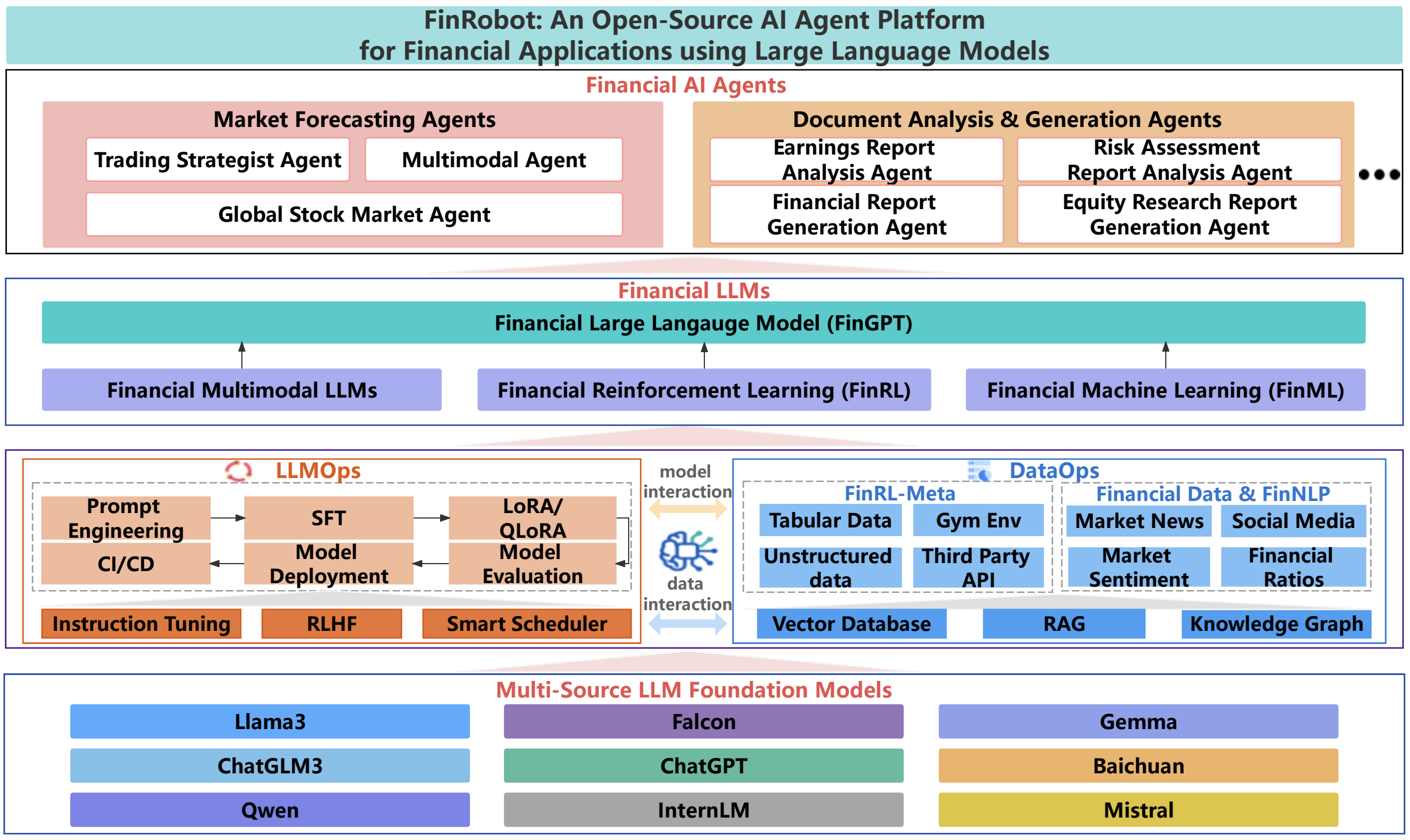
Comprehensive Introduction FinRobot is an open source AI intelligence platform developed by AI4Finance Foundation and designed for financial analytics. It not only covers traditional language models, but also incorporates a variety of AI technologies, aiming to provide a comprehensive solution for the financial industry.F...
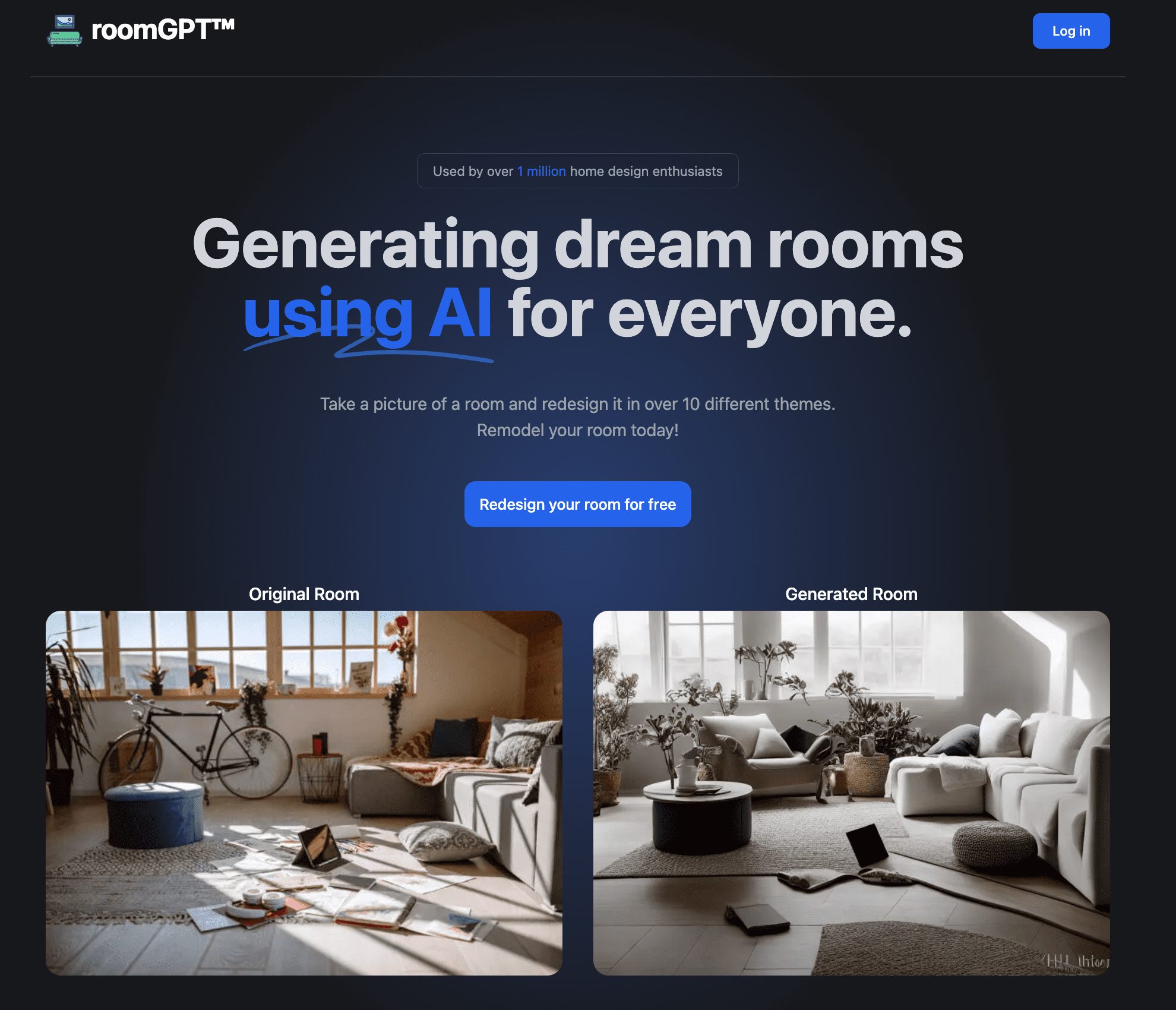
General Introduction RoomGPT is an open source project developed by GitHub user Nutlope that allows users to upload photos of rooms and generate redesigned versions of them using artificial intelligence technology. The project aims to give users access to professional-grade interior design without expensive designer fees...
LangBot is a large model-based instant messaging bot platform that supports multiple messaging platforms and large models. The platform adapts to QQ, WeChat (enterprise WeChat, personal WeChat), Flybook, Discord, OneBot and other messaging platforms, and supports Open...
General Introduction Kotaemon is an open source document Q&A tool designed to provide end-users and developers with Q&A functionality based on Retrieval Augmented Generation (RAG). The project is developed by Cinnamon and supports a variety of LLM API providers (e.g. OpenA...
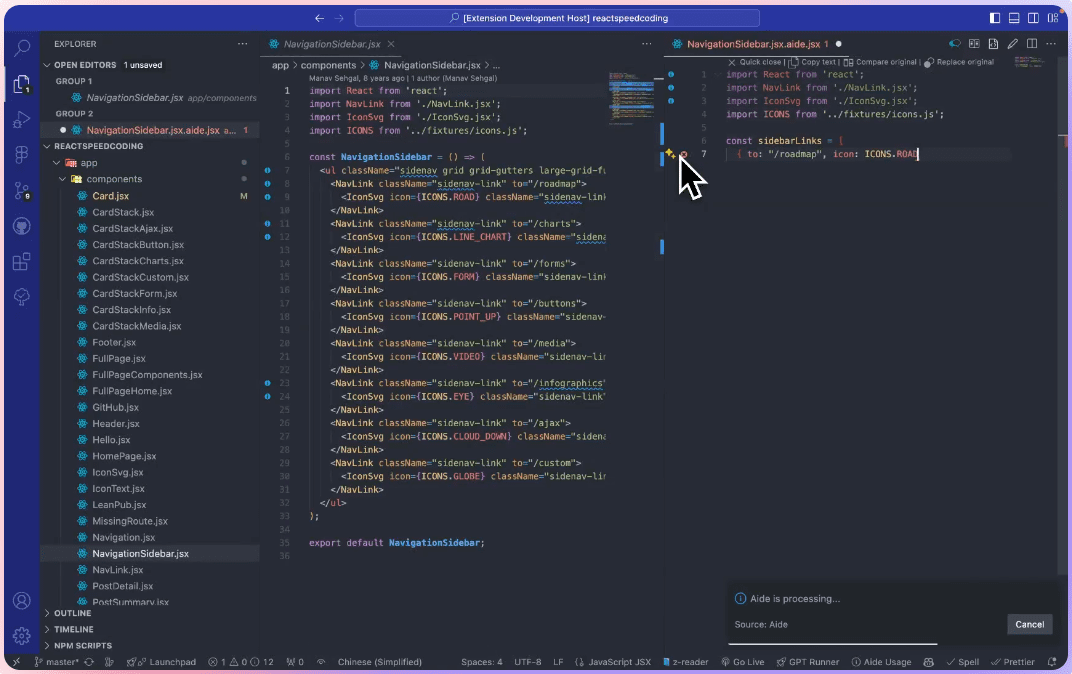
General Introduction AIDE (AI-assisted Development Extension) is a powerful VSCode AI-assisted development extension, focusing on providing unique and practical AI programming assistance. It is different from GitHu...
Comprehensive Introduction AnyText is a revolutionary multilingual visual text generation and editing tool developed based on the diffusion model. It generates natural, high-quality multilingual text in images and supports flexible text editing features. It was developed by a team of researchers and presented at ICLR 2024...
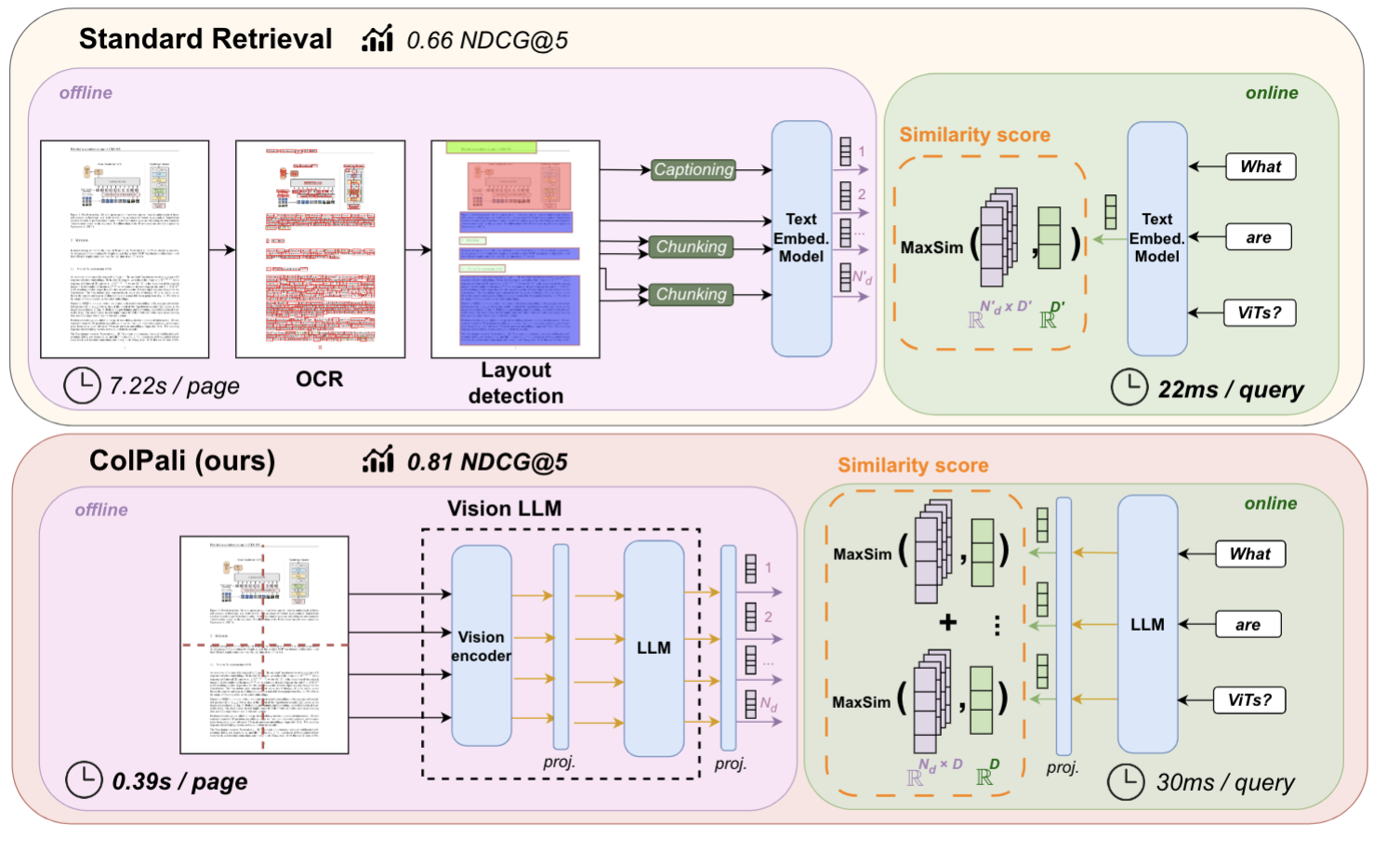
The goal of table recognition is to parse tables in images, accurately identify table structures and cell locations, and reduce them to structured table formats (e.g., HTML). In today's information age, a large amount of important tabular data still exists in an unstructured state (e.g., scanned documents with pictures of statistical tables...).
Comprehensive Introduction TxAgent is an open-source AI tool developed by Harvard University's Medical and Scientific Artificial Intelligence Team (MIMS) to help physicians analyze drug interactions and develop personalized treatment plans. It combines patient-specific situations through multi-step reasoning and real-time retrieval of biomedical knowledge...
General Introduction PandasAI is a Python based open source platform designed to simplify the process of data analysis through natural language processing techniques. Enabling users to work conversationally with databases (e.g. SQL, CSV, pandas, polars, mongodb, n...
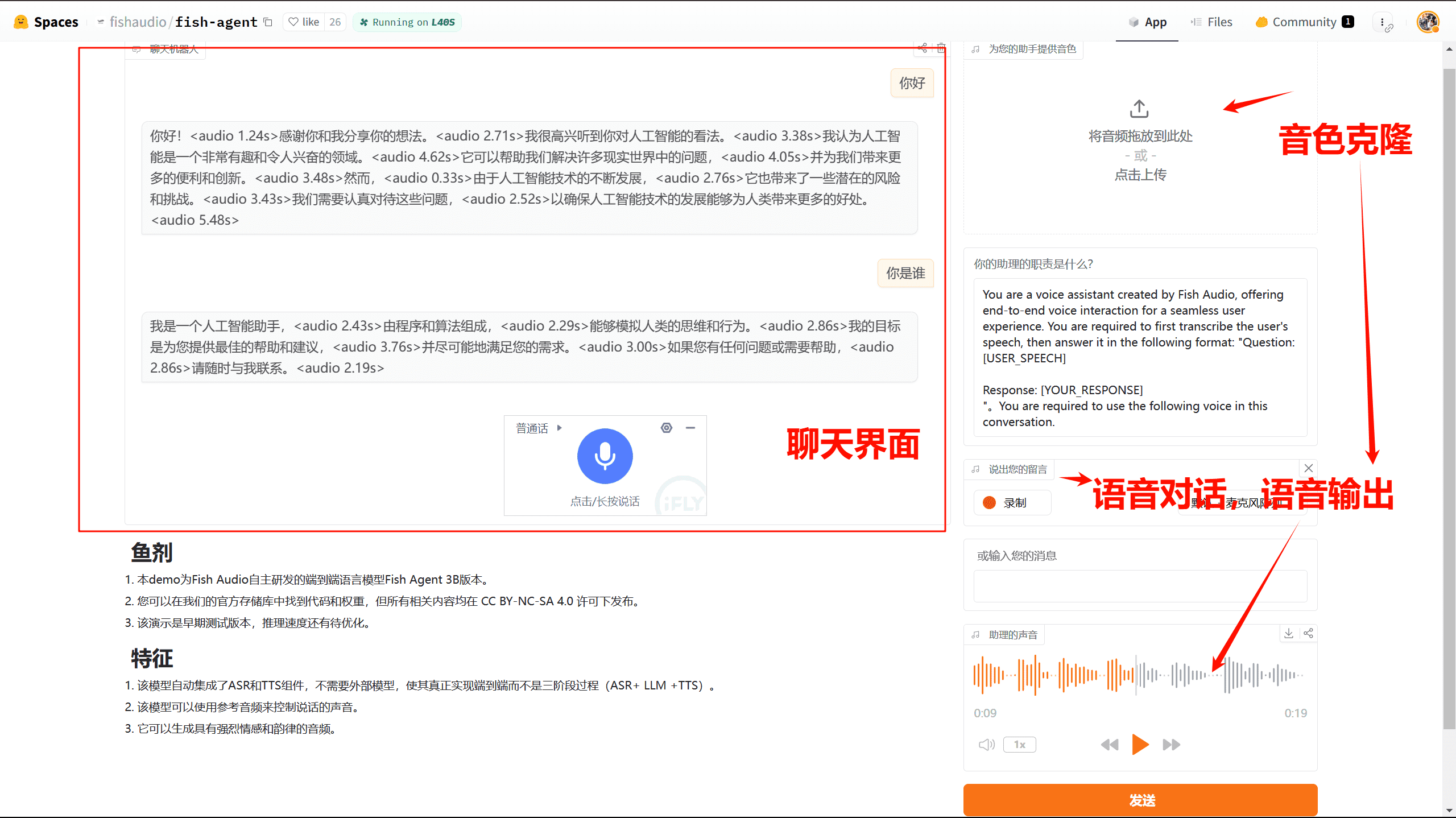
Comprehensive Introduction Fish Speech Derivative Project Fish Agent is a revolutionary end-to-end AI speech cloning system developed based on the V0.1 3B model architecture. As a fully end-to-end speech clone processing system, its most important feature is the use of innovative speechless...
