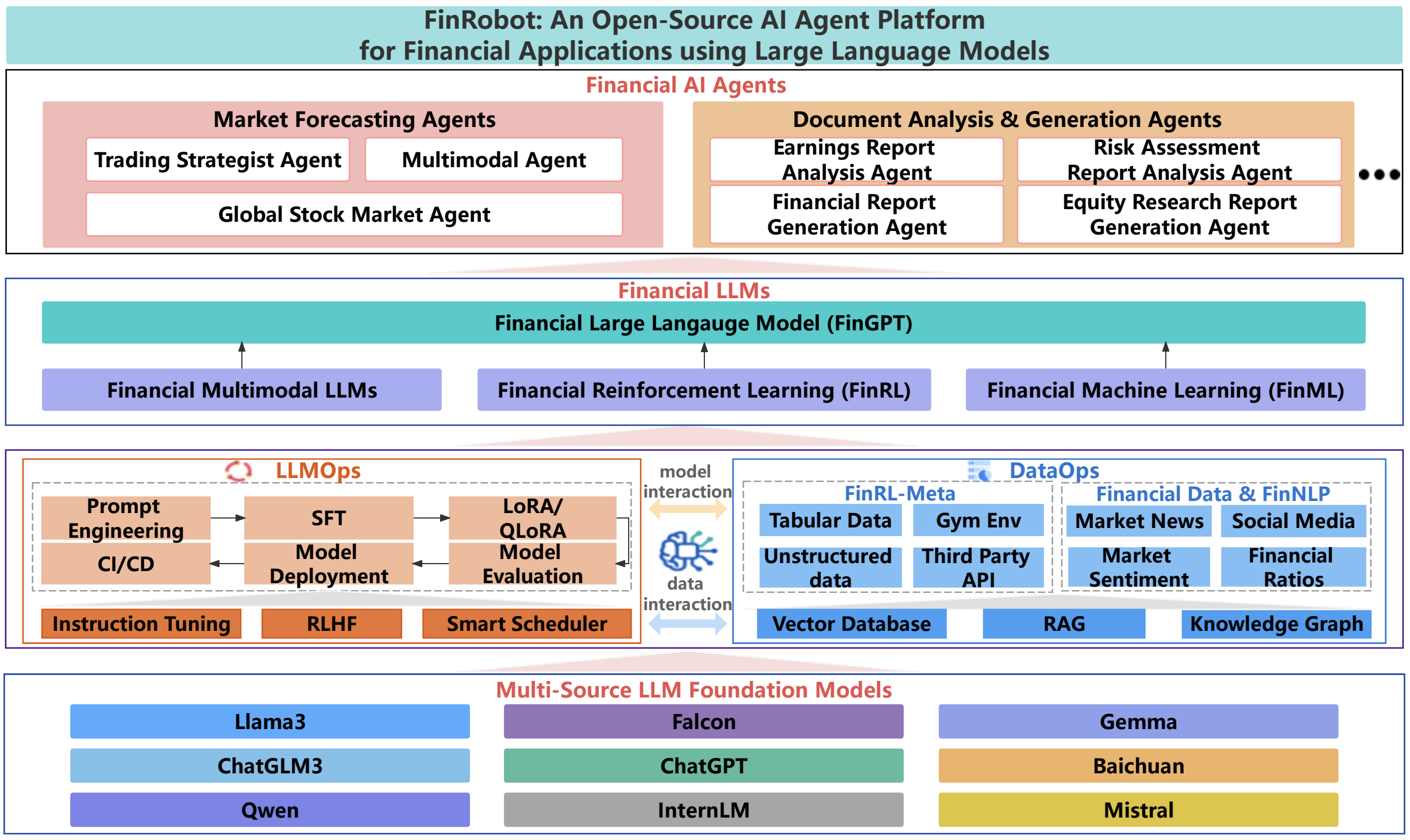
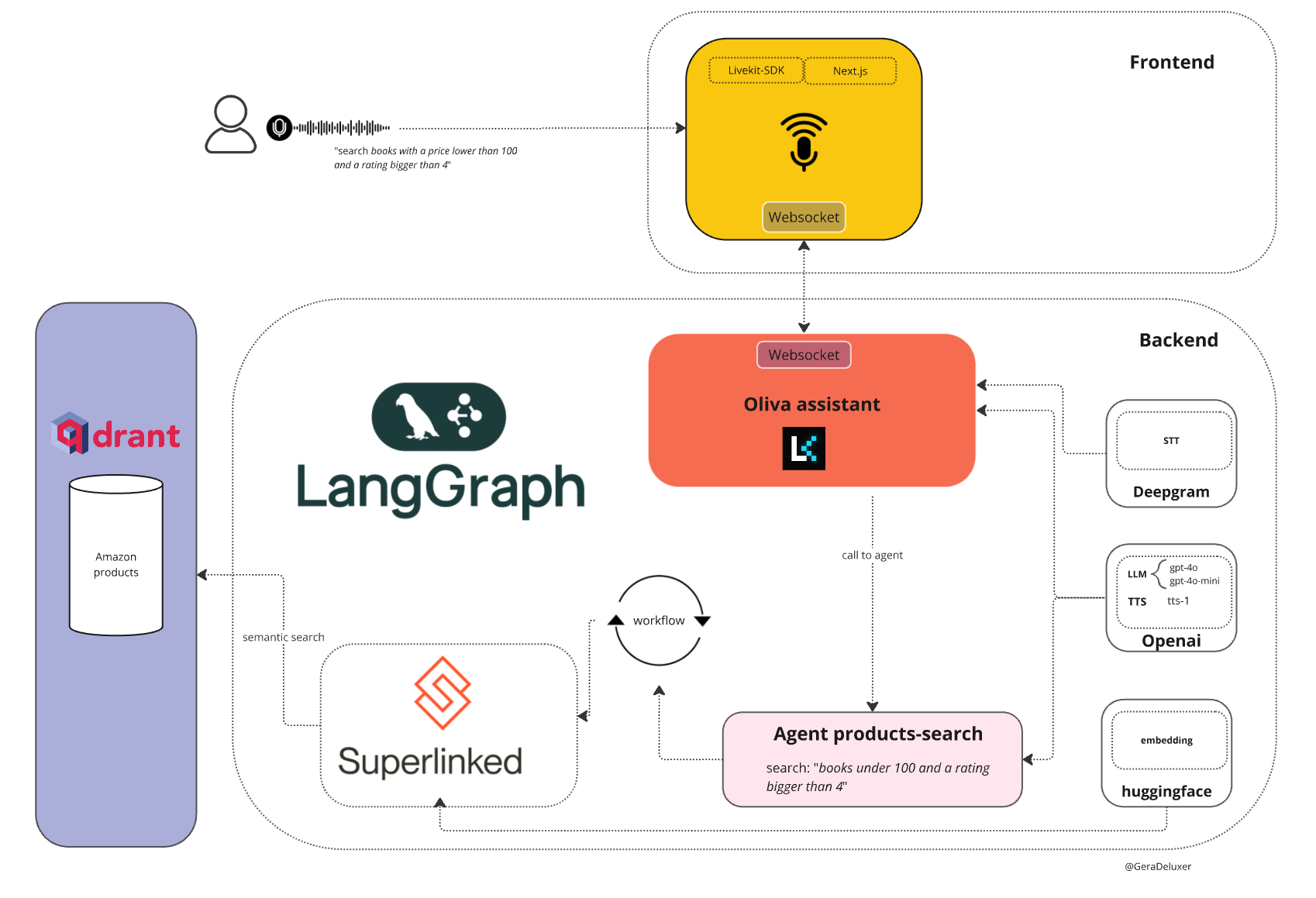
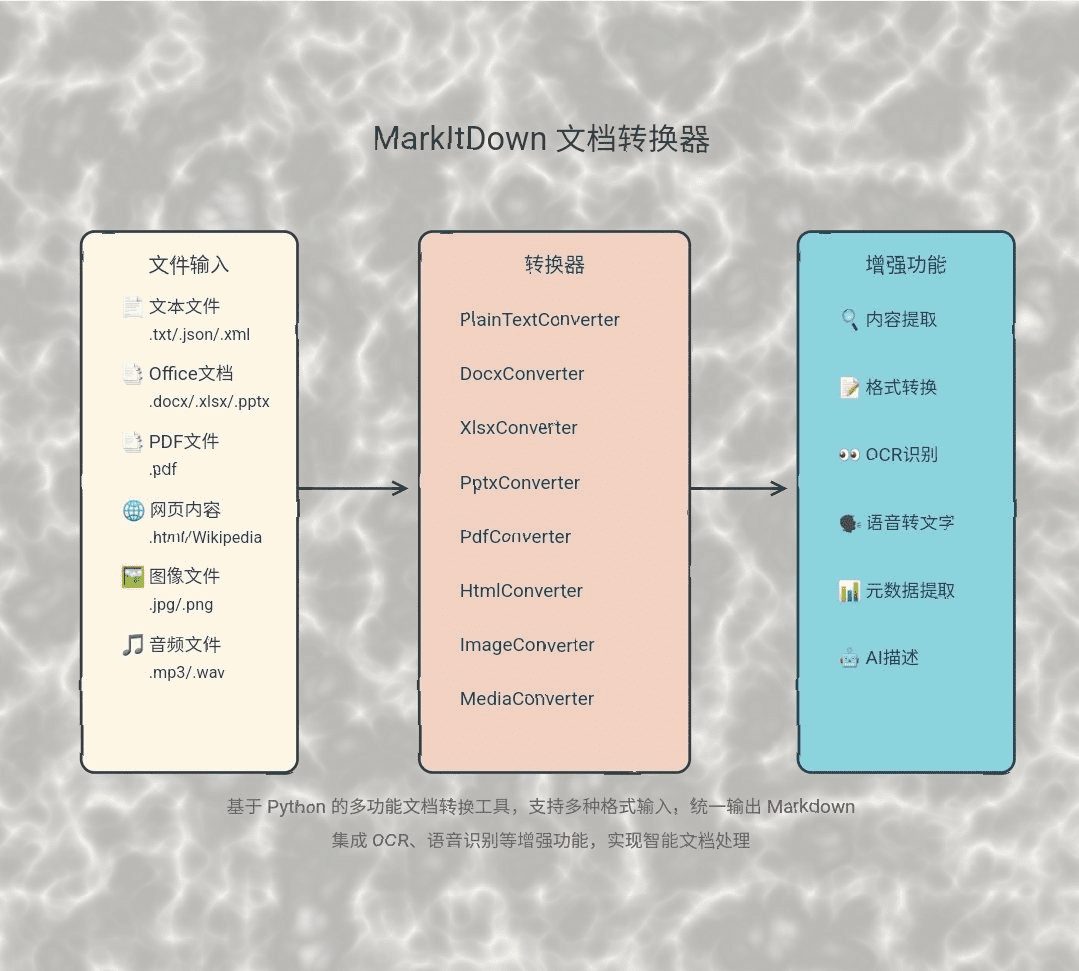
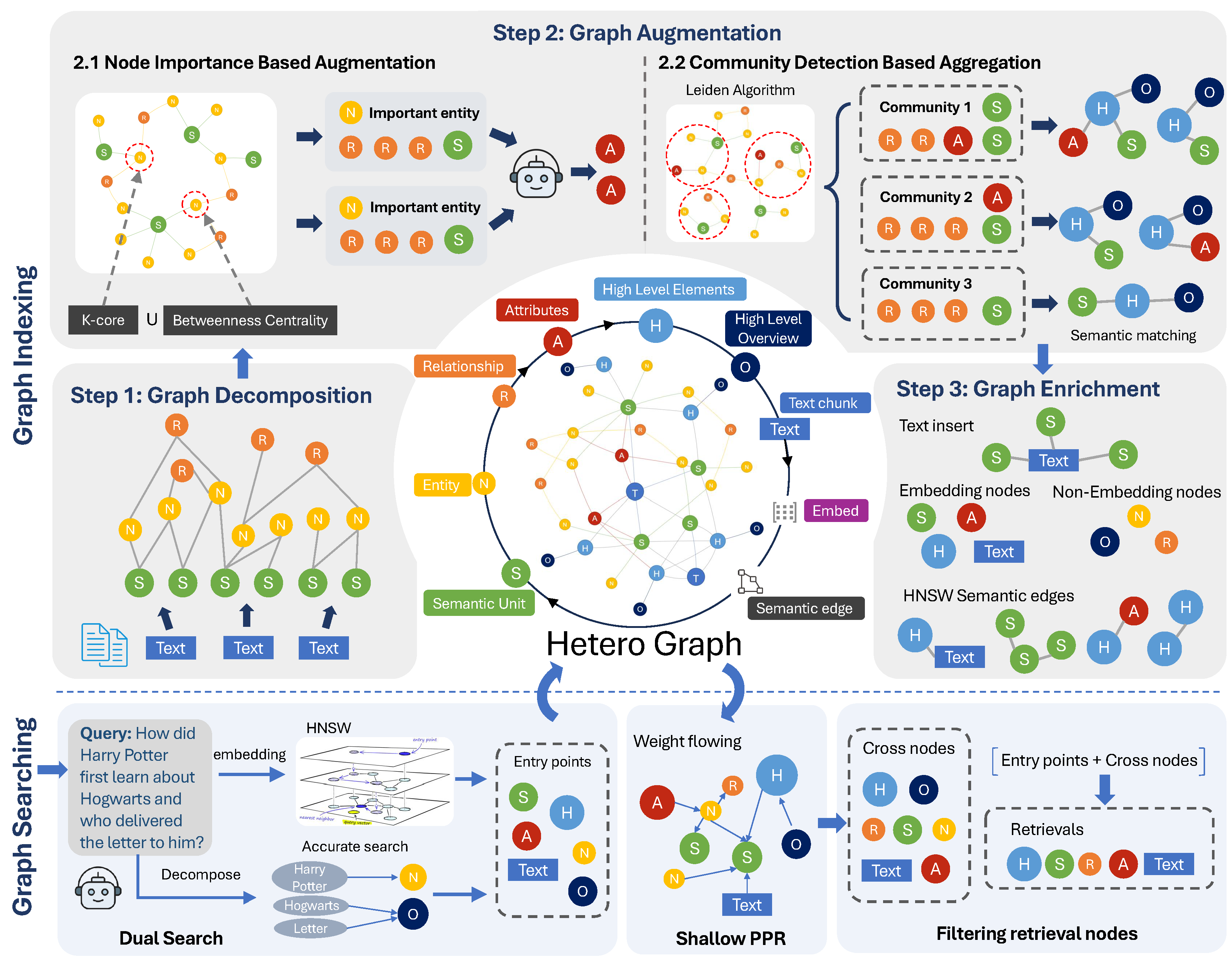
종합 소개 FinRobot은 AI4Finance Foundation에서 개발한 오픈 소스 AI 인텔리전스 플랫폼으로, 금융 분석을 위해 설계되었습니다. 전통적인 언어 모델뿐만 아니라 다양한 AI 기술을 통합하여 금융 산업을 위한 포괄적인 솔루션을 제공하는 것을 목표로 합니다.F....
