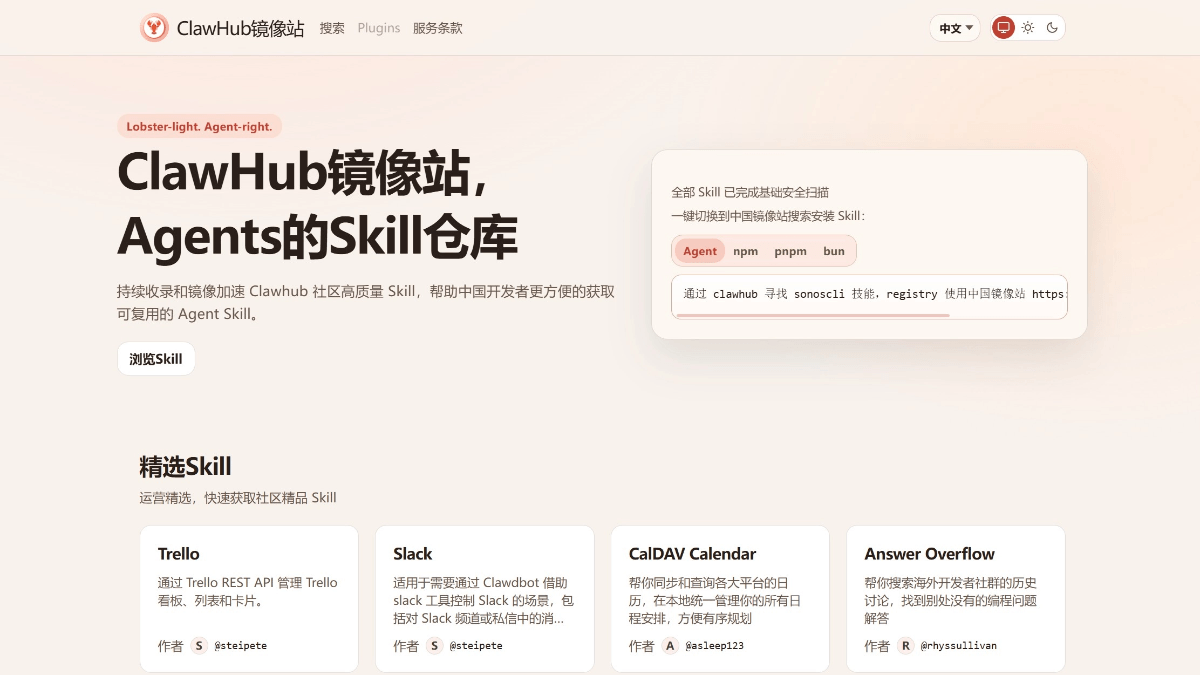
메소-(화학)ClawHub中国镜像站 - OpenClaw官方推出的技能市场本地化站点ClawHub中国镜像站是OpenClaw官方推出的技能市场本地化站点,是字节跳动BytePlus及火山引擎提供基础设施支持。镜像站专为解决国内开发者访问原站速度慢、API受限等痛点而设,提供完整中文...최신 AI 리소스2 일 전04.8K
메소-(화학)Wan2.7-Video - 阿里通义实验室推出的新一代 AI 视频生成模型系列Wan2.7-Video 是阿里通义实验室推出的新一代 AI 视频生成模型系列,由文生视频(Wan2.7-t2v)、图生视频(Wan2.7-i2v)、参考生视频(Wan2.7-r2v)和视频编辑(Wa...최신 AI 리소스2 일 전04K
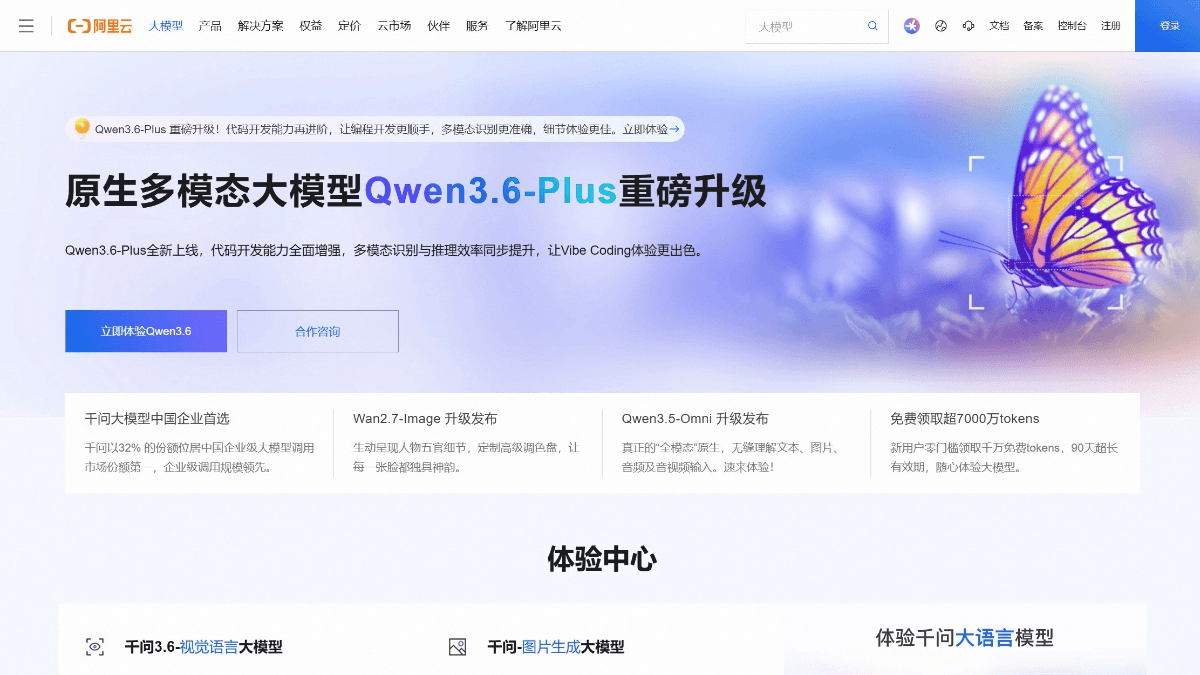
Qwen3.6-Plus - 阿里通义推出的新一代原生多模态大模型Qwen3.6-Plus是阿里发布新一代大语言模型,是千问3.6系列的首款模型,定位为企业级Agentic AI编程利器。相比3.5版本,模型在编程能力、智能体Agent能力和多模态推理上实现全面跃升...최신 AI 리소스4일 전07.3K
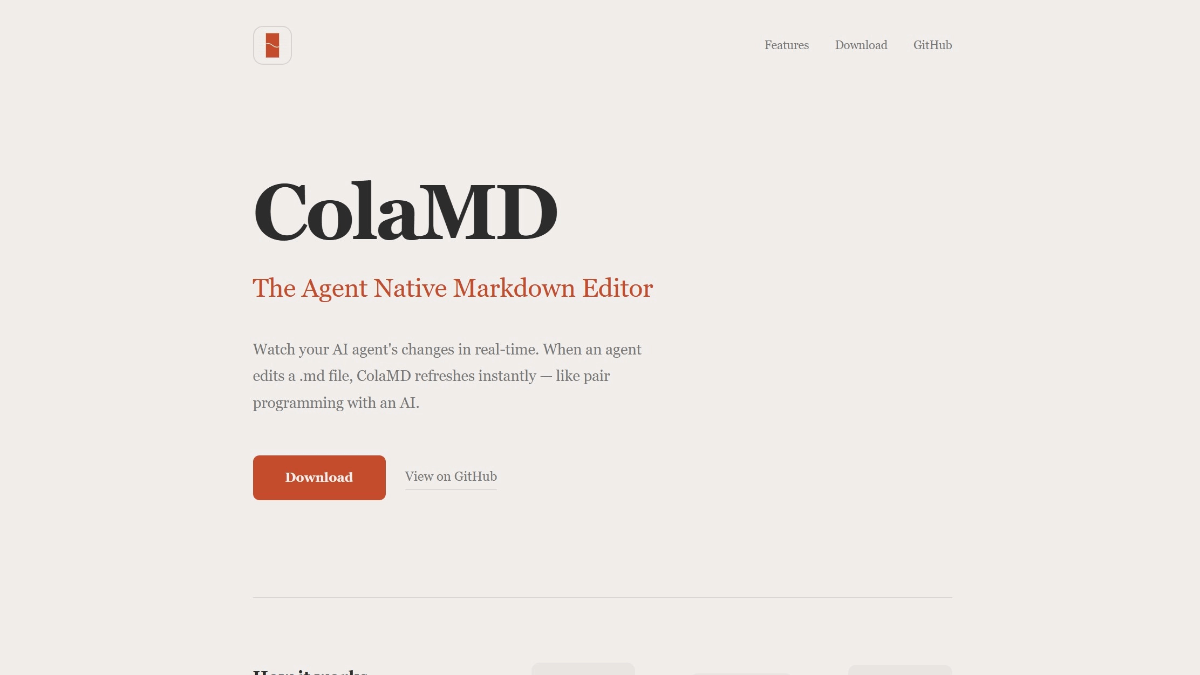
ColaMD - 专为 AI Agent 时代设计的开源 Markdown 编辑器ColaMD 是专为 AI Agent 时代设计的开源 Markdown 编辑器,采用 MIT 协议开源,支持 macOS、Windows 和 Linux 三大平台。解决了传统编辑器(如 Typora...최신 AI 리소스4일 전05.1K
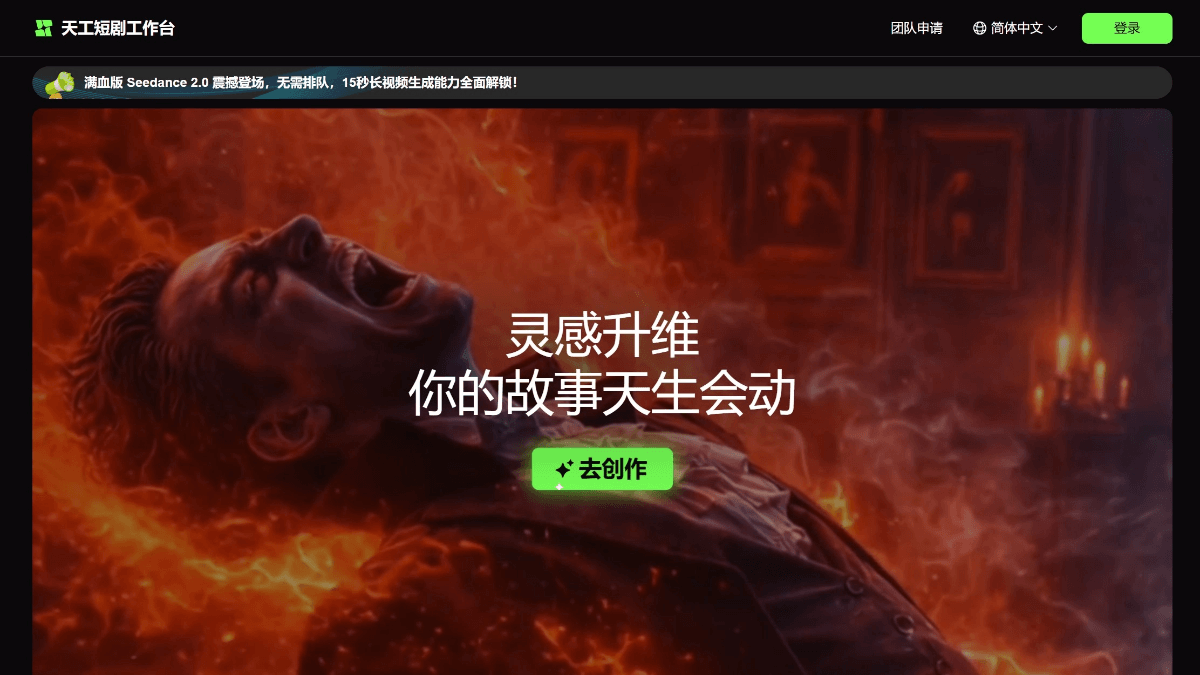
天工短剧工作台 - 天工AI推出的AI短剧工业化创作平台天工短剧工作台是昆仑万维天工AI团队推出的AI短剧工业化创作平台,主打"Agent驱动内容创作流程自动化"。平台整合Seedance、SkyReels、可灵、Vidu四大视频模型,通过资产提取、导演...최신 AI 리소스5일 전07.5K
Gemma 4 - 谷歌DeepMind发布的第四代开源大语言模型系列Gemma 4是谷歌DeepMind发布的第四代开源大语言模型系列,属于Gemma家族的最新版本。专为高级推理和智能体(agentic)工作流设计,为开发者提供高性能、低门槛的本地化AI解决方案,覆盖...최신 AI 리소스5일 전08.7K
Updream - 哔哩哔哩推出的自研AI视频创作工具Updream是哔哩哔哩推出的自研AI视频创作工具,目前采用定向邀请制内测。产品定位为UP主的"智能创意助手",通过AI技术打通创作全流程:从灵感生成、选题构思到智能剪辑、分镜处理,再到个性化技能库与...최신 AI 리소스5일 전010.1K
LongCat-AudioDiT - 美团开源的新一代高保真文本转语音模型LongCat-AudioDiT 是美团 LongCat 团队开源的新一代高保真文本转语音模型,采用 Wav-VAE 结合 Diffusion Transformer(DiT)的端到端架构,直接在波形...최신 AI 리소스5일 전07.4K
小精龙 - 学而思推出的原生学生端精准学智能体小精龙是学而思基于OpenClaw架构打造的原生学生端精准学智能体,以"大脑映射、私有财产、学习伴侣"为核心定位。首次将长期记忆、动态学情诊断、教育专属Skill链与情感陪伴系统整合为统一的学生专属A...최신 AI 리소스6일 전07.6K
Veo 3.1 Lite - Google DeepMind发布的低成本AI视频生成模型Veo 3.1 Lite是Google DeepMind发布的低成本AI视频生成模型,定位为Veo系列中最实惠的版本,专为大规模视频生成场景设计。模型支持文本和图像生成视频,输出720p和1080p分...최신 AI 리소스6일 전08.2K
GLM-5V-Turbo - 智谱发布首个原生多模态Coding基座模型GLM-5V-Turbo是智谱发布首个原生多模态Coding基座模型,专为视觉编程打造。模型从预训练阶段深度融合视觉与文本能力,能直接理解设计稿、网页截图、K线图表等视觉信息并生成可运行代码,实现"所...최신 AI 리소스6일 전07.4K
Wan2.7-Image - 阿里通义实验室推出的图像生成与编辑统一模型Wan2.7-Image 是阿里巴巴通义实验室发布的图像生成与编辑统一模型,定位为"全场景视觉创作旗舰"。模型直击AI生图领域"标准脸"审美疲劳和"色彩盲盒"痛点,采用生成与理解统一的底层架构,具备文...최신 AI 리소스6일 전08.6K