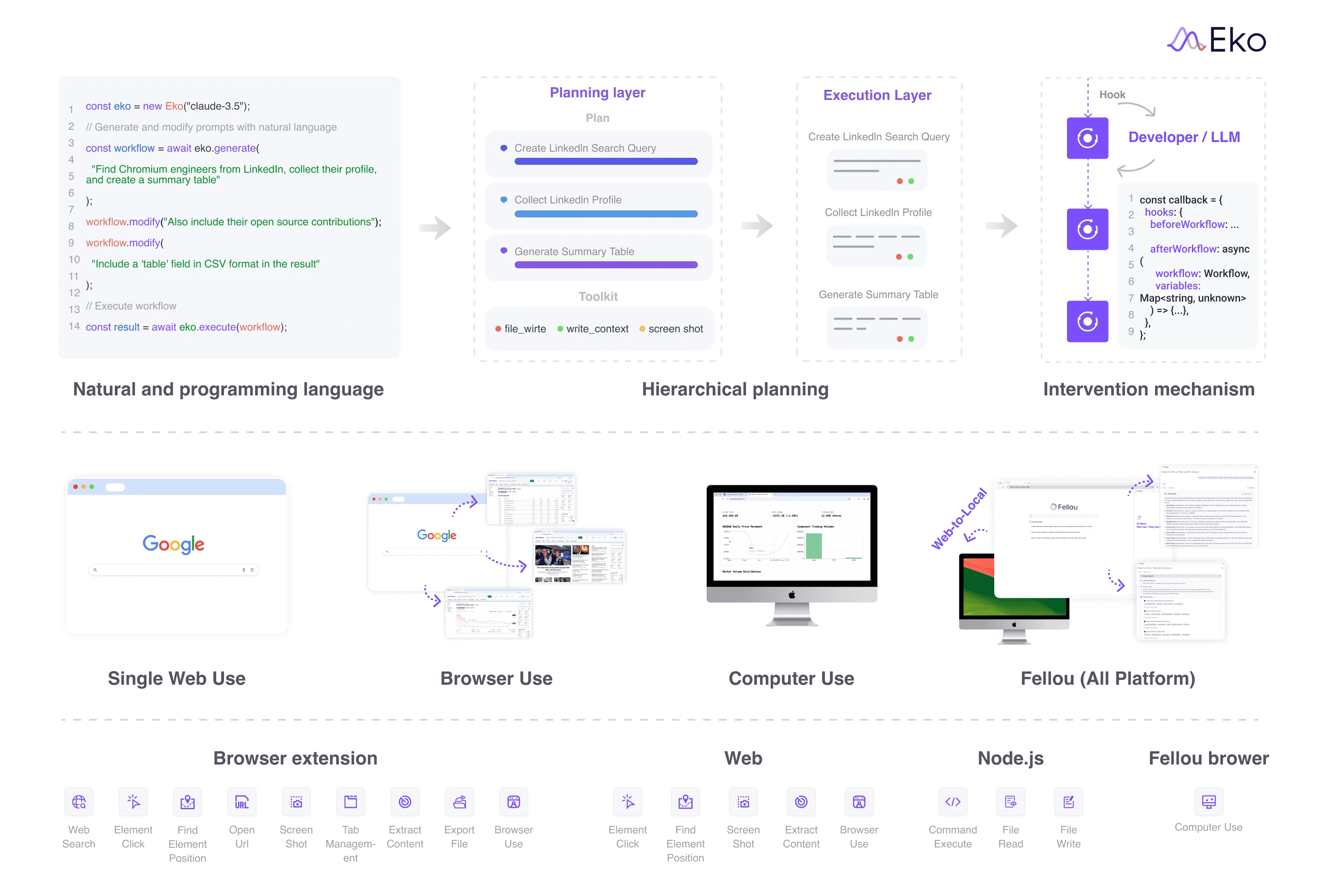
General Introduction Eko is a production-grade JavaScript framework designed to build efficient intelligent agent workflows through natural language descriptions. It is designed to enable developers to automate everyday tasks using AI technologies without deep programming.Eko provides a uni...
Comprehensive Introduction R1-V is an open source project that aims to achieve breakthroughs in visual language modeling (VLM) through low-cost reinforcement learning (RL). The project utilizes a verifiable reward mechanism to incentivize VLMs to learn generic counting abilities. Amazingly, R1-V's 2B ...
General Introduction HyperChat is an open source chat client developed by BigSweetPotatoStudio, hosted on GitHub, and designed to provide a comprehensive overview of the BigSweetPotatoStudio language model by integrating APIs from several large language models (LLMs) such as OpenAI, Cla...
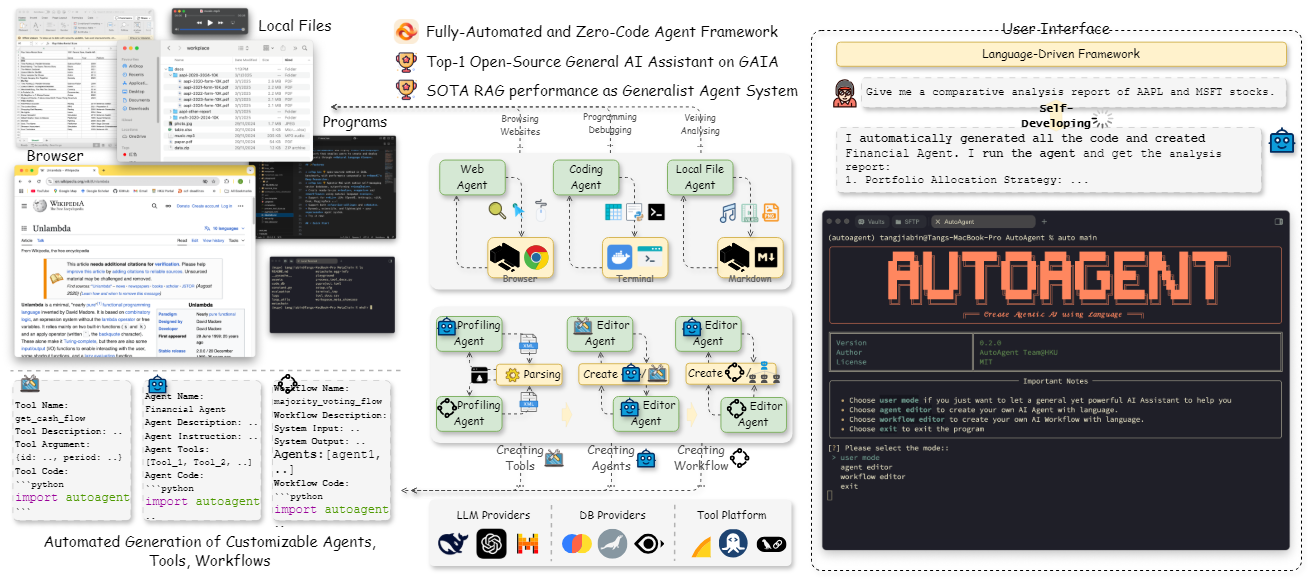
General Introduction AutoAgent is an open source AI intelligences framework developed by the Data Intelligence Laboratory of the University of Hong Kong (HKUDS) and hosted on GitHub.It allows users to rapidly create and deploy customized AI intelligences by describing their requirements in purely natural language, without any programming base...
Comprehensive introduction No front-end , pure configuration file configuration API channel . Just write a file can run up an API station of their own , the document has a detailed configuration guide , white friendly. uni-api is a project to unify the management of large model APIs , allowing a unified ...
General Introduction openapi-mcp-server is an open source tool designed to transform OpenAPI v3.1 compliant APIs into AI usable resources. It is maintained by janwilmake and is based on Model Contex...
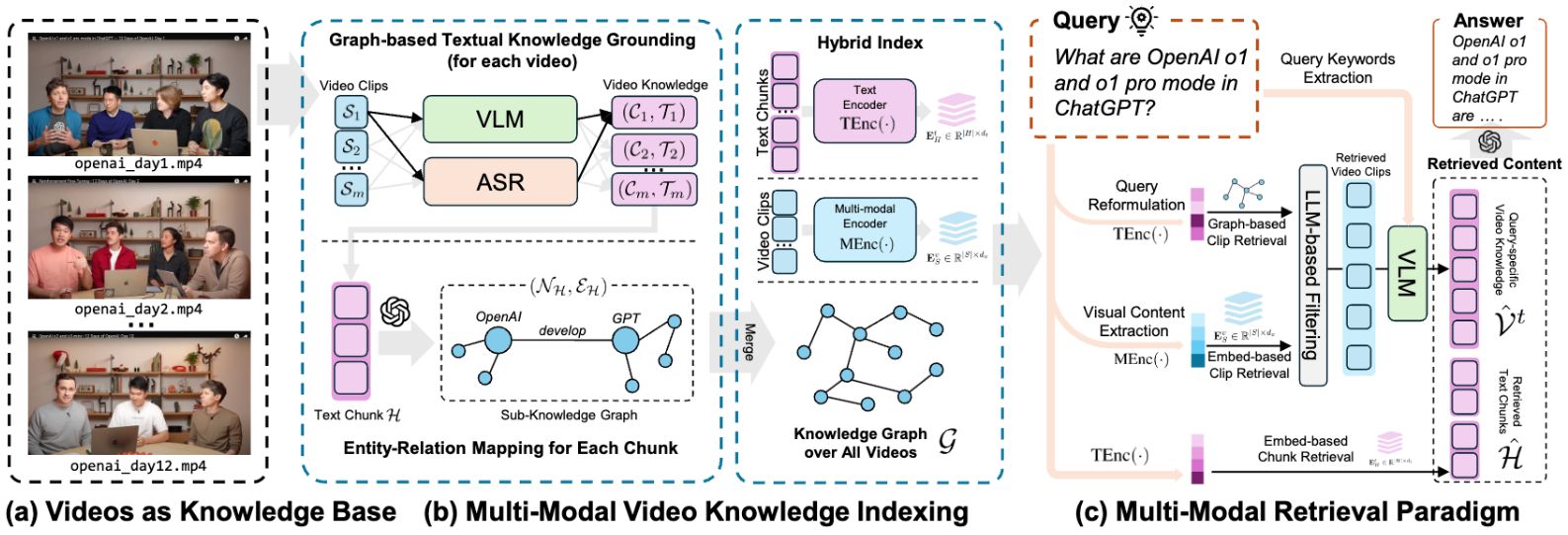
Comprehensive Introduction VideoRAG is a retrieval-enhanced generative framework designed for processing and understanding very long contextual videos. The tool combines a graph-driven textual knowledge base with hierarchical multimodal context encoding to efficiently process on a single NVIDIA RTX 3090 GPU...
Comprehensive Introduction Perplexica is an open source AI-driven search engine designed to provide answers that delve deep into the Internet. It uses advanced machine learning algorithms, such as similarity search and embedding techniques, to optimize search results and provide clear answers with cited sources.Perple...
General Introduction Genesis is a generative physics world designed for general purpose robotics and embodied AI learning. It provides a unified simulation platform that supports the simulation of a wide range of materials and physical phenomena.Genesis aims to unlock generative AI and physics simulation by combining...
General Introduction InfiniteYou is an open source project developed by the ByteDance Intelligent Creation team. It is based on Diffusion Transformers (DiTs) technology, using the FLUX.1-dev model, the core function is to allow users to upload a photo and enter a text description, generating...
General Introduction realtime-transcription-fastrtc is an open source project focused on converting speech to text in real time. It uses FastRTC technology to process low-latency audio streams , combined with the local Whisper model to achieve efficient ...
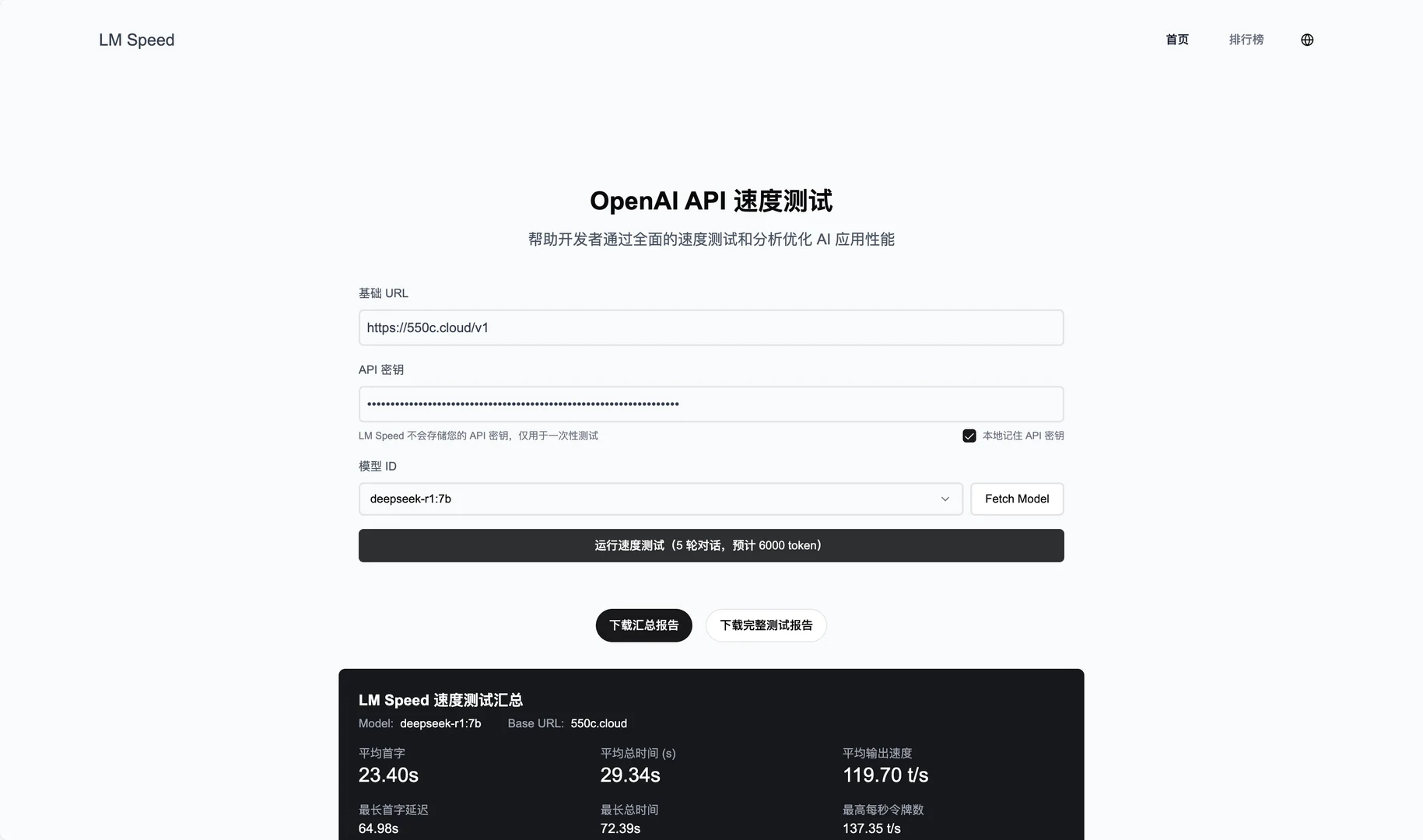
Comprehensive Introduction LM Speed is a tool designed specifically for AI developers, along with an online service site, lmspeed.net.Its core function is to test and analyze the performance of language model APIs, helping users to quickly identify speed bottlenecks and optimize calling strategies. This...
Comprehensive Introduction OpenAOE is an open source large model group chat framework, aiming to solve the problem of the lack of chat frameworks in the current market with multiple models responding in parallel. With OpenAOE, users can talk to multiple Large Language Models (LLMs) at the same time and get parallel output. The framework supports ...
General Introduction Morphik Core is an open source project developed by the morphik-org team and hosted on GitHub. It used to be called DataBridge Core, but is now renamed Morphik Core.This...
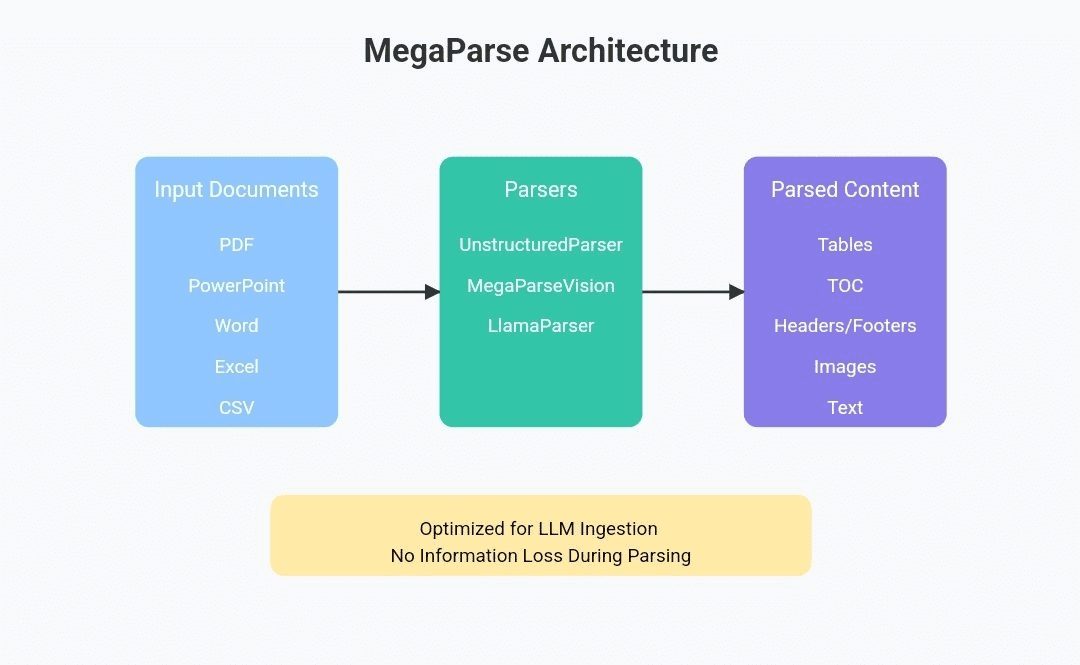
Comprehensive Introduction MegaParse is a powerful and versatile document parsing tool designed to optimize data processing for the Large Language Model (LLM). Whether you are working with text, PDF, PowerPoint presentations or Word documents, MegaParse...
General Introduction AI Chatbot Supabase is an open source AI chatbot template built on Next.js and Supabase. Developed by Vercel, the project aims to provide a fully functional and customizable chatbot solution. By ...
