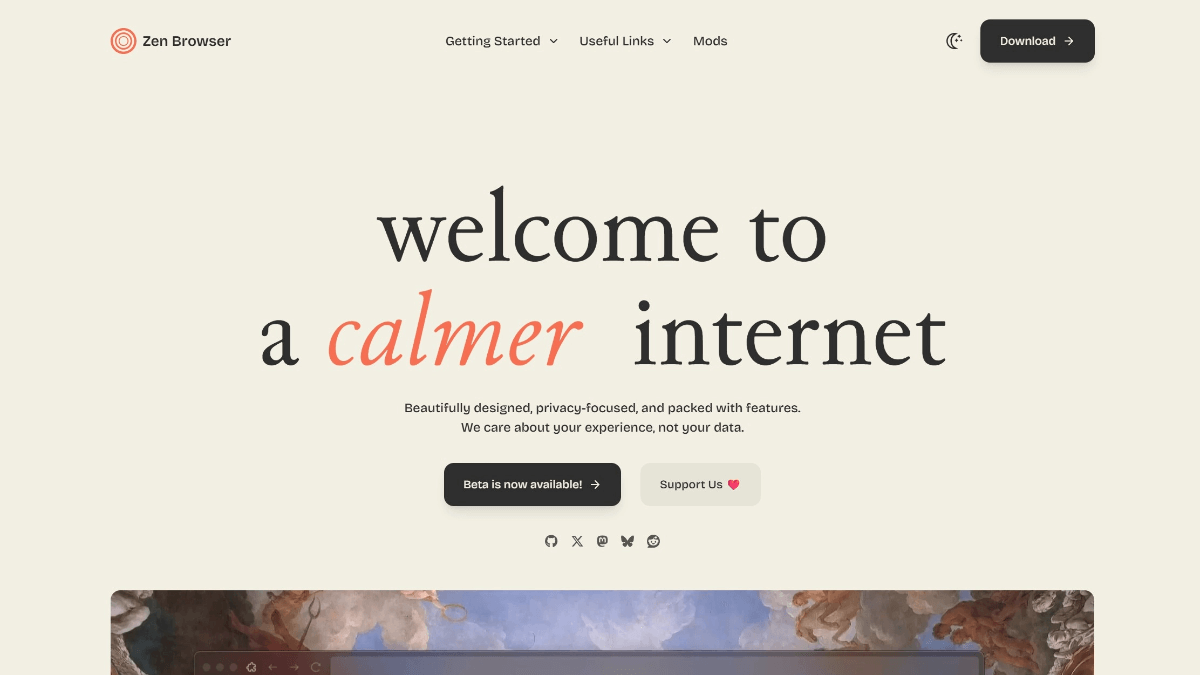
Zen 브라우저는 Firefox 커널 기반의 오픈 소스 브라우저로, 세로 탭 표시줄 및 작업 공간 분리와 같은 핵심 기능을 통해 간단하고 효율적인 브라우징 경험에 중점을 두고 있습니다. 사이드바 디자인으로 50개 이상의 탭의 전체 제목을 명확하게 표시하고 다중 창 분할 화면 브라우징을 지원합니다.