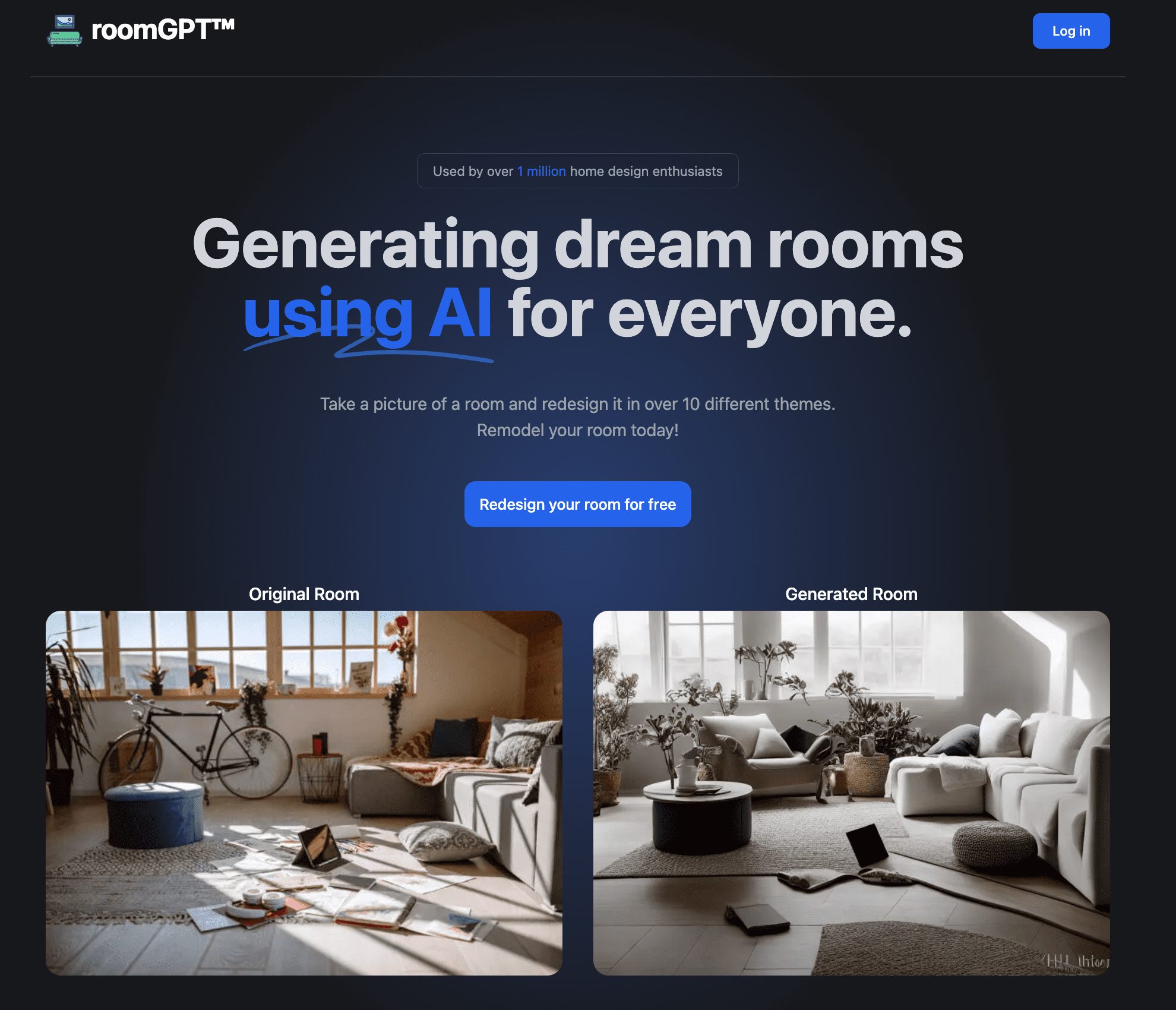
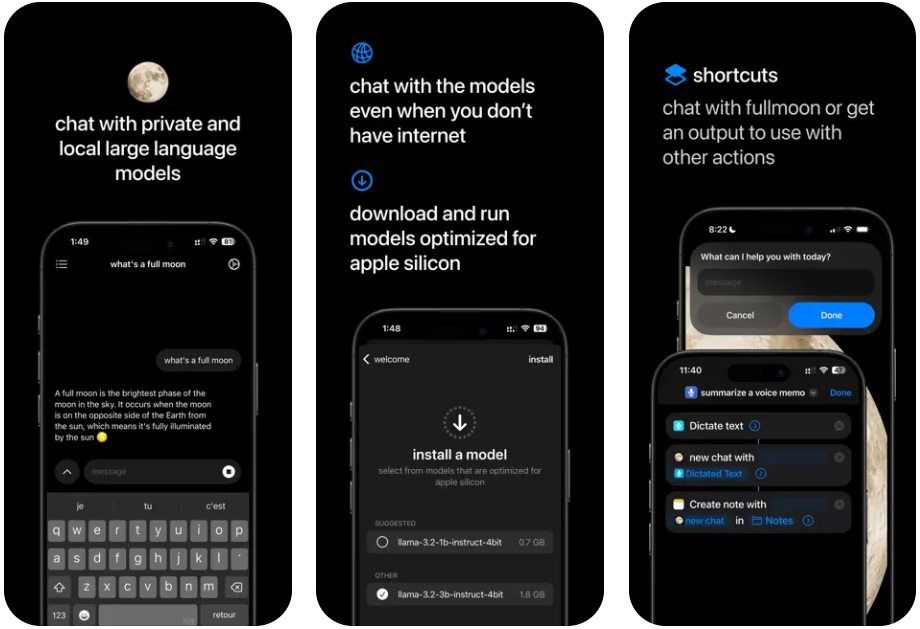
일반 소개 RoomGPT는 사용자가 방 사진을 업로드하고 인공지능 기술을 사용하여 새롭게 디자인된 버전을 생성할 수 있는 GitHub 사용자 Nutlope가 개발한 오픈 소스 프로젝트입니다. 이 프로젝트는 사용자가 비싼 디자이너 비용 없이 전문가 수준의 인테리어 디자인을 이용할 수 있도록 하는 것을 목표로 합니다....
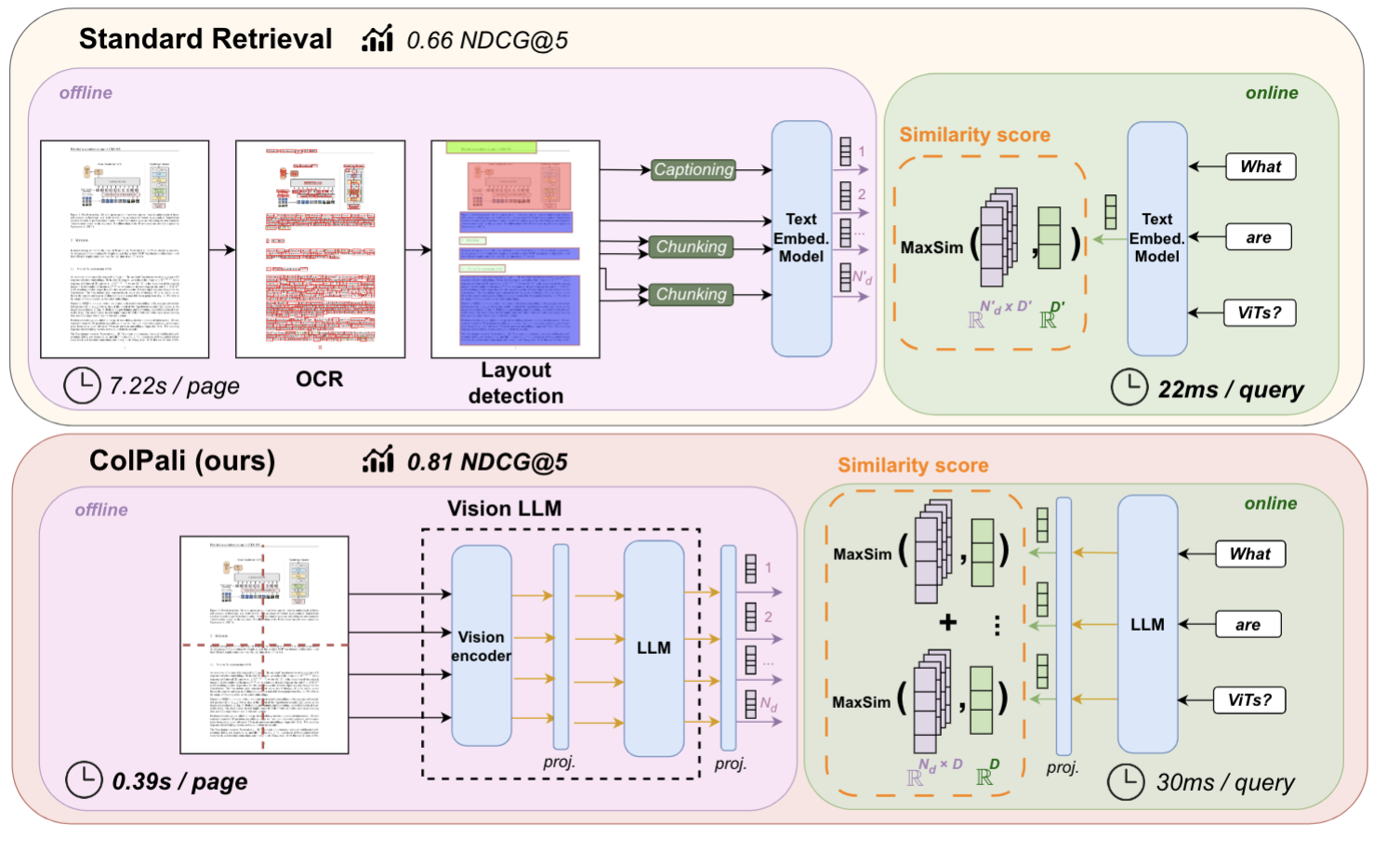
표 인식의 목표는 이미지에서 표를 구문 분석하여 표 구조와 셀 위치를 정확하게 식별하고 이를 구조화된 표 형식(예: HTML)으로 변환하는 것입니다. 오늘날의 정보화 시대에는 여전히 많은 양의 중요한 표 데이터가 비정형화된 상태로 존재합니다(예: 통계표 그림이 있는 스캔 문서...).
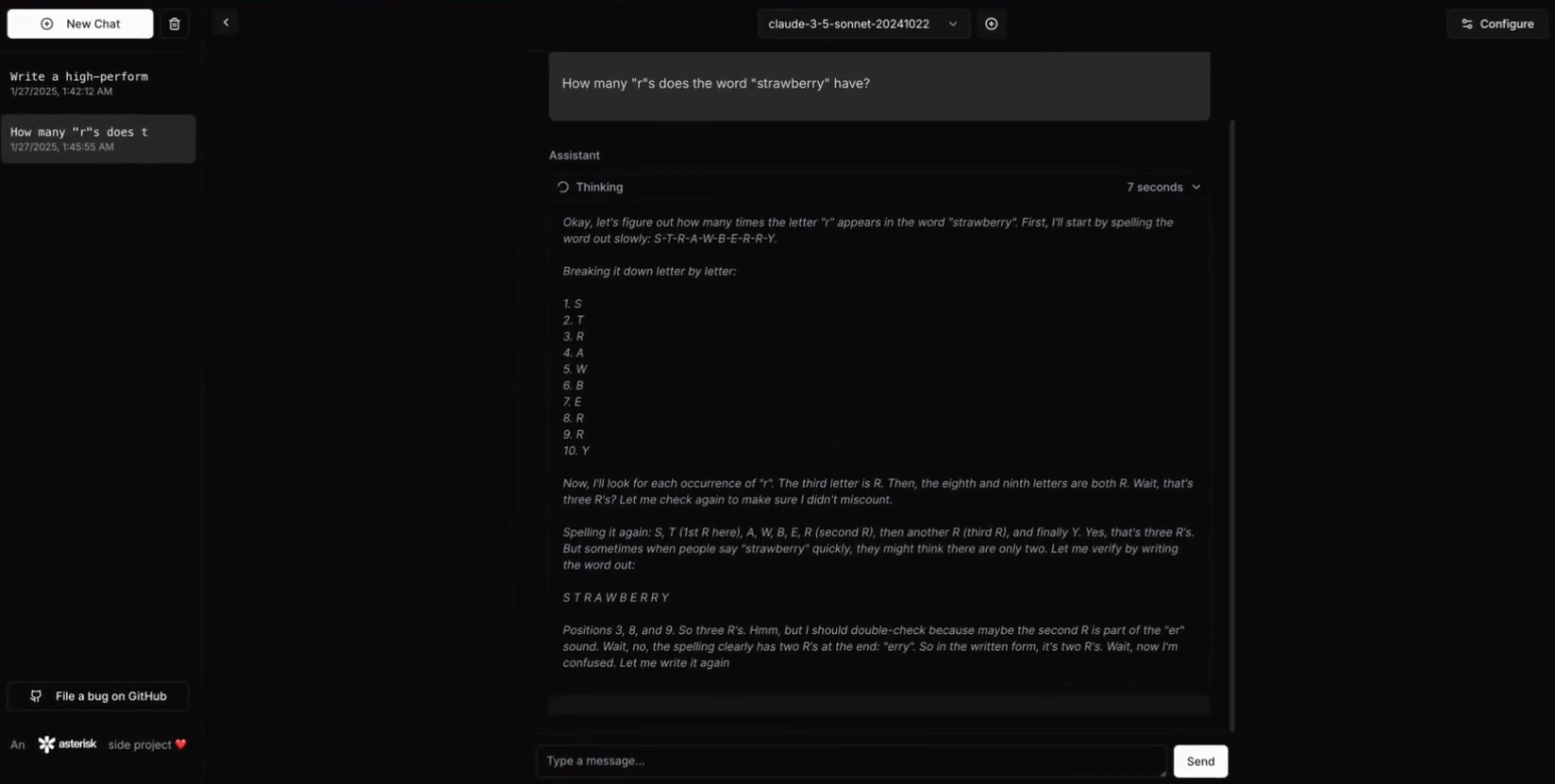
종합 소개 R1-V는 저비용 강화 학습(RL)을 통해 시각 언어 모델링(VLM)의 획기적인 발전을 목표로 하는 오픈 소스 프로젝트입니다. 이 프로젝트는 검증 가능한 보상 메커니즘을 활용하여 VLM이 일반적인 수 세기 능력을 학습하도록 동기를 부여합니다. 놀랍게도, R1-V의 2B는 ...