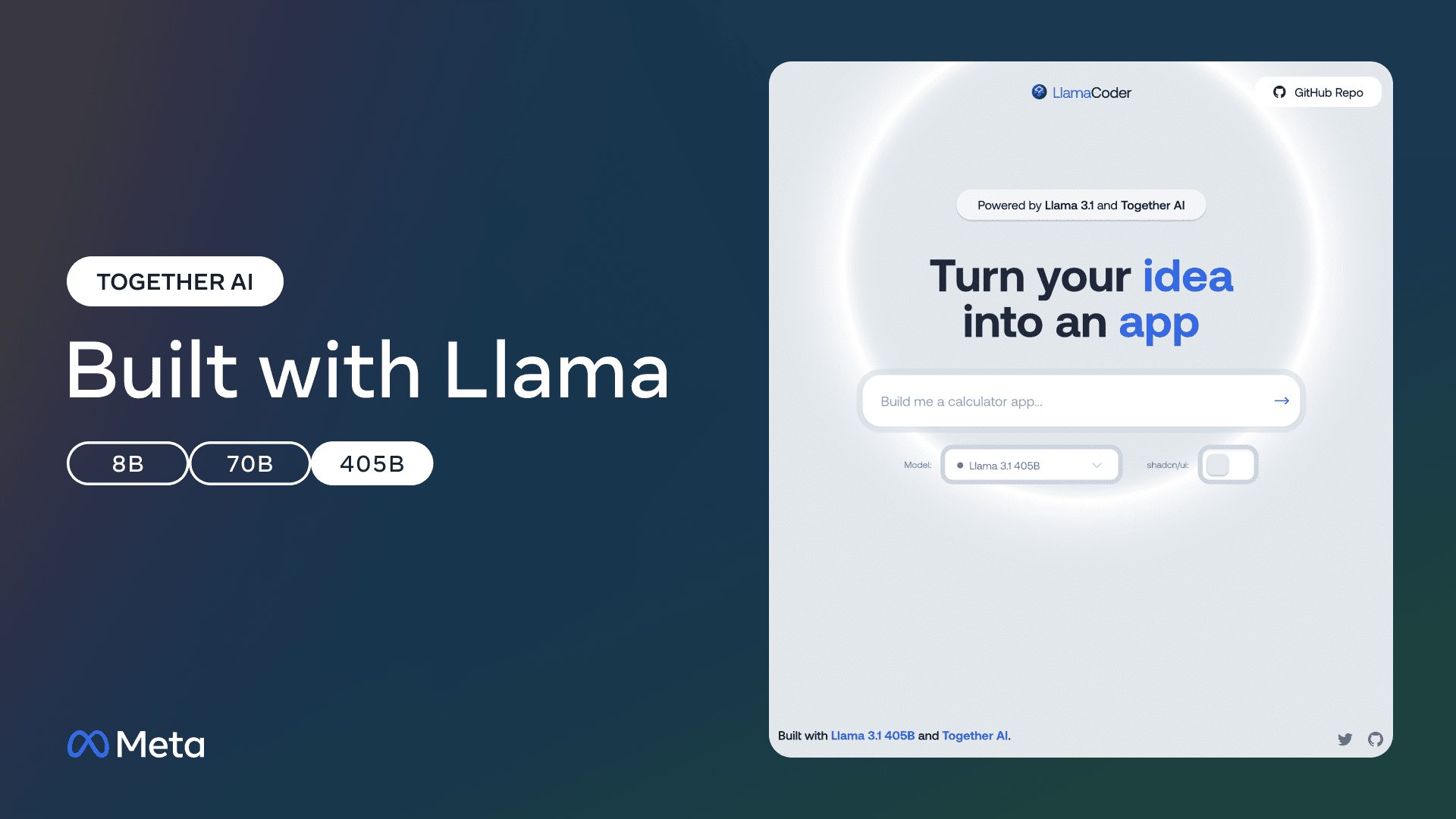
General Introduction LlamaCoder is an open source code generation tool based on Llama 3.1 and Together AI. It can generate small applications with simple prompts and is suitable for developers to quickly realize their ideas.LlamaCoder provides...
Comprehensive introduction WeClone is an open source project that uses WeChat chat logs and voice messages, combined with large language models and speech synthesis technology, to allow users to create personalized digital doppelgangers. The project can analyze the user's chat habits to train the model , but also a small number of voice samples to generate realistic sound...
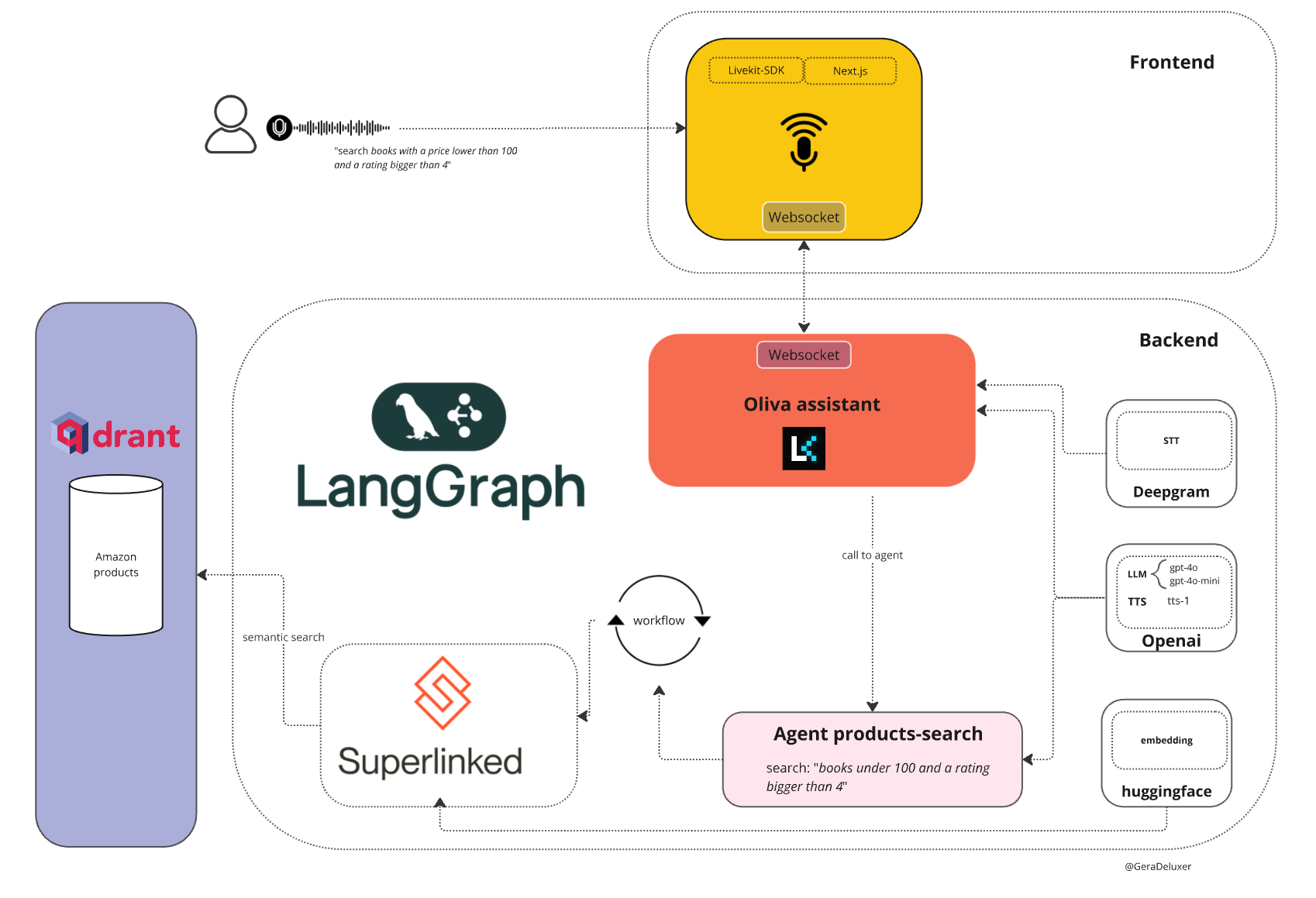
General Introduction Oliva is an open source multi-intelligence assistant tool developed by Deluxer on GitHub. It helps users search for product information in the Qdrant database through the collaboration of multiple AI intelligences. The main feature is that it supports voice operation...
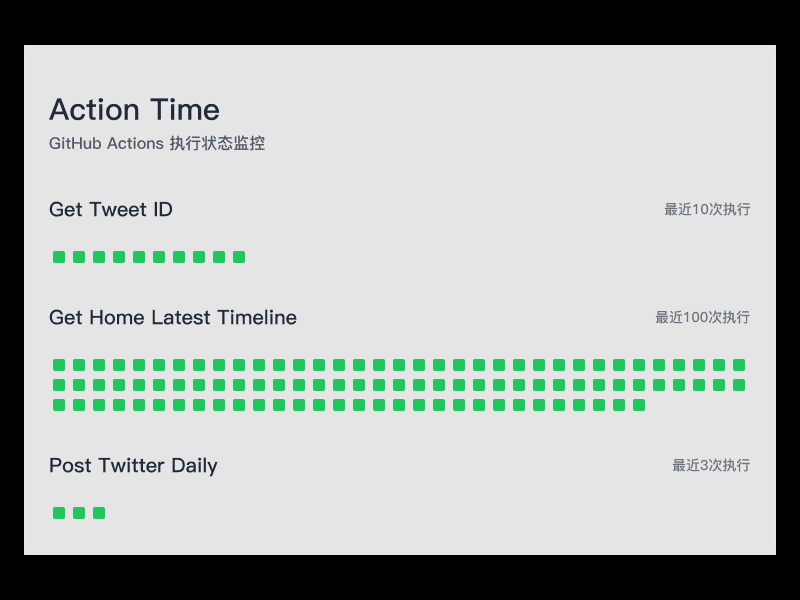
General Introduction X-Kit is an open source tool designed to crawl and analyze X (formerly Twitter) user data and tweets. Developed by GitHub user xiaoxiunique, the tool is designed to help users automate the process of obtaining basic information and tweets about a given X user and...
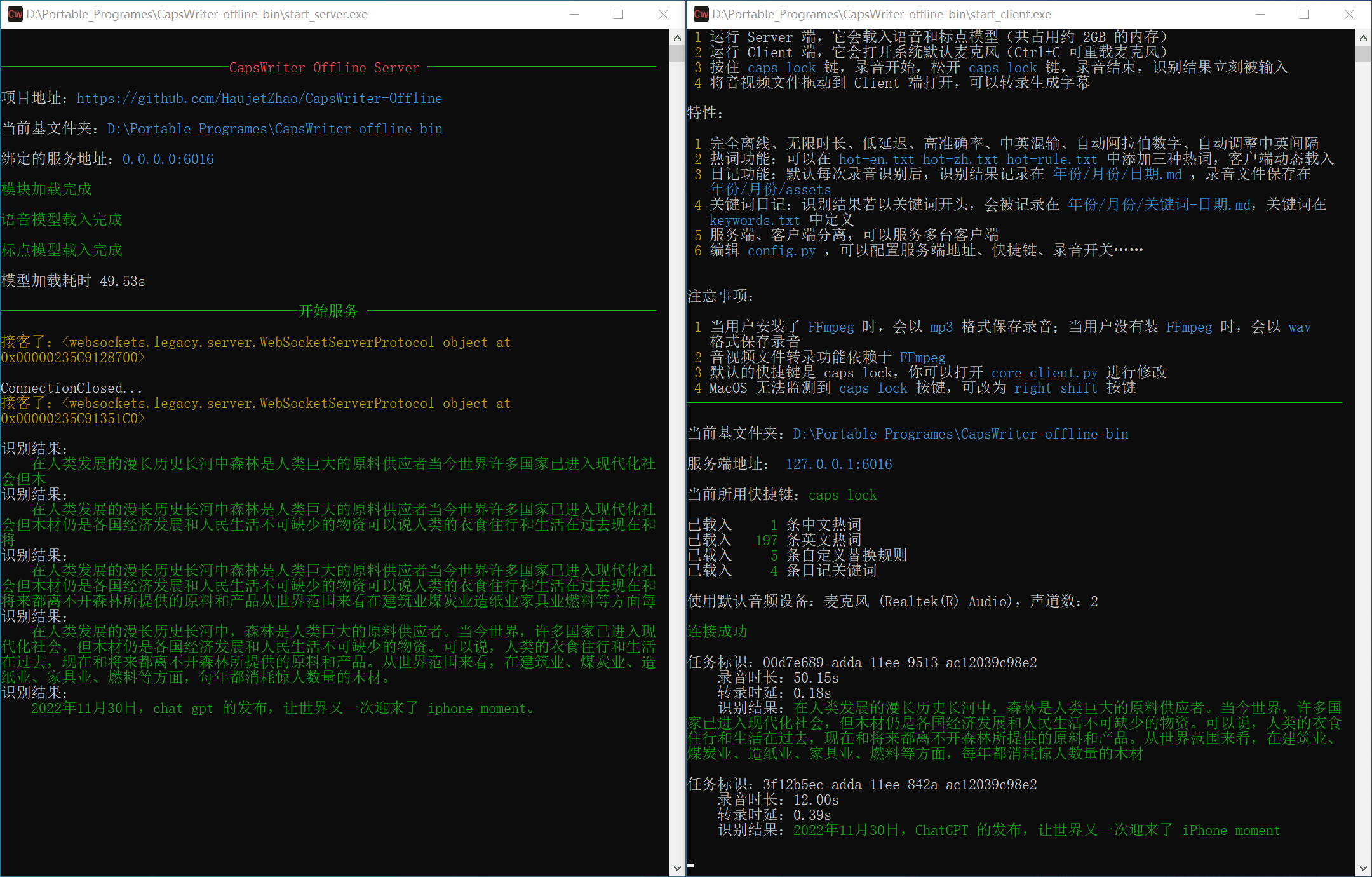
General Introduction CapsWriter-Offline is a voice input and subtitle transcription tool for PC, hosted on GitHub and built by developer HaujetZhao. It runs completely offline and does not require an Internet connection to realize speech-to-text and audio-visual...
General Introduction MyCoder is an open source project developed by the drivecore team and hosted on GitHub, aiming to provide developers with intelligent programming assistance through a command line interface. It is based on Anthropic's Claude AP...
General Description A module for fixing invalid JSON files, especially for parsing erroneous JSON data output by Large Language Models (LLMs). The module fixes common JSON syntax errors such as missing quotes, incorrect commas, unescaped characters and incomplete key-value...
General Introduction Vercel AI SDK is an open source tool developed by the Vercel team to help developers build AI applications using frameworks such as React, Svelte, Vue and Solid. It supports multiple language model providers...
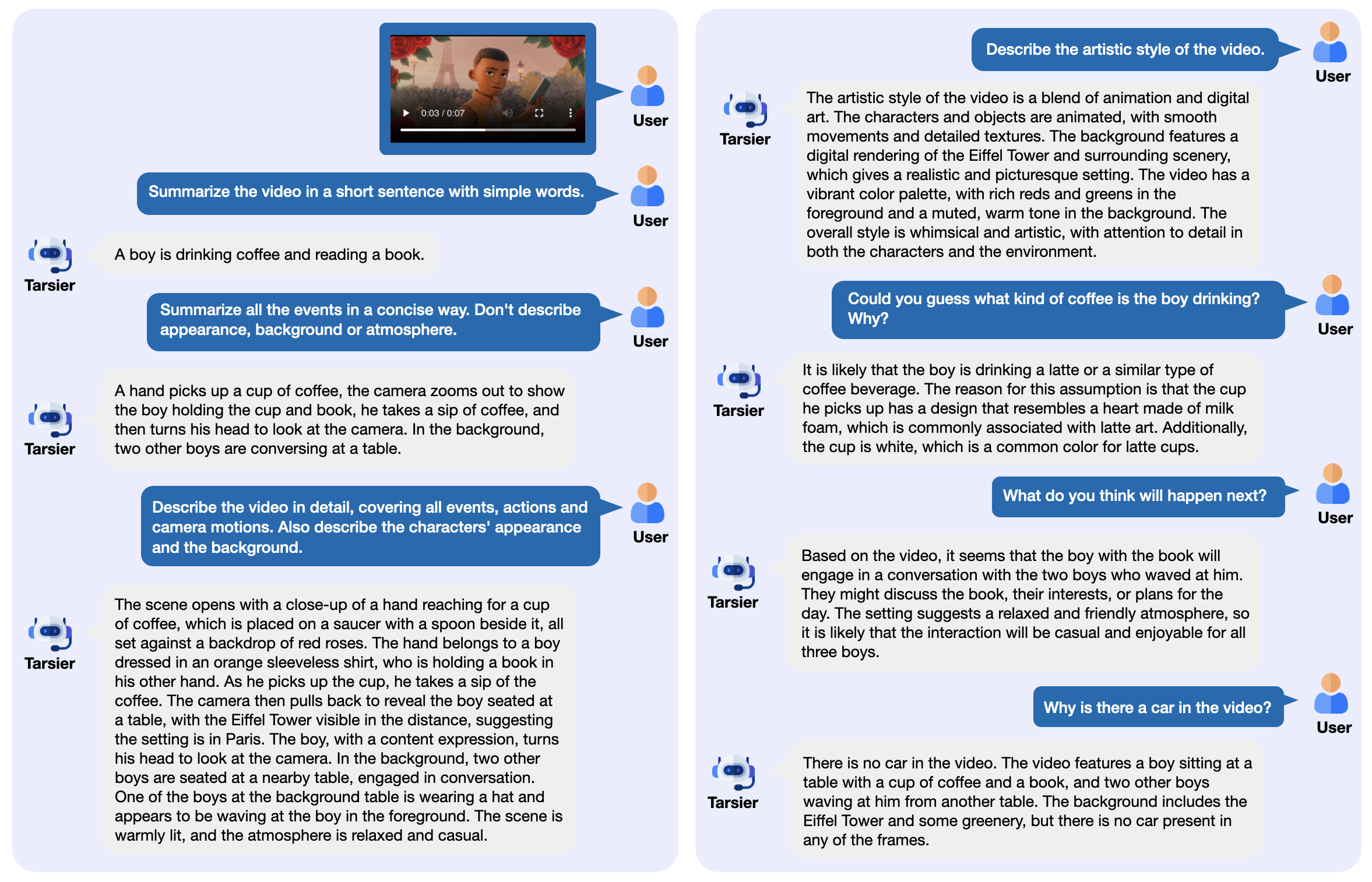
Comprehensive Introduction Tarsier is a family of open-source video-language models developed by ByteDance for generating high-quality video descriptions. It consists of a simple structure: the CLIP-ViT processes video frames, combined with a Large Language Model (LLM) to analyze...
Comprehensive Introduction DeepClaude is a high-performance Large Language Model (LLM) inference API and chat interface that integrates the chained inference (CoT) capabilities of DeepSeek R1 with the creativity and code generation of the Anthropic Claude model...
Comprehensive Introduction Kolors is a large-scale text-to-image generation model developed by the Racer team, based on potential diffusion techniques. The model is trained on billions of text-image data pairs, and is capable of generating high-quality, complex semantically accurate images with support for both Chinese and English input.Kolors in visual quality...
General Introduction AgentGPT is an open source project developed by the Reworkd team and hosted on GitHub, designed to allow users to autonomously create, configure, and deploy AI intelligences through a browser. Users simply set a goal, and AgentGPT can...
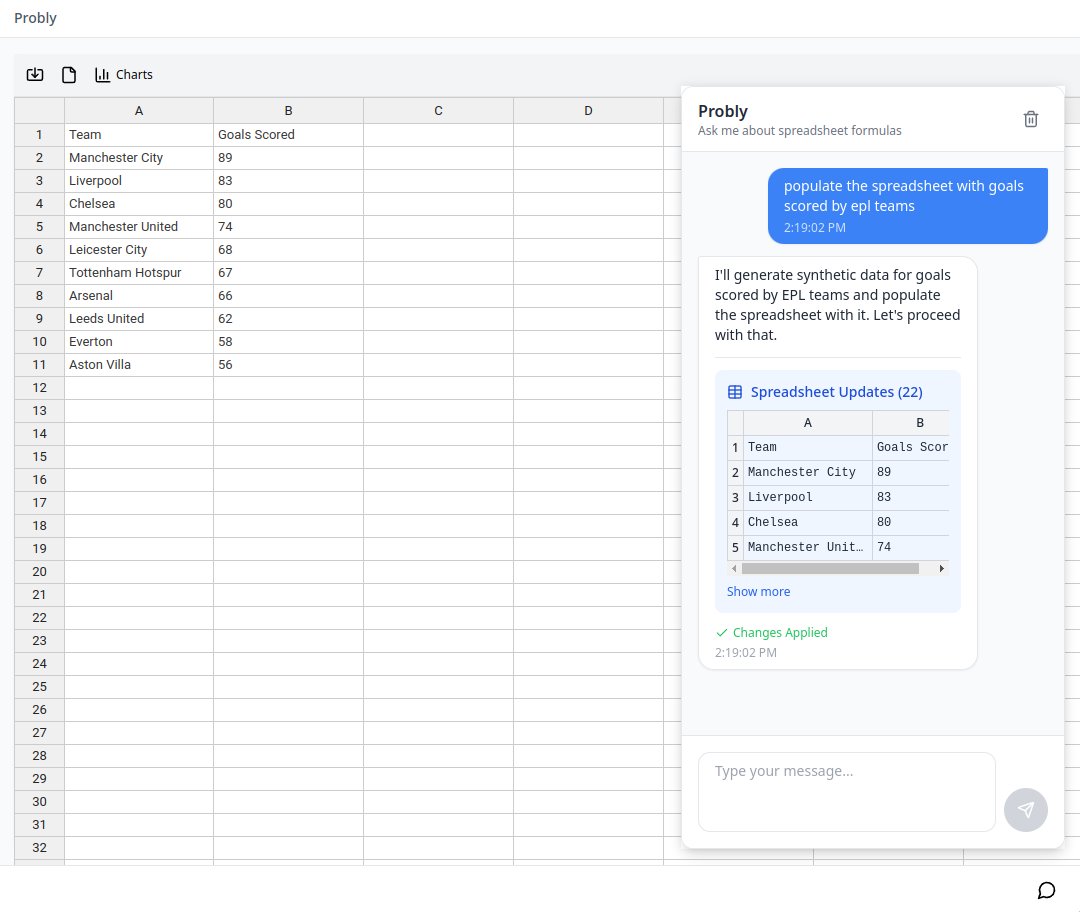
Comprehensive Introduction Probly is a spreadsheet tool developed by the PragmaticMachineLearning team and open-sourced on GitHub that combines the functionality of traditional spreadsheets with powerful AI data analysis capabilities. It not only supports the use of ...