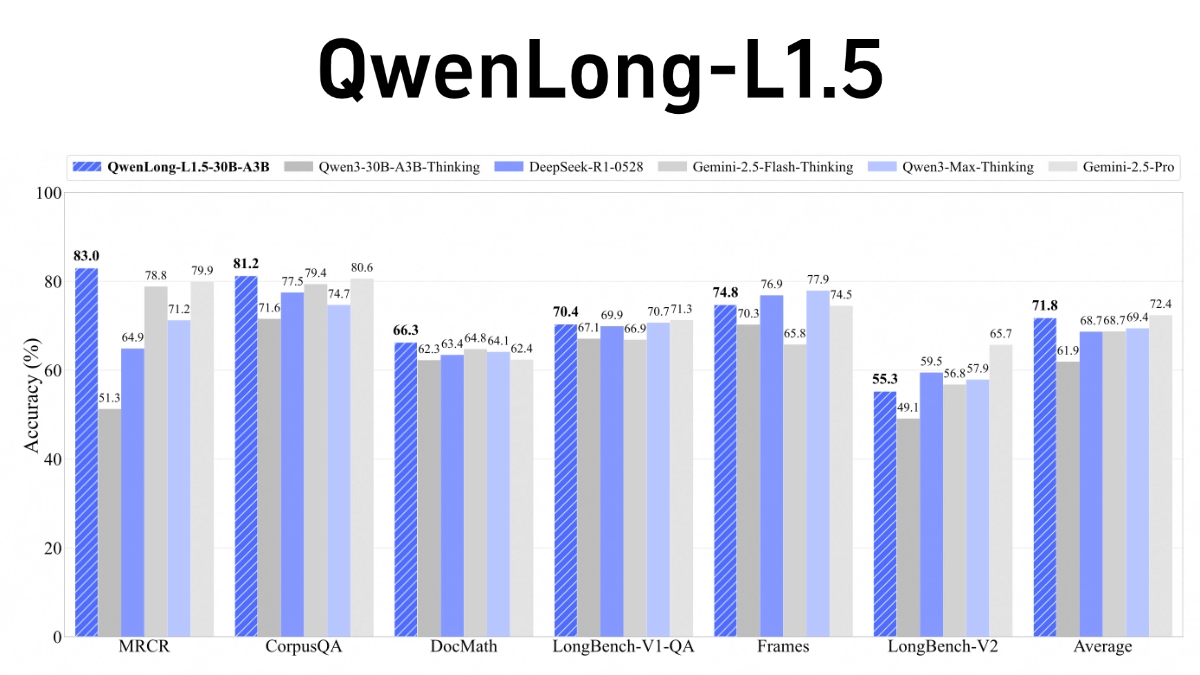
QwenLong-L1.5는 알리바바 통이 연구소의 오픈 소스 긴 텍스트 추론 모델로, 매우 긴 컨텍스트(예: 100만~4백만 토큰)의 복잡한 추론 문제를 해결하는 데 중점을 둡니다. 핵심 혁신은 지식 그래프, SQL 구문 분석 및 다중 지능을 통한 학습 후 단계의 세 가지 주요 혁신에 있습니다 ...
MedASR은 구글이 오픈소스화한 1억 5천만 개의 파라미터 의료 음성 인식 모델로, 5,000시간의 감작된 임상 말뭉치를 기반으로 미세 조정되어 약물, 용량 및 해부학 용어에 최적화되어 있으며, 6그램의 의료 언어 모델이 내장되어 있고 민간 방사선 데이터 세트 RAD-DICT에서 단어 오류율이 4.6에 불과합니다....
Fun-Audio-Chat-8B는 알리 통이 팀의 오픈 소스 80억 매개 변수 엔드 투 엔드 음성 빅 모델, 음성 출력에서 직접 음성, ASR + LLM + TTS 접합 필요 없음, 중국어와 영어에 유창하며 지연 시간이 짧고 자연스러운 음색을 가진 이중 언어입니다. 25Hz의 이중 해상도 공유 LLM 사용...
GLM-4.7은 AI 프로그래밍, 복잡한 추론 및 지능형 신체 작업에 심도 있게 최적화된 스마트 스펙트럼 AI에서 출시하고 오픈소스로 제공하는 최신 플래그십 그랜드 모델입니다. 이 모델은 다국어 코딩, 장거리 작업 계획 및 도구 협업 기능을 통해 200k 컨텍스트 길이와 최대 128k 출력을 지원합니다....