일반 소개 HyperChat은 BigSweetPotatoStudio에서 개발하고 GitHub에서 호스팅하는 오픈 소스 채팅 클라이언트로, OpenAI, Cla... 등 여러 대형 언어 모델(LLM)의 API를 통합하여 BigSweetPotatoStudio 언어 모델에 대한 포괄적인 개요를 제공하도록 설계되었습니다.
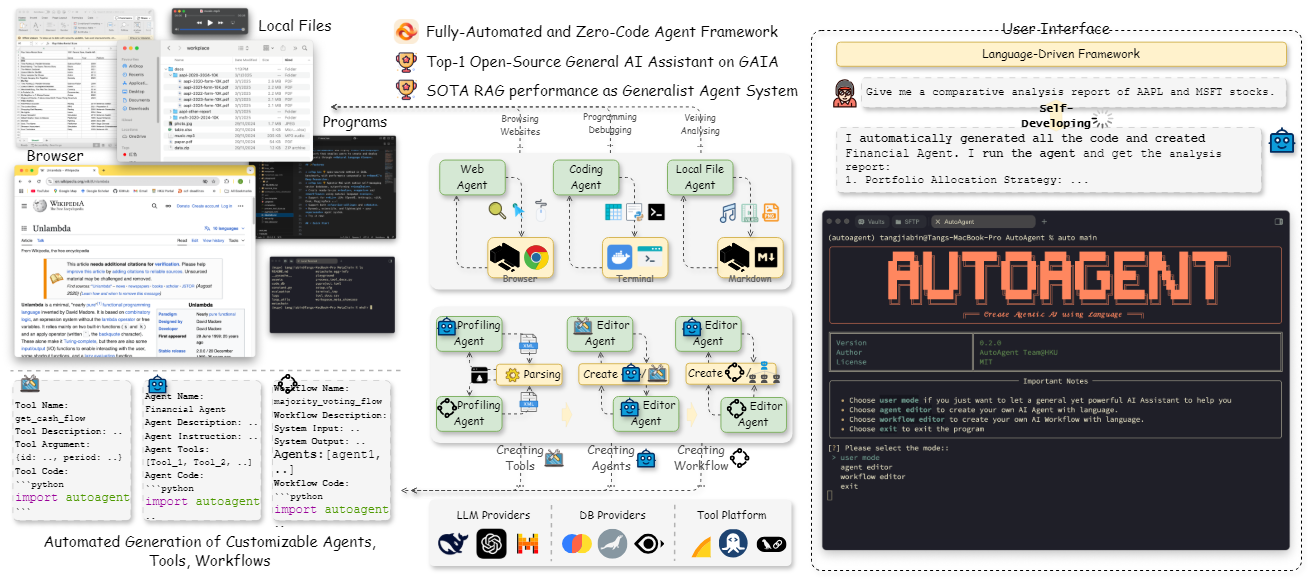
일반 소개 AutoAgent는 홍콩대학교 데이터 인텔리전스 연구소(HKUDS)에서 개발하고 GitHub에서 호스팅하는 오픈 소스 AI 인텔리전스 프레임워크로, 사용자가 프로그래밍 기반 없이 순수 자연어로 요구 사항을 설명하여 맞춤형 AI 인텔리전스를 빠르게 생성하고 배포할 수 있습니다....
포괄적인 소개 프런트엔드, 순수 구성 파일 구성 API 채널이 없습니다. 파일을 작성하기 만하면 자체 API 스테이션을 실행할 수 있으며 문서에는 흰색 친화적 인 자세한 구성 가이드가 있습니다. uni-api는 대규모 모델 API 프로젝트의 통합 관리로, 통합 된 ...
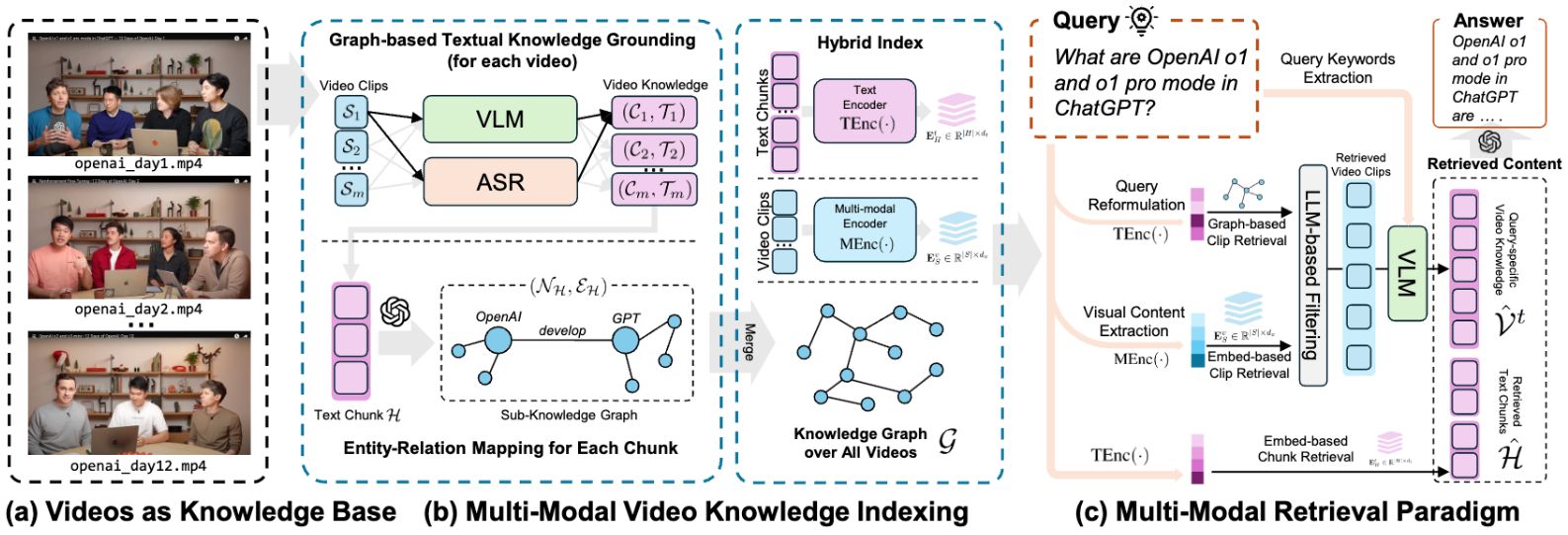
포괄적인 소개 VideoRAG는 매우 긴 컨텍스트 비디오를 처리하고 이해하도록 설계된 검색 강화 생성 프레임워크입니다. 이 도구는 그래프 중심의 텍스트 지식 기반과 계층적 멀티모달 컨텍스트 인코딩을 결합하여 단일 NVIDIA RTX 3090 GPU에서 효율적으로 처리합니다....
일반 소개 인피니트유는 바이트댄스 인텔리전트 크리에이션 팀에서 개발한 오픈소스 프로젝트입니다. FLUX.1-dev 모델을 사용하는 확산 트랜스포머(DiT) 기술을 기반으로 하며, 핵심 기능은 사용자가 사진을 업로드하고 텍스트 설명을 입력하여 생성할 수 있도록 하는 것입니다.
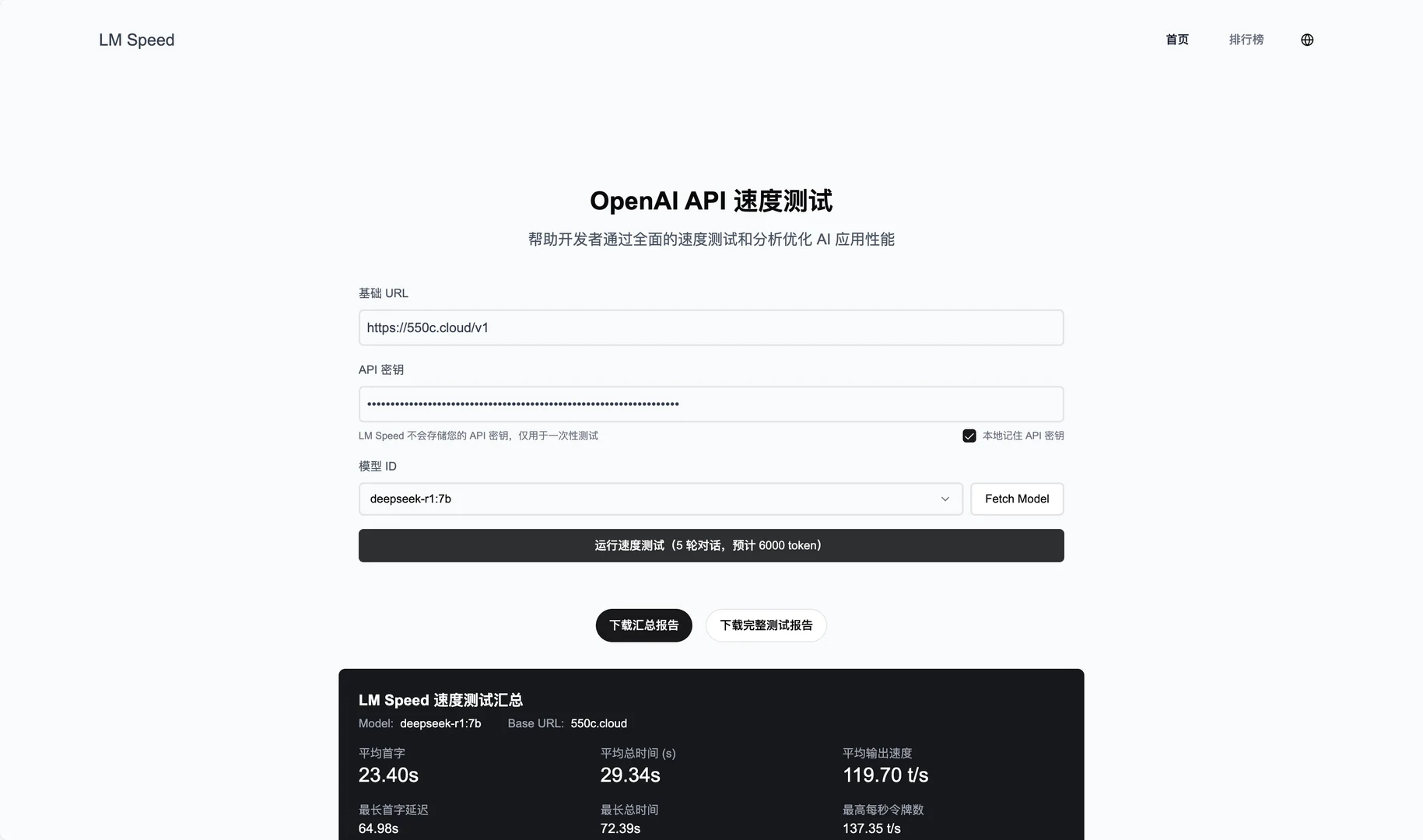
일반 소개 LM Speed는 AI 개발자를 위해 특별히 설계된 도구로, lmspeed.net에서 온라인 서비스로도 제공됩니다. 핵심 기능은 언어 모델 API의 성능을 테스트하고 분석하여 사용자가 속도 병목 현상을 빠르게 식별하고 호출 전략을 최적화할 수 있도록 돕는 것입니다. 이...
종합 소개 OpenAOE는 오픈 소스 대규모 모델 그룹 채팅 프레임워크로, 현재 시장에 여러 모델이 병렬로 응답하는 채팅 프레임워크가 부족한 문제를 해결하기 위해 개발되었습니다. OpenAOE를 사용하면 사용자는 여러 LLM(대규모 언어 모델)과 동시에 대화하고 병렬 출력을 얻을 수 있습니다. 이 프레임워크는 다음을 지원합니다.
종합 소개 WeClone은 대규모 언어 모델 및 음성 합성 기술과 결합된 WeChat 채팅 로그와 음성 메시지를 사용하여 사용자가 개인화된 디지털 도플갱어를 만들 수 있는 오픈 소스 프로젝트입니다. 이 프로젝트는 사용자의 채팅 습관을 분석하여 모델을 훈련시킬 뿐만 아니라 소수의 음성 샘플로 사실적인 소리를 생성할 수 있습니다....
일반 설명 잘못된 JSON 파일을 수정하는 모듈로, 특히 LLM(대규모 언어 모델)에서 출력되는 잘못된 JSON 데이터를 구문 분석하기 위한 모듈입니다. 이 모듈은 따옴표 누락, 잘못된 쉼표, 이스케이프되지 않은 문자 및 불완전한 키-값과 같은 일반적인 JSON 구문 오류를 수정합니다.
일반 소개 X-Kit은 X(이전의 트위터) 사용자 데이터와 트윗을 크롤링하고 분석하기 위해 설계된 오픈 소스 도구입니다. GitHub 사용자 xiaoxiunique가 개발한 이 도구는 사용자가 특정 X 사용자에 대한 기본 정보와 트윗을 얻는 프로세스를 자동화할 수 있도록 설계되었습니다.
종합 소개 컬러는 잠재적 확산 기법을 기반으로 Racer 팀에서 개발한 대규모 텍스트-이미지 생성 모델입니다. 이 모델은 수십억 개의 텍스트-이미지 데이터 쌍에 대해 학습되었으며 중국어와 영어 입력을 모두 지원하여 의미적으로 정확한 고품질의 복잡한 이미지를 생성할 수 있습니다.시각적 품질의 컬러...
일반 소개 AgentGPT는 사용자가 브라우저를 통해 자율적으로 AI 인텔리전스를 생성, 구성 및 배포할 수 있도록 설계된 오픈 소스 프로젝트로, Reworkd 팀에서 개발하여 GitHub에서 호스팅하고 있습니다. 사용자는 목표를 설정하기만 하면 AgentGPT는 다음을 수행할 수 있습니다.