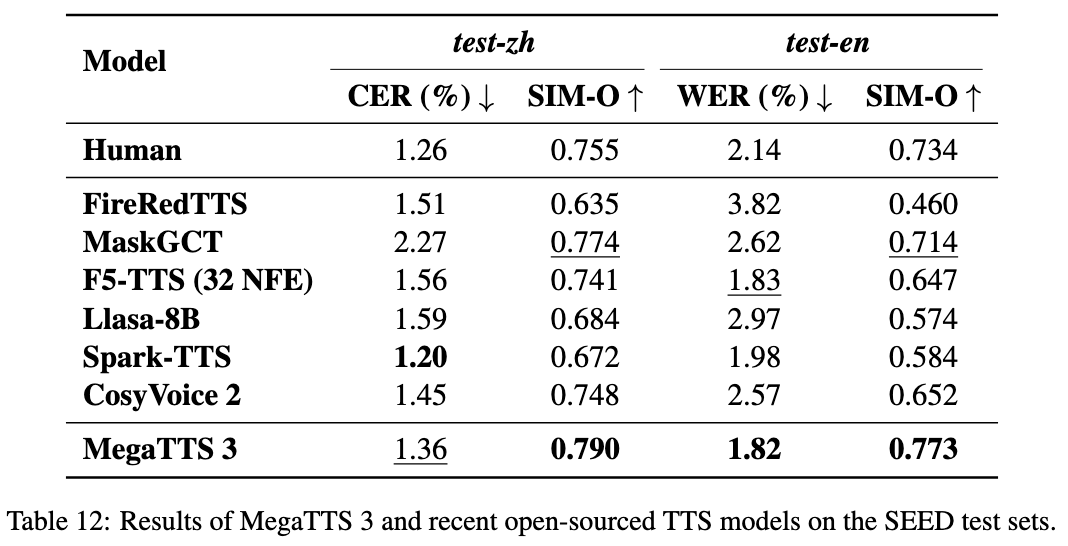
Comprehensive Introduction MegaTTS3 is an open source speech synthesis tool developed by ByteDance in cooperation with Zhejiang University, focusing on generating high-quality Chinese and English speech. Its core model is only 0.45B parameters , lightweight and efficient , support for mixed Chinese and English speech generation and speech cloning . The project is hosted on ...
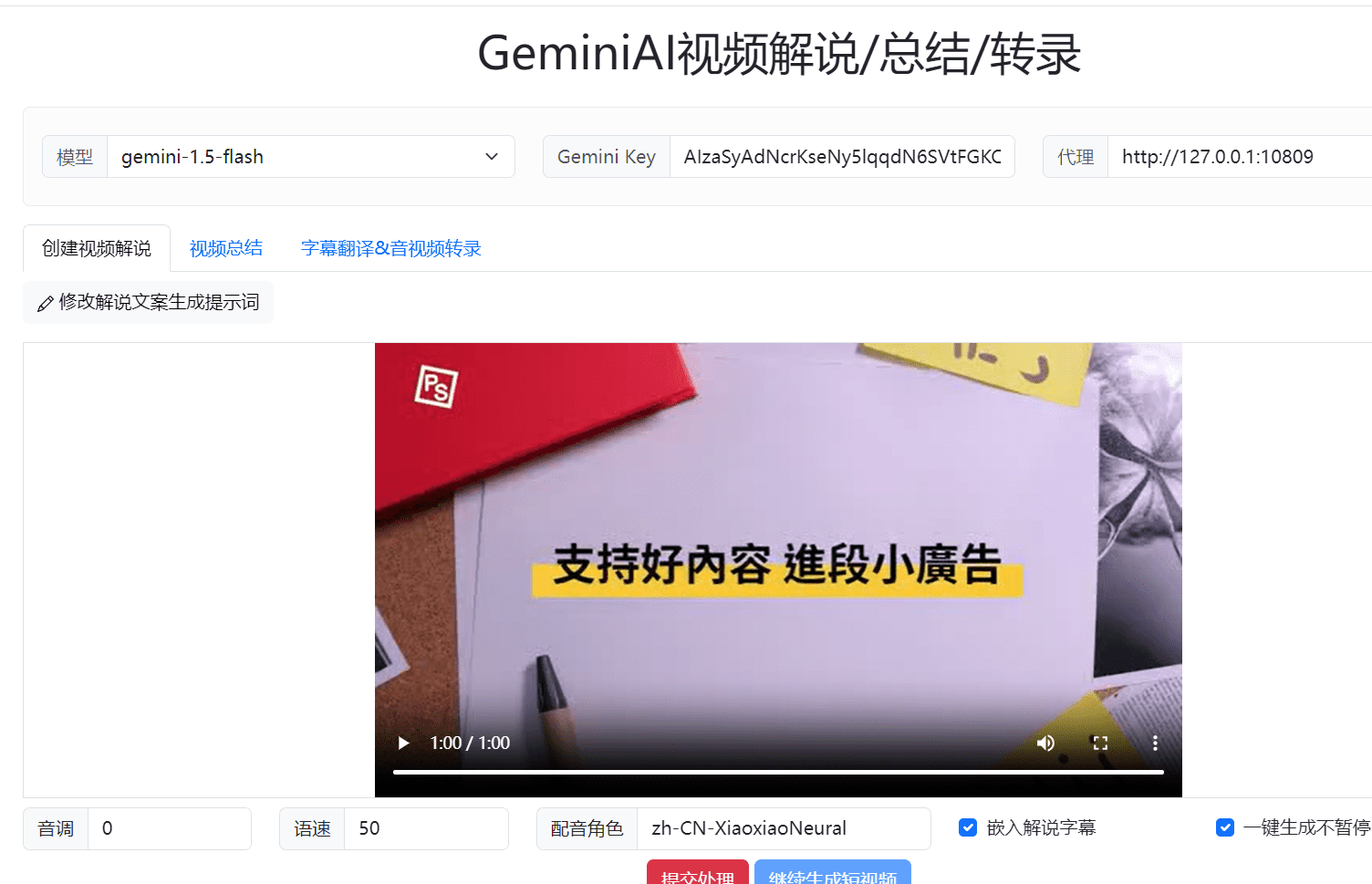
Comprehensive Introduction AI2SRT is an open source project that utilizes the GeminiAI Big Model to generate short narrated videos and video summaries for long videos with one click, while supporting audio and video transcription subtitles. The project aims to simplify the video content creation process and provide efficient subtitle generation and translation functions. Users can pass...
Comprehensive introduction MockingBird is an open source project designed to achieve rapid speech cloning and text-to-speech through AI technology. Users only need to provide 5 seconds of voice samples to generate any voice content. The project supports a variety of Chinese datasets , and in Windows ...
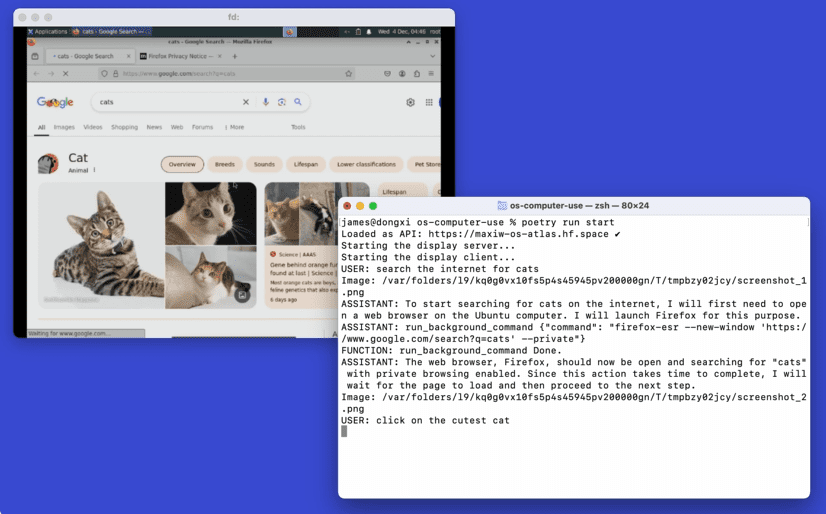
General Introduction E2B Open Computer Use is an open source project that aims to provide a secure cloud-based Linux computer use experience through the E2B Desktop Sandbox.The E2B Sandbox provides a desktop graphical environment that users can connect to any large...
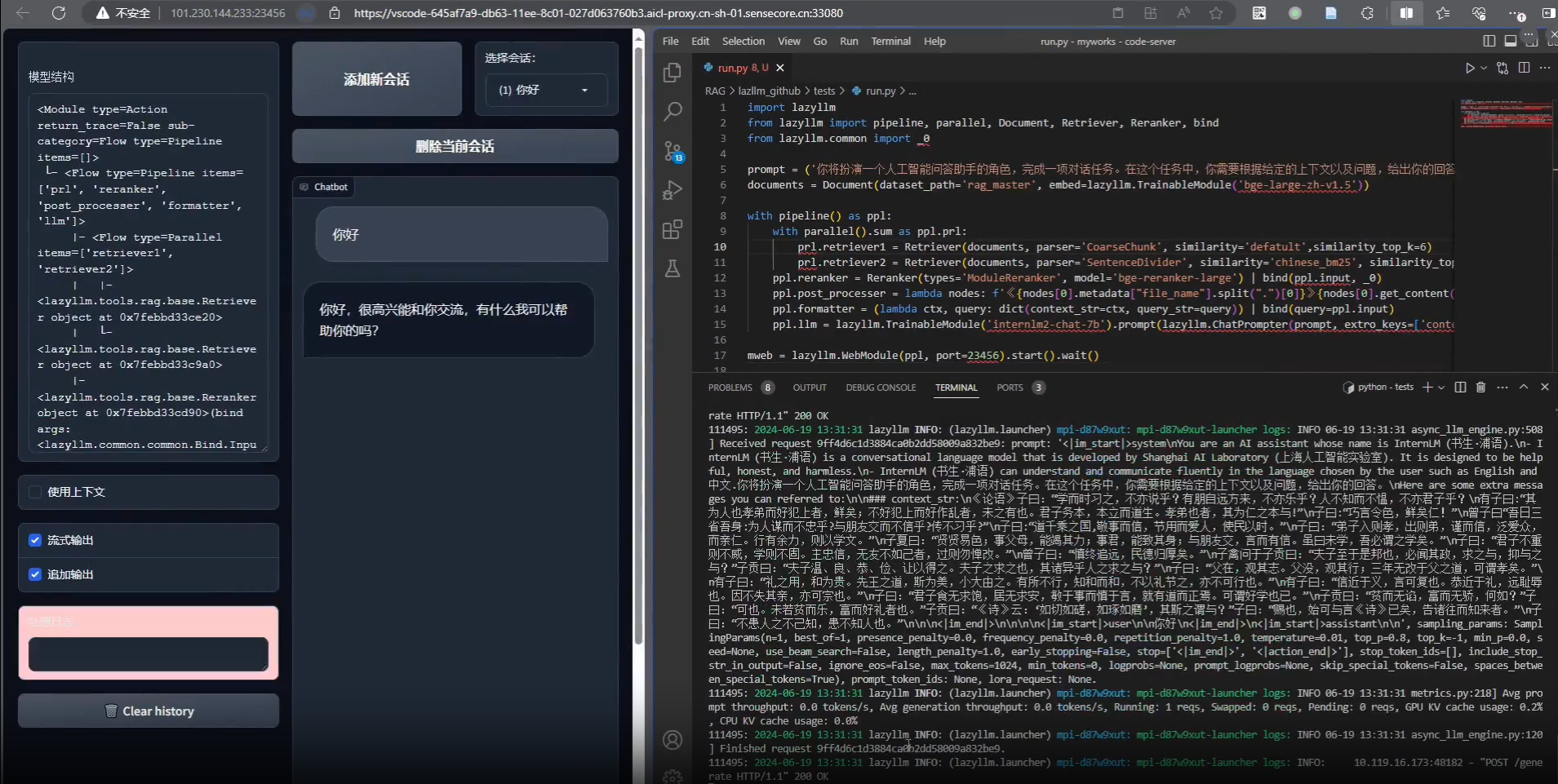
Comprehensive Introduction LazyLLM is an open source tool developed by the LazyAGI team, focusing on simplifying the development process of multi-intelligence large model applications. It helps developers quickly build complex AI applications through one-click deployment and lightweight gateway mechanisms, saving tedious engineering configuration...
Comprehensive Introduction Orate is an AI toolkit focused on speech generation and transcription. It provides a unified API that seamlessly integrates with leading AI providers such as OpenAI, ElevenLabs, and AssemblyAI to help users create forced...
Because the domestic deployment can not access hugging face, so in the big brother deployment program based on the transformation to be able to deploy to cloudflare workers. Preparation 1, register cloudflare 2, register hugging fac...
General Introduction OmniGen is a "general purpose" image generation model developed by VectorSpaceLab that allows users to create diverse and contextually rich visuals with simple text prompts or multimodal inputs. It is particularly well suited for applications that need to recognize...
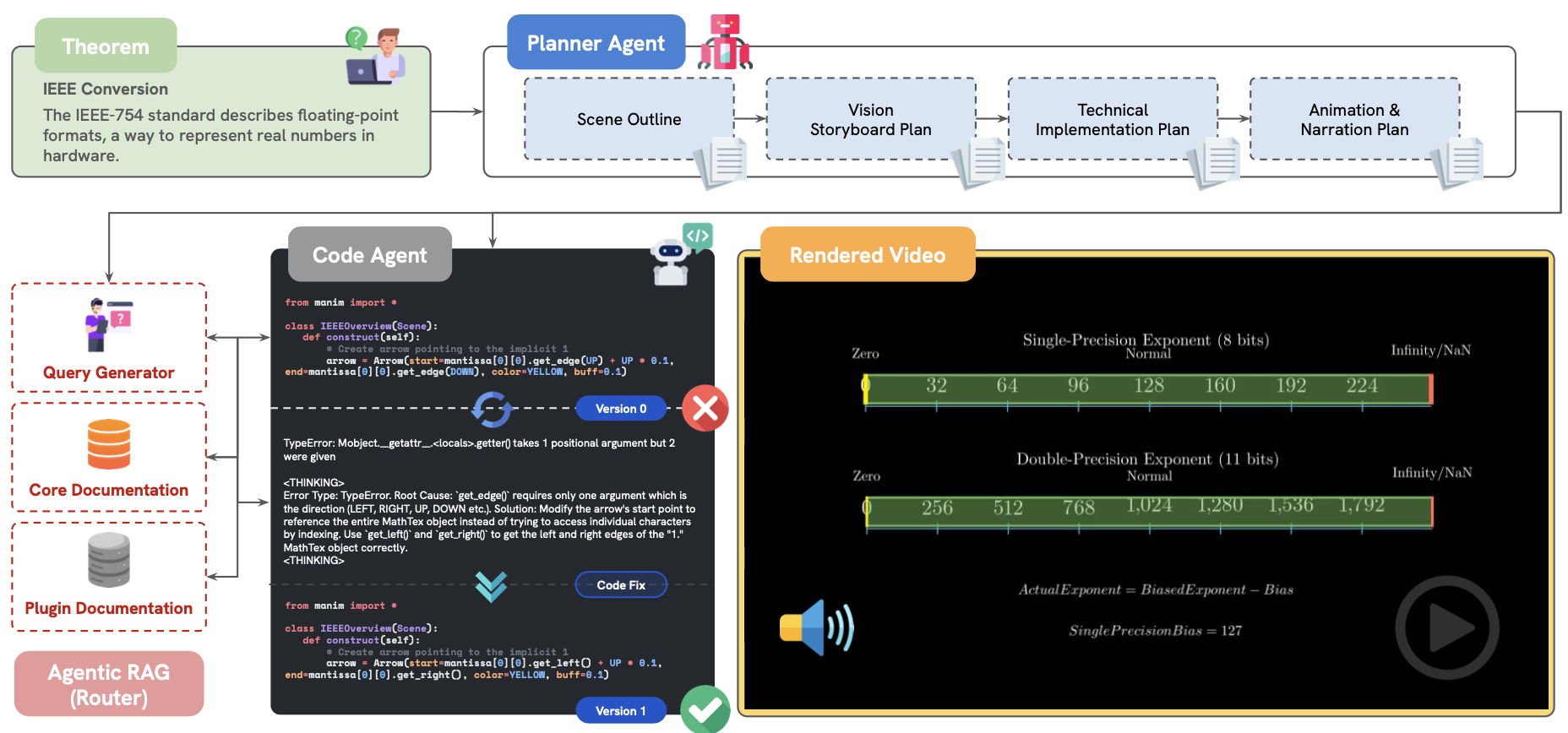
General Introduction TheoremExplainAgent is an innovative project developed by TIGER AI Lab to transform complex mathematical and scientific theorems into easy-to-understand video animations using artificial intelligence techniques. The tool is based on the Large Language Model (LLM...
General Introduction PhotoDoodle is an open source image editing tool, developed by ShowLab, focusing on artistic editing of photos through artificial intelligence technology. Users only need to input simple text prompt words to add cartoon style, 3D effect, light...