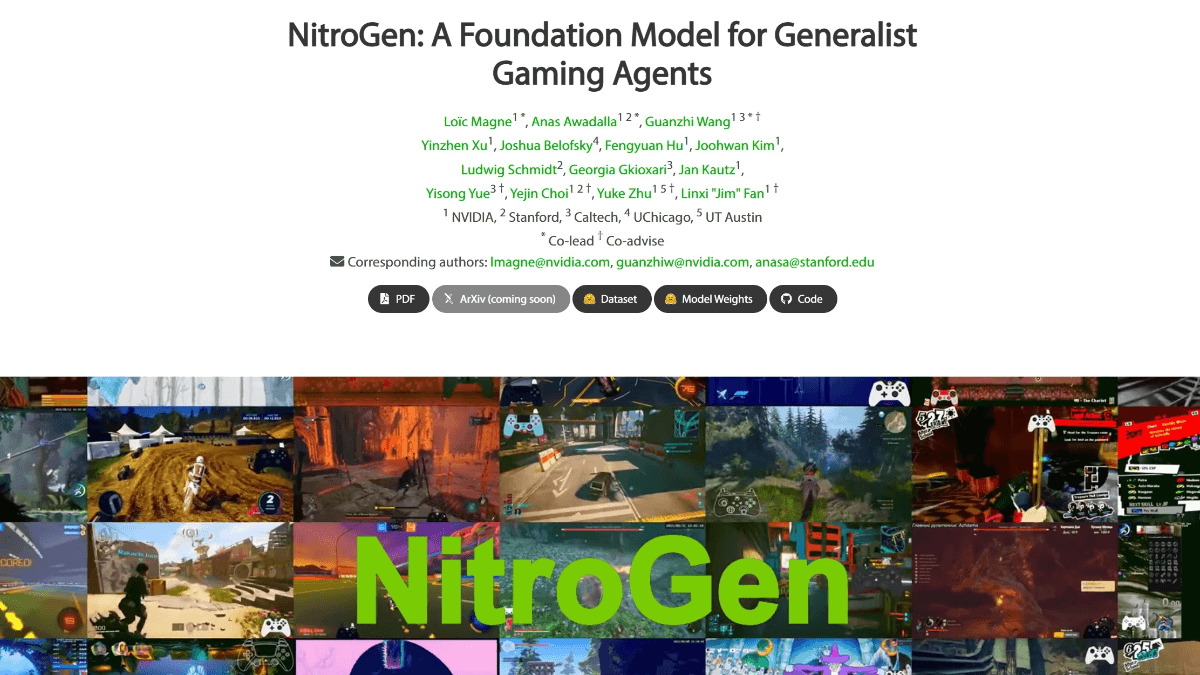
NitroGen은 NVIDIA가 스탠포드 대학, 칼텍 및 기타 기관과 함께 개발한 오픈 소스 게임 AI 모델로, 1,000개 이상의 다양한 유형의 게임을 플레이할 수 있습니다. 이 모델은 GROOT N1.5 아키텍처를 기반으로 하며, 40,000시간의 게임 비디오 데이터(조이스틱 조작 주석 포함)를 분석하여 완성되었습니다....
Qwen-Image-Layered는 Ali 팀의 오픈 소스 AI 이미지 편집 모델로, 일반 이미지를 독립적인 투명 레이어로 지능적으로 분해하여 포토샵과 같은 정밀 편집을 구현합니다. 이 모델은 Apache 2.0 프로토콜을 사용하여 오픈 소스이며 유연한 레이어 제어를 지원합니다....
T5Gemma 2는 Google에서 오픈소스로 제공하는 차세대 인코더-디코더 모델로, 멀티모달 및 긴 컨텍스트 처리 기능으로 업그레이드된 Gemma 3 아키텍처를 기반으로 합니다. 텍스트와 이미지를 포함한 다양한 데이터 유형을 지원하며, 생성 시 매우 긴 컨텍스트(최대 128K)를 처리할 수 있습니다.
FunctionGemma는 2억 7천만 개의 매개변수를 가진 Gemma 3 기본 모델을 기반으로 개발된 Google의 함수 호출에 최적화된 경량 AI 모델로, 휴대폰, 브라우저 및 기타 기기에서 자연어를 실시간으로 실행 가능한 API 명령으로 변환합니다. 핵심 기능은 로컬 오프...