Lightpanda - 专为 AI 时代设计的开源无头浏览器Lightpanda是Lightpanda.io公司开发的开源无头浏览器,专为AI自动化和Web抓取设计。采用Zig语言从零构建,去除了图形渲染等冗余功能,核心优势是速度比Chrome快11倍,内存占...최신 AI 리소스6일 전07.2K
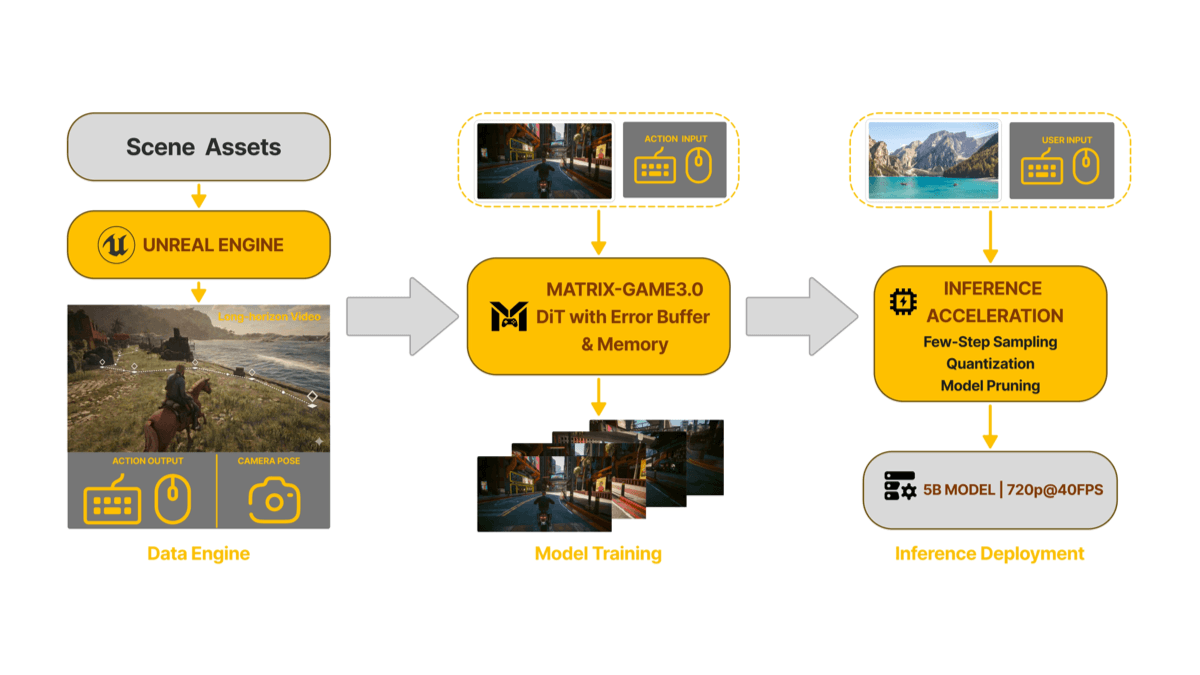
Matrix-Game 3.0 - 昆仑万维发布的实时交互式世界模型Matrix-Game 3.0是昆仑万维发布的实时交互式世界模型,属于AIGC全家桶中的三大核心模型之一。模型通过物理仿真驱动,解决了传统世界模型易失忆、环境不稳定的问题,支持720p、40fps实时...최신 AI 리소스1주일 전08.8K
Mureka V9 - 昆仑万维旗下天工 AI 推出的 AI 音乐模型Mureka V9是昆仑万维旗下天工AI在中关村论坛上发布的AI音乐模型,是Mureka系列的最新迭代版本,通过技术创新重塑数字音乐创作生态。基于Musicot(Music Chain-of-Thou...최신 AI 리소스1주일 전05.3K
LongCat-Next - 美团龙猫开源的原生多模态大模型LongCat-Next 是美团龙猫开源的原生多模态大模型,采用"下一个Token预测"(NTP)统一架构,将图像、语音与文本映射为同源离散Token,打破传统"语言为中心"的拼凑式设计。核心创新包括...최신 AI 리소스1주일 전08.2K
PixVerse V6 - 爱诗科技推出的最新一代AI视频生成模型PixVerse V6是爱诗科技推出的最新一代AI视频生成模型。在保持秒级生成速度的同时,重点优化了人物真实感、复杂运动表现、物理模拟及声画协同能力,支持最长15秒1080P视频生成。최신 AI 리소스1주일 전08K
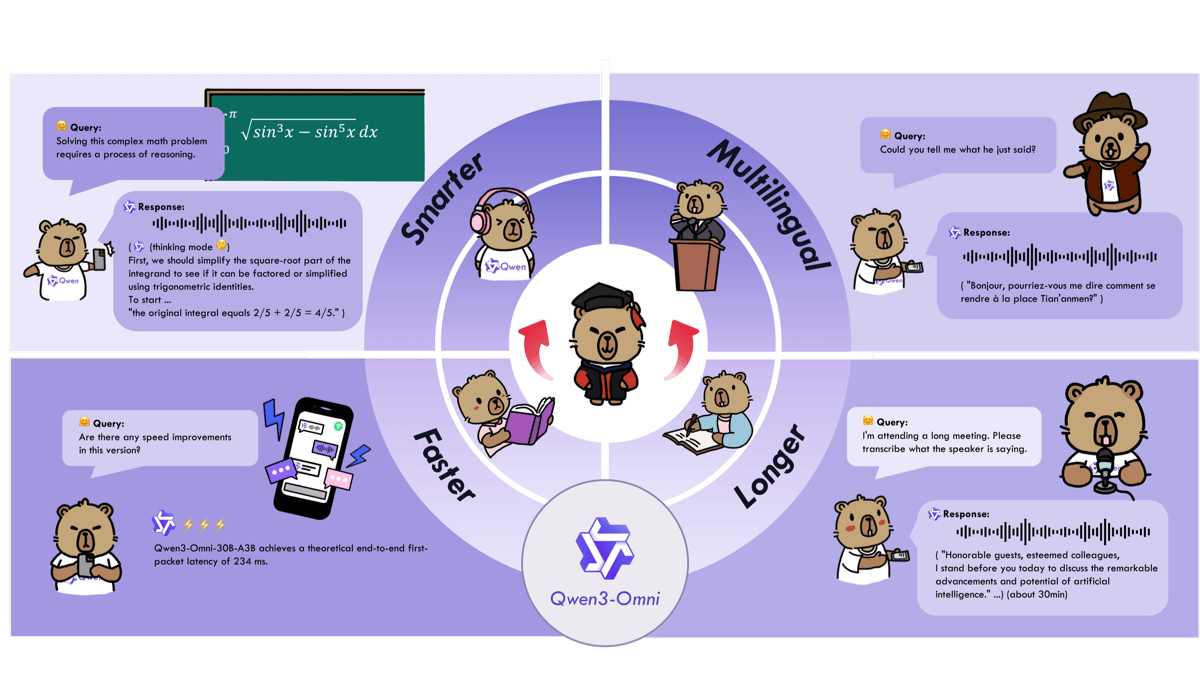
Qwen3.5-Omni - 阿里通义推出的新一代全模态大模型Qwen3.5-Omni是阿里通义推出的新一代全模态大模型,支持文本、图片、音频、音视频的原生理解与生成。采用Hybrid-Attention MoE架构,支持256K超长上下文,可处理10小时音频或...최신 AI 리소스1주일 전09.4K
移动云 MobileClaw - 中国移动推出的桌面级 AI 办公 Agent移动云 MobileClaw 是中国移动推出的桌面级AI办公智能体,央企首个深度兼容OpenClaw生态的"自研小龙虾",主打"本地优先、隐私至上"。采用一键安装开箱即用设计,适配Windows/ma...최신 AI 리소스1주일 전010.9K
Pascal Editor- 开源 AI 3D 建筑设计与可视化工具,网页端直接使用Pascal Editor 是基于浏览器的3D建筑设计与可视化工具,专为建筑师、设计师和开发者打造,支持在网页端直接进行楼层规划、空间布局和建筑场景探索。采用现代Web技术栈(React Three ...최신 AI 리소스1주일 전08K
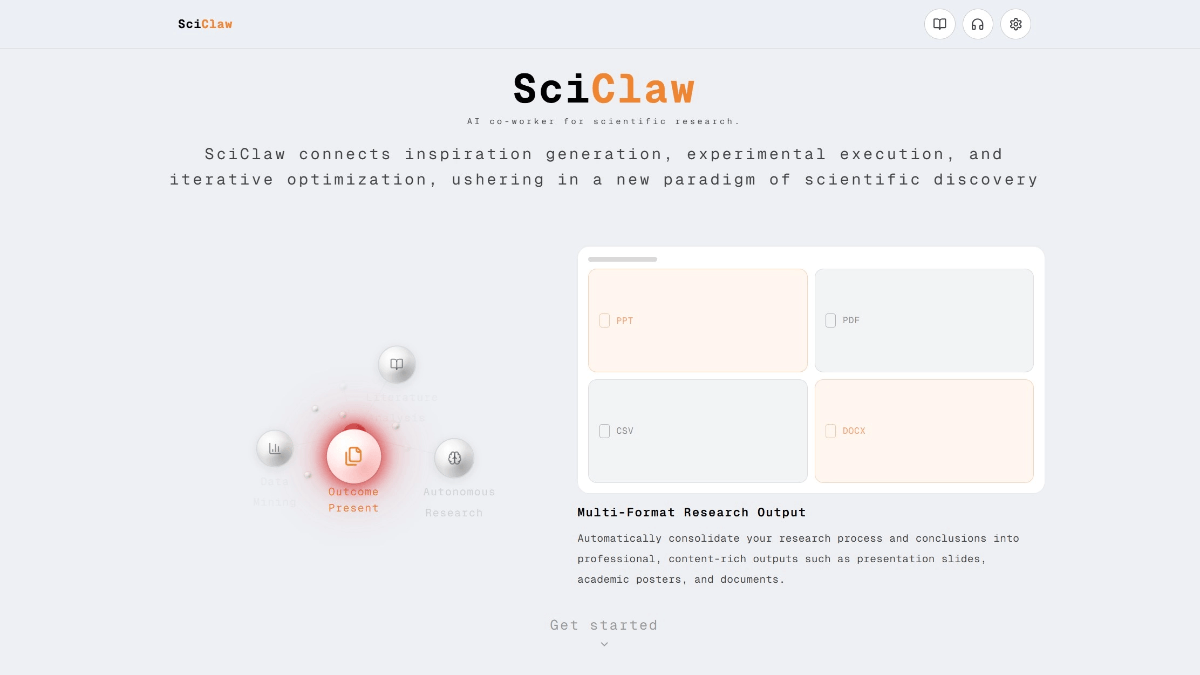
SciClaw - 面向科研人员的云端 AI Agent 协同系统SciClaw(科研龙虾) 是面向科研人员的云端 AI 协同系统,定位为"科研人的深夜搭子"。能深度分析文献、自主执行实验、自动排版生成论文/PPT/海报,记住用户电脑里的所有研究资料,将灵感、执行与...최신 AI 리소스1주일 전06.9K
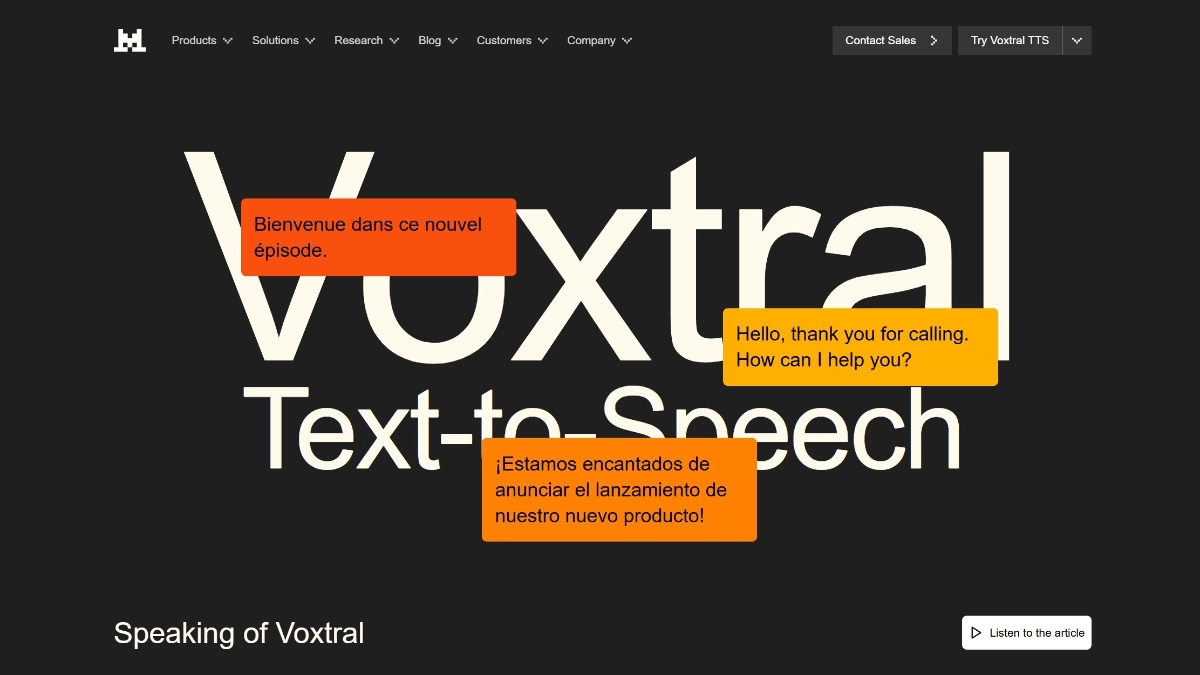
Voxtral TTS - Mistral AI推出的开源文本转语音模型Voxtral TTSoxtral TTS是法国AI公司Mistral AI发布的开源文本转语音模型,采用40亿参数轻量化架构,量化后仅需3GB内存即可在智能手机等边缘设备实时运行。模型原生支持英语...최신 AI 리소스1주일 전06.1K
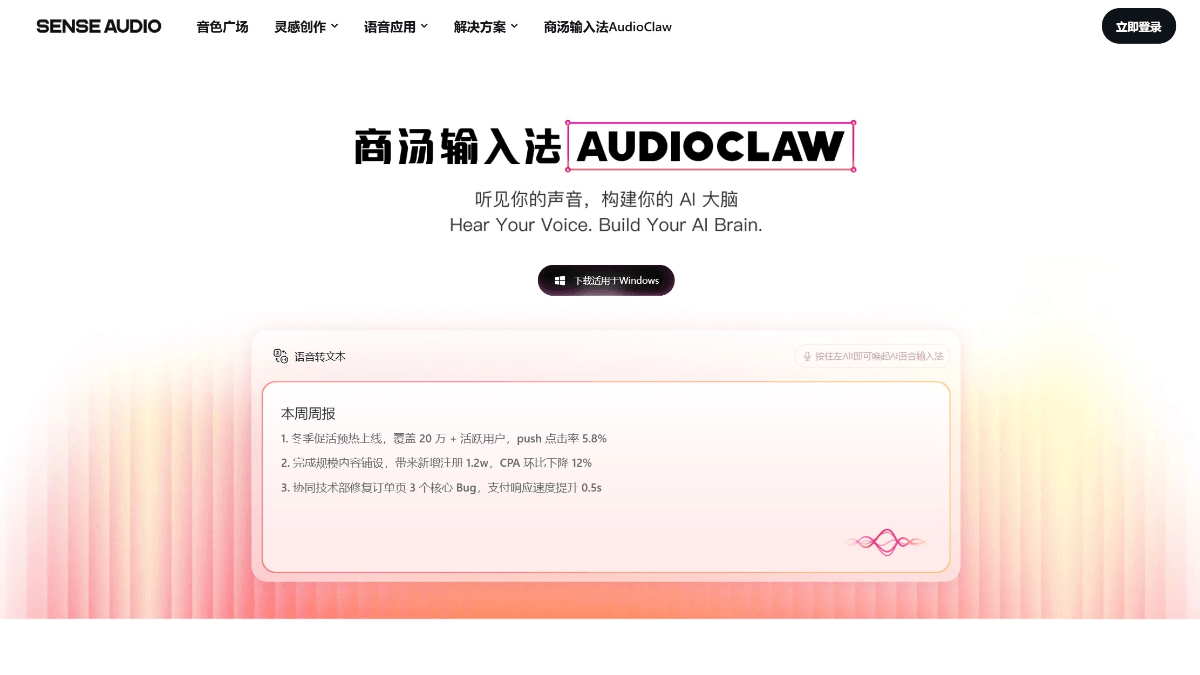
商汤输入法AudioClaw - 商汤科技推出的AI语音智能助手商汤输入法AudioClaw是商汤科技基于日日新多模态大模型打造的AI语音智能应用,深度接入OpenClaw底层能力,定位为"会听话的龙虾"智能助手。최신 AI 리소스1주일 전08.3K
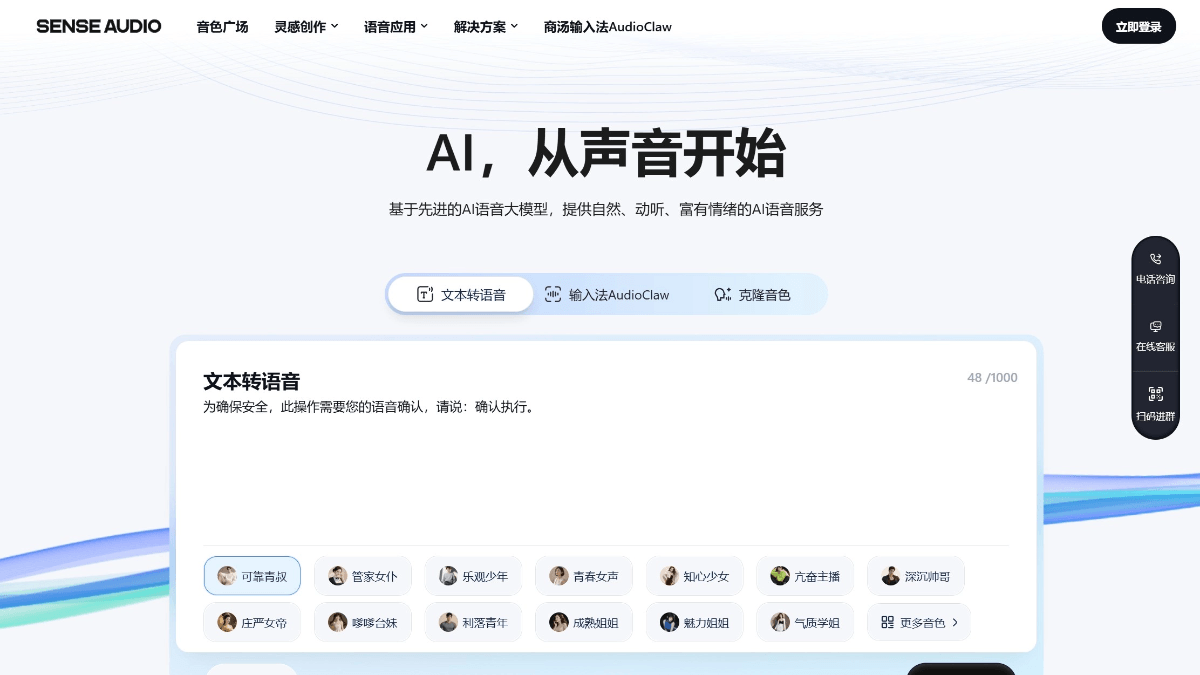
SenseAudio - 商汤科技推出的一站式 AI 语音开放平台SenseAudio 是商汤科技推出的AI语音开放平台,面向开发者与企业提供一站式语音AI解决方案。平台集成语音识别(ASR)、语音合成(TTS)、音色克隆等核心能力,语音识别覆盖20+语言并支持说话...최신 AI 리소스2 주 전08.2K
