

저는 최근에 훌륭한 오픈 소스 프로젝트를 발견했습니다. RAG 이 아이디어는 DeepSeek-R1 다음 조합의 추론 능력 Agentic Workflow RAG 검색에 적용
프로젝트 주소
https://github.com/deansaco/r1-reasoning-rag.git
이 프로젝트는 다음과 같은 조합을 통해 구현되고 있습니다. DeepSeek-R1및Tavily 노래로 응답 LangGraph를 활용하여 AI 주도의 동적 정보 검색 및 답변 메커니즘을 구현합니다. deepseek (명목식 형태로 사용됨) r1 지식창고에서 정보를 능동적으로 검색, 삭제 및 종합하여 복잡한 질문에 완벽하게 답하기 위한 추론 기능
올드 래그 대 뉴 래그
기존의 RAG(검색 증강 생성)는 다소 경직된 방식으로, 일반적으로 검색이 처리된 후 유사도 검색을 통해 일부 콘텐츠를 찾은 다음 일치 정도에 따라 순서를 다시 지정하고 신뢰할 수 있는 정보 조각을 대규모 언어 모델(LLM)에 제공하여 답변을 생성합니다. 하지만 이는 특히 재정렬 모델의 품질에 따라 달라지는데, 모델이 강력하지 않으면 중요한 정보를 놓치거나 잘못된 정보를 LLM에 전달하기 쉬워 결과물의 신뢰도가 떨어질 수 있습니다.
선물 . LangGraph 팀은 프로세스를 크게 업그레이드하여 DeepSeek-R1 AI의 강력한 추론 능력은 기존의 고정된 필터링 방식을 상황에 따라 조정할 수 있는 보다 유연하고 역동적인 프로세스로 변화시켰습니다. 이를 '에이전트 검색'이라고 부르는데, AI가 누락된 정보를 적극적으로 찾을 뿐만 아니라 정보를 검색하는 과정에서 자체 전략을 지속적으로 최적화하여 일종의 순환 최적화 효과를 형성함으로써 LLM에 전달되는 콘텐츠가 더욱 정확해질 수 있도록 합니다.
이 개선 사항은 실제로 모델 내에서 확장된 테스트 시간 추론의 개념을 RAG 검색에 적용하여 검색의 정확성과 효율성을 크게 향상시킵니다. 이 새로운 접근 방식은 RAG 검색 기술을 연구하는 사람들이 꼭 살펴볼 만한 가치가 있습니다!
핵심 기술 및 하이라이트
DeepSeek-R1 추론
업데이트 DeepSeek-R1 는 강력한 추론 모델입니다.
- 정보 콘텐츠에 대한 심층 사고 분석
- 기존 콘텐츠 평가
- 여러 차례의 추론을 통해 누락된 콘텐츠를 식별하여 검색 결과의 정확성 향상
빠른 정보 검색
Tavily 즉각적인 정보 검색을 제공하여 대형 모델을 최신 정보로 만들어 모델에 대한 지식의 범위를 확장할 수 있습니다.
- 정적 데이터에만 의존하지 않고 동적 검색을 통해 누락된 정보를 찾아낼 수 있습니다.
LangGraph 재귀 검색(RR)
통해 Agentic AI 메커니즘을 사용하여 대규모 모델이 여러 차례의 검색 및 추론 과정을 거친 후 폐루프 학습을 형성할 수 있도록 하며, 다음과 같은 일반적인 프로세스를 따릅니다:
- 첫 번째 단계는 문제에 대한 정보를 검색하는 것입니다.
- 두 번째 단계는 해당 정보가 질문에 답하기에 충분한지 분석하는 것입니다.
- 3단계 정보가 충분하지 않은 경우 추가 문의를 하세요.
- 4단계 관련 없는 콘텐츠를 필터링하고 유효한 정보만 보관하기
그런 递归式 검색 메커니즘은 대규모 모델이 지속적으로 쿼리 결과를 최적화하여 필터링된 정보를 더욱 완전하고 정확하게 만들 수 있도록 보장합니다.
소스 코드 분석
소스 코드를 보면 간단한 세 개의 파일로 구성되어 있습니다:agent및llm및prompts
에이전트
이 섹션의 핵심 아이디어는 다음과 같습니다. create_workflow 이 함수
 다음을 정의합니다.
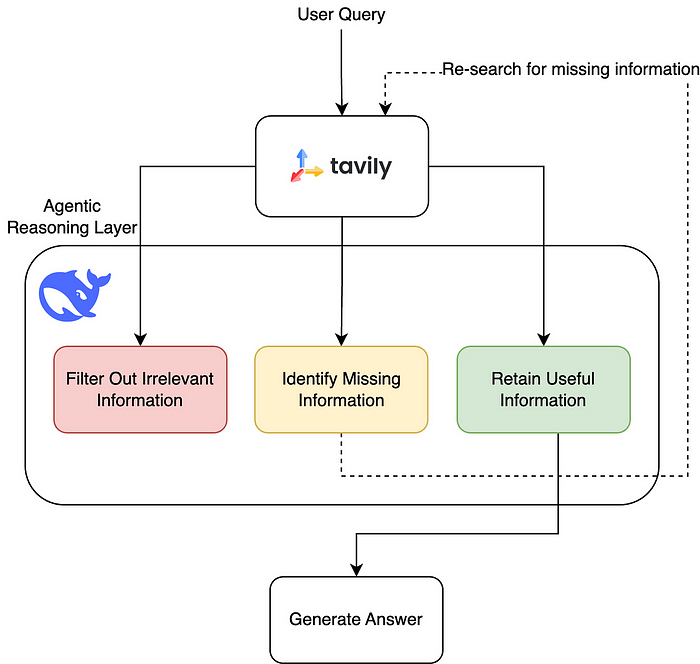
다음을 정의합니다. workflow 의 노드는 add_conditional_edges 정의의 일부는 조건부 가장자리이며, 처리의 전체 아이디어는 처음에 표시된 그래프의 재귀 논리입니다.
익숙하지 않은 경우 LangGraph 그렇다면 정보를 확인할 수 있습니다.LangGraph 이 구조는 노드와 에지가 있는 그래프 데이터 구조이며, 에지는 조건부일 수 있습니다.
각 검색 후에는 빅 모델에 의해 선별되어 쓸모없는 정보는 걸러내고(관련 없는 정보 필터링), 유용한 정보는 유지하고(유용한 정보 유지), 누락된 정보에 대해서는(누락된 정보 식별) 다시 한 번 검색됩니다. 원하는 답을 찾을 때까지 이 과정을 반복합니다.
프롬프트
여기에는 두 가지 주요 단서가 정의되어 있습니다.VALIDATE_RETRIEVAL 검색된 정보가 주어진 질문에 답할 수 있는지 확인하는 데 사용됩니다. 템플릿에는 retrieved_context와 question이라는 두 개의 입력 변수가 있습니다. 주요 목적은 제공된 텍스트 블록을 기반으로 질문에 답할 수 있는 정보가 포함되어 있는지 여부를 판단하는 JSON 형식의 응답을 생성하는 것입니다. 
ANSWER_QUESTION: 제공된 텍스트 블록을 기반으로 질문 답변 에이전트에게 질문에 답변하도록 지시하는 데 사용됩니다. 이 템플릿에는 retrieved_context와 question이라는 두 개의 입력 변수도 있습니다. 주요 목적은 주어진 컨텍스트 정보를 기반으로 직접적이고 간결한 답변을 제공하는 것입니다.