TRELLIS.2는 40억 개의 파라미터를 갖춘 Microsoft의 오픈 소스 대규모 3D 생성 모델로, 고충실도 이미지에서 3D 생성에 중점을 두고 있습니다. 혁신적인 "O-Voxel"스파 스 복셀 구조를 사용하여 복잡한 토폴로지와 날카로운 특징을 효율적으로 처리하여 전체 PBR 재료로 고품질 3D 정보를 생성 할 수 있습니다 ...
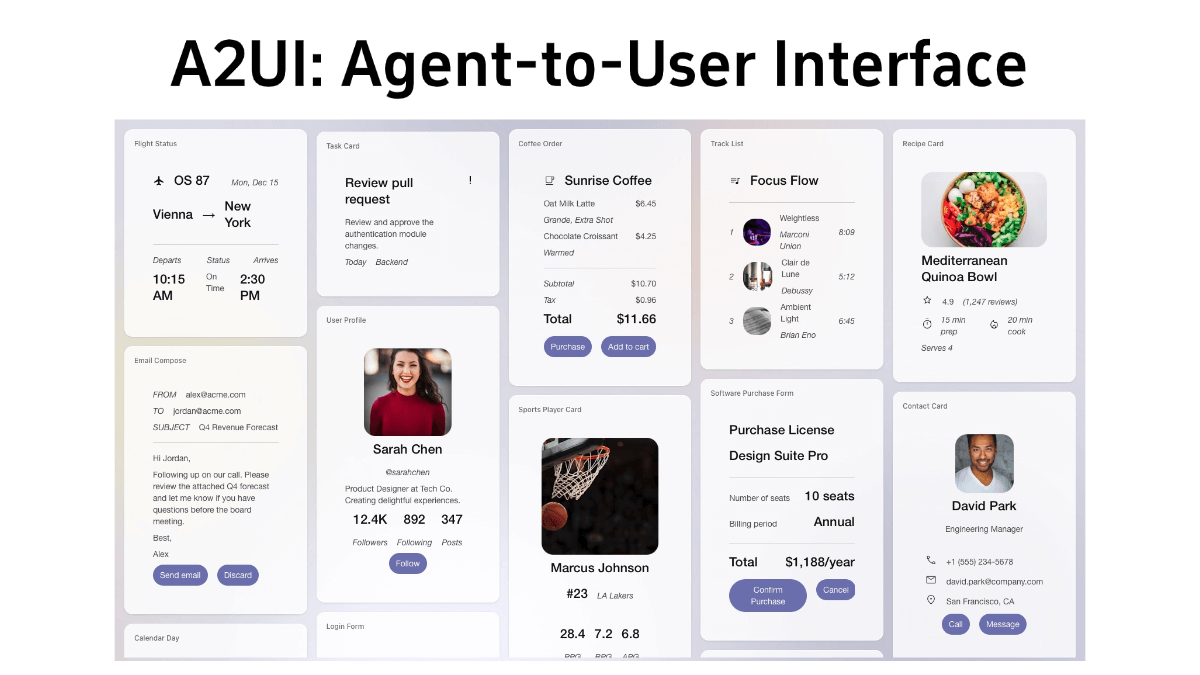
A2UI(에이전트-사용자 인터페이스)는 AI 에이전트를 위한 복잡한 대화형 인터페이스를 생성하는 문제를 해결하는 Google의 오픈 소스 에이전트 중심 인터페이스 프로토콜입니다. AI 에이전트가 사용자 인터페이스, 클라이언트 애플리케이션의 구조를 설명할 수 있는 선언적 JSON 형식을 통해 ...