TurboQuant - Google Research 推出的突破性内存压缩算法TurboQuant 是 Google Research 推出的突破性内存压缩算法,专为解决大语言模型推理中的 KV 缓存瓶颈而设计。최신 AI 리소스2 주 전06.8K
Gemini 3.1 Flash Live - Google 推出的旗舰级实时语音模型Gemini 3.1 Flash Live 是 Google 推出的旗舰级实时语音模型,被誉为"迄今最高质量的音频和语音模型"。主打超低延迟的自然对话体验,支持 90+ 种语言的原生多模态交互,能精准...최신 AI 리소스2 주 전07.9K
Lyria 3 Pro - 谷歌推出的最先进AI音乐生成模型Lyria 3 Pro是谷歌推出的最先进的AI音乐生成模型。相比前代Lyria 3仅30秒的生成时长,Pro版本可一次性生成长达3分钟的完整音轨,精准控制前奏、主歌、副歌、桥段等歌曲结构。최신 AI 리소스2 주 전07.2K
OpenCLI - 开源 AI 命令行工具框架,任何网站变成命令行OpenCLI是开源的命令行工具框架,将网站、Electron应用和本地命令行工具统一转化为可通过命令行操作的接口,将网站(如B站、知乎、Twitter等)和Electron应用(如Cursor、No...최신 AI 리소스2 주 전014.1K
TuyaClaw - 涂鸦智能推出的数字与物理世界联动 AI AgentTuyaClaw 是涂鸦智能(Tuya Smart)推出的 AI 助理,基于 OpenClaw 架构搭建,是全球首个同时打通数字世界与物理世界的 AI Agent。与市面上仅能在屏幕内执行任务的"龙虾...최신 AI 리소스2 주 전010.1K
TypeNo - 开源 AI 语音输入工具,专为 macOS 设计TypeNo 是 marswaveai 团队开源的中文语音输入工具,专为 macOS 打造。用户只需轻点 Control 键即可录音,松手后语音会在本地实时转为文字并自动填入当前应用。최신 AI 리소스2 주 전09.1K
HiDreamClaw - 智象未来推出的多模态原生AI智能体应用HiDreamClaw 是智象未来(HiDream.ai)推出的多模态原生AI智能体应用,定位为图片与视频生成垂直领域的创作助手。目前已接入其海外平台vivago,面向创作者提供7×24小时在线服务。최신 AI 리소스2 주 전09.4K
PrismAudio - 阿里通义实验室开源的视频生成音频框架PrismAudio 是阿里通义实验室推出的视频生成音频框架,专注于为视频自动匹配严丝合缝的环境音效。框架创新性地引入"分解式思维链"(CoT)机制,让模型在生成音频前先分析视频内容、声音时序、音质特...최신 AI 리소스2 주 전09.2K
MAI-Image-2 - 微软推出的第二代自研图像生成模型MAI-Image-2 是微软推出的第二代自研图像生成模型,模型在权威评测平台 LMArena 中跃升至全球第三位,仅次于谷歌和 OpenAI,标志着微软在图像生成领域实现从"追赶者"到"第一梯队"的...최신 AI 리소스2 주 전010.3K
NineClaw - 好未来推出的教师专属 AI 原生桌面超级智能体NineClaw(九章龙虾) 是好未来(TAL)推出的行业首款教师专属AI原生桌面超级智能体,昵称"九龙"。深度融合好未来20年教研积累与海量题库资源,采用本地化运行架构,支持Windows和MacO...최신 AI 리소스2 주 전012.2K
EdgeClaw - 面壁智能联合清华等开源的端云协同 AI 智能体框架EdgeClaw 是面壁智能联合清华大学等机构开源的端云协同 AI 智能体框架,主打安全可控与本地部署。首创三层数据安全协议(S1/S2/S3),通过规则检测器与本地 LLM 语义检测器实时分类请求敏...최신 AI 리소스2 주 전011.9K
Qwen3.5-Max-Preview - 阿里通义千问推出的旗舰大模型预览版Qwen3.5-Max-Preview 是阿里通义千问团队推出的旗舰大模型预览版,在 LM Arena 国际大模型竞技场以1464分跻身全球前五、国内第一,标志着国产大模型首次进入全球第一梯队。최신 AI 리소스2 주 전010K
微信ClawBot - 微信官方推出连接 OpenClaw 的 AI 插件微信ClawBot是微信官方推出的AI插件,核心定位是连接OpenClaw(开源AI智能体框架)与微信的消息通道。用户只需在部署OpenClaw的设备上执行一条命令完成安装,可通过微信聊天界面直接发送...최신 AI 리소스2 주 전015.3K