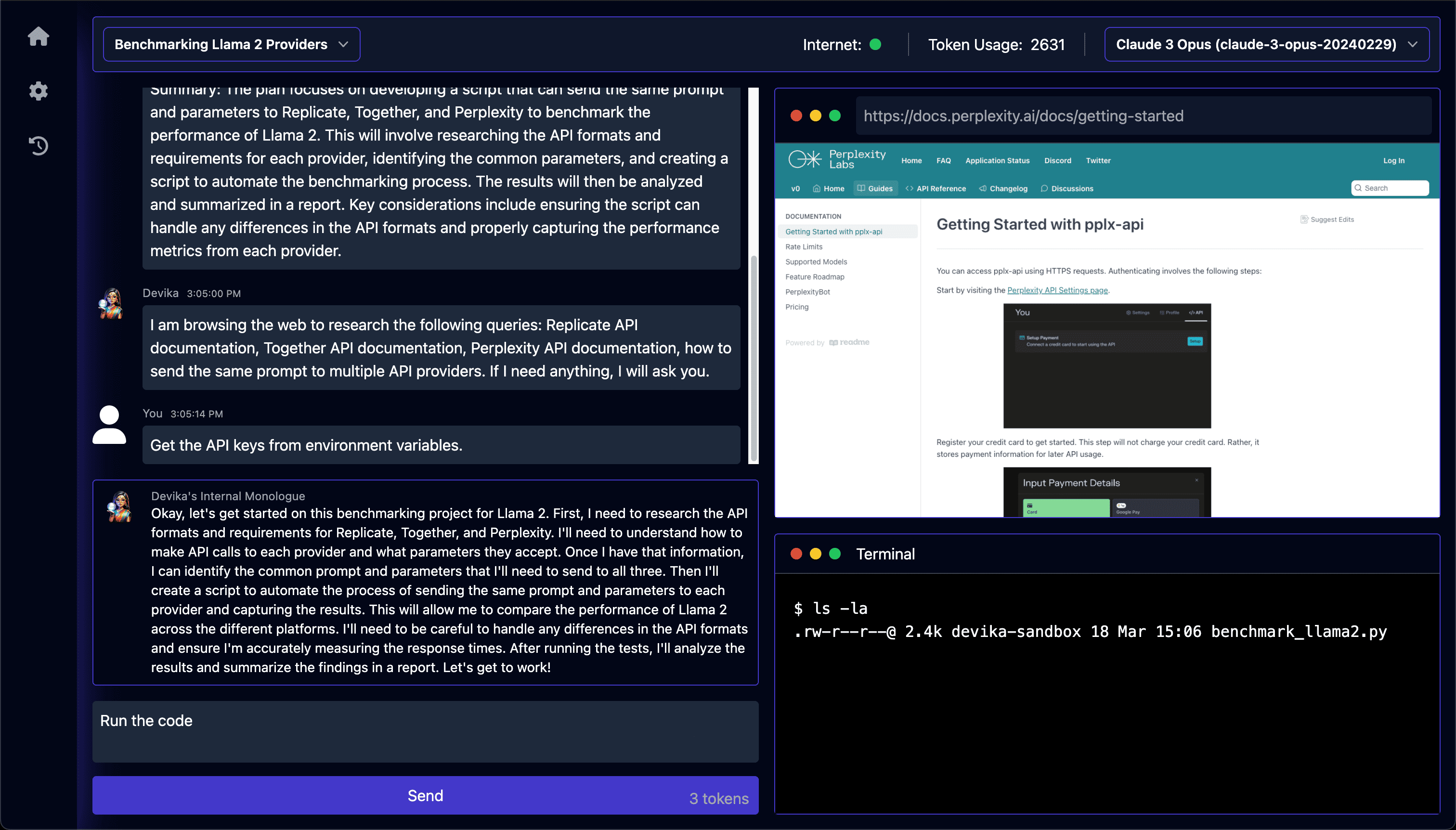
General Introduction Devika is an advanced AI software engineer that understands high-level human instructions, breaks them down into steps, studies the relevant information, and writes code to achieve a given goal. It intelligently develops software using large-scale language models, planning and reasoning algorithms, and web browsing capabilities.D...
General Introduction ell is a lightweight functional language model programming library developed by former OpenAI researcher William Guss. It is designed with the idea of treating cues as programs, not just strings. ell provides automated version control and serialization...
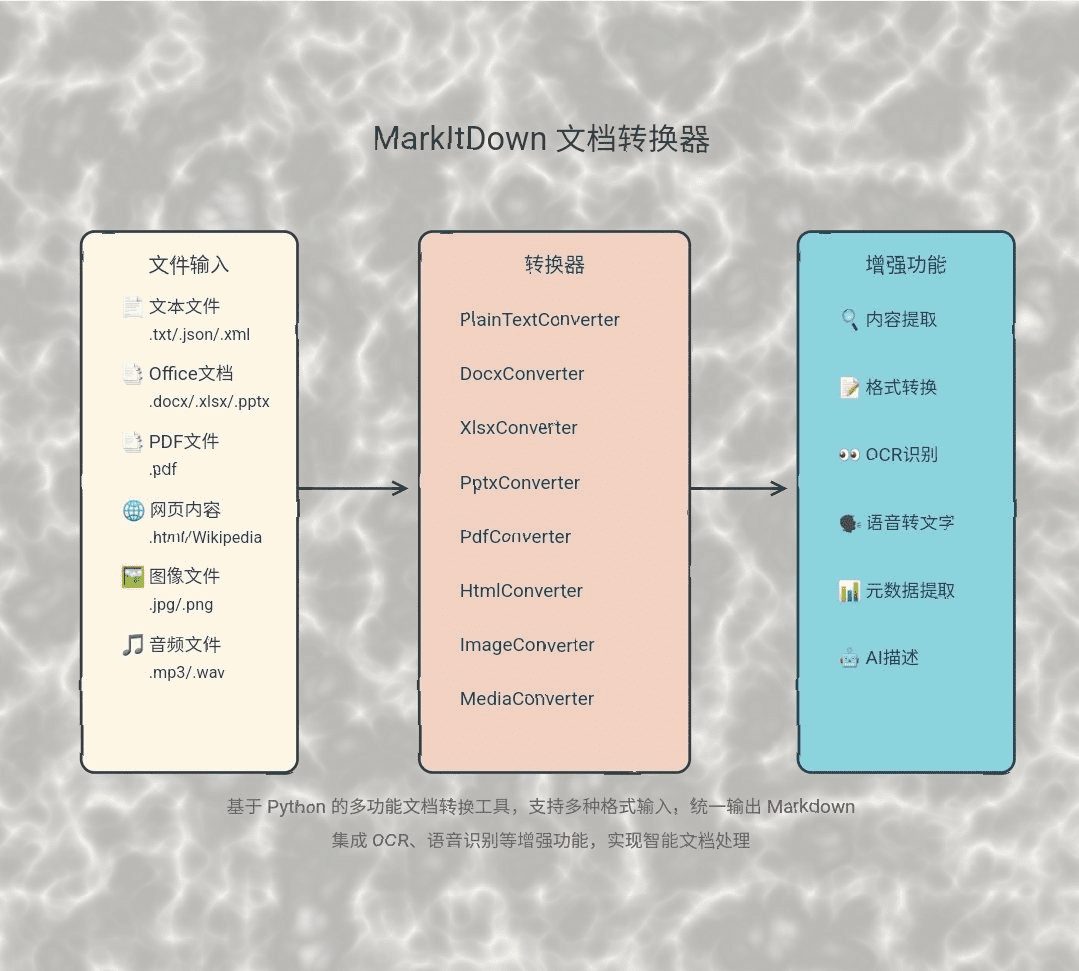
General Introduction MarkItDown is a Python tool developed by Microsoft designed to convert various files and office documents to Markdown format. The tool supports a wide range of file types, including PDF, PowerPoint, Word, Excel, diagrams...
QAnything Comprehensive Introduction QAnything (Question and Answer based on Anything) is a local knowledge base Q&A system launched by NetEase, which supports all kinds of file formats and databases, and can be installed and used offline....
General Introduction Weebo is an open source real-time voice chatbot that utilizes Whisper Small for speech recognition, Llama 3.2 for natural language generation, and Kokoro-82M for speech synthesis. The project was developed by Aman...
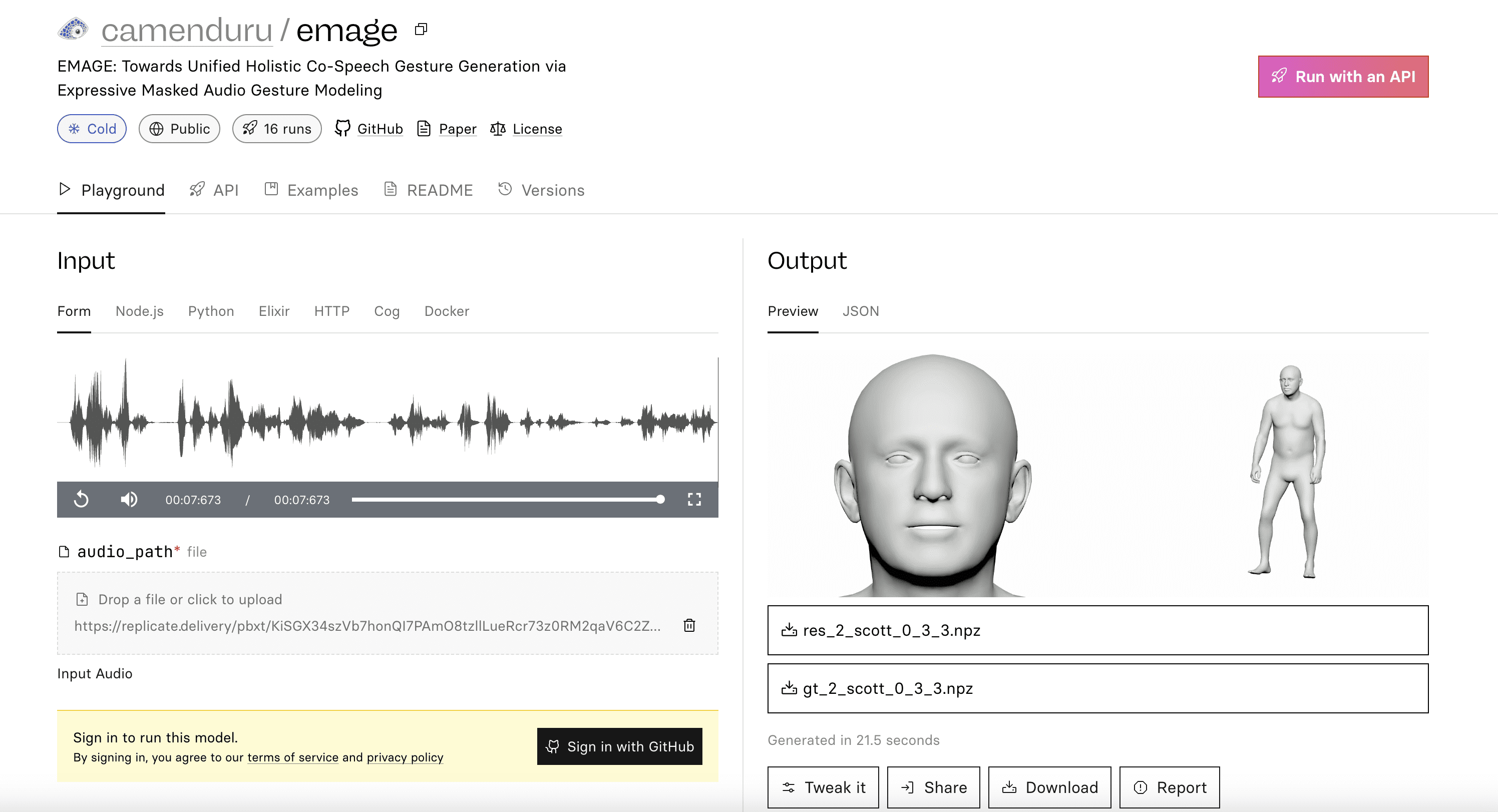
Comprehensive Introduction PantoMatrix is an advanced full-body gesture generation framework capable of generating complete human movements from audio and partial gestures, including face, partial body, hand and full-body movements. The framework utilizes the latest multimodal datasets and deep learning techniques to provide high-quality 3D...
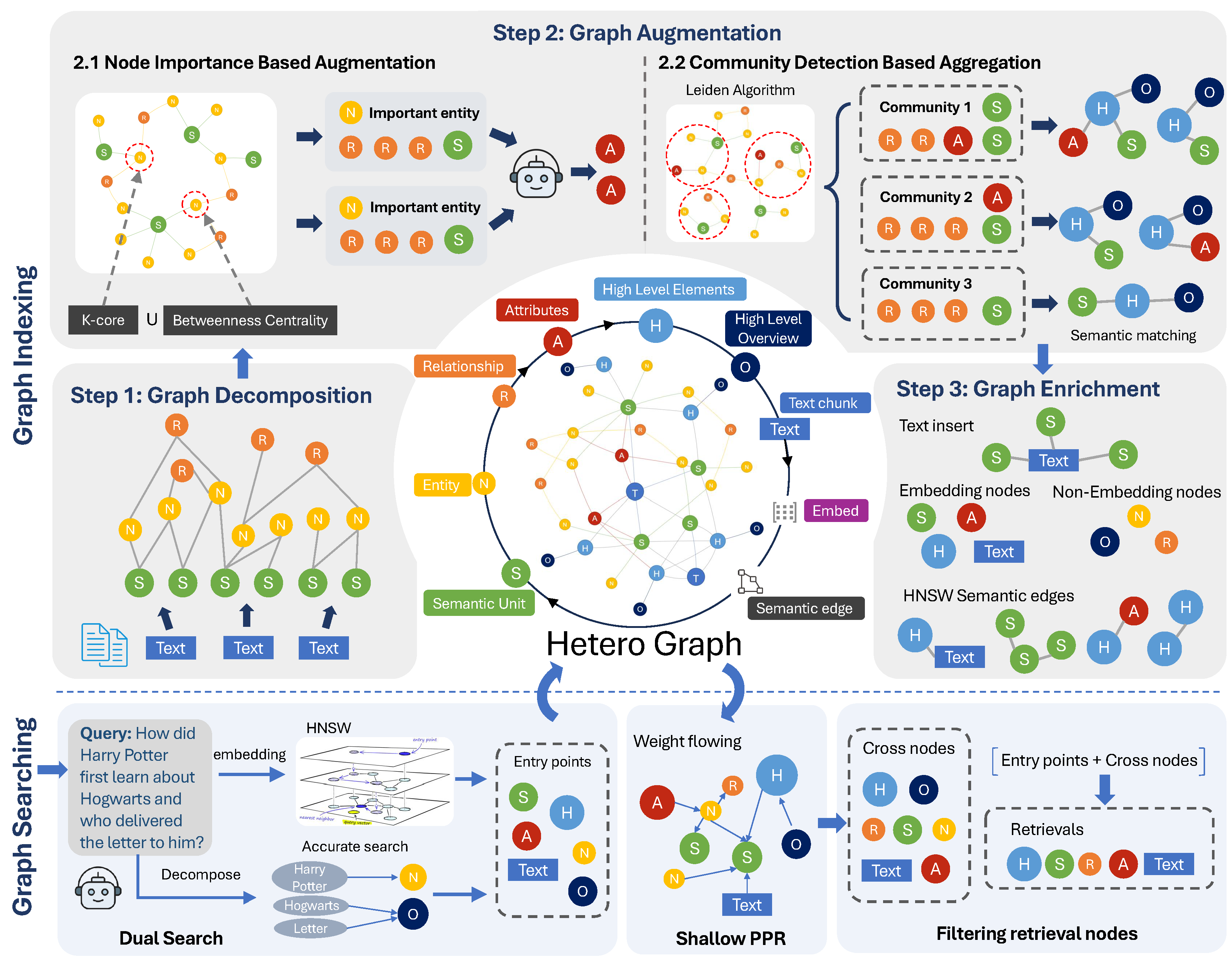
A Comprehensive Introduction NodeRAG is an open source Retrieval Augmented Generation (RAG) system hosted on GitHub and developed by Terry-Xu-666. It optimizes information retrieval and generation through heterogeneous graph structures, significantly improving retrieval accuracy and contextual relevance.Nod...
Comprehensive Introduction LangbaseInc's Langui is an open source user interface component library designed for generative AI and Large Language Model (LLM) projects. The library is based on Tailwind CSS and provides a collection of pre-built UI components to help developers quickly construct...
Comprehensive Introduction Flow is a lightweight task engine designed for building AI agents, emphasizing simplicity and flexibility. Unlike traditional node- and edge-based workflows, Flow uses a dynamic task queuing system that supports parallel execution, dynamic scheduling, and intelligent dependency management. Its core concept is ...
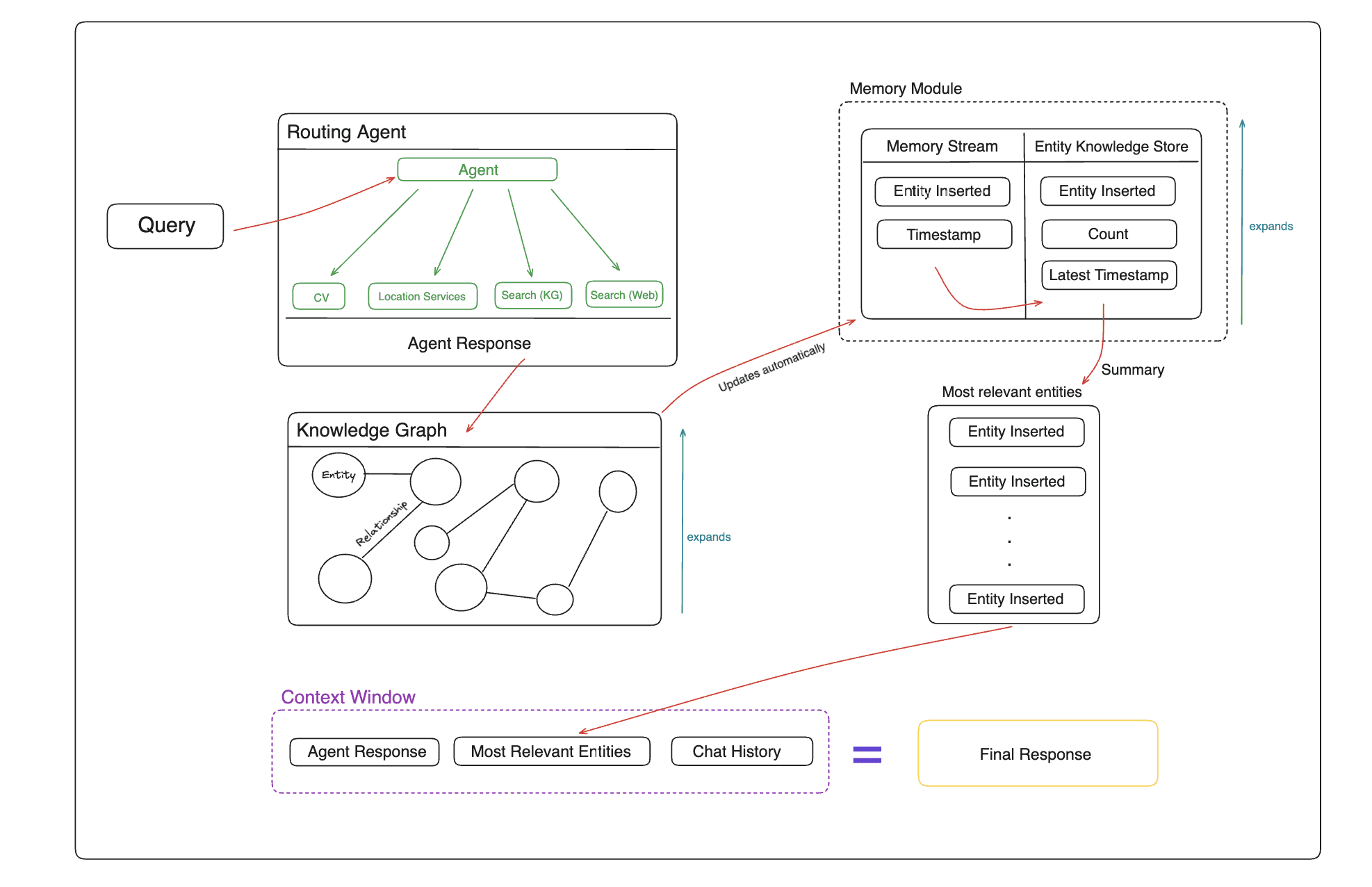
General Introduction Memary is an innovative open source project focused on providing long-term memory management solutions for autonomous intelligences. The project helps intelligences break through the limitations of traditional context windows to achieve smarter interaction experiences through knowledge graphs and specialized memory modules.Memary adopts...
General Introduction Gemini Cursor is a desktop intelligent assistant based on Google's Gemini 2.0 Flash (experimental) model. It enables visual, auditory, and voice interactions through a multimodal API, providing real-time low-latency use...