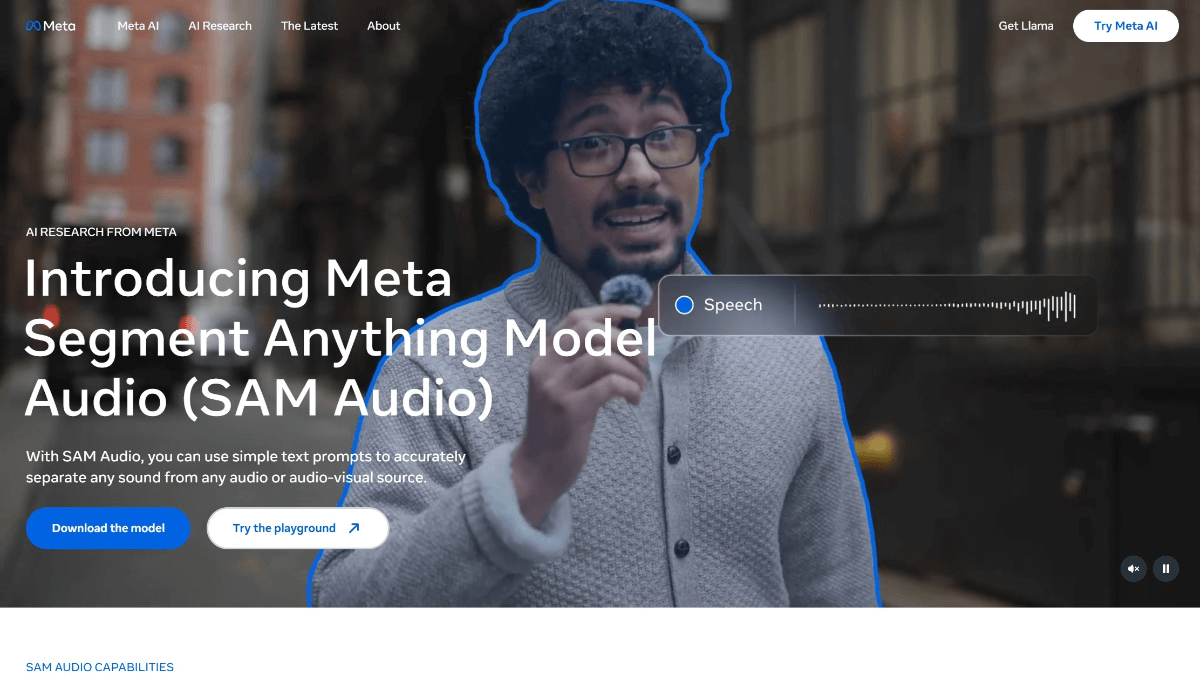
SAM 오디오는 복잡한 오디오 믹스에서 임의의 대상 사운드를 정확하게 분리하기 위해 메타에서 도입한 오픈 소스 멀티모달 오디오 세분화 모델입니다. 텍스트, 시각 및 시간적 차원의 단서를 결합하여 오디오 편집, 노이즈 제거, 사운드 추출 등의 작업을 유연하고 효율적으로 처리할 수 있습니다.