YouClaw - Chat2DB 开源的极简 AI Agent 桌面客户端YouClaw 是 Chat2DB 团队推出的极简 AI Agent 桌面客户端,主打"最懂你的 AI 个人助理"定位。基于 Tauri 2 + React 构建,安装包仅约 30MB,支持 Wind...최신 AI 리소스2 주 전014.3K
Xiaomi MiMo-V2-Omni - 小米推出的Agent全模态基座模型Xiaomi MiMo-V2-Omni 是小米推出的面向Agent时代的全模态基座模型,专为现实世界中复杂的多模态交互与执行场景打造。模型从底层构建了融合文本、视觉、语音的统一架构,将"感知"与"行动...최신 AI 리소스2 주 전09.4K
Vidu Claw - Vidu AI 推出的 AI 视频创意AgentVidu Claw(代号"V龙")是生数科技旗下 Vidu AI 平台推出的 AI 创意智能体,定位为"你的第一个 AI 创意员工"。基于 Vidu 视频大模型构建,能自动完成从创意理解、脚本撰写、分...최신 AI 리소스2 주 전09.7K
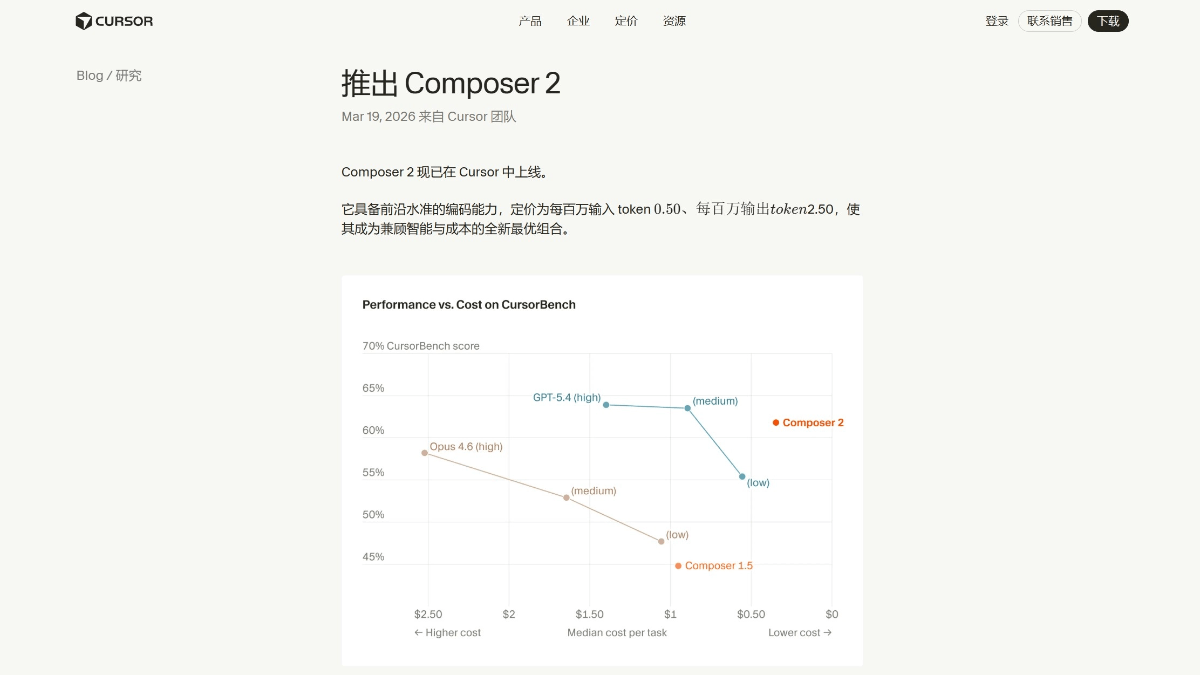
Composer 2 - Cursor 推出的专有代码大模型Composer 2 是 AI 编程平台 Cursor 推出的专有代码大模型,主打"长周期智能体编程"。模型支持 20 万 Token 上下文窗口,能自主处理包含数百个操作的复杂开发任务,在 Term...최신 AI 리소스2 주 전07.6K
MiMo-V2-TTS - 小米推出的自研语音合成大模型MiMo-V2-TTS是小米推出的自研语音合成大模型,与MiMo-V2-Pro、MiMo-V2-Omni共同构成小米面向"Agent时代"的三大基础模型矩阵。模型基于自研Audio Tokenizer...최신 AI 리소스2 주 전010.5K
MiniMax M2.7 - MiniMax 推出的旗舰级 Agent 推理大模型MiniMax M2.7 是 MiniMax 推出的旗舰级 Agent 推理大模型,主打"模型自我进化"能力。模型通过构建 Agent Harness 体系,深度参与自身训练与优化流程,在部分研发场景...최신 AI 리소스3주 전012.3K
Xiaomi MiMo-V2-Pro - 小米推出的旗舰级MoE大模型Xiaomi MiMo-V2-Pro 是小米推出的旗舰级MoE大模型,采用1万亿总参数、420亿激活参数的混合专家架构,支持最高100万token超长上下文。模型以代号"Hunter Alpha"匿名...최신 AI 리소스3주 전09.8K
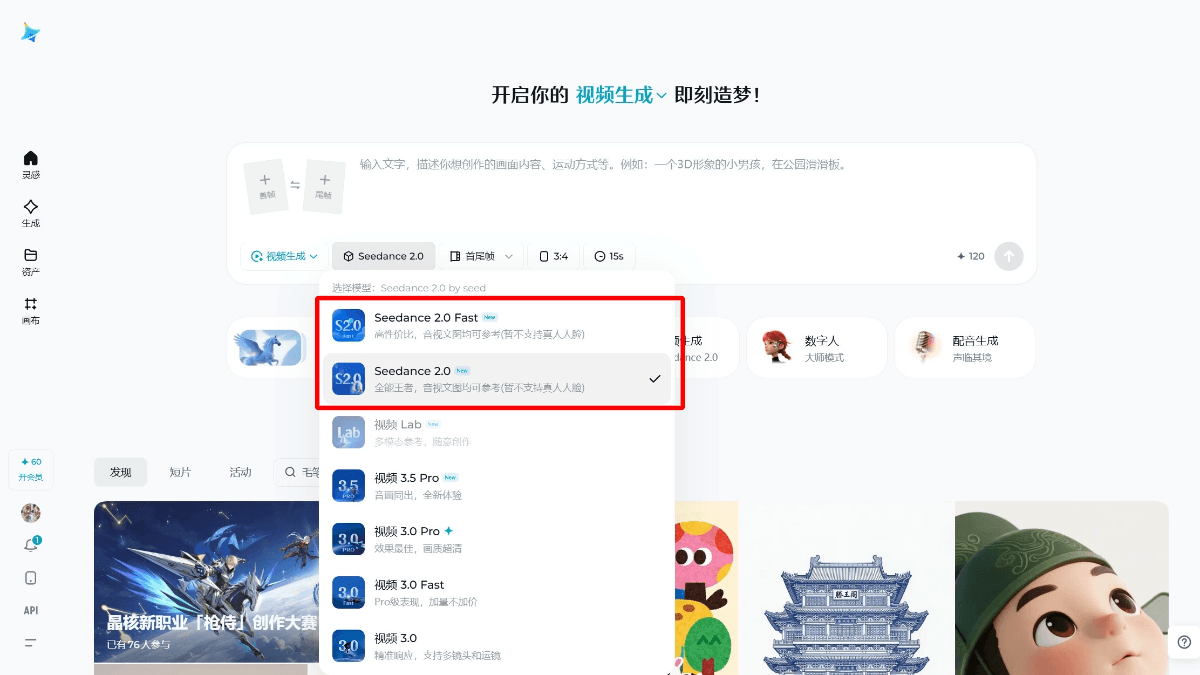
Seedance 2.0 - 字节Seed团队推出的第二代多模态AI视频生成模型Seedance 2.0 是字节跳动(TikTok母公司)Seed团队开发的第二代多模态AI视频生成模型,代表了从单纯文本/图像转视频工具向专业级电影制作平台的重大升级,支持文本、图像、视频片段和音频...최신 AI 리소스3주 전010.9K
GPT-5.4 mini - OpenAI 推出的轻量级 AI 模型GPT-5.4 mini 是 OpenAI 发布的轻量级模型,定位为"迄今能力最强的小型模型"。在保留 GPT-5.4 核心能力的同时,实现了速度提升 2 倍以上,成本大幅降低,专为对延迟敏感的高频工...최신 AI 리소스3주 전010.8K
SkyClaw - Skywork AI 推出的云端AI Agent工作空间SkyClaw 是 Skywork AI 推出的云端持久化智能工作空间,定位超越传统对话机器人的"主动执行型代理"。支持在 Slack、Discord、WhatsApp 等主流平台原生集成,能基于用户...최신 AI 리소스3주 전012.6K
Mistral Small 4 - Mistral AI 开源的多模态大模型Mistral Small 4 是 Mistral AI 开源的多模态大模型,采用 1190 亿参数 MoE 架构(每 token 激活 60 亿参数),支持 256K 超长上下文。核心突破在于三合一...최신 AI 리소스3주 전010.7K
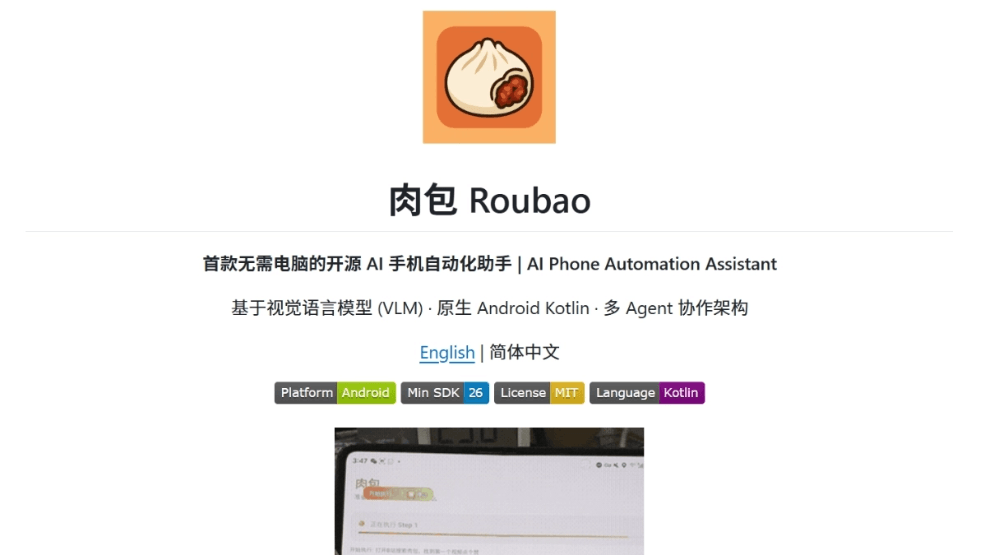
肉包 - 开源AI手机自动化助手,能看懂屏幕自动执行肉包(Roubao)是开源的AI手机助手,让用户用现有Android手机能体验类似"豆包手机"的智能自动化功能。肉包基于视觉语言模型,能看懂屏幕内容并自动执行复杂任务,从点外卖、发微信到跨App操作...최신 AI 리소스3주 전014.7K
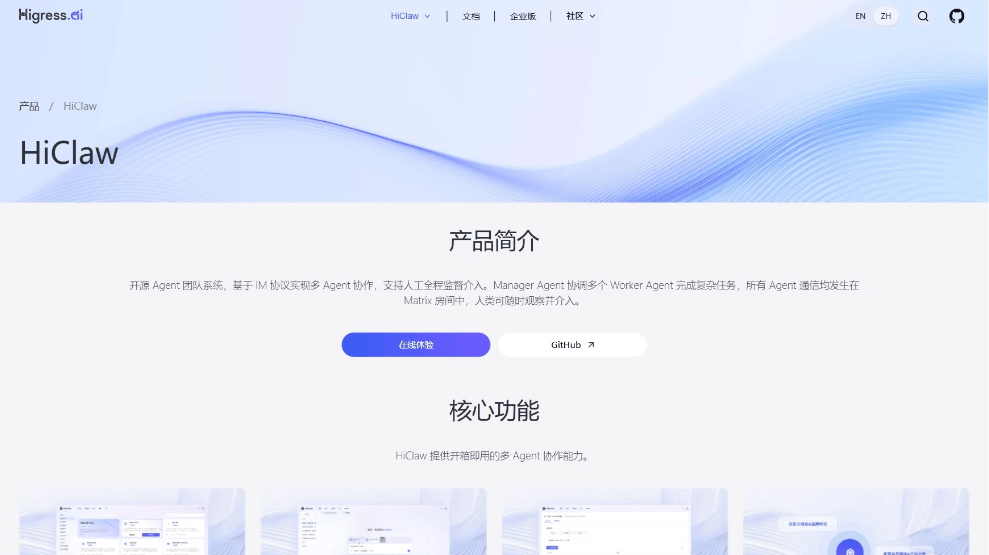