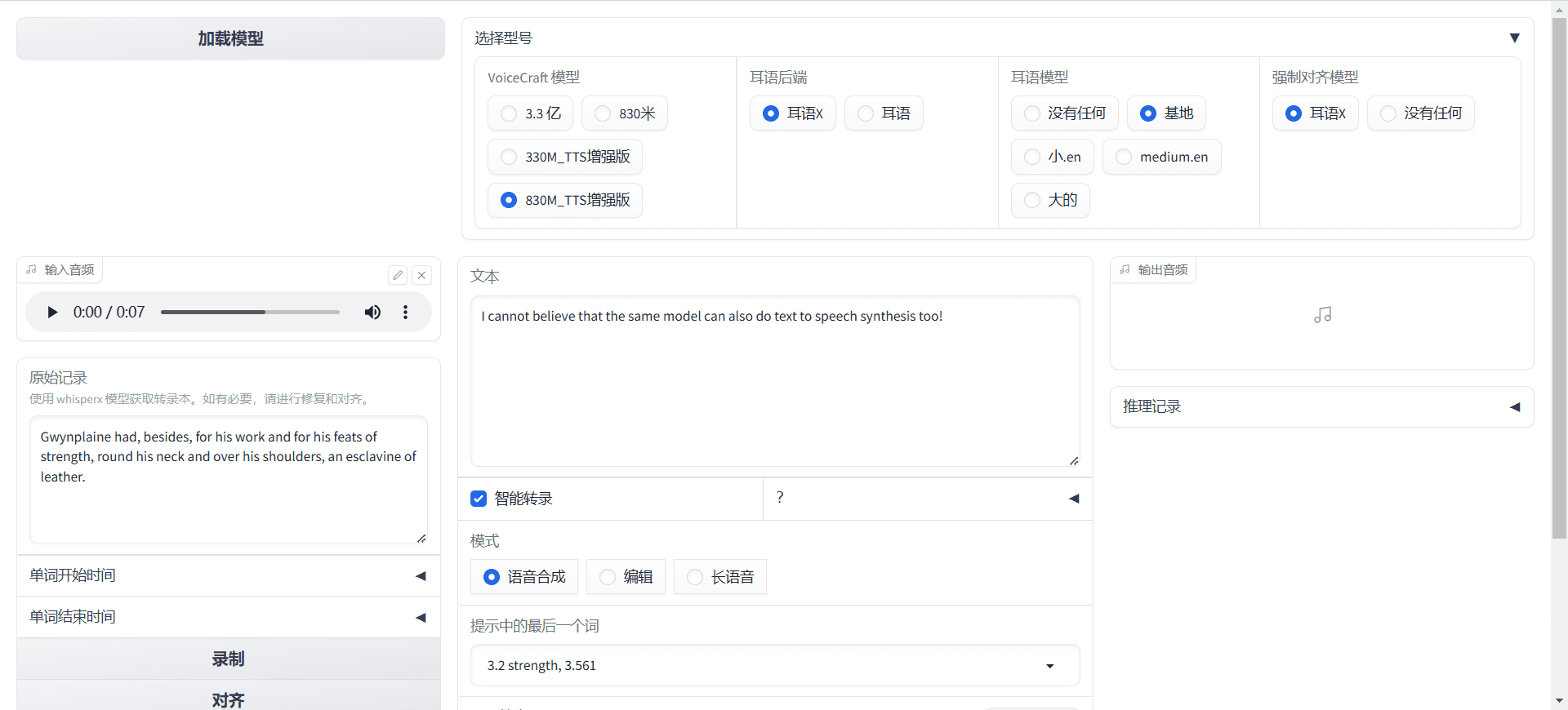
Comprehensive Introduction VoiceCraft is an open source speech editing and zero-sample speech synthesis tool based on the neural codec language model. It employs an innovative coded sequence generation method that enables insertion, deletion and replacement operations on existing speech sequences to generate natural, coherent edited speech...
General Introduction AgentNetworkProtocol (ANP for short) is an open source protocol project, hosted on GitHub, focused on providing secure and efficient communication solutions for intelligent agents (AI Agents). It works through a three-layer architecture - identity and encryption...
General Introduction FlashMLA is an efficient MLA (Multi-head Latent Attention) decoding kernel developed by DeepSeek AI, optimized for NVIDIA Hopper architecture GPUs...
General Introduction Fast-Agent is an open source tool maintained by the evalstate team on GitHub, designed to help developers quickly define, test and build multi-intelligence workflows. It is based on a simple declarative syntax, and supports the use of MCP (Mode...
Comprehensive Introduction XianyuAutoAgent is an intelligent customer service robot system designed for the Idlefish platform, open-sourced by developer shaxiu on GitHub. It realizes 7×24 hours automatic duty through AI technology, and helps Idlefish sellers reply...
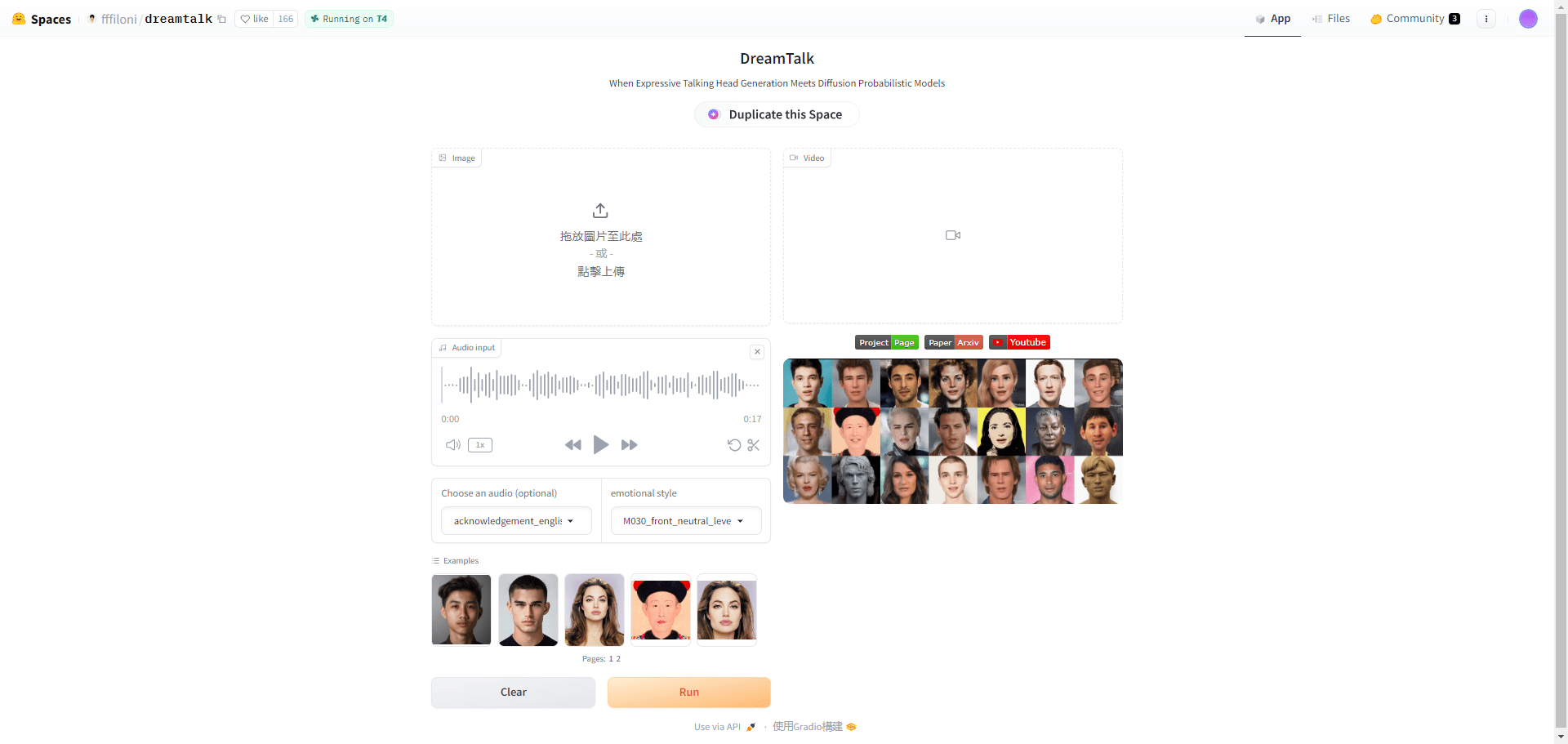
DreamTalk Comprehensive Introduction DreamTalk is a diffusion model-driven expression talking head generation framework, jointly developed by Tsinghua University, Alibaba Group and Huazhong University of Science and Technology. It mainly consists of three parts: a noise reduction network, a style-aware lip expert and a style predictor, and can be based on...
General Introduction Zonos is an open source speech synthesis and speech cloning tool developed by Zyphra.The Zonos-v0.1 version uses an advanced Transformer and blending model to generate high quality speech output. The tool supports multiple languages...
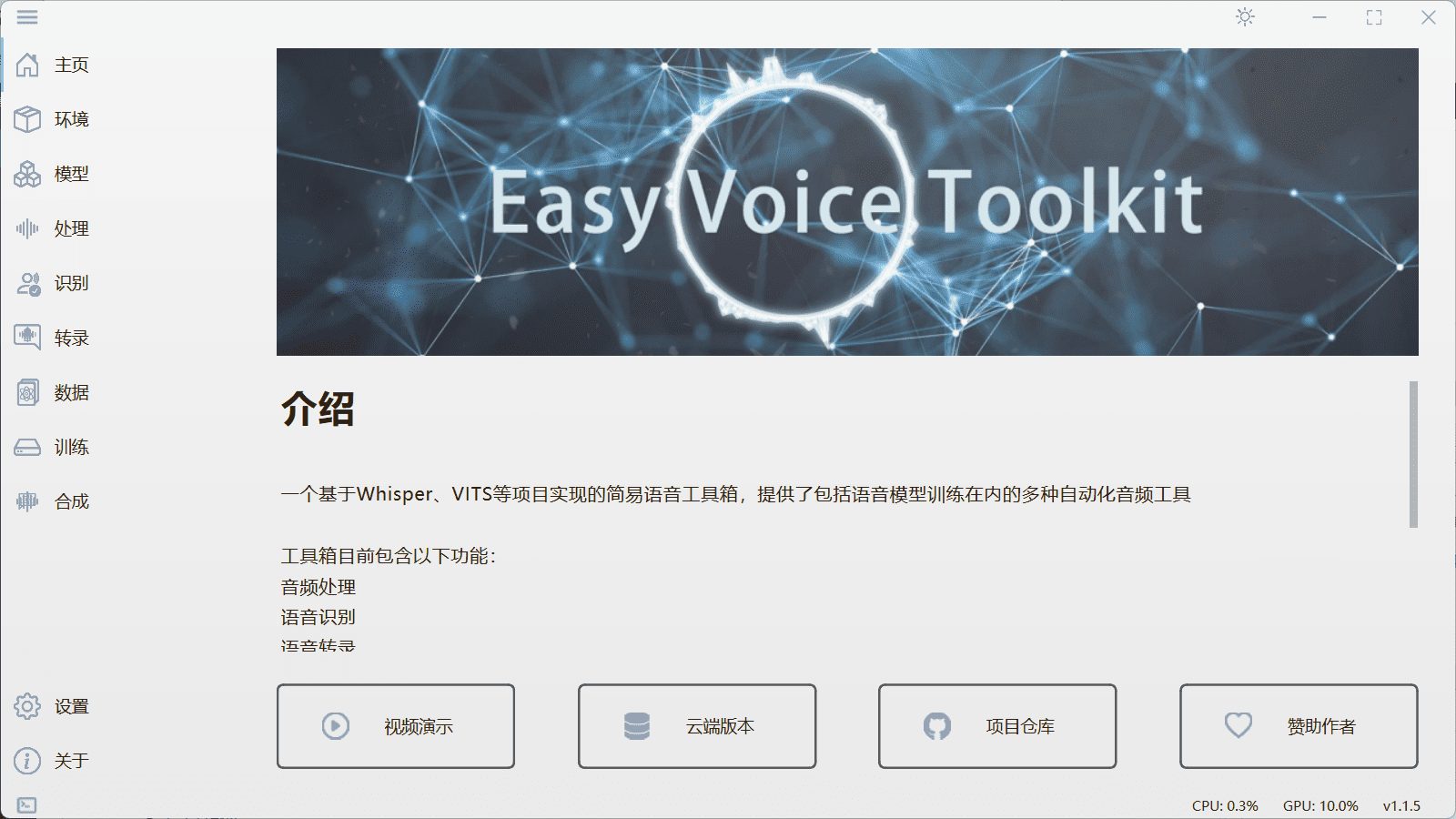
Comprehensive Introduction Easy-Voice-Toolkit is a multifunctional toolkit based on the Open Source Speech Project, providing a variety of automated audio tools for speech recognition, speech transcription, speech conversion, dataset creation and model training. Users can selectively use these tools as needed...
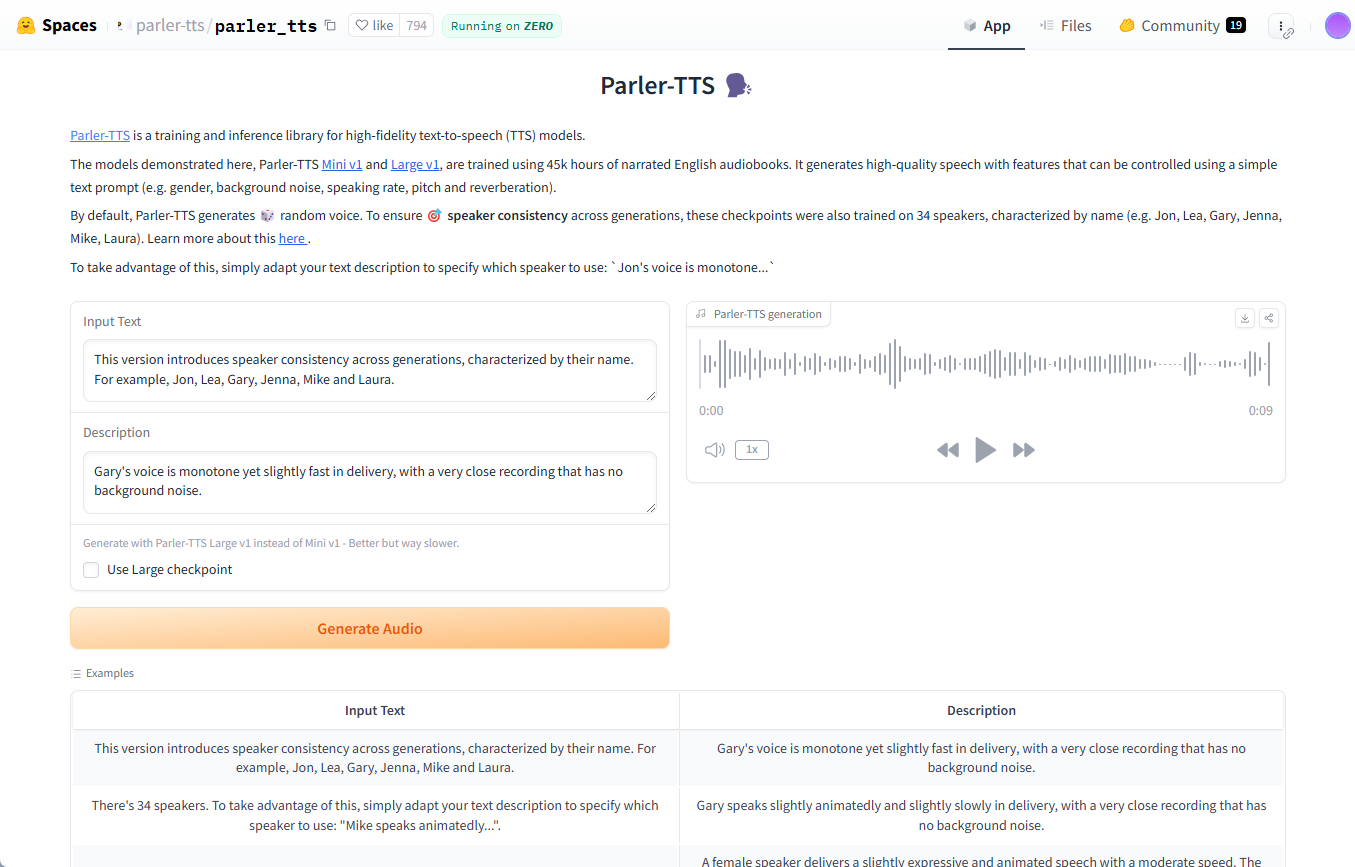
General Introduction Parler-TTS is an open source text-to-speech (TTS) modeling library developed by Hugging Face, designed to generate high-quality, natural-sounding speech. The model is capable of generating speech based on input text with a specific speaker style (e.g. gender, pitch, speaking style...
General Introduction ModelBest is a company specializing in developing lightweight and high-performance large models, dedicated to applying advanced AI technologies to mainstream consumer electronics and various end devices in daily life. Its MiniCPM series of end-side models are characterized by extreme arithmetic power and memory usage efficiency...
General Introduction Ichigo is an open source real-time speech AI project that aims to extend text-based language models with native "listening" capabilities. The project uses early fusion techniques inspired by Meta's Chameleon paper.Ichigo's goal is to become...
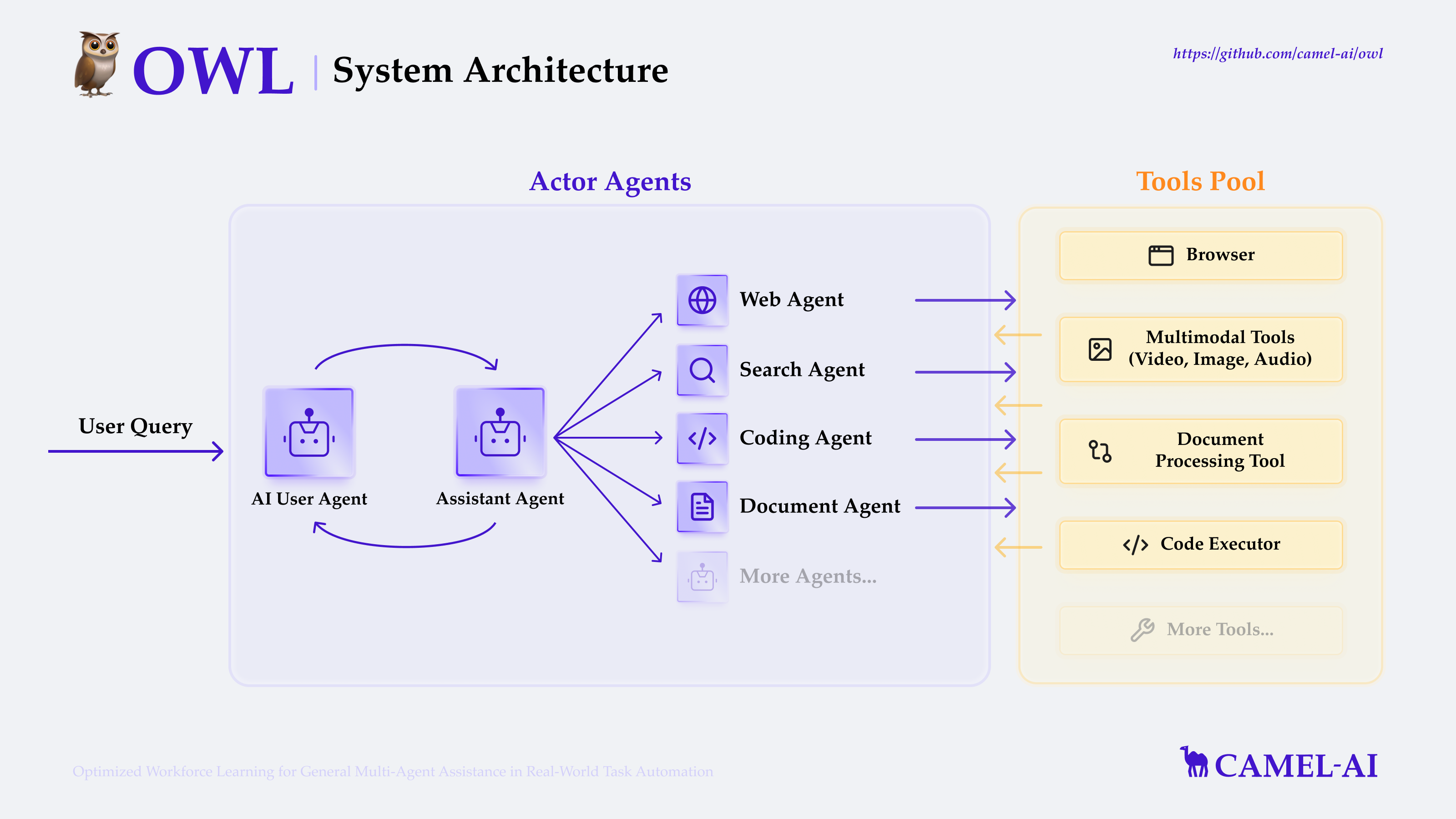
Comprehensive Introduction OWL (Optimized Workforce Learning) is an open source framework developed by the CAMEL-AI team focused on optimizing multi-intelligence collaboration for automating real-world tasks. Based on the CAMEL-AI framework ...