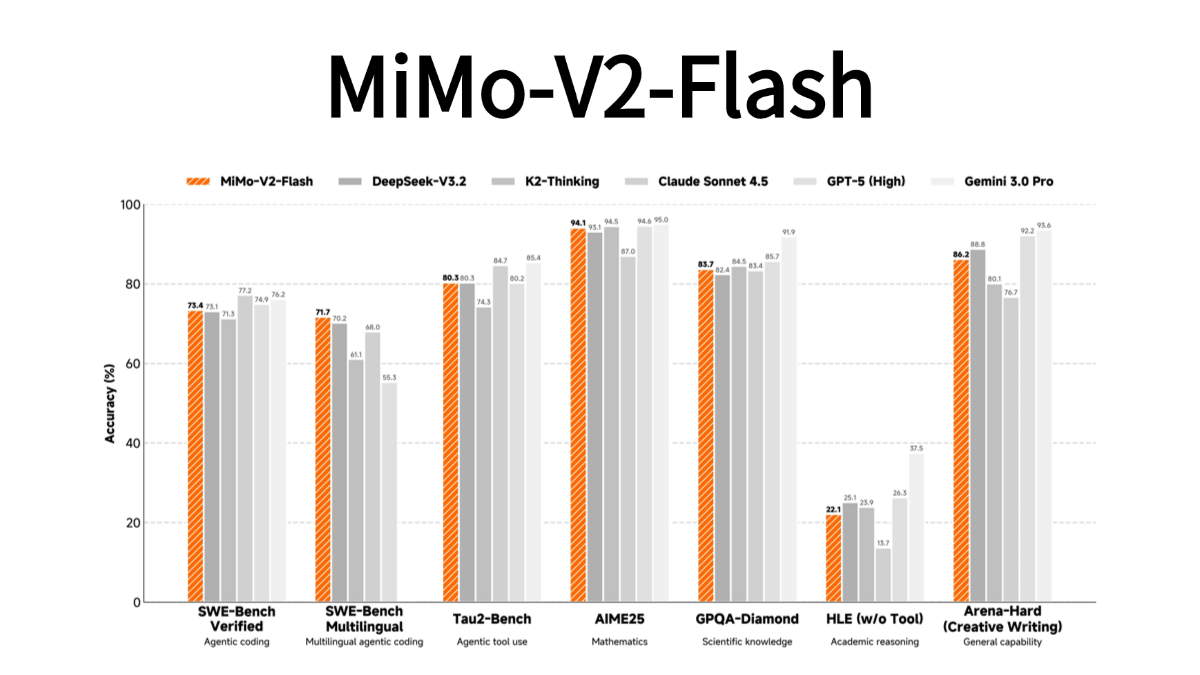
MiMo-V2-Flash는 효율적인 추론과 지능형 신체 애플리케이션에 초점을 맞춘 총 파라미터 3090억 개와 활성 파라미터 150억 개를 갖춘 Xiaomi에서 출시한 오픈 소스 MoE 아키텍처 대형 모델입니다. 이 모델은 하이브리드 주의 집중 아키텍처와 다중 단어 메타 예측 기술을 채택하여 초당 150 토큰의 추론 속도로 ...
완무브는 알리 통이 연구소, 칭화대학교 및 기타 기관이 공동 개발한 오픈 소스 AI 비디오 생성 프레임워크로, 정밀한 모션 제어 기술을 통한 고품질 비디오 합성에 중점을 두고 있습니다. 핵심 기술은 기존 이미지 대 비디오 모델에 포인트 수준의 모션 제어를 원활하게 추가 할 수있는 "잠재적 궤적 안내"입니다 ...
바나나 슬라이드는 자연어 명령을 사용해 전문적인 프레젠테이션을 빠르게 만들 수 있도록 지원하는 나노 바나나 프로 AI 모델을 기반으로 하는 오픈 소스 지능형 PPT 생성기입니다. 사용자가 주제를 한 문장(예: "인간이 생태계에 미치는 영향")으로 설명할 수 있으며, 이는 스스로 할 수 있습니다.