HiClaw - 阿里云开源的多智能体团队协作系统HiClaw 是阿里云开源的多 Agent 协作框架,让单个用户能像指挥团队一样调度多个 AI 员工。系统设置一位 Manager 管家负责拆解任务、分配工作,各 Worker 专精不同领域且相互隔离...최신 AI 리소스3주 전014.8K
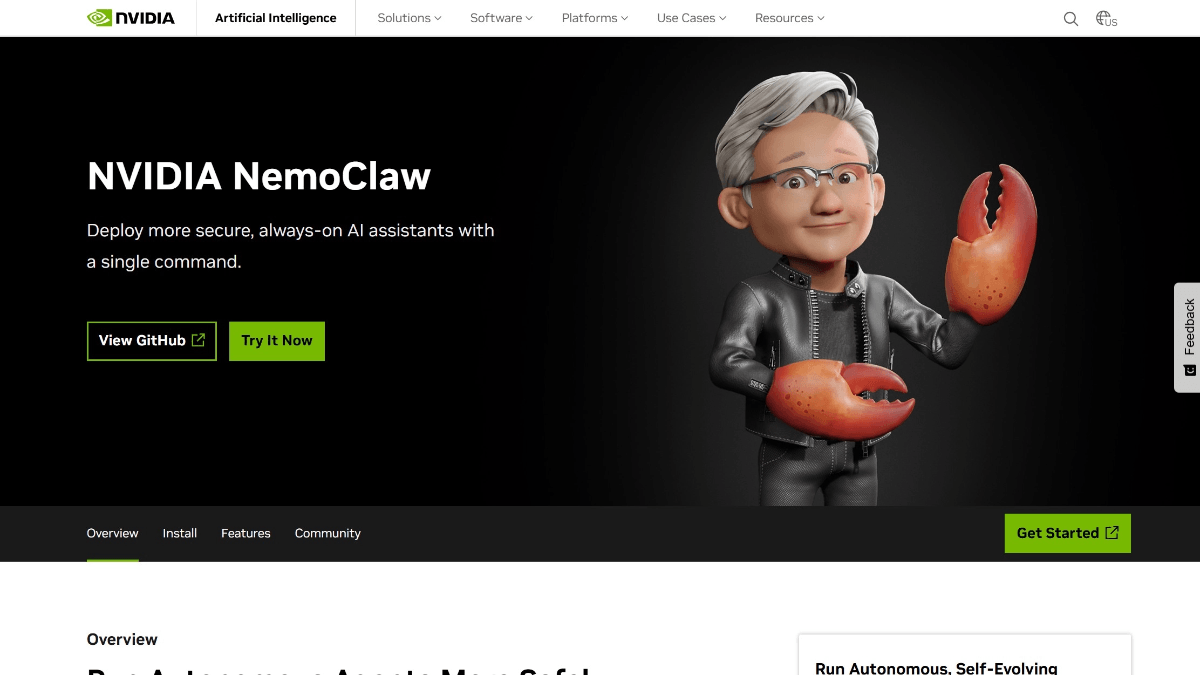
NemoClaw - NVIDIA 推出的开源企业级 AI Agent 安全增强平台NemoClaw 是 NVIDIA 推出的开源企业级 AI Agent 安全增强平台。作为 OpenClaw 的"安全插件"和运行时沙箱层,通过 OpenShell 为自主 AI 代理添加企业级的隐私...최신 AI 리소스3주 전014.6K
OpenMAIC - 清华大学开源的多智能体AI课堂系统OpenMAIC是清华大学研发的开源多智能体AI课堂系统,由教育学院与计算机系联合开发。系统基于大语言模型构建全智能辅助教学环境,支持AI生成课件、语音讲解、互动讨论及作业批改,实现全流程自动化教学。최신 AI 리소스3주 전045.9K
Clawith - DataElem 团队开源的多智能体协作平台Clawith 是 DataElem 团队开源的"OpenClaw for Teams"——面向团队的多智能体协作平台。在保留 OpenClaw 灵魂与记忆能力的基础上,升级为 Aware 自主感知系...최신 AI 리소스3주 전020.1K
Fun-CineForge - 阿里通义实验室开源的影视级配音多模态大模型Fun-CineForge 是阿里通义实验室开源的首个支持影视级多场景配音的多模态大模型,基于 CosyVoice3 打造。通过"数据+模型"一体化设计,创新性地解决音画同步、情感表达、音色一致与时间...최신 AI 리소스3주 전011.7K
MiniMax Music 2.5+ - MiniMax推出的AI音乐生成模型MiniMax Music 2.5+是MiniMax推出的AI音乐生成模型,专注器乐创作。模型精通古典管弦、电子氛围、自然声景等多元风格,擅长将东方传统乐器与西方现代编曲融合,实现跨风格创新。최신 AI 리소스3주 전010.7K
GLM-5-Turbo - 智谱 AI 推出专为 OpenClaw 场景深度优化的基座模型GLM-5-Turbo 是智谱 AI 发布的全球首款专为 OpenClaw(龙虾) 场景深度优化的基座模型,也是 GLM-5 系列的高速增强版本。模型从训练阶段就针对 Agent 任务的核心需求进行专...최신 AI 리소스3주 전014.2K
Fun-AudioGen-VD - 阿里通义实验室推出的声音设计系统Fun-AudioGen-VD 是阿里通义实验室推出的创新语音大模型,专注于声音设计与场景化音频生成。模型支持通过自然语言指令直接生成包含特定音色、情绪表达和完整听觉场景的高质量音频,无需参考音频即可...최신 AI 리소스3주 전010.7K
Gemini Embedding 2 - Google推出的首个原生五模态 Embedding 模型企业知识库管理员:需要统一检索文档、会议录音、培训视频、产品图片等多模态资料的企业用户 RAG 应用开发者:为多模态内容提供语义检索能力,提升生成质量的 AI 应用开发者 法律/医疗行业从业者:如 E...최신 AI 리소스3주 전012.6K
Nemotron 3 Super - NVIDIA开源的大语言模型,专为AI Agent推理设计Nemotron 3 Super是NVIDIA 发布的Nemotron 3 系列中目前最强大的开源权重 AI 模型。模型采用 1200 亿参数的混合专家(MoE)架构,推理时仅激活 120 亿参数,实...최신 AI 리소스3주 전08.3K
Paperclip - 开源的AI Agent编排平台,管理和协调多个AI智能体Paperclip是开源的AI代理编排平台,定位为“零人工公司操作系统”,用于管理和协调多个AI代理(如OpenClaw、Claude Code等)协同工作。提供组织架构、目标对齐、预算控制、任务追踪...최신 AI 리소스3주 전014.5K
AlphaClaw - 熵简科技推出的金融投研 AI Agent 工具AlphaClaw 是熵简科技推出的金融投研 AI 工具,搭载于 AlphaEngine 平台,被誉为"投研小龙虾"。完成了从"有问必答的 AI 助手"向"自主执行的 AI 分析师"的进化,能独立跑通...최신 AI 리소스3주 전012.6K
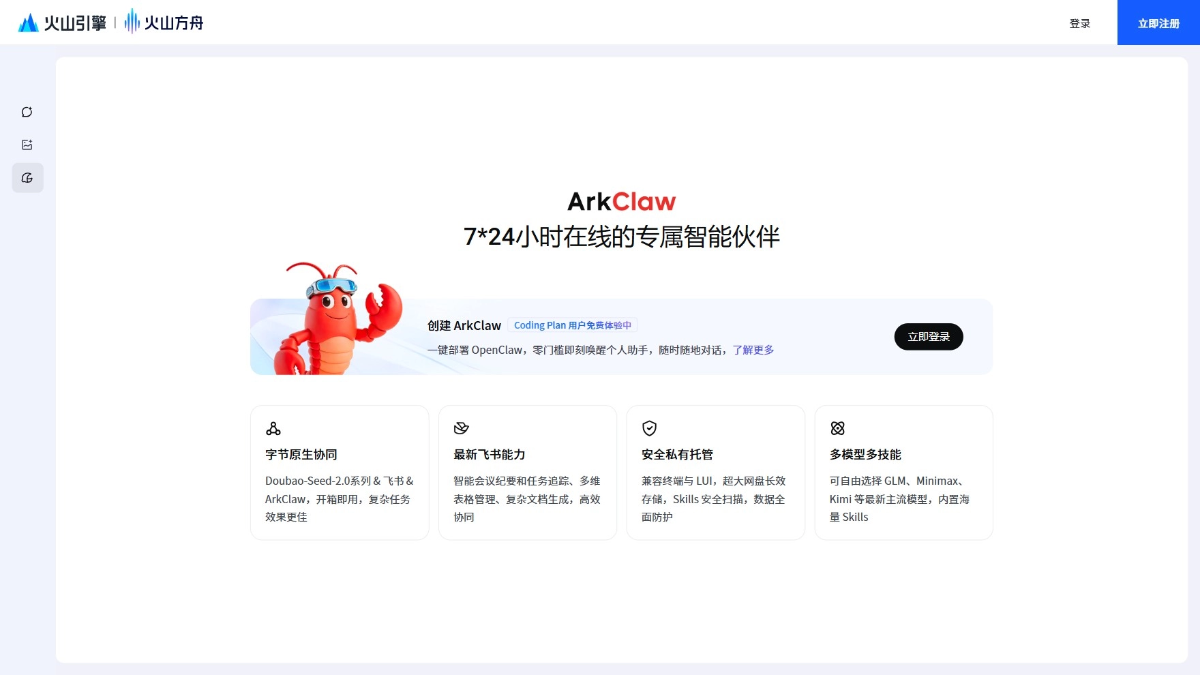