General Introduction Audiblez is an open source project designed to convert eBooks (e.g. .epub format) into audiobooks (e.g. .m4b format). The project utilizes Kokoro's high-quality speech synthesis technology to support multiple languages and multiple voices. Users can simply...
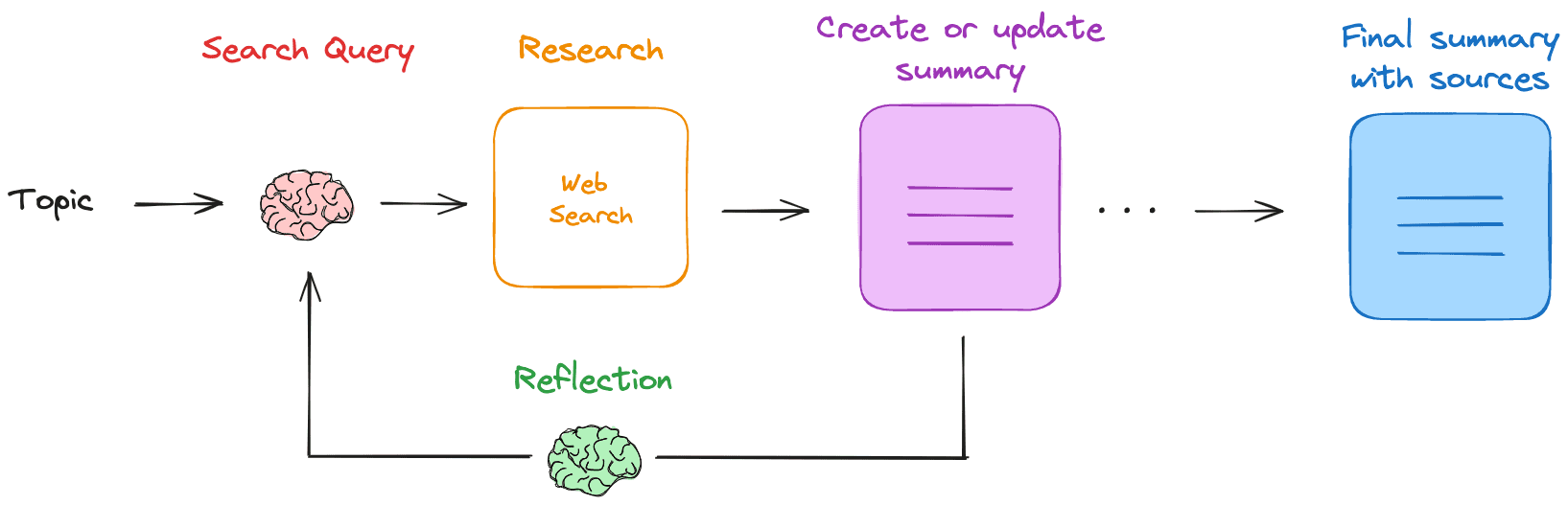
General Introduction Research Rabbit is a native LLM (Large Language Model) based web research and summarization assistant. After the user provides a research topic, Research Rabbit generates a search query, obtains relevant web results, and summarizes those results...
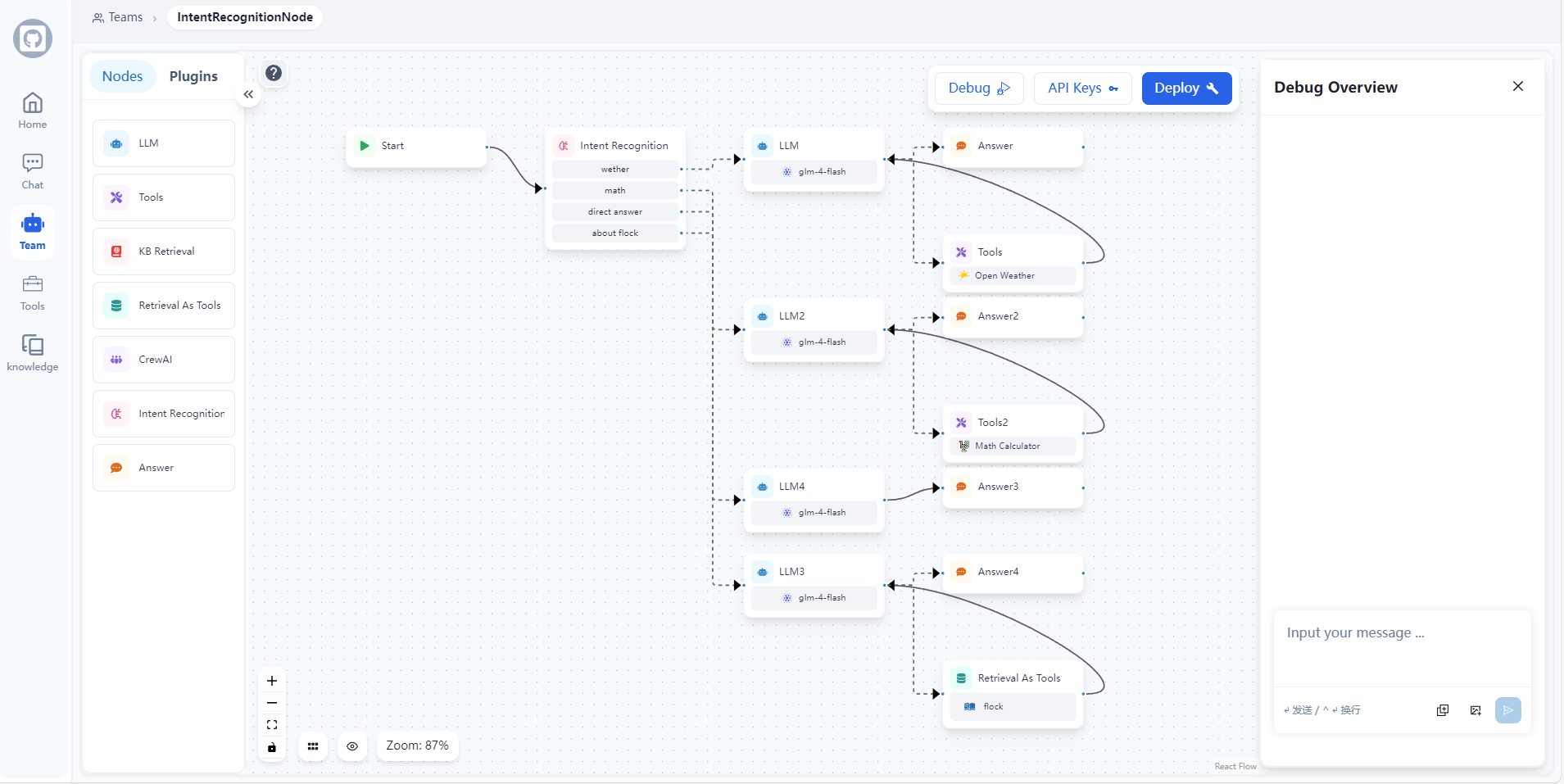
General Introduction Flock is an open source low-code platform for workflows, hosted on GitHub and developed by the Onelevenvy team. It is based on LangChain and LangGraph technologies and is focused on helping users quickly build chat machines...
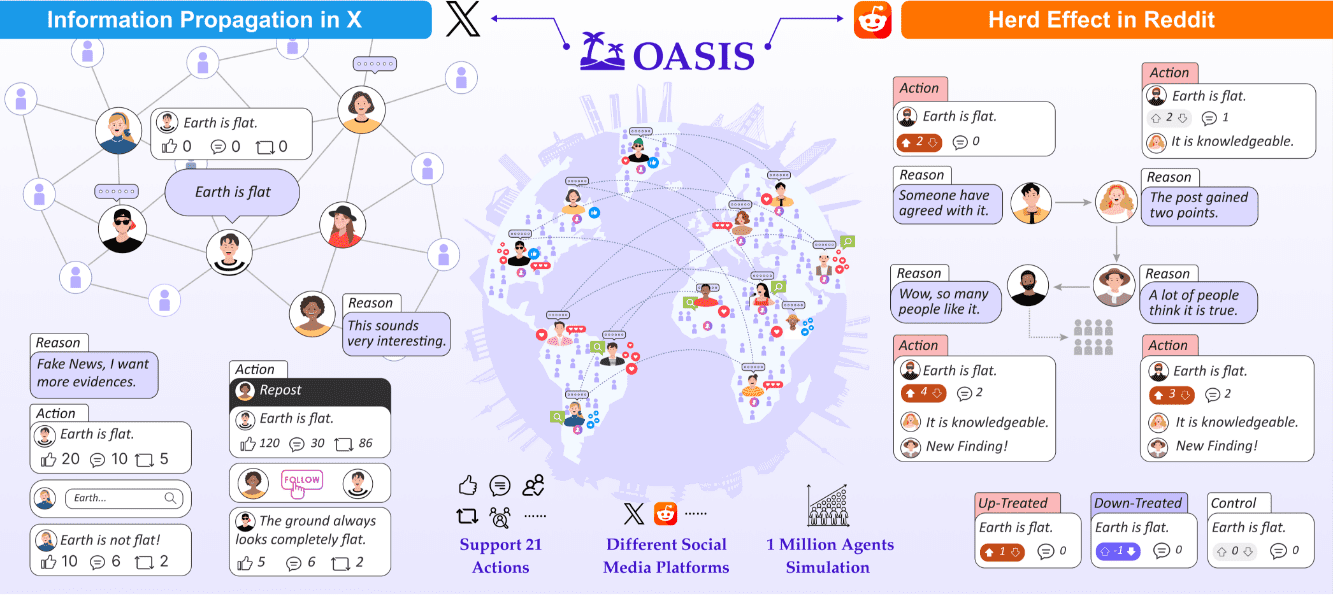
General Introduction OASIS (Open Agent Social Interaction Simulations) is an open source social media simulator capable of simulating the behavior of up to one million users. The platform combines large-scale language modeling and rule-based...
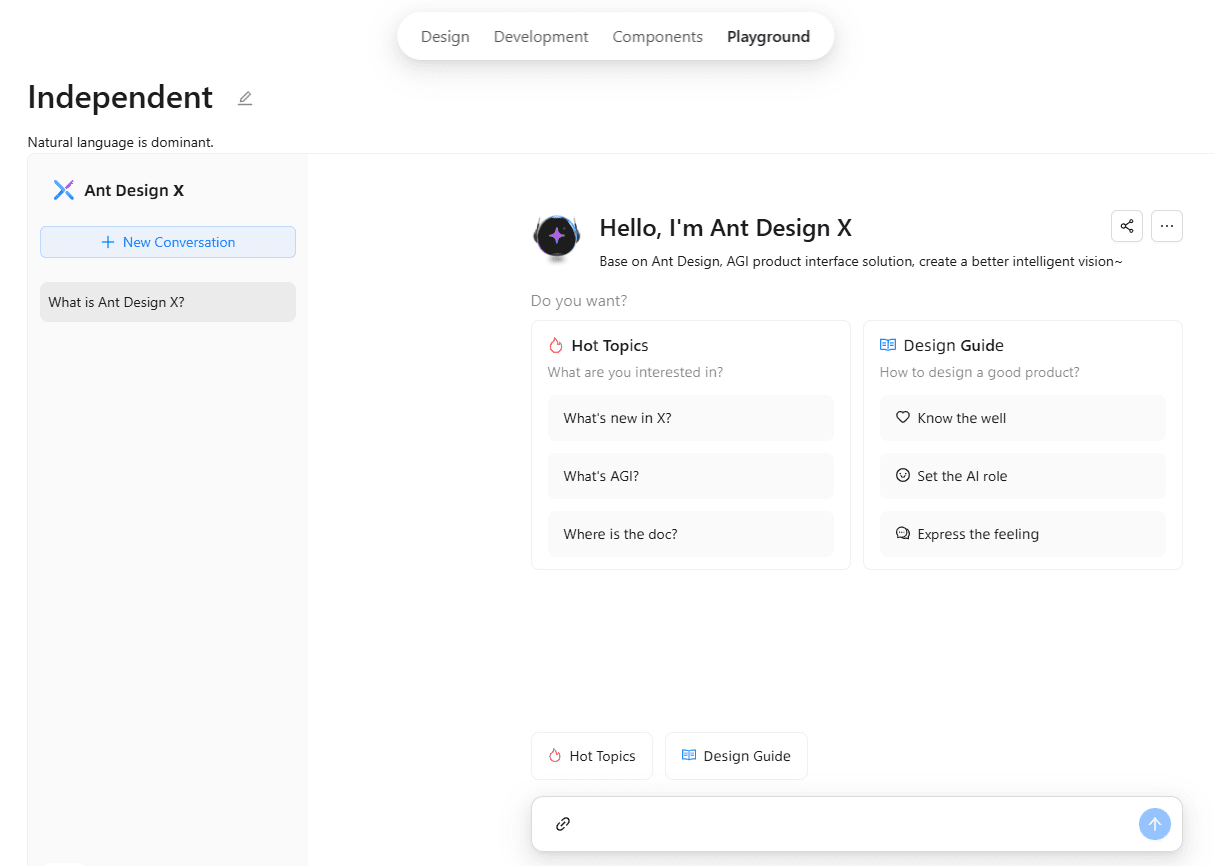
Comprehensive Introduction Ant Design X is a toolkit open-sourced by Ant Group, designed to help developers quickly build AI-driven dialog interfaces. It provides a rich set of components and templates, supports model integration compatible with OpenAI standards, and is suitable for a variety of applications such as intelligent customer service, AI assistants, and other...
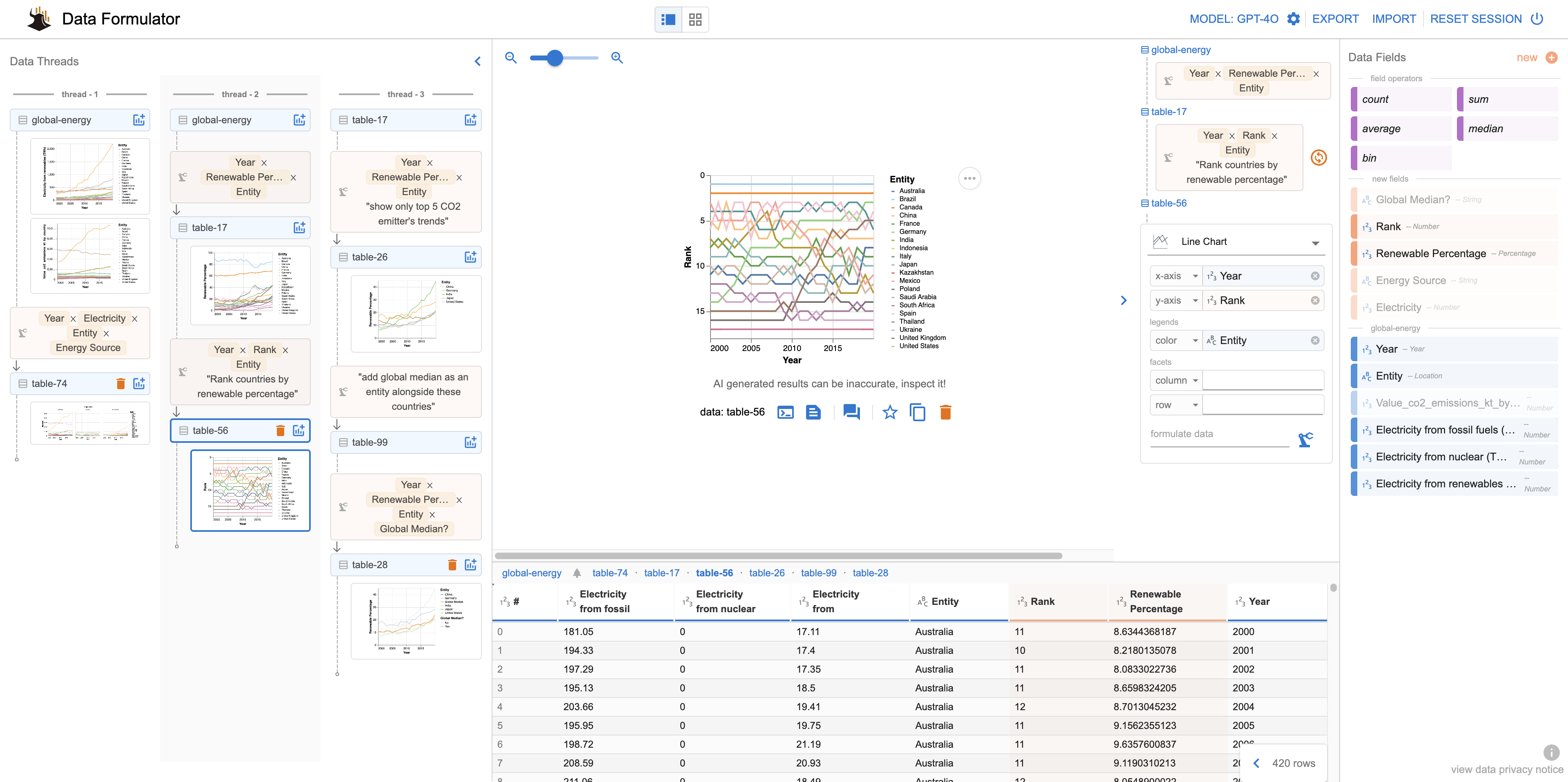
General Introduction Data Formulator is an open source AI-driven data visualization tool developed by Microsoft Research. The tool combines a graphical user interface (GUI) and natural language input (NL) to enable users to quickly create and iterate through simple interactions and commands...
General Introduction G-Search-MCP is an open source Google search tool hosted on GitHub and modified by developer jae-jae based on google-search. It passes MCP (Model Context...