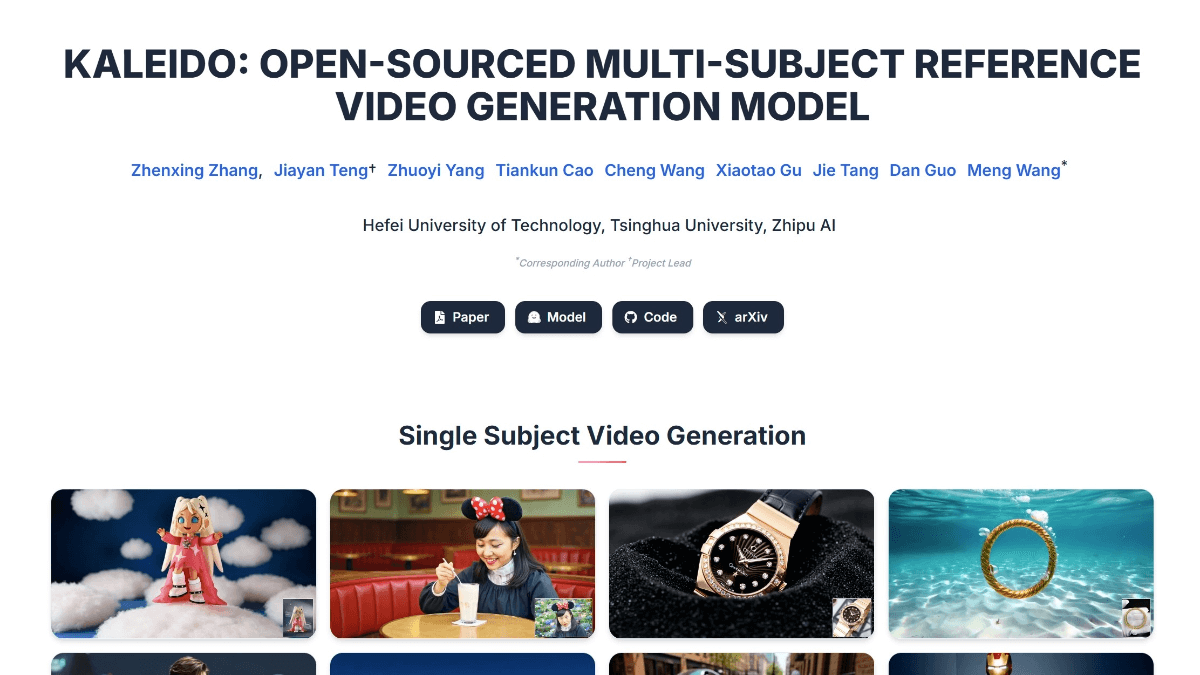
칼레이도는 허페이 공과대학교, 칭화대학교, 스마트 스펙트럼 AI가 공동 개발한 오픈 소스 다중 피사체 참조 비디오 생성 모델입니다. 여러 참조 이미지를 통해 피사체 일관된 비디오를 생성하여 다중 피사체 일관성 및 배경 분리에서 기존 모델의 결함을 해결합니다.Kaleido는 특수한 데이터를 통해 비디오를 생성합니다.
Paper2Slides는 홍콩대학교 데이터 인텔리전스 연구소의 오픈 소스 AI 도구로, 클릭 한 번으로 학술 논문을 전문적인 슬라이드나 포스터로 변환해 줍니다. 네트워크 정보에 의존하지 않고 문서 내용을 직접 구문 분석하는 RAG(검색 증강 생성) 기술을 사용하여 생성된 PPT가 원본과 매우 일치하도록 보장합니다.
리얼비디오는 스마트 스펙트럼 AI의 오픈소스 실시간 스트리밍 비디오 생성 시스템으로, 2~3초 안에 자연스럽고 부드러운 비디오 응답을 빠르게 생성할 수 있습니다. 사용자가 사진을 업로드하고 텍스트를 입력하기만 하면 시스템이 해당 음성과 영상을 생성하여 AI 캐릭터와 실시간으로 대화할 수 있습니다...
DeepSearchQA는 복잡한 다단계 쿼리 작업에서 지능의 성능을 평가하기 위해 설계된 Google의 오픈 소스 AI 연구 에이전트 테스트 벤치마크입니다. 17개 도메인을 포괄하는 900개의 수작업으로 설계된 "인과 관계 체인" 작업으로 구성되어 있으며, AI가 인간 연구원처럼 행동하고 다단계 작업을 수행하도록 요구합니다.
Claude-Mem은 세션 전반에 걸친 AI의 메모리 손실 문제를 해결하는 Claude Code용 오픈 소스 플러그인입니다. 이 플러그인은 도구의 관찰 사용을 자동으로 캡처하고, 시맨틱 요약을 생성하고, 후속 세션에 관련 컨텍스트를 삽입하여 Claude를 지원합니다....