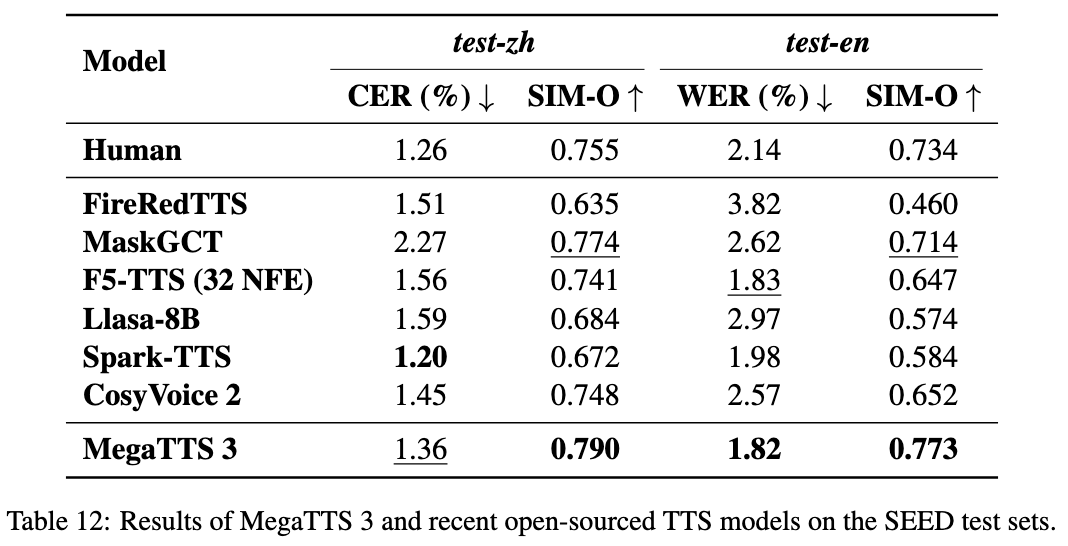
종합 소개 MegaTTS3는 고품질 중국어 및 영어 음성 생성에 중점을 두고 절강대학교와 협력하여 바이트댄스가 개발한 오픈 소스 음성 합성 도구입니다. 핵심 모델은 가볍고 효율적인 0.45억 개의 파라미터로 중국어와 영어 혼합 음성 생성 및 음성 복제를 지원합니다. 프로젝트는 ...에서 호스팅됩니다.
종합적인 소개 모킹버드는 AI 기술을 통해 빠른 음성 복제와 텍스트 음성 변환을 목표로 하는 오픈 소스 프로젝트입니다. 사용자는 5초 분량의 음성 샘플만 제공하면 모든 음성 콘텐츠를 생성할 수 있습니다. 이 프로젝트는 다양한 중국어 데이터 세트를 지원하며 Windows에서는 ...
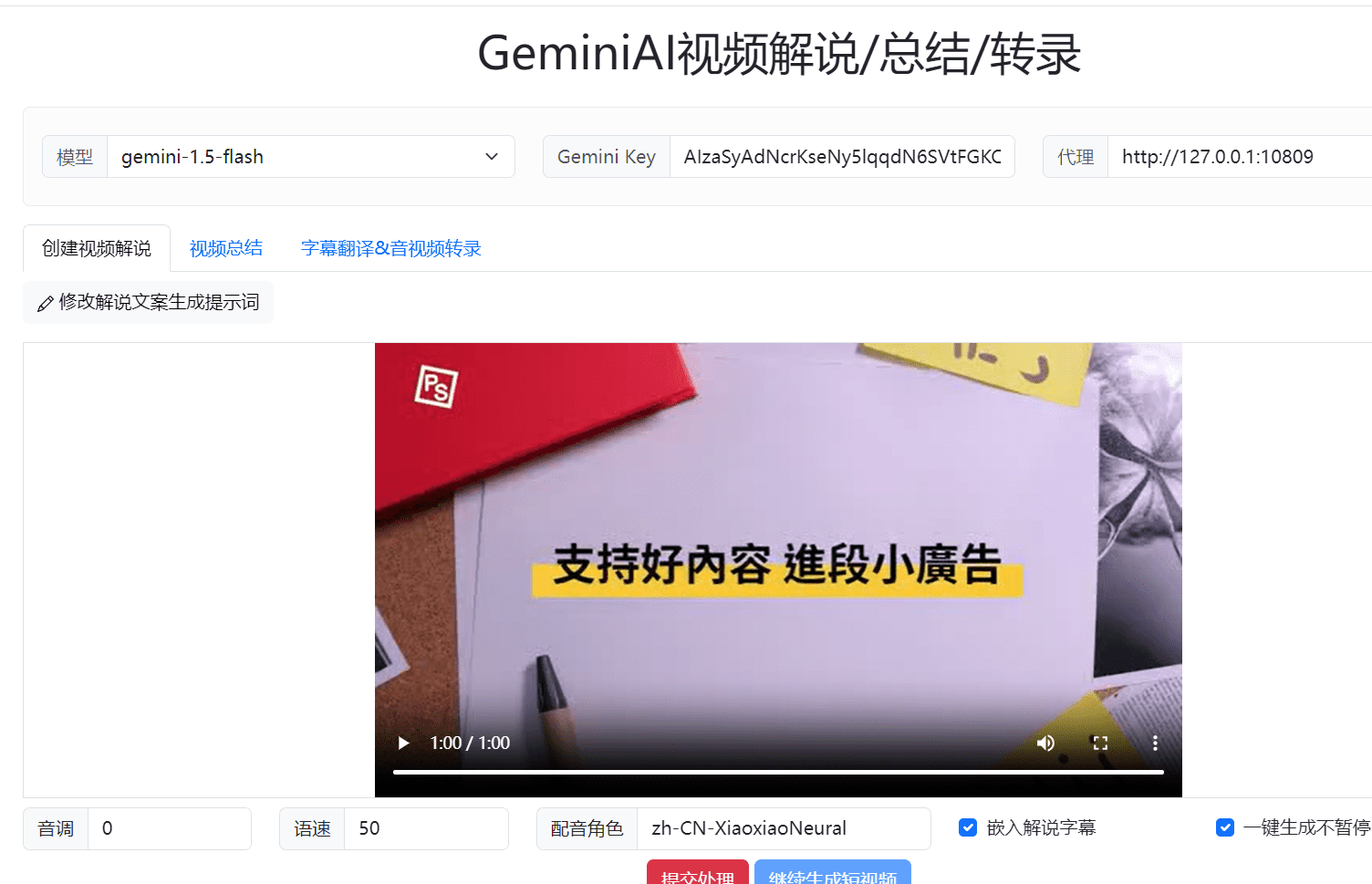
개요 AI2SRT는 GeminiAI 빅 모델을 사용하여 한 번의 클릭으로 짧은 내레이션 동영상과 긴 동영상의 동영상 요약을 생성하는 동시에 오디오 및 동영상 전사 자막을 지원하는 오픈 소스 프로젝트입니다. 이 프로젝트는 동영상 콘텐츠 제작 과정을 간소화하고 효율적인 자막 생성 및 번역 기능을 제공하는 것을 목표로 합니다. 사용자는 통과할 수 있습니다...
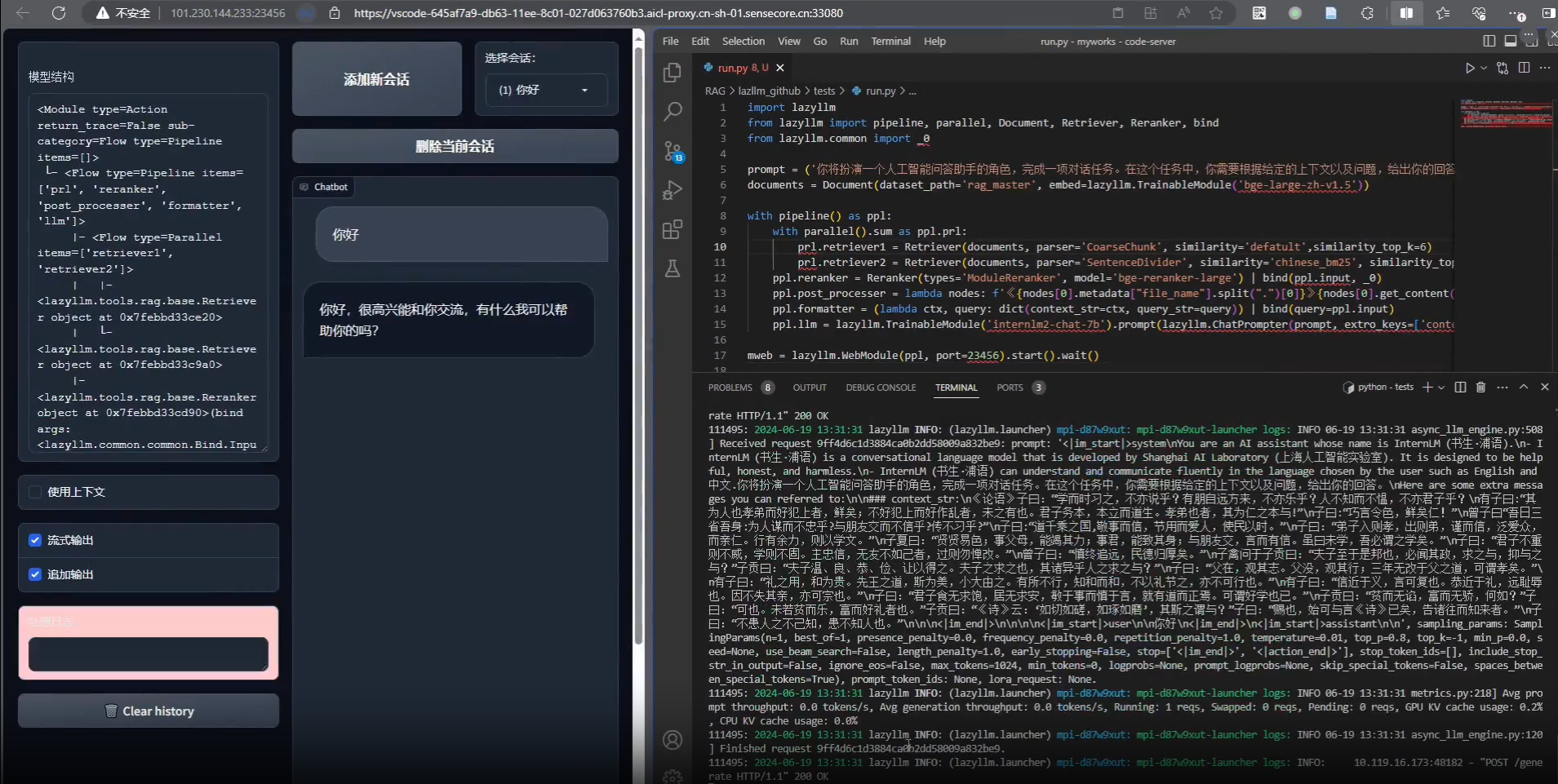
포괄적인 소개 LazyLLM은 LazyAGI 팀이 개발한 오픈 소스 도구로, 다중 지능 대규모 모델 애플리케이션의 개발 프로세스를 간소화하는 데 중점을 두고 있습니다. 개발자는 원클릭 배포와 가벼운 게이트웨이 메커니즘을 통해 복잡한 AI 애플리케이션을 빠르게 구축하여 지루한 엔지니어링 구성을 줄일 수 있습니다.
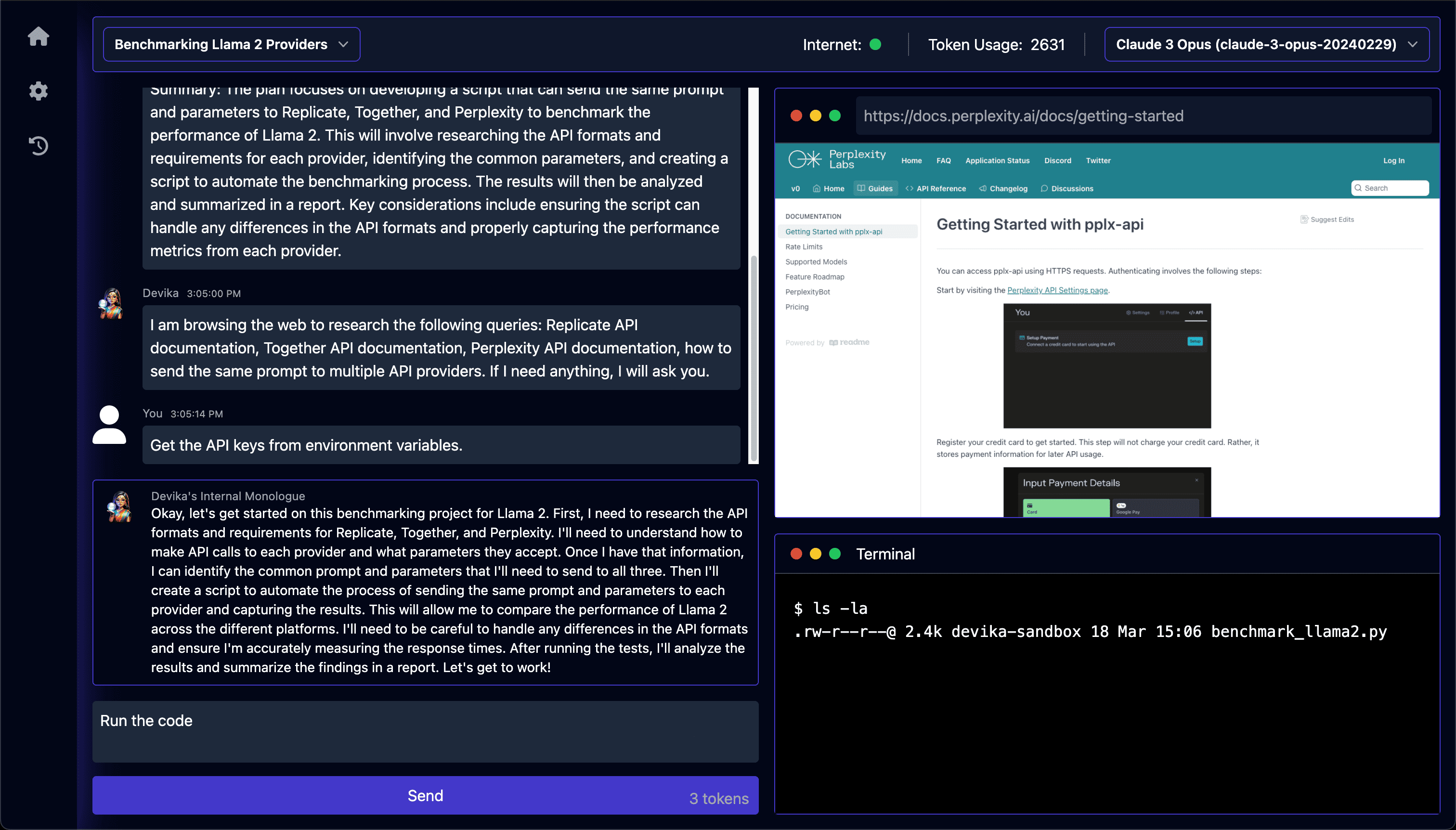
일반 소개 Devika는 인간의 높은 수준의 지시를 이해하고, 이를 단계별로 세분화하여 관련 정보를 연구하고, 주어진 목표를 달성하기 위해 코드를 작성하는 고급 AI 소프트웨어 엔지니어입니다. 대규모 언어 모델, 계획 및 추론 알고리즘, 웹 브라우징 기능을 사용하여 소프트웨어를 지능적으로 개발합니다....