ArkClaw - 火山引擎推出的云端AI助手,零门槛部署OpenClawArkClaw是火山引擎推出的云端智能助手平台,基于OpenClaw架构构建,让用户无需繁琐配置可快速部署专属AI Agent。최신 AI 리소스3주 전016.4K
GPT-5.3 Instant - OpenAI推出的GPT-5系列快速响应版本模型GPT-5.3 Instant 是 OpenAI 发布的 ChatGPT 主力模型升级版,主打"体验优化"而非参数堆叠。精准解决了用户长期诟病的"说教感"和机械回复问题,对话语气更自然直接,大幅减少了...최신 AI 리소스3주 전09.1K
Fun-CosyVoice3.5 - 阿里通义实验室推出的第三代语音合成大模型Fun-CosyVoice3.5是阿里通义实验室推出的第三代语音合成大模型,主打"自然语言指令控制"能力,用户可直接用口语化描述(如"语气坚定一点""语速慢一点")来调节合成语音的情绪、语速和风格,无...최신 AI 리소스3주 전08.4K
Gemini 3.1 Flash-Lite - Google推出的最轻量、最具性价比的模型Gemini 3.1 Flash-Lite 是 Google 发布的 Gemini 3 系列中最轻量、最具性价比的模型,主打极致速度与低成本。模型从 Gemini 3 Pro 蒸馏而来,输入价格仅 ...최신 AI 리소스4주 전017.6K
FireRed-OCR - 小红书团队开源的端到端文档解析模型FireRed-OCR 是小红书 Super Intelligence 团队开源的端到端文档解析模型,基于 Qwen3-VL-2B 架构打造,仅用 2B 参数就在 OmniDocBench v1.5 ...최신 AI 리소스4주 전015.9K
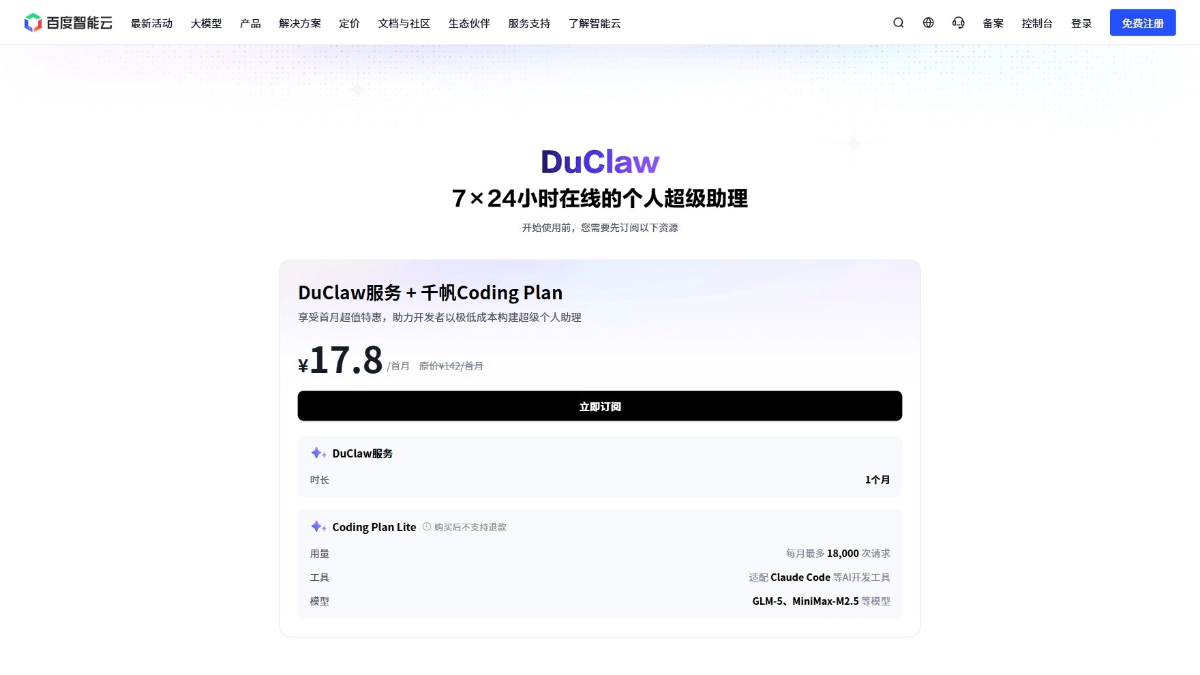
DuClaw - 百度智能云推出的OpenClaw云部署服务DuClaw是百度智能云推出的托管式OpenClaw服务,专为无技术背景用户设计。DuClaw免除了服务器配置、镜像选择和API密钥管理的繁琐步骤,用户订阅后可在网页端直接调用完整的智能体功能。최신 AI 리소스4주 전013.8K
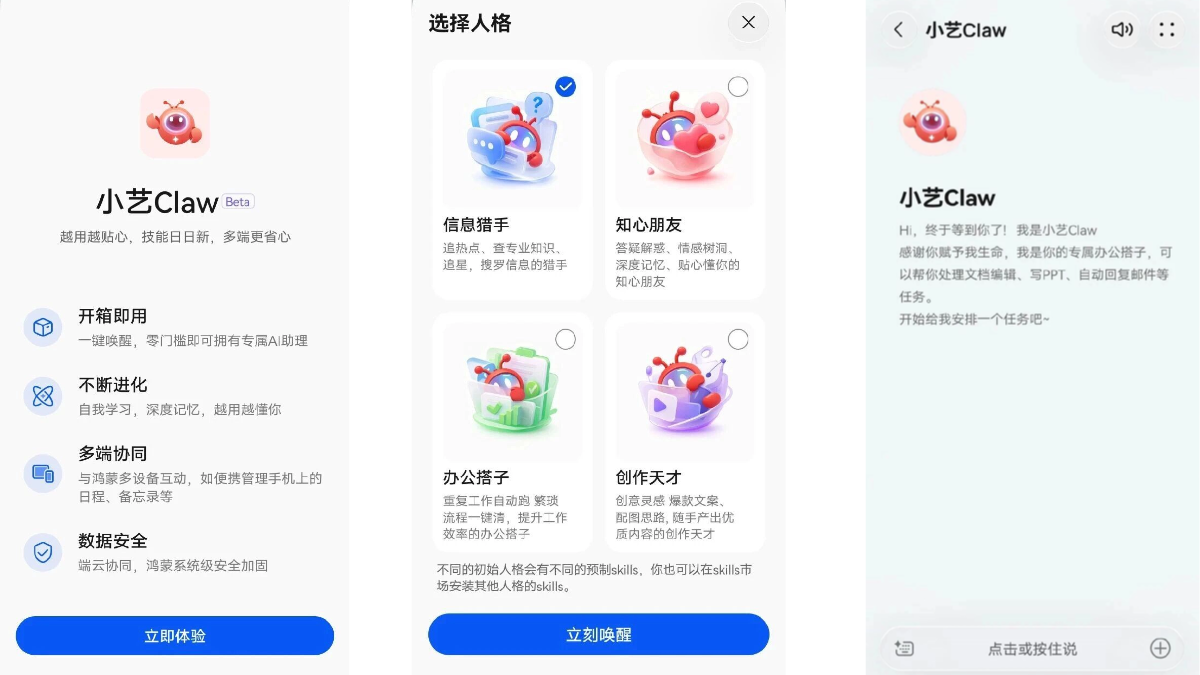
小艺Claw - 华为推出的个人手机AI助理,一键接入OpenClaw小艺Claw是华为基于OpenClaw开源框架推出的AI智能体,集成于小艺App中。小艺Claw打破传统语音助手"被动应答"的交互逻辑,具备自主规划与任务执行能力,可独立完成办公文档处理、信息检索、服...최신 AI 리소스4주 전015.5K
GPT‑5.4 - OpenAI推出的全能旗舰AI模型GPT-5.4是OpenAI推出的旗舰AI模型,专为复杂专业场景设计。模型突破性融合推理、编程、原生计算机操控与深度搜索四大能力,在OSWorld测试中首次超越人类操作水平,知识工作任务表现达专家级标...최신 AI 리소스4주 전010K
Mobile-Agent-v3.5 - 阿里通义开源的原生GUI Agent框架Mobile-Agent-v3.5是阿里巴巴通义实验室开源的新一代多平台GUI Agent框架,支持桌面、手机、浏览器三大平台,可跨Android、Ubuntu、macOS、Windows实现自动化操...최신 AI 리소스4주 전016.2K
gws - 谷歌开源的CLI工具,支持接入各类AI Agent系统gws 是 Google Workspace 团队推出的命令行工具,采用 Rust 构建。工具支持运行时动态生成命令,通过读取 Google Discovery Service 实时适配所有 Work...최신 AI 리소스4주 전011.9K
HY-WU - 腾讯混元开源的实时神经参数生成框架HY-WU(混元无相)是腾讯混元推出的功能性神经记忆框架,能在AI推理时即时创建个性化适配参数。框架为每个任务"临时定制"专属技能,无需重新训练模型。최신 AI 리소스4주 전013.1K
MiroFish - 开源的AI预测引擎,智能体进行自由交互与社会演化MiroFish是中科大20岁学生BaiFu开源的AI预测引擎,基于多智能体技术,能从新闻、小说等种子信息自动构建高保真平行数字世界。최신 AI 리소스4주 전016.2K
ClawFeed - 开源AI新闻摘要工具,一站式聚合任意网站内容ClawFeed是开发者Kevin He推出的开源AI新闻摘要工具,解决信息过载问题。通过聚合Twitter、RSS、GitHub等多平台信息源,利用AI自动生成4小时、每日、每周和每月的结构化摘要...최신 AI 리소스1개월 전032.7K
FireRed-Image-Edit - 小红书团队开源的通用图像编辑模型FireRed-Image-Edit 是小红书 Super Intelligence 团队开源的通用图像编辑模型,基于扩散 Transformer 架构,在 GEdit、ImgEdit 等多个权威评测...최신 AI 리소스1개월 전036.7K