KoalaQA는 Chaitin 팀이 개발한 오픈소스 지능형 애프터서비스 시스템입니다. AI 모델을 기반으로 AI 고객 서비스, AI 검색 및 지식 기반 관리 기능을 제공하여 기업이 지능형 Q&A 플랫폼을 신속하게 구축할 수 있도록 지원합니다. 이 시스템은 연중 무휴 실시간 응답을 지원합니다 ...
VoxCPM 1.5는 Facade Intelligence에서 출시한 오픈 소스 음성 생성 모델로, 스플리터 없이 텍스트 음성 변환(TTS) 기술을 기반으로 몇 가지 혁신과 개선 사항을 적용했습니다. 엔드 투 엔드 확산 자동 회귀 아키텍처를 채택하여 텍스트에서 직접 연속 음성 파형을 생성하므로 기존 세분화 방법의 한계를 피할 수 있습니다....
미스트랄 바이브는 코드 검색, 파일 조작, 버전 관리 및 기타 작업을 완료하기 위해 자연어 상호 작용을 지원하는 Devstral 모델을 기반으로 개발된 미스트랄 AI의 오픈 소스 명령줄 코딩 어시스턴트입니다. 기호를 통해 프로젝트 구조와 Git 상태를 자동으로 스캔할 수 있습니다....
GLM-TTS는 강력한 음성 합성 기능을 갖춘 오픈 소스 산업 등급 음성 합성 시스템입니다. 2단계 생성 아키텍처를 채택하여 첫 번째 단계에서는 텍스트를 음성 토큰 시퀀스로 변환하고, 두 번째 단계에서는 토큰 시퀀스를 고품질 오디오로 변환합니다. 이 시스템은 3초의 음성 샘플만 지원하여 사운드를 완성할 수 있습니다.
GLM-ASR은 스마트 스펙트럼 AI가 오픈소스화한 고성능 음성 인식 모델 제품군으로, 클라우드 기반 모델인 GLM-ASR-2512와 오픈소스 엔드사이드 모델인 GLM-ASR-Nano-2512를 포함합니다.GLM-ASR-2512는 세계 최고의 클라우드 기반 음성 인식 모델로, 여러 개의 ...
OpenAutoGLM은 다중 모드 인식을 통해 휴대폰 화면의 내용을 이해하고 사용자가 지정한 작업을 완료하기 위해 작업 흐름을 자동으로 생성 할 수있는 "휴대폰 사용"기능을 갖춘 오픈 소스 지능형 신체 모델입니다. 사용자는 "근처 훠궈를 검색하려면 메이투안을 열어..."와 같이 자연어를 사용하여 요구 사항을 설명하기만 하면 됩니다.
SurfSense는 오픈 소스 AI 리서치 및 지식 관리 도구입니다. 고도로 사용자 정의가 가능하며 검색 엔진, Slack, Jira, Notion, YouTube, GitHub 및 기타 여러 외부 데이터 소스에 연결하여 사용자가 정보를 쉽게 통합할 수 있습니다. 사용자는 다양한 자료를 업로드할 수 있습니다.
GLM-4.6V는 스마트 스펙트럼 AI에서 오픈소스화한 멀티모달 대규모 언어 모델 시리즈로, 클라우드 및 고성능 클러스터 시나리오를 위한 기본 버전인 GLM-4.6V(106B-A12B)와 혼합 전문가(MoE) 아키텍처, 총 약 106억 개의 레퍼런스, 활성화... 등 두 가지 버전이 있습니다.
InkSight는 종이 필기 노트를 편집 가능한 디지털 잉크 파일(예: SVG 형식)로 변환하는 Google의 오픈 소스 AI 필기 인식 도구입니다. 기존 OCR과 달리 텍스트 콘텐츠를 인식하고 필기 스타일, 단락 구조, 주요 표시를 복원하며 다국어 처리를 지원할 수 있습니다.










![FLUX.2 [klein] - Black Forest Labs 开源的轻量级图像生成与编辑模型](https://aisharenet.com/wp-content/uploads/2026/01/1768710007-1768710007-FLUX.2-klein.png)