llm
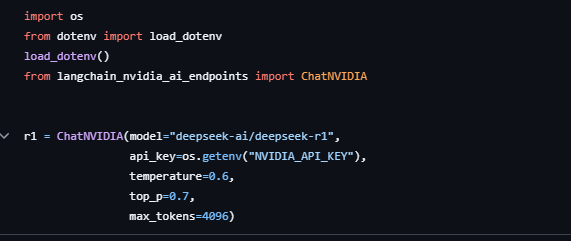
여기서는 간단하게 r1 모델링
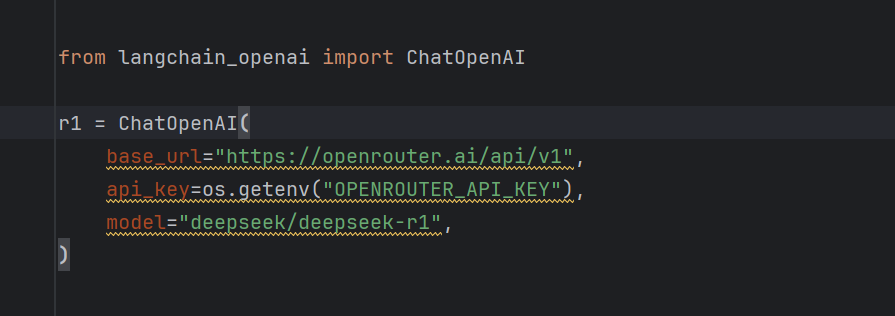
다음과 같이 다른 공급업체에서 제공하는 모델로 전환할 수 있습니다. openrouter 무료 r1 모델링
테스트 효과
프로젝트에 있는 스크립트를 사용하지 않는 별도의 스크립트를 작성했습니다. 《哪吒2》中哪吒的师傅的师傅是谁
먼저 검색을 호출하여 정보를 조회한 다음 다음과 같이 유효성 검사를 시작합니다.

그런 다음 분석을 시작하고 다음을 얻습니다. 哪吒的师父是太乙真人 이 정보는 유효하지만 누락된 정보도 발견되었습니다. 타이이의 마스터(예: 네자의 마스터)의 구체적인 신원 또는 이름

그런 다음 누락된 정보를 검색하고 검색에서 돌아온 정보를 계속 분석하고 확인합니다.
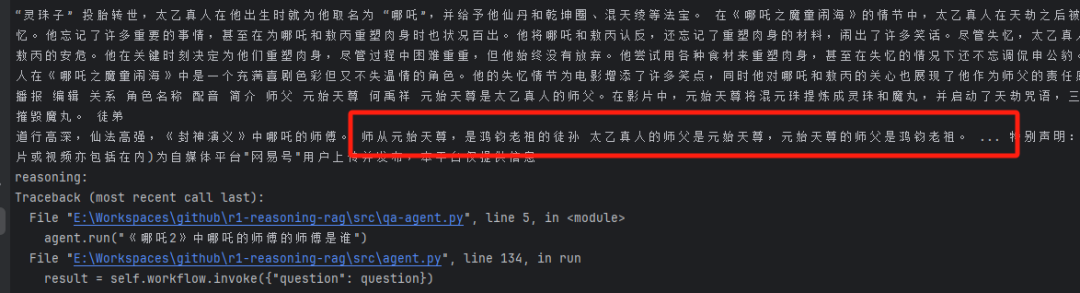
나중에 네트워크가 다운되어 오류를 보고했지만, 위 이미지에서 볼 수 있듯이 다음과 같은 핵심 정보를 찾을 수 있어야 합니다.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서




댓글 없음...