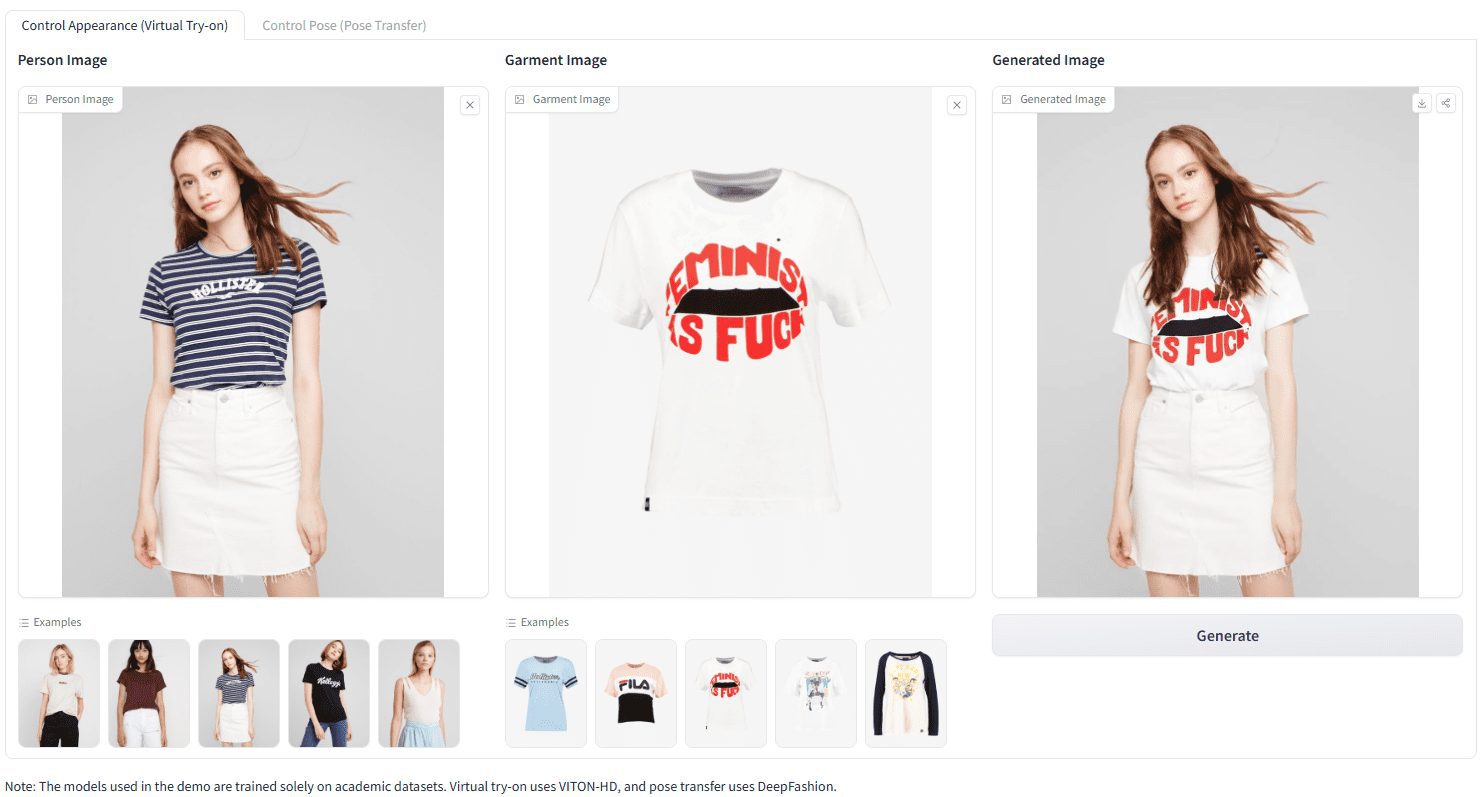
Comprehensive Introduction Leffa is a unified framework for generating controllable character images, enabling precise manipulation of character appearance (e.g., virtual fitting) and pose (e.g., pose transfer). The framework significantly reduces distortion of fine-grained details by directing the target query to focus on the correct reference key in the attention layer, with ...
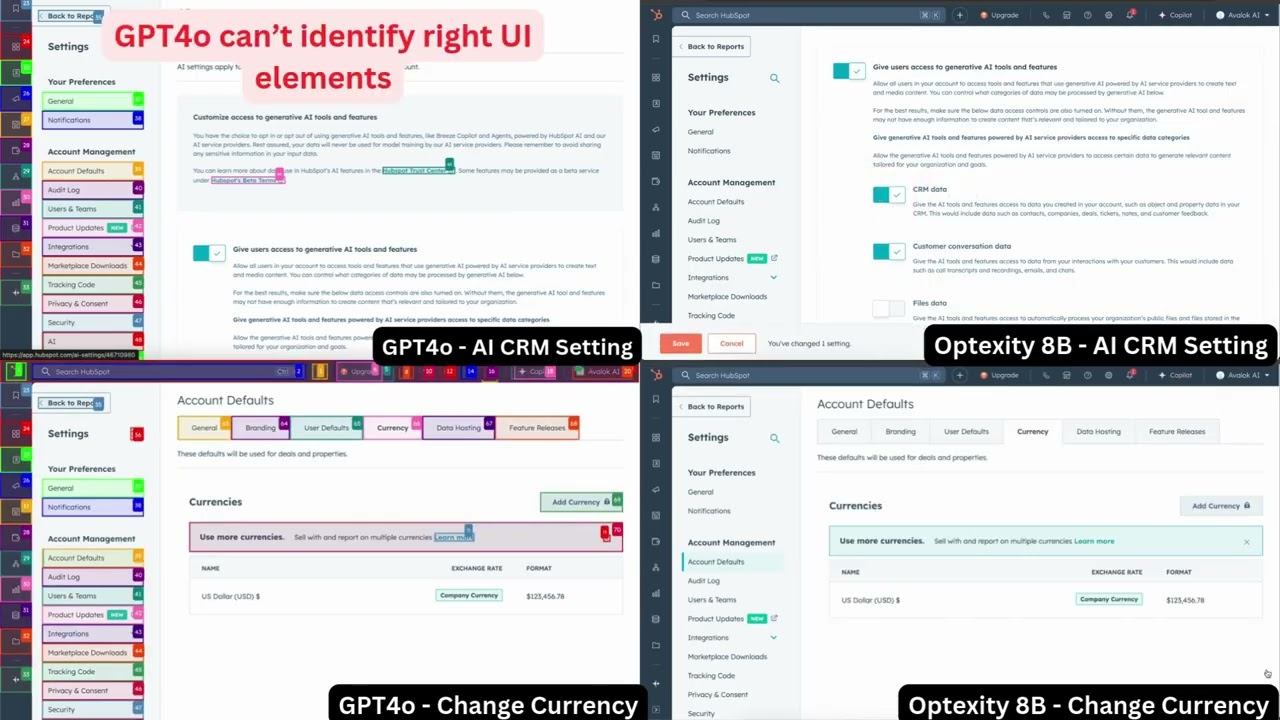
General Introduction Optexity is an open source project on GitHub, developed by the Optexity team. Its core is to use human demonstration data to train AI to complete computer tasks, especially web page operations. The project contains three code libraries : Compute...
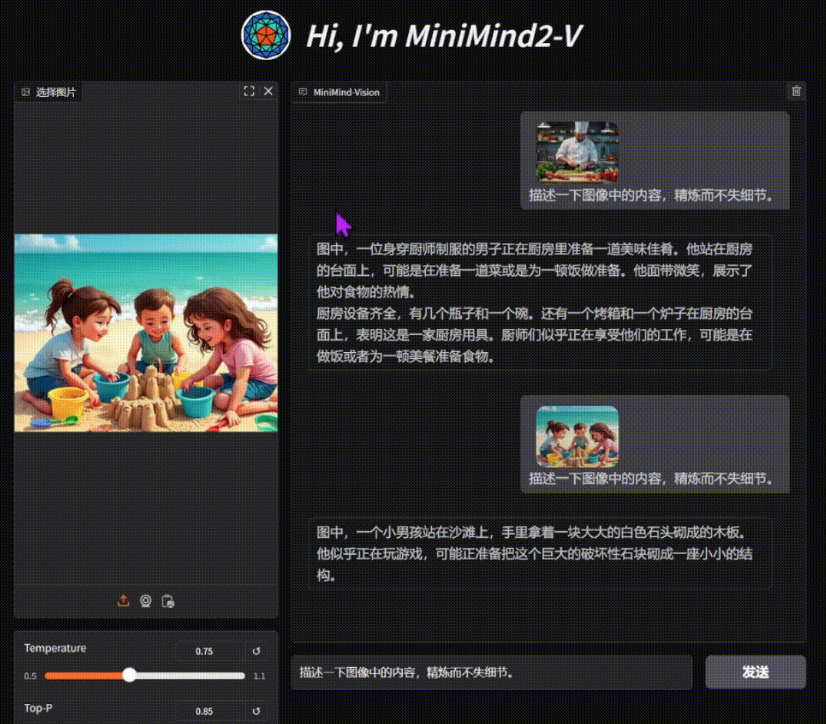
General Introduction MiniMind-V is an open source project, hosted on GitHub, designed to help users train a lightweight visual language model (VLM) with only 26 million parameters in less than an hour. It is based on the MiniMind language model, with new visual...
Comprehensive Introduction insanely-fast-whisper is a combination of OpenAI's Whisper model and various optimization techniques (e.g. Transformers, Optimum, Flash Attention) for audio trans...
General Introduction Ruyi-Models is an open source project designed to generate high quality videos from images. Developed by the IamCreateAI team, the project supports the generation of 768 resolution, 24 frames per second, a total of 5 seconds 120 frames of cinematic video...
General Introduction OrionChat is a web-based AI chat interface that provides users with a unified platform to interact with multiple mainstream AI models. The project supports a wide range of AI models including Ollama (running locally), OpenAI GPT, Google Gemi...
General Introduction RapBank is a dataset and toolset designed for rap lyrics generation. The project was created by NZqian to provide researchers and developers with a high-quality rap lyrics data by collecting and processing rap songs from YouTube...
General Introduction SegAnyMo is an open source project developed by a team of researchers at UC Berkeley and Peking University, including members such as Nan Huang. This tool focuses on video processing and can automatically recognize and segment arbitrary moving objects in a video, such as people, animals or...
Comprehensive Introduction Voice Changer is an open source real-time voice transformation tool that supports a wide range of AI voice models such as MMVC, so-vits-svc, RVC, DDSP-SVC, and Beatrice.The tool is compatible with multiple platforms...
General Introduction Bilingual Book Maker is an open source project designed to help users create multilingual versions of eBooks using AI technology. The tool mainly uses ChatGPT for translation and supports multiple file formats including epub, txt and srt...
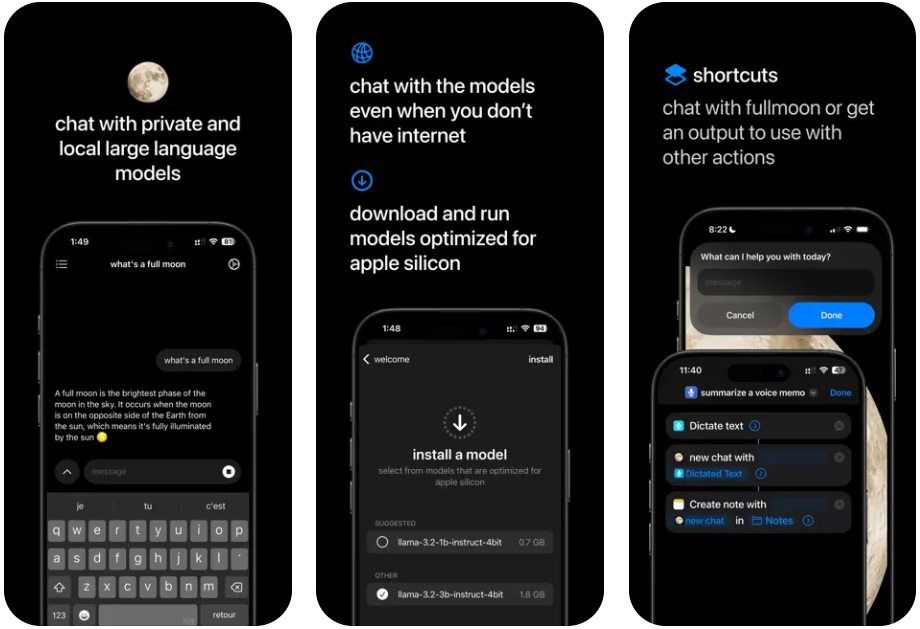
General Description Fullmoon is an application designed for iOS devices and aims to provide the ability to chat privately with native large language models. The app is optimized for Apple Silicon and is supported on iPhone, iPad and Mac. Users of the chat...
General Introduction TripoSG is an open source project developed by the VAST AI research team to generate high-quality 3D models from a single image. The project uses large-scale rectifier-flow converter technology, combined with hybrid supervised training and high-quality datasets, to allow the generated 3D models to have...
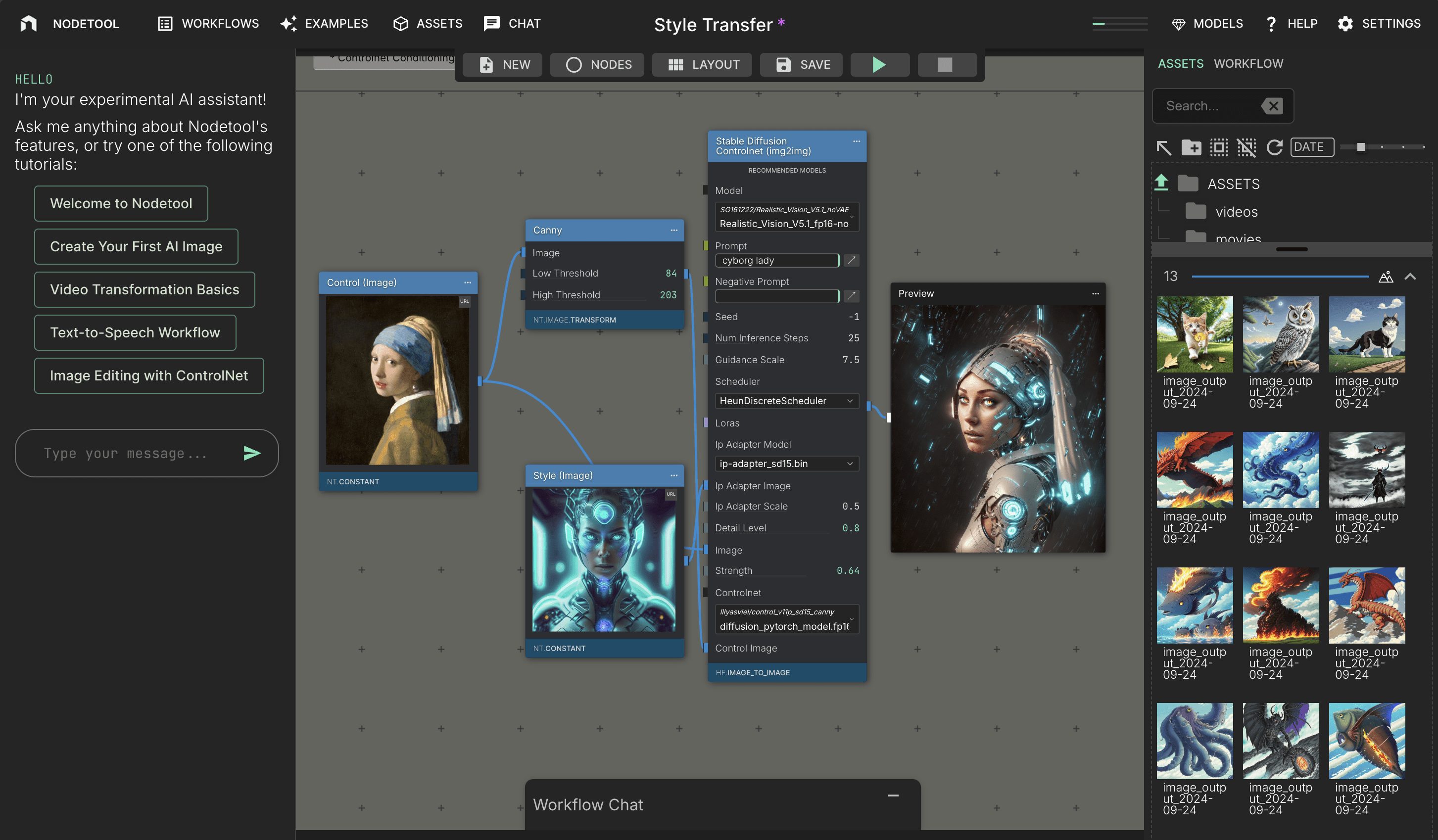
General Introduction NodeTool is an innovative AI authoring platform designed to provide a simple, intuitive interface for AI enthusiasts, developers, data scientists and creatives. Whether you're an artist, developer, or beginner, NodeTool helps you quickly prototype creative...
Comprehensive Introduction SVFR (Stable Video Face Restoration) is a unified framework for video face restoration that supports Basic Face Restoration (BFR), colorization, repair, and their combination tasks. The framework utilizes generative and kinematic priors by unifying ...
General Introduction MIDI-3D is an open source project developed by the VAST-AI-Research team to quickly generate 3D scenes containing multiple objects from a single image for developers, researchers and creators. This tool is based on the multi-instance diffusion modeling technique...
General Introduction E2M (Everything to Markdown) is an open source Python library designed to convert a wide range of file formats to Markdown format. The tool supports formats including doc, docx, epub, html, htm, u...
Introducing Browse Browse AI is a no-coding cloud-based web automation software designed to help users extract and monitor data from any website without programming. You can train a bot to perform data extraction, monitoring and automation tasks with just one mouse point...
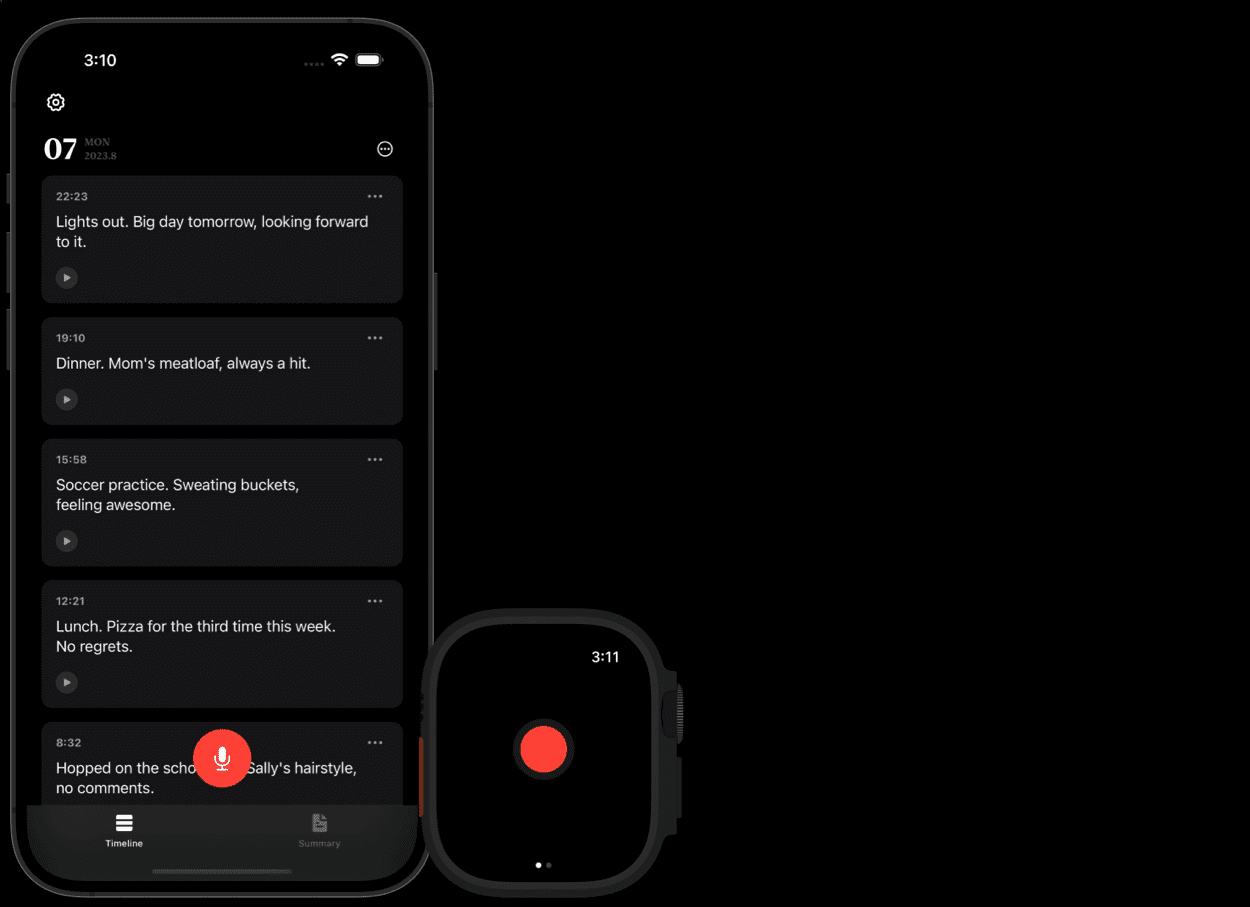
General Introduction ALog is an AI-based voice diary application designed to help users record their daily lives by voice. The project is developed by duxins and open-sourced on GitHub. Users can record their diary through voice input, and the app will automatically convert the voice into text...