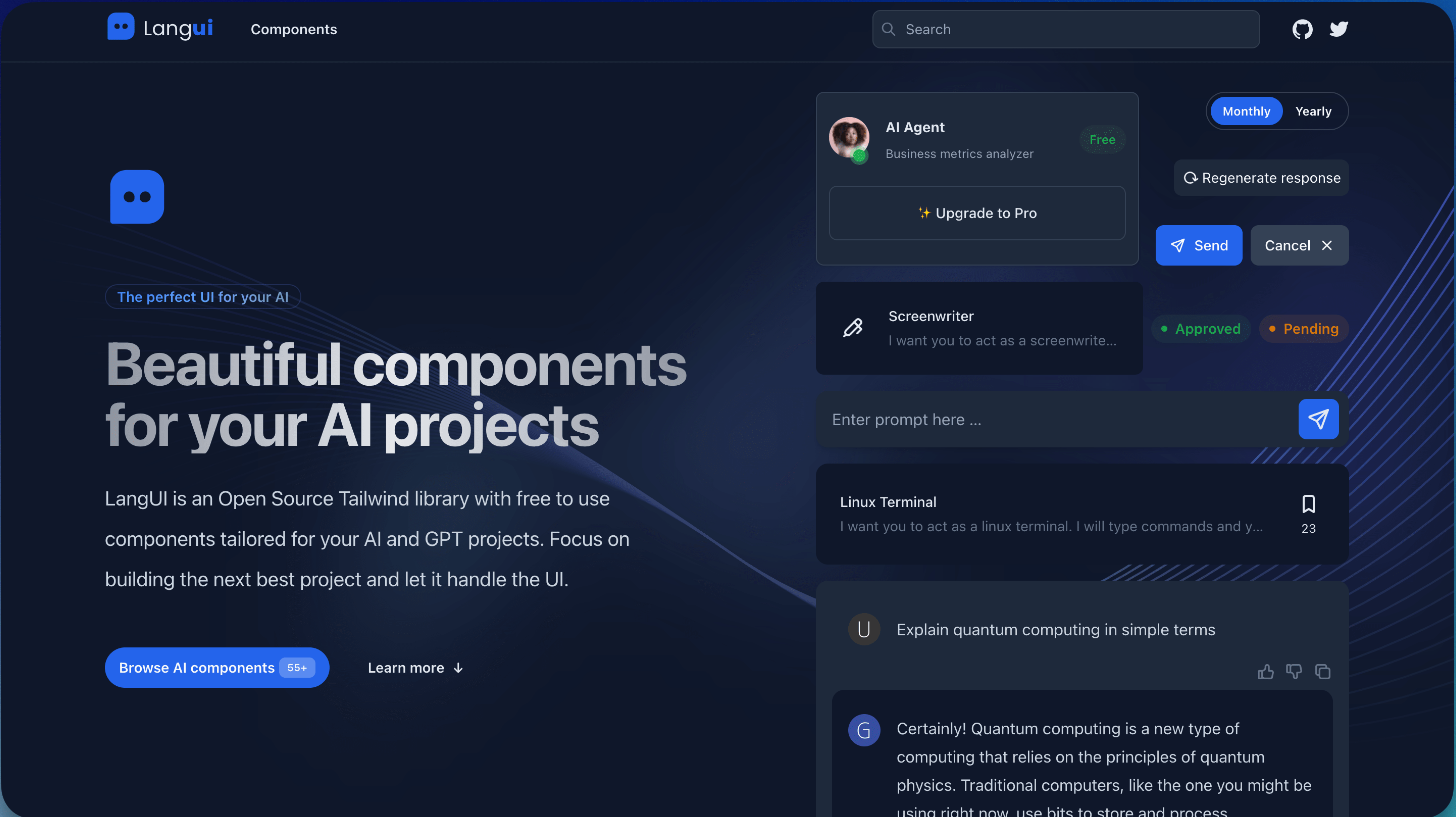
일반 소개 LangbaseInc의 Langui는 제너레이티브 AI 및 LLM(대규모 언어 모델링) 프로젝트를 위해 설계된 오픈 소스 사용자 인터페이스 컴포넌트 라이브러리입니다. 이 라이브러리는 Tailwind CSS를 기반으로 하며 개발자가 빠르게 구성할 수 있도록 미리 빌드된 UI 컴포넌트 모음을 제공합니다.
포괄적인 소개 Flow는 단순성과 유연성에 중점을 두고 AI 에이전트 구축을 위해 설계된 경량 작업 엔진입니다. 기존의 노드 및 에지 기반 워크플로우와 달리 Flow는 병렬 실행, 동적 스케줄링 및 지능형 종속성 관리를 지원하는 동적 작업 대기열 시스템을 사용합니다. 핵심 개념은 ...
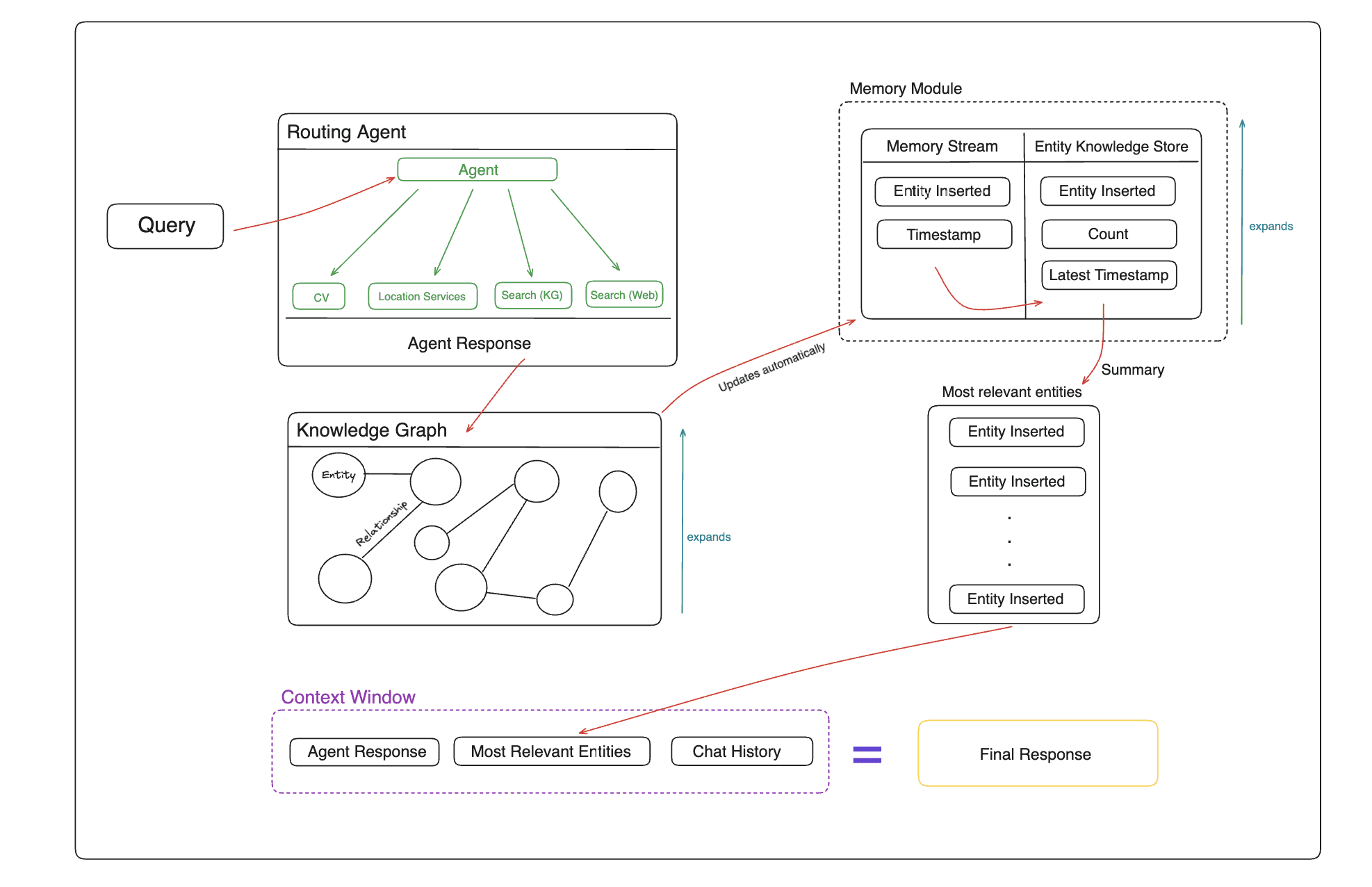
일반 소개 Memary는 자율 지능을 위한 장기 메모리 관리 솔루션을 제공하는 데 중점을 둔 혁신적인 오픈 소스 프로젝트입니다. 이 프로젝트는 지식 그래프와 특수 메모리 모듈을 통해 지능이 기존 컨텍스트 윈도우의 한계를 극복하고 더 스마트한 상호 작용 경험을 달성할 수 있도록 지원합니다.Memary는 ...
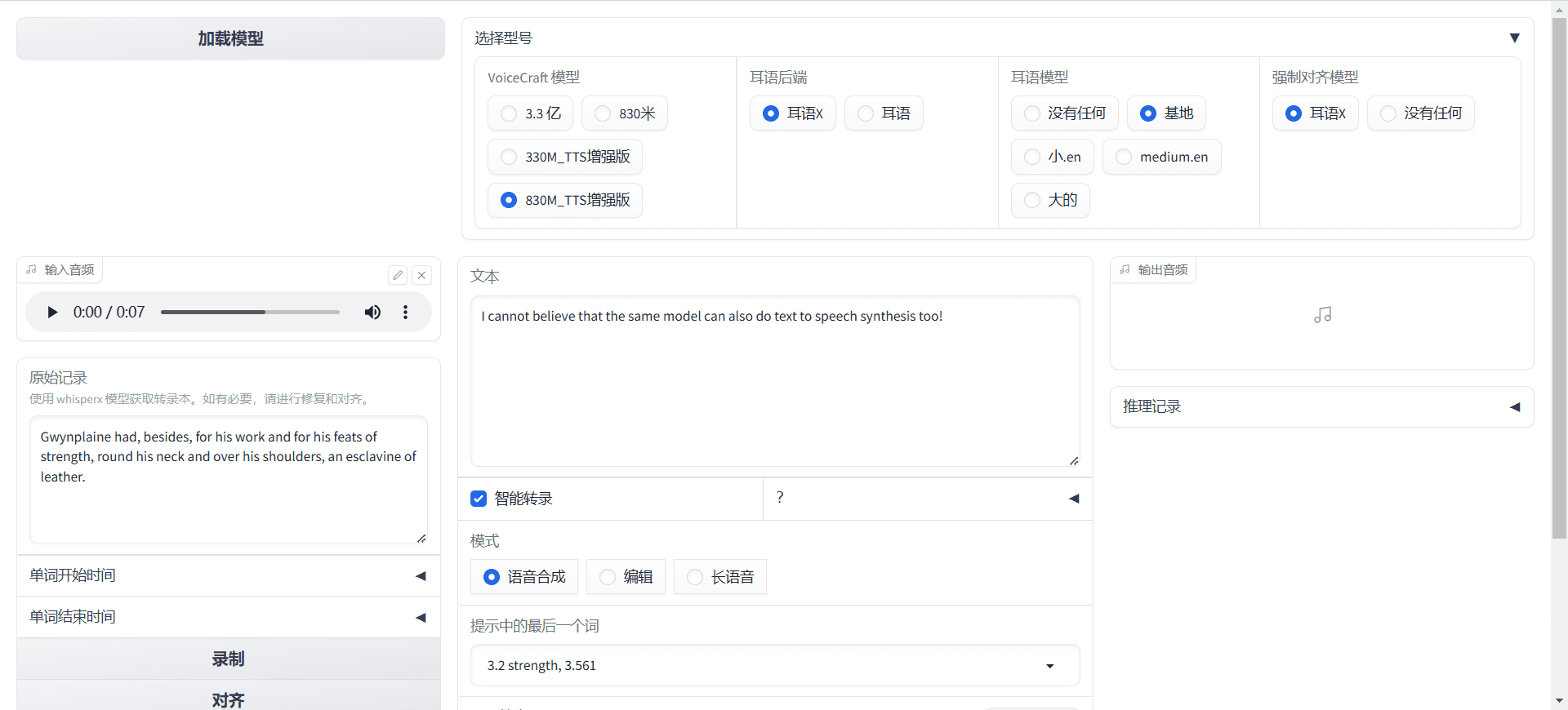
개요 VoiceCraft는 신경 코덱 언어 모델을 기반으로 하는 오픈 소스 음성 편집 및 제로 샘플 음성 합성 툴입니다. 기존 음성 시퀀스에 대한 삽입, 삭제 및 교체 작업을 가능하게 하는 혁신적인 코드화된 시퀀스 생성 방법을 사용하여 자연스럽고 일관된 편집 음성을 생성할 수 있습니다.
일반 소개 에이전트네트워크프로토콜(줄여서 ANP)은 지능형 에이전트(AI 에이전트)를 위한 안전하고 효율적인 커뮤니케이션 솔루션을 제공하는 데 중점을 둔 오픈 소스 프로토콜 프로젝트로, GitHub에서 호스팅되고 있습니다. 이 프로젝트는 ID와 암호화의 3계층 아키텍처를 통해 작동합니다...
종합 소개 XianyuAutoAgent는 개발자 shaxiu가 GitHub에서 오픈소스로 공개한 Idlefish 플랫폼용으로 설계된 지능형 고객 서비스 로봇 시스템입니다. AI 기술을 사용하여 7×24 시간 자동 근무를 수행하여 유휴 물고기 판매자가 응답할 수 있도록 지원합니다.