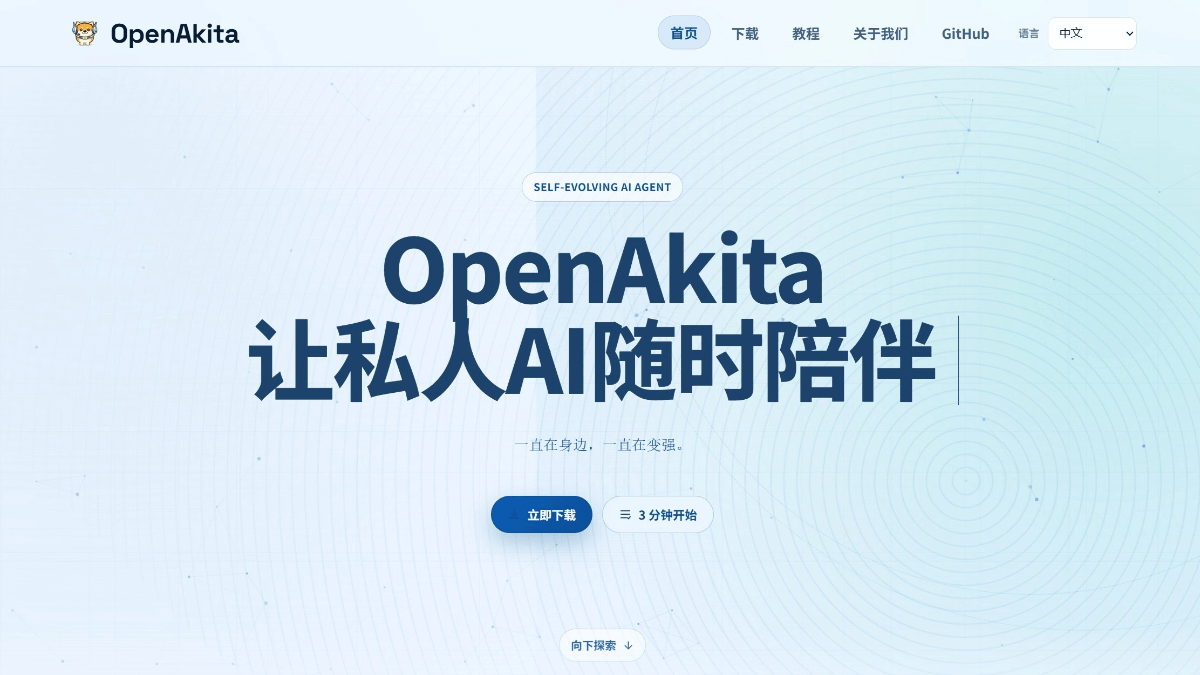
OpenAkita - 开源的自进化AI助手框架,多平台无缝协作OpenAkita是开源的自进化AI助手框架,提供智能、灵活且易于使用的AI辅助工具。每日自动执行内存整合、错误自检与修复、任务复盘,遇到卡壳时自动生成新技能并安装依赖,越用越聪明。支持Windows...최신 AI 리소스1개월 전036.2K
ClawWork - 香港大学数据科学实验室开源的AI经济压力测试框架ClawWork是香港大学数据科学实验室开发的AI经济压力测试框架,允许AI在模拟经济环境中完成真实工作任务并获得报酬。核心逻辑是让初始资金仅10美元的AI通过完成220个专业任务(覆盖制造、金融、医...최신 AI 리소스1개월 전027.9K
Ming-Omni-tts - 蚂蚁联合Inclusion AI开源的多模态音频生成模型Ming-Omni-tts 是蚂蚁集团与Inclusion AI联合开源的多模态音频生成模型,包含0.5B和16.8B-A3B两个版本。模型首次实现了语音、环境音和音乐的统一自回归生成,支持语速、音量...최신 AI 리소스2개월 전028.4K
Qwen3.5 - 阿里通义千问团队开源的最新一代大语言模型Qwen3.5是阿里巴巴通义千问团队开源的最新一代大语言模型,属于千问(Qwen)系列的升级版本。Qwen3.5突破了传统文本模型的限制,实现了真正的原生多模态理解,可直接处理文本、图像、视频等多种模...최신 AI 리소스2개월 전030.4K
Ring-2.5-1T - 蚂蚁百灵开源的万亿参数混合线性架构思考模型Ring-2.5-1T 是蚂蚁集团百灵大模型团队开源的全球首个万亿参数混合线性架构思考模型,采用1:7 MLA与Lightning Linear Attention混合设计,激活参数量达63B。模型在...최신 AI 리소스2개월 전029.1K
Xiaomi-Robotics-0 - 小米开源的首代具身智能大模型Xiaomi-Robotics-0 是小米开源的首代具身智能大模型,拥有47亿参数,采用"大脑+小脑"混合架构设计。视觉语言大脑基于多模态大模型,负责理解人类模糊指令与空间推理;动作执行小脑则通过Di...최신 AI 리소스2개월 전030.4K
AionUi - 免费开源的多AI Agent桌面应用AionUi是一个免费开源的多AI Agent桌面应用,支持将Gemini CLI、Claude Code等命令行AI工具整合到图形界面,提供本地文件操作、多会话管理、跨平台运行等功能。支持macOS...최신 AI 리소스2개월 전038K
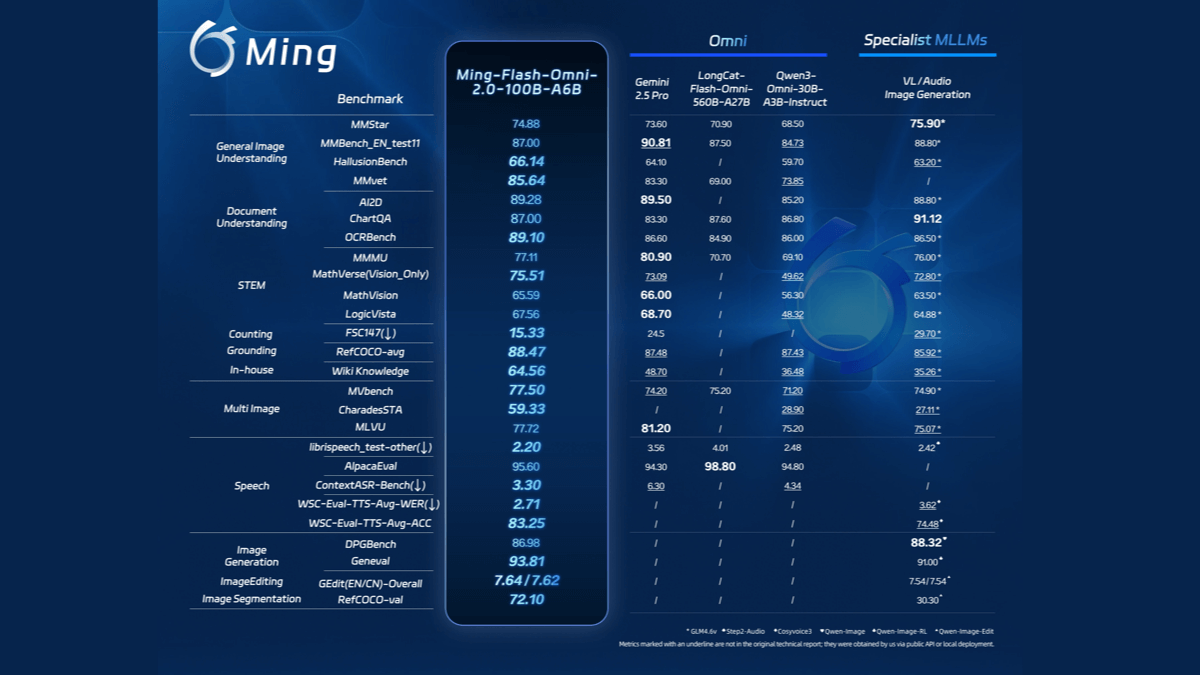
Ming-flash-omni 2.0 - 蚂蚁集团开源的全模态大模型Ming-flash-omni 2.0是蚂蚁集团开源的全模态大模型,集成了视觉、语音和生成能力的AI模型,在多项基准测试中性能领先。支持同时生成语音、环境音效和音乐,能通过自然语言指令精细控制音色、语...최신 AI 리소스2개월 전030.8K
Protenix-v1 - 字节Seed团队推出的首个开源蛋白质结构预测模型Protenix-v1是字节跳动ByteDance Seed团队推出的首个开源蛋白质结构预测模型,性能在严格对齐训练数据和模型规模后超越AlphaFold 3。模型具备显著的推理时扩展特性:通过增加采...최신 AI 리소스2개월 전029.2K
Clawra - 基于OpenClaw框架开源的AI女友程序Clawra是一个基于OpenClaw框架开发的AI女友程序,由韩国开发者David Im制作,具有完整人设和交互功能。通过Persona Engineering技术赋予AI“18岁亚裔女性练习生”的...최신 AI 리소스2개월 전030.8K
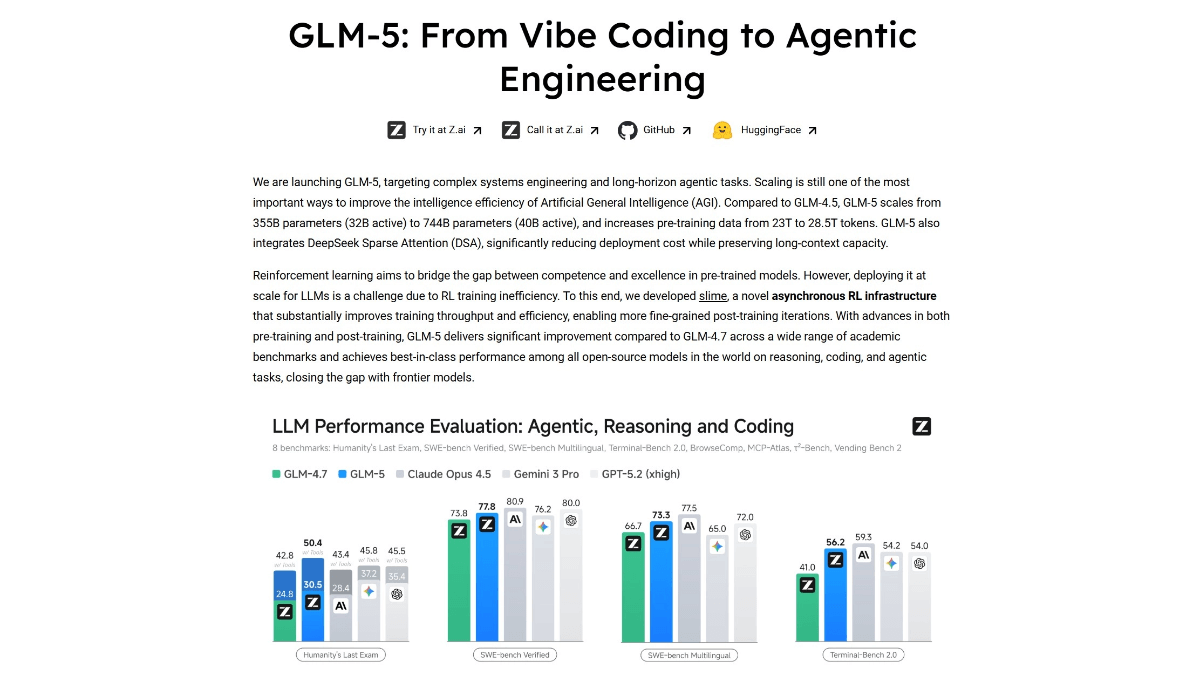
GLM-5 - 智谱AI推出的旗舰级开源大模型GLM-5是智谱AI推出的旗舰级开源大模型,采用744B参数规模(激活40B),专为Agentic Engineering智能体工程打造。模型在编程与Agent能力上取得开源SOTA表现,SWE-be...최신 AI 리소스2개월 전033.4K
nanobot - HKUDS开源的超轻量级个人AI助手框架nanobot 是香港大学数据智能实验室(HKUDS)开源的超轻量级个人AI助手框架,仅用约 4,000行Python代码实现了完整的多通道AI助手功能。作为 OpenClaw 的轻量替代品,nano...최신 AI 리소스2개월 전039.3K