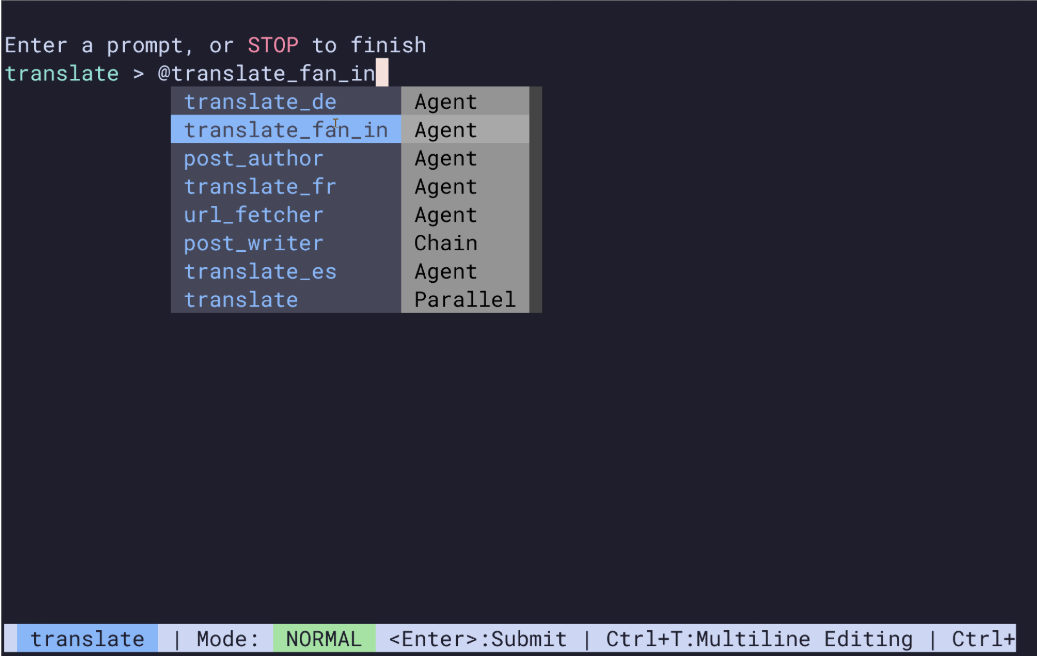
드림톡 종합 소개 드림톡은 칭화대학교, 알리바바 그룹, 화중과학기술대학교가 공동으로 개발한 확산 모델 기반 표정 토킹 헤드 생성 프레임워크입니다. 주로 노이즈 감소 네트워크, 스타일 인식 립 전문가, 스타일 예측기의 세 부분으로 구성되어 있으며, 다음을 기반으로 할 수 있습니다.
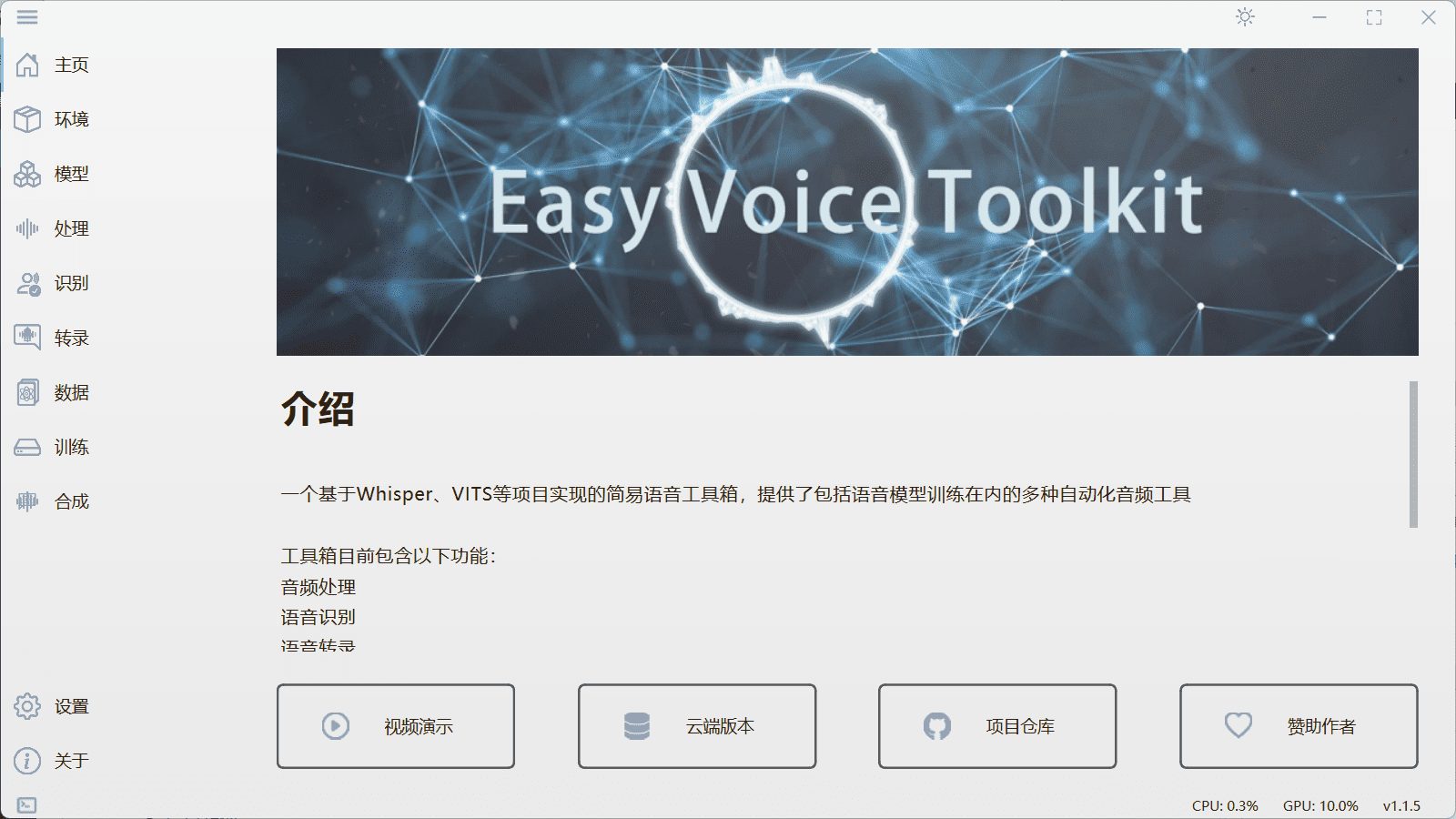
개요 Easy-Voice-Toolkit은 오픈 소스 음성 프로젝트에 기반한 다기능 툴킷으로 음성 인식, 음성 전사, 음성 변환, 데이터 세트 생성 및 모델 학습을 위한 다양한 자동화된 오디오 도구를 제공합니다. 사용자는 필요에 따라 이러한 도구를 선택적으로 사용할 수 있습니다...
일반 소개 ModelBest는 경량 고성능 대형 모델 개발에 주력하는 회사로, 첨단 AI 기술을 주류 가전제품 및 일상 생활의 모든 종류의 최종 장치에 적용하는 데 전념하고 있습니다. 극한의 연산 능력과 메모리 사용 효율을 갖춘 MiniCPM 시리즈 엔드 사이드 모델은 ...
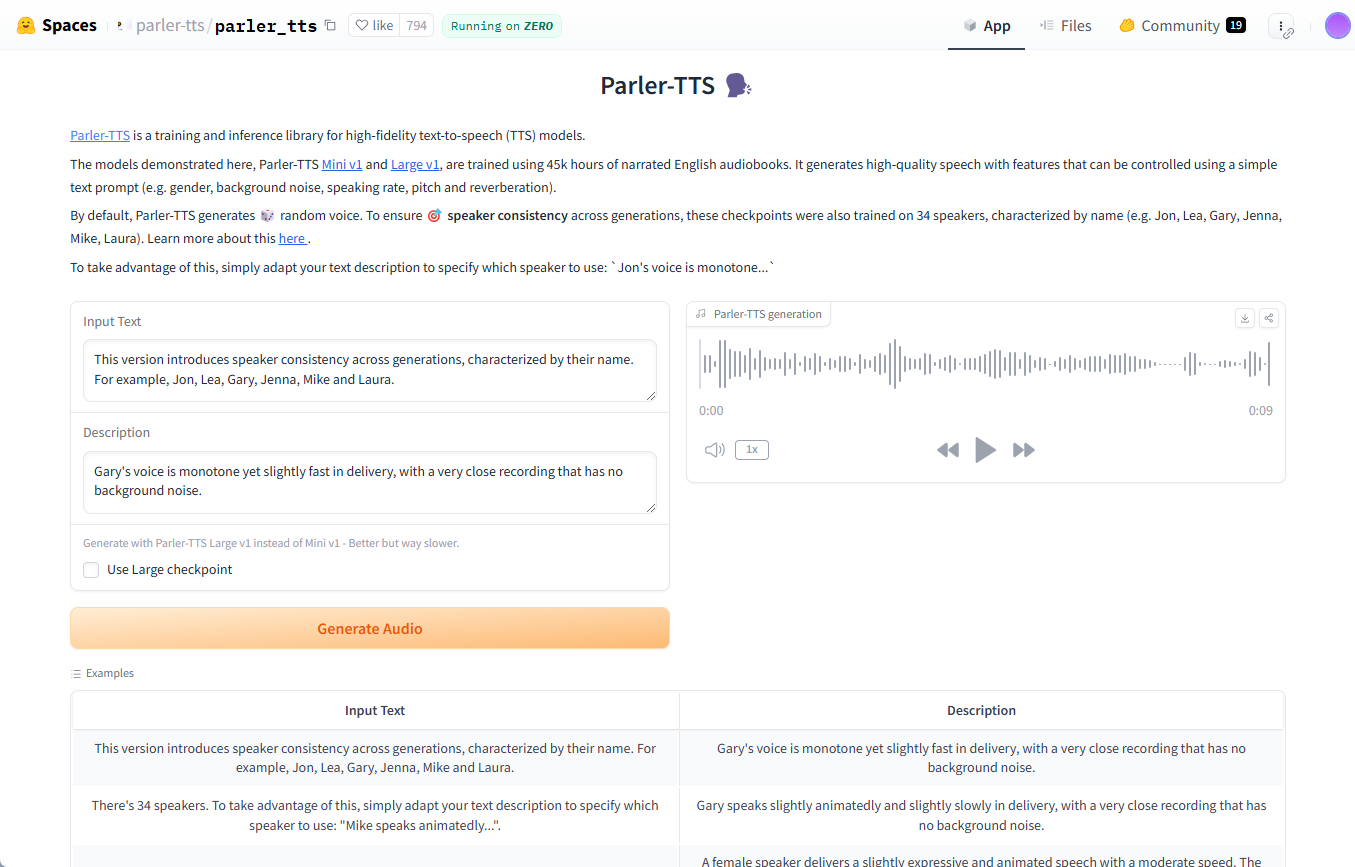
일반 소개 Parler-TTS는 고품질의 자연스러운 음성을 생성하도록 설계된 Hugging Face에서 개발한 오픈 소스 텍스트 음성 변환(TTS) 모델 라이브러리입니다. 이 모델은 특정 화자 스타일(예: 성별, 음조, 말하기 스타일 등)을 가진 입력 텍스트를 기반으로 음성을 생성할 수 있습니다.
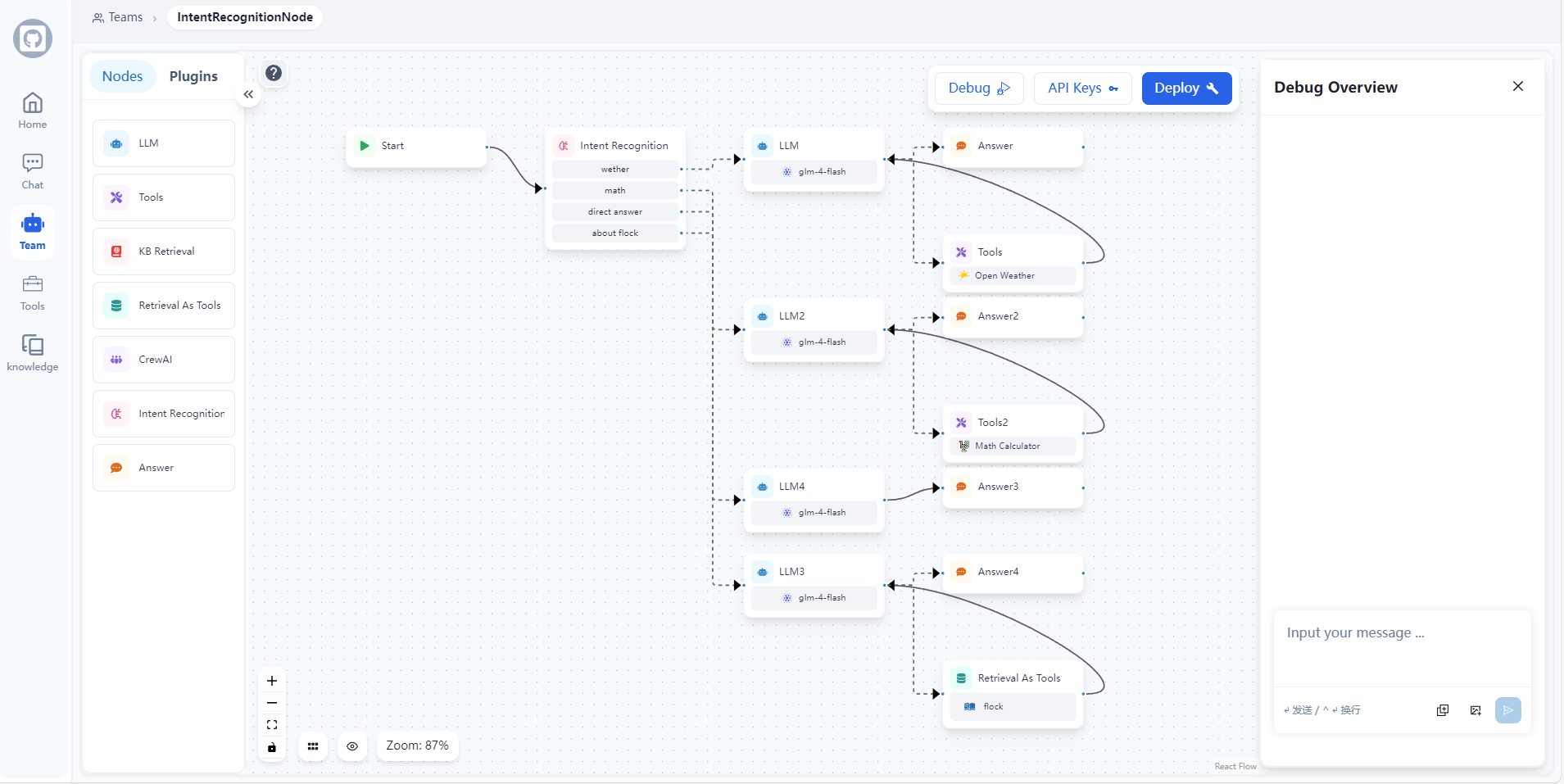
일반 소개 플록은 워크플로우를 위한 오픈 소스 로우코드 플랫폼으로, GitHub에서 호스팅되고 Onelevenvy 팀이 개발했습니다. LangChain과 LangGraph 기술을 기반으로 하며, 사용자가 채팅 머신을 빠르게 구축할 수 있도록 돕는 데 중점을 두고 있습니다.
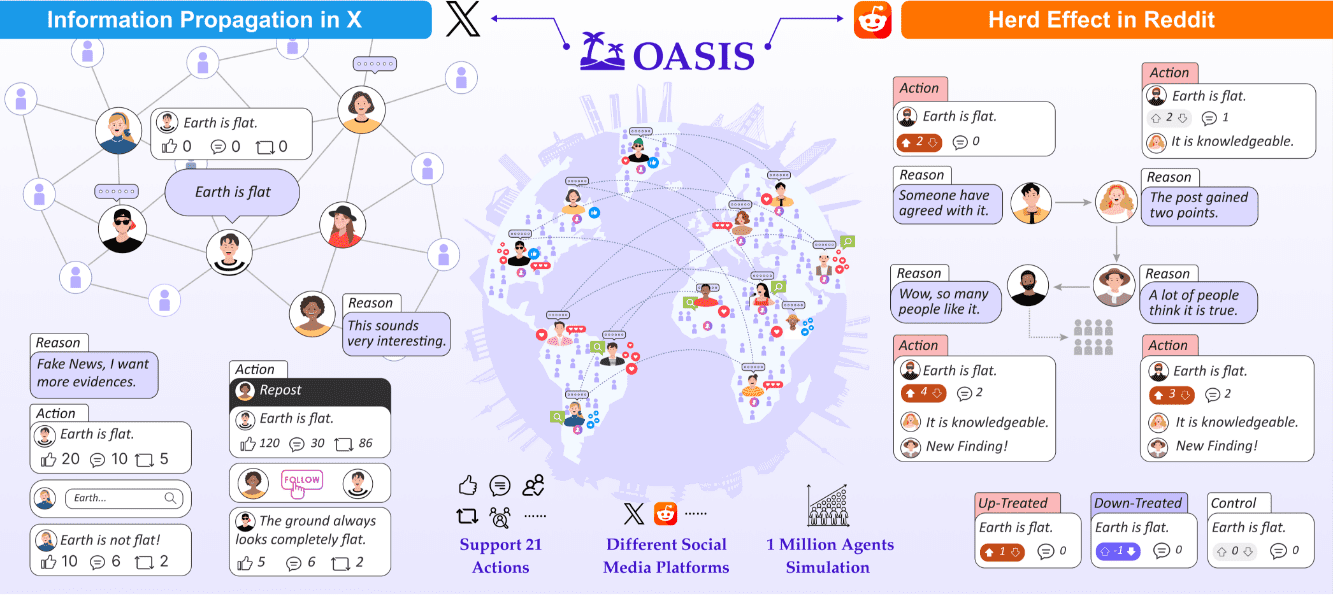
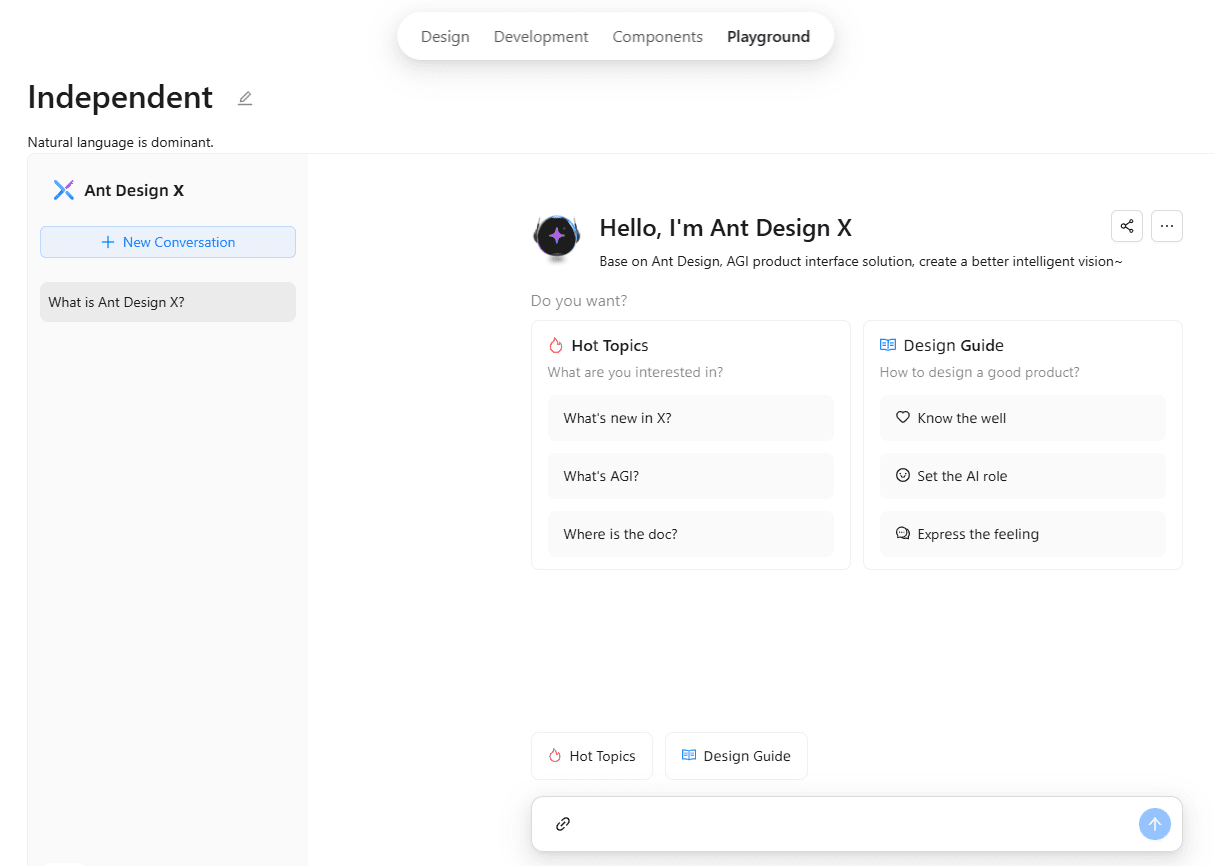
종합 소개 Ant Design X는 개발자가 AI 기반 대화 인터페이스를 빠르게 구축할 수 있도록 설계된 Ant Group에서 오픈소스화한 툴킷입니다. 풍부한 구성 요소와 템플릿 세트를 제공하고 OpenAI 표준과 호환되는 모델 통합을 지원하며 지능형 고객 서비스, AI 어시스턴트 등 다양한 애플리케이션에 적합합니다.
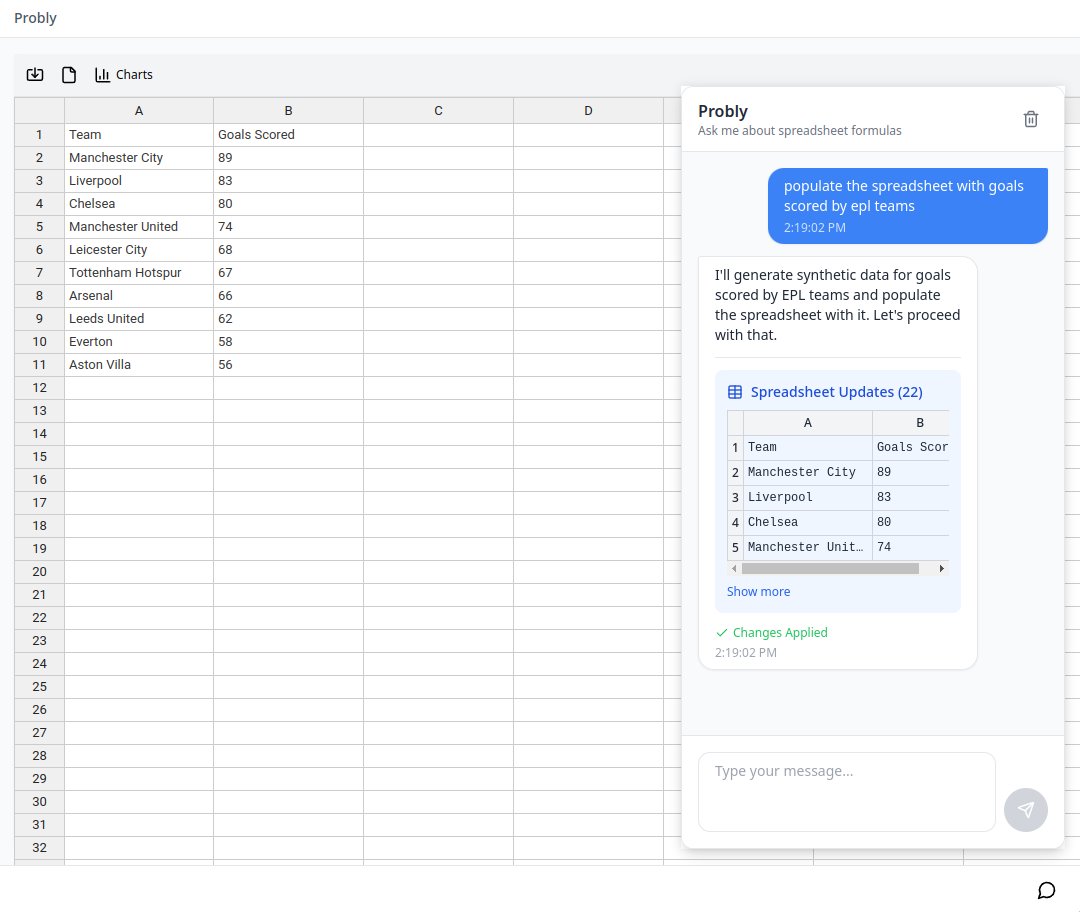
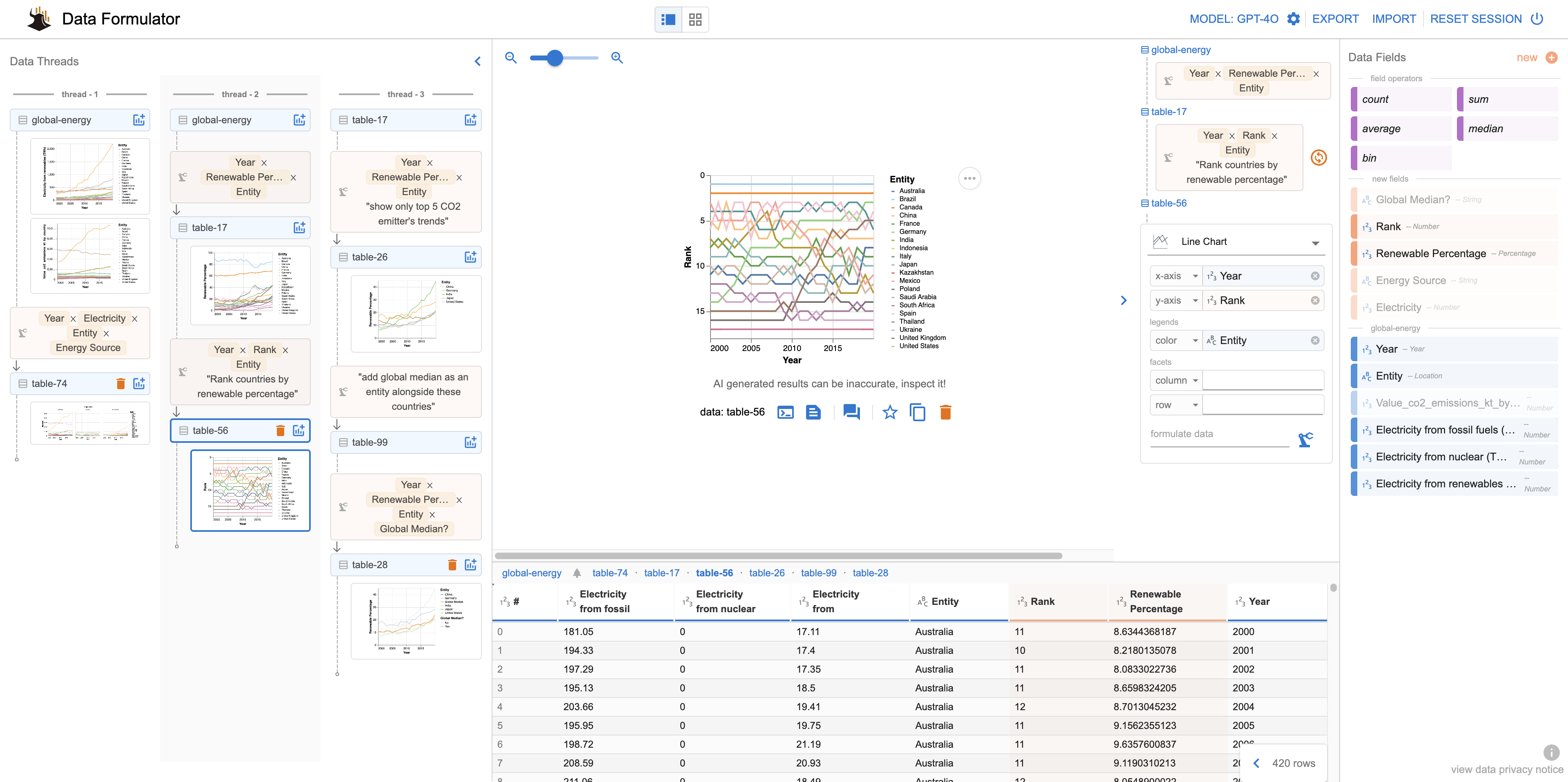
일반 소개 데이터 포뮬레이터는 Microsoft Research에서 개발한 오픈 소스 AI 기반 데이터 시각화 도구입니다. 이 도구는 그래픽 사용자 인터페이스(GUI)와 자연어 입력(NL)을 결합하여 사용자가 간단한 상호 작용과 명령을 통해 빠르게 만들고 반복할 수 있게 해 줍니다.