RynnBrain - 阿里巴巴达摩院开源的具身智能大脑基础模型RynnBrain 是阿里巴巴达摩院开源的具身智能大脑基础模型,为机器人提供深度环境理解和物理世界交互能力。是业界首个赋予机器人时空记忆和物理空间推理能力的开源模型。包含2B、8B、30B等7个不同参...최신 AI 리소스2개월 전022.2K
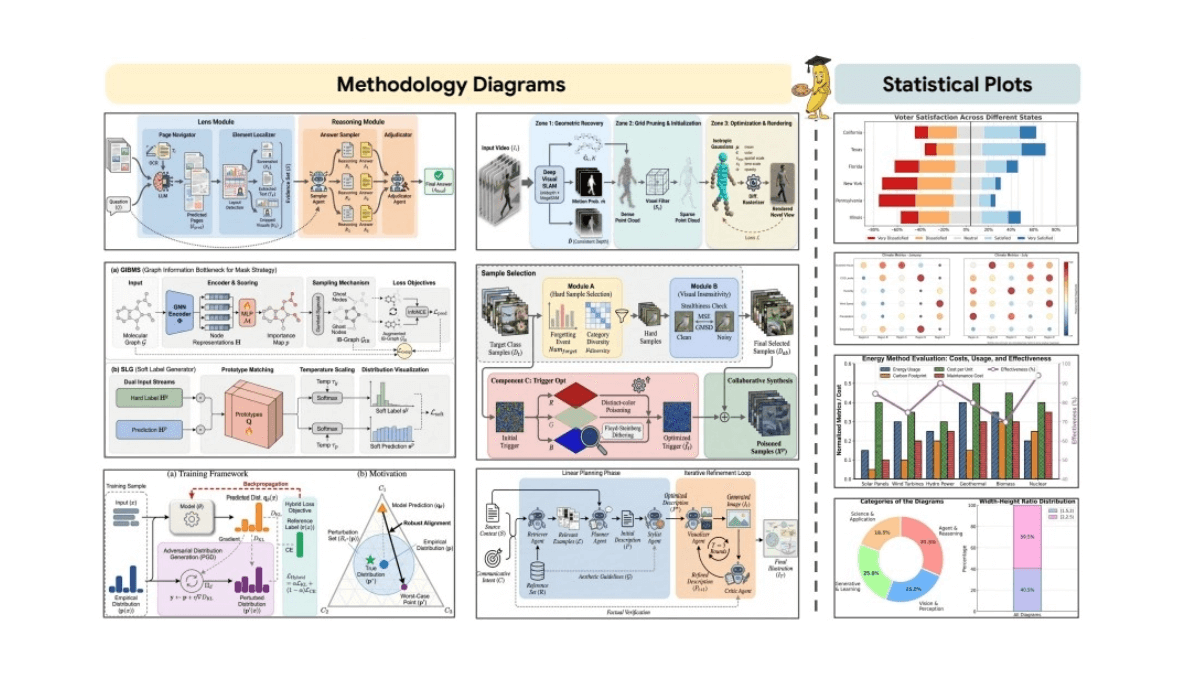
PaperBanana - 北大与谷歌联合开源的AI学术插图自动生成框架PaperBanana是北大与谷歌团队联合开源的AI学术插图自动生成框架,专门解决科研人员绘制方法示意图和统计图表的痛点。框架通过五个智能体协作(检索、规划、造型、渲染和批评),实现从文本描述到Neu...최신 AI 리소스2개월 전026.7K
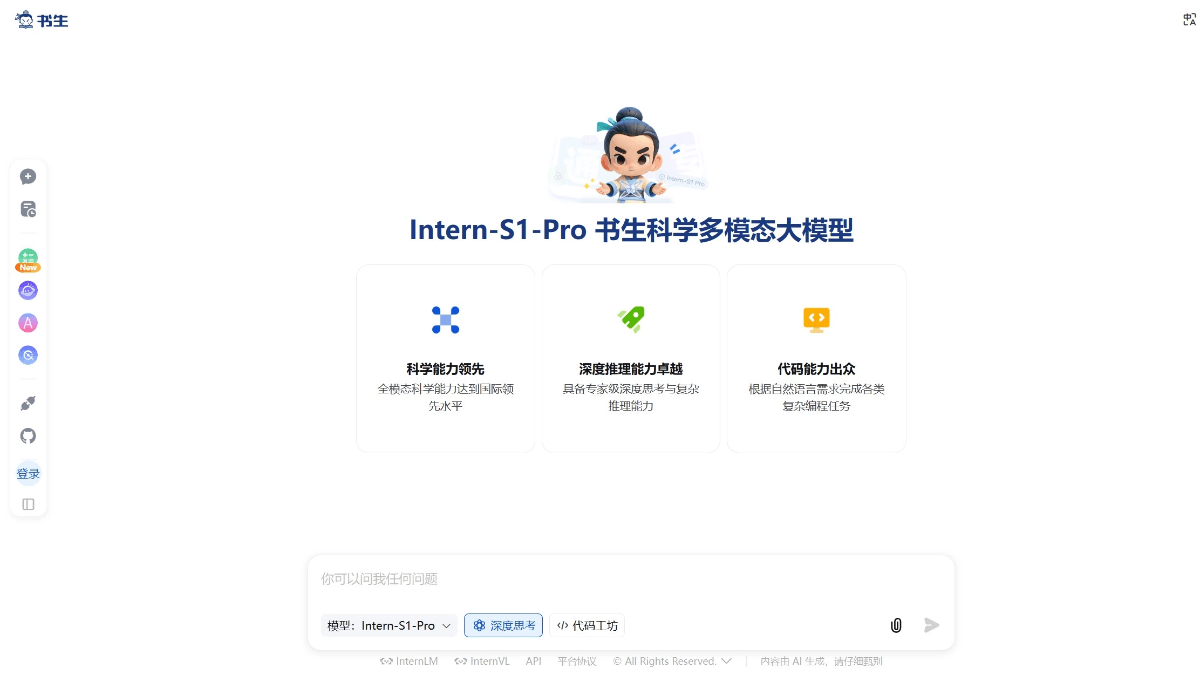
Intern-S1-Pro - 上海AI Lab开源的首个万亿参数科学多模态大模型Intern-S1-Pro是上海人工智能实验室开源的全球首个万亿参数级科学多模态大模型。采用512专家MoE架构,激活仅8专家22B参数,兼顾性能与效率。模型基于SAGE架构,引入傅里叶位置编码,统一...최신 AI 리소스2개월 전024.1K
LingBot-VA - 蚂蚁灵波开源的首个“自回归视频-动作世界模型”LingBot-VA 是蚂蚁灵波开源的全球首个“自回归视频-动作世界模型”,把视频生成与机器人控制塞进同一 Transformer,每一步同时输出下一帧世界画面和对应动作,实现“边想边干”。최신 AI 리소스2개월 전027.8K
MiniCPM-o 4.5 - 面壁智能开源的 9B 全模态旗舰模型MiniCPM-o 4.5 是面壁智能开源的 9B 全模态旗舰模型,以“边看边听主动说”的端到端架构,在手机端即可跑出 GPT-4o 级体验:支持单图、多图、高帧率长视频、实时语音双工对话,首 tok...최신 AI 리소스2개월 전031K
SoulX-FlashTalk - Soul App AI团队开源的实时数字人生成模型SoulX-FlashTalk是Soul App AI团队开源的实时数字人生成模型,拥有140亿参数量,实现了0.87秒超低延迟和32帧/秒的高帧率。模型通过双向蒸馏技术解决了传统数字人延迟高、画面易...최신 AI 리소스2개월 전028.6K
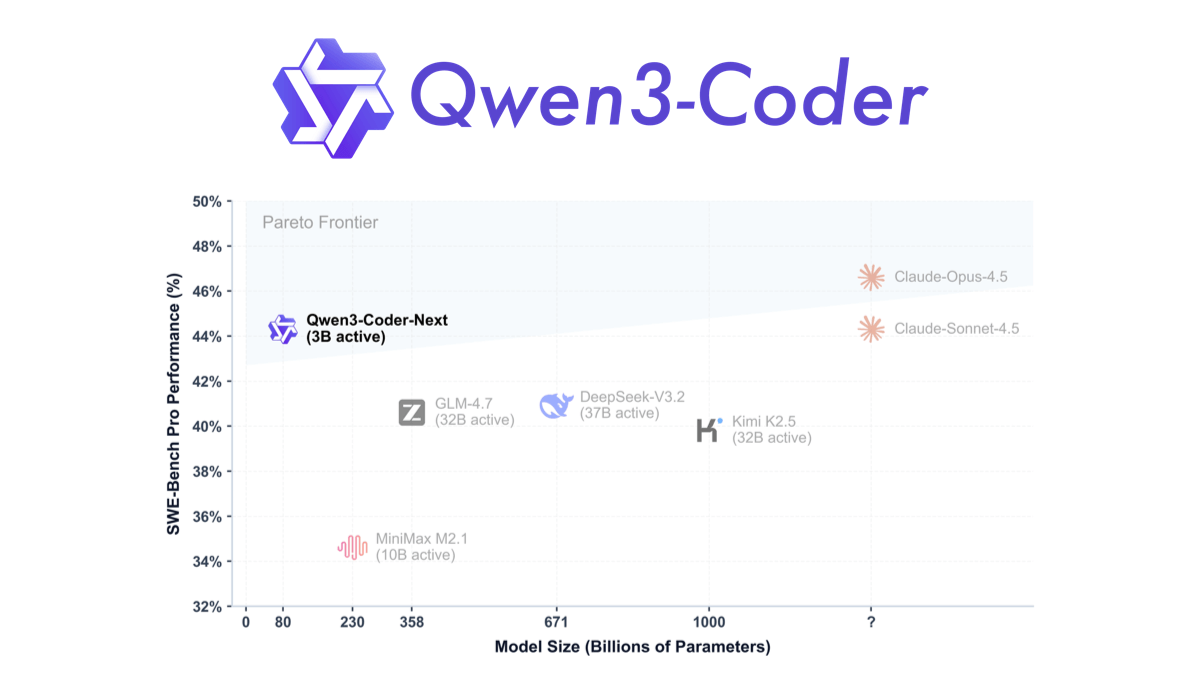
Qwen3-Coder-Next - 阿里通义千问开源的编程智能体混合模型Qwen3-Coder-Next是阿里巴巴通义千问团队开源的专为编程智能体设计的高效混合模型,基于80B总参数的Qwen3-Next架构,推理时仅激活3B参数。核心创新在于采用环境交互和强化学习训练方...최신 AI 리소스2개월 전032.4K
GLM-OCR - 智谱开源的 0.9B 轻量级专业 OCR 模型GLM-OCR 是智谱开源的 0.9B 轻量级专业 OCR 模型,在 OmniDocBench V1.5 以 94.6 分刷新 SOTA。兼顾“小体积”与“全场景”,扫描、手写、印章、多语混排、复杂表...최신 AI 리소스2개월 전031.8K
Step 3.5 Flash - 阶跃星辰开源的 1960 亿稀疏 MoE 模型Step 3.5 Flash 是阶跃星辰开源的 1960 亿稀疏 MoE 模型,每 token 仅激活 110 亿参数,能在代码任务跑出 350 token/s 的实时速度。基于自研 MTP-3 多 ...최신 AI 리소스2개월 전024.4K
UnifoLM-VLA-0 - 宇树科技开源的首款操作型大模型UnifoLM-VLA-0 是宇树科技 UnifoLM 系列的首款操作型大模型,突破传统视觉语言模型(VLM)仅能理解图像文字的局限,通过在机器人操作数据上的持续预训练,实现从"图文理解"向具备物理常...최신 AI 리소스2개월 전025K
SenseNova-MARS - 商汤科技开源的多模态搜索推理Agent语言模型SenseNova-MARS 是商汤开源的首个支持动态视觉推理与图文搜索深度融合的智能体视觉语言模型(Agentic VLM),提供 8B 和 32B 双版本。模型能自主规划任务步骤、调用多种工具(如...최신 AI 리소스2개월 전024.1K
MOVA - 创智学院联合模思智能开源的端到端音视频生成模型MOVA(MOSS-Video-and-Audio) 是上海创智学院 OpenMOSS 团队联合模思智能(MOSI)开源的端到端音视频生成模型,是中国首个高性能开源音视频模型。突破了传统"先画面后配音...최신 AI 리소스2개월 전024.3K