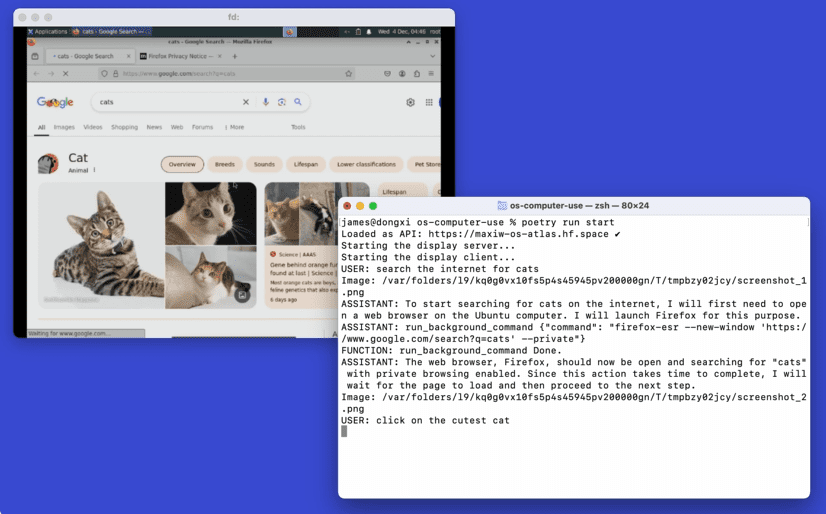
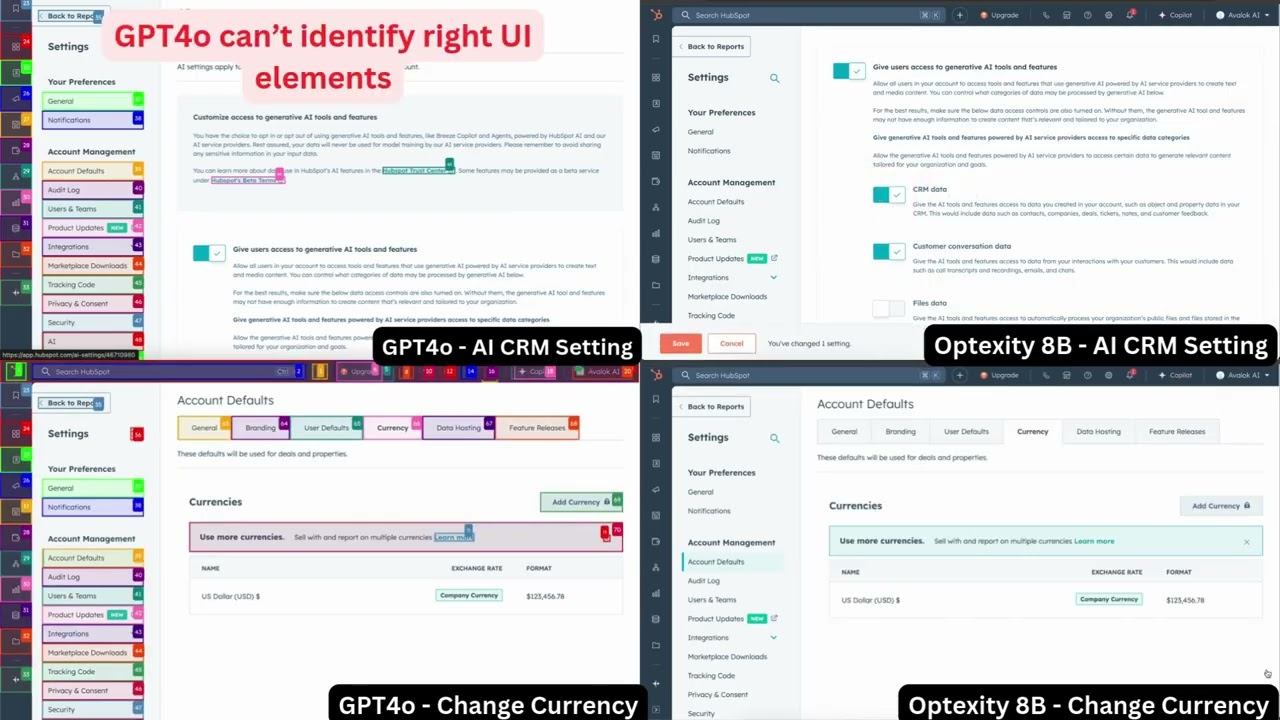
일반 소개 옵텍스티는 옵텍스티 팀이 개발한 GitHub의 오픈 소스 프로젝트입니다. 이 프로젝트의 핵심은 인간의 데모 데이터를 사용하여 컴퓨터 작업, 특히 웹 페이지 작업을 완료하도록 AI를 훈련시키는 것입니다. 이 프로젝트에는 다음과 같은 세 가지 코드 라이브러리가 포함되어 있습니다.
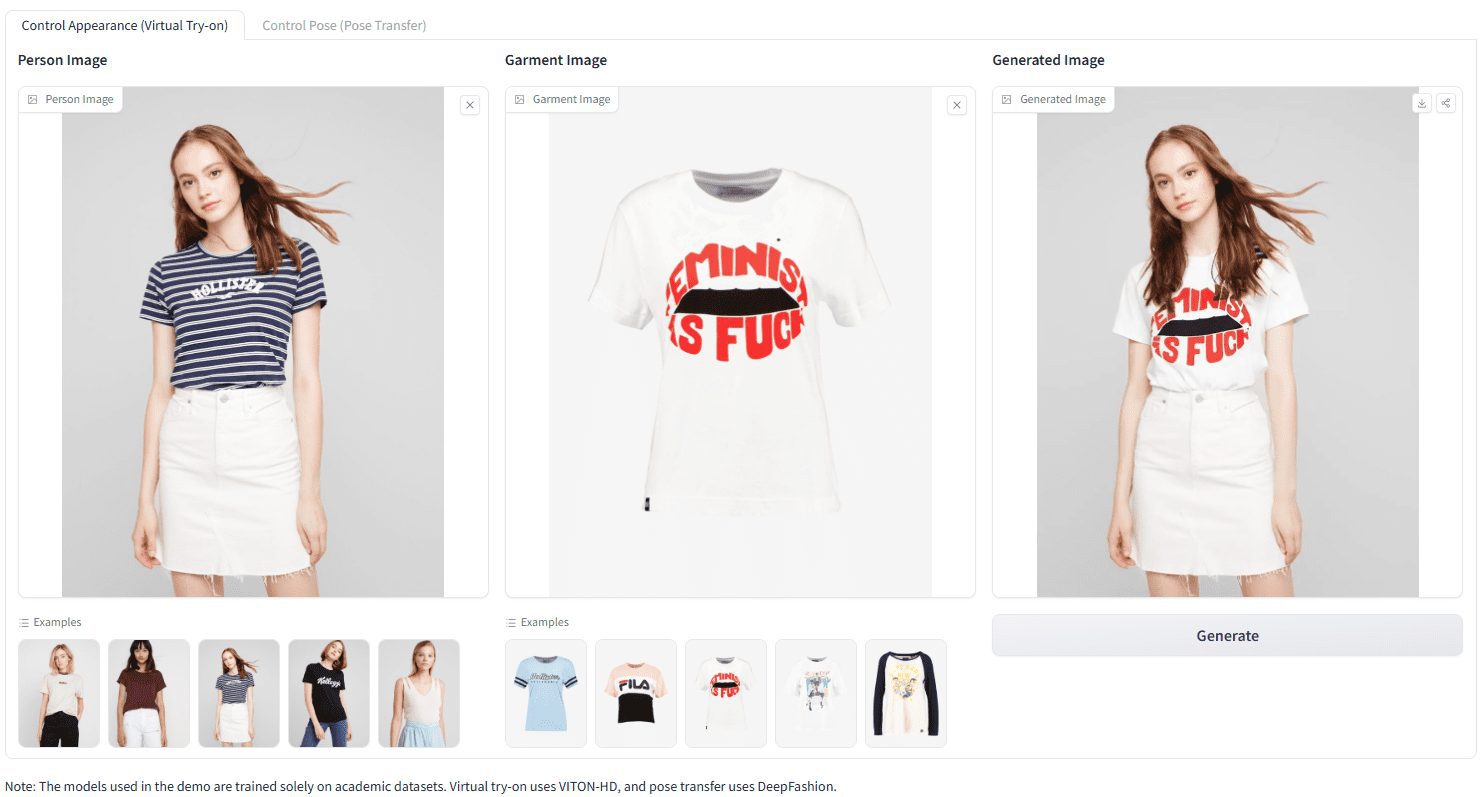
개요 레파는 제어 가능한 캐릭터 이미지를 생성하기 위한 통합 프레임워크로, 캐릭터의 외형(예: 가상 피팅)과 포즈(예: 포즈 전송)를 정밀하게 조작할 수 있습니다. 이 프레임워크는 대상 쿼리가 주의 레이어에서 올바른 참조 키에 집중하도록 지시하여 세밀한 디테일의 왜곡을 크게 줄입니다.
일반 소개 SegAnyMo는 UC 버클리와 북경대학교의 연구팀이 개발한 오픈 소스 프로젝트로, Nan Huang 등의 멤버가 참여하고 있습니다. 이 도구는 동영상 처리에 중점을 두고 있으며 동영상에서 사람, 동물 또는... 등 임의의 움직이는 물체를 자동으로 식별하고 세그먼트화할 수 있습니다.
일반 소개 TripoSG는 단일 이미지에서 고품질 3D 모델을 생성하기 위해 VAST AI 연구팀에서 개발한 오픈 소스 프로젝트입니다. 이 프로젝트는 하이브리드 지도 학습 및 고품질 데이터 세트와 결합된 대규모 정류기-흐름 변환기 기술을 사용하여 생성된 3D 모델이 다음과 같은 기능을 갖출 수 있도록 합니다.
일반 소개 MIDI-3D는 개발자, 연구원 및 크리에이터를 위해 단일 이미지에서 여러 오브젝트가 포함된 3D 장면을 빠르게 생성하기 위해 VAST-AI-Research 팀에서 개발한 오픈 소스 프로젝트입니다. 이 도구는 다중 인스턴스 확산 모델링 기법을 기반으로 합니다...
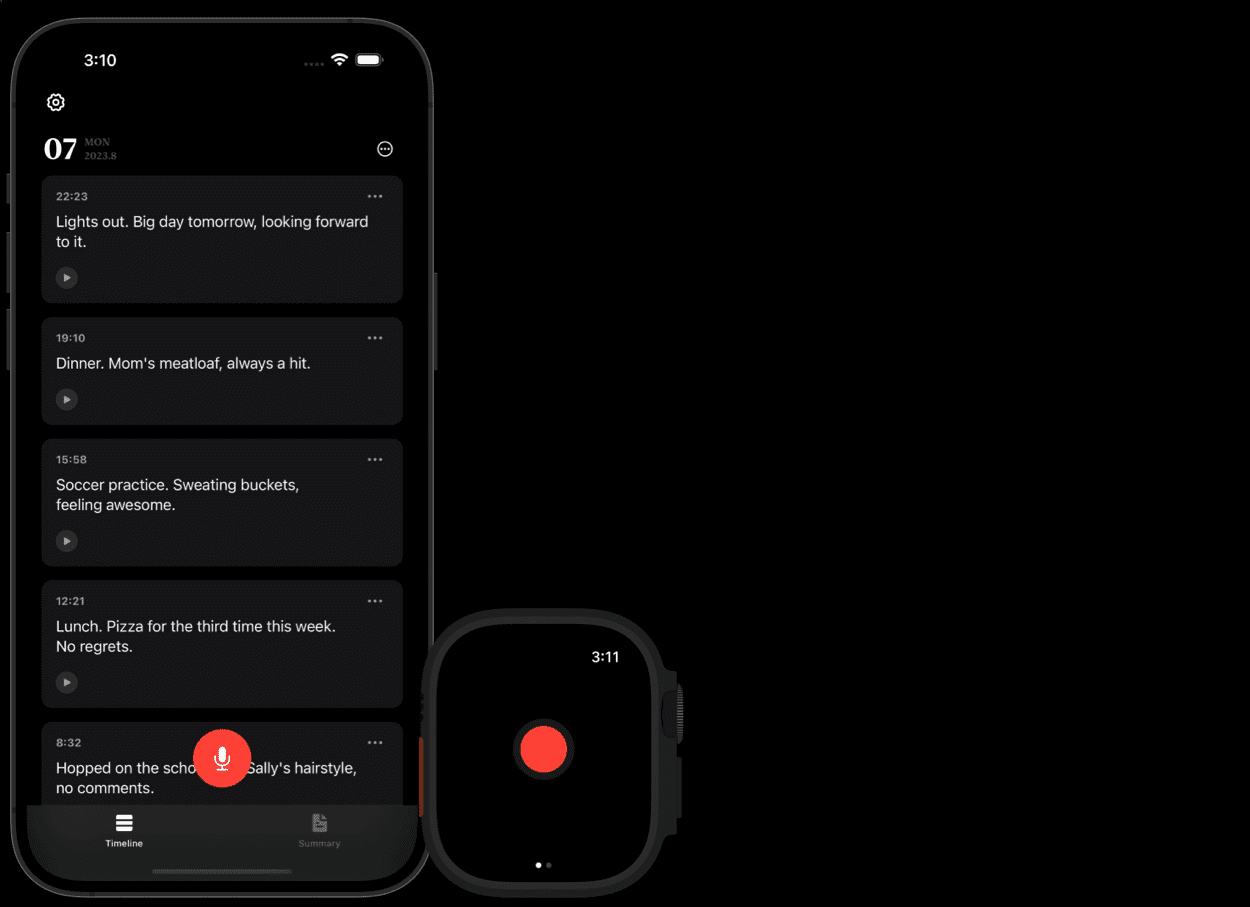
개요 ALog는 사용자가 음성으로 일상을 기록할 수 있도록 설계된 AI 기반 음성 일기장 애플리케이션입니다. duxins가 개발했으며 GitHub에서 오픈소스입니다. 사용자는 음성 입력을 통해 일기 항목을 녹음할 수 있으며, 앱은 음성을 자동으로 텍스트로 변환합니다....