
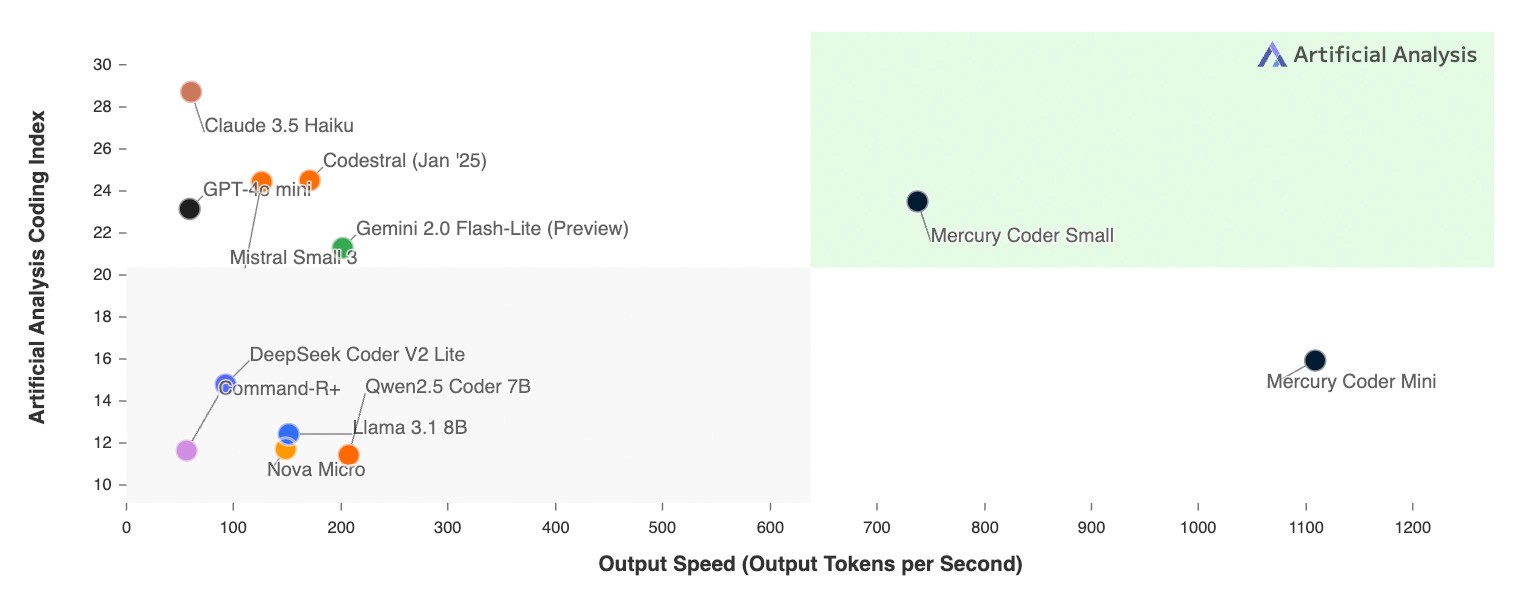

대형 언어 모델 분야에 새로운 멤버가 등장했습니다. 최근 대형 언어 모델인 Qwen 제품군은 최신 버전인 Qwen3를 출시했습니다. 개발팀에 따르면 플래그십 모델인 Qwen3-235B-A22B는 코딩, 수학 및 범용 능력의 벤치마크에서 Qwen3-235B-A22B와 비교하여 우위를 보인 것으로 나타났습니다. DeepSeek-R1 , o1 . o3-mini Qwen3는 Grok-3 및 Gemini-2.5-Pro와 같은 업계 최고 모델의 성능에 맞도록 설계되었습니다. 이러한 경쟁 모델 선정은 현재 성능 벤치마크와 직접적으로 경쟁하는 것을 목표로 하는 Qwen3의 포지셔닝을 반영합니다.

흥미로운 점은 소규모 혼합 전문가(MoE) 모델인 Qwen3-30B-A3B가 더 많은 수의 공변량(비록 후자의 활성화 매개변수의 10분의 1이지만)을 가진 QwQ-32B보다 성능이 더 뛰어나다고 주장되며, 심지어 더 작은 Qwen3-4B 모델도 Qwen2.5-72B-Instruct의 성능과 일치한다고 주장된다는 점입니다. 이는 최적화된 모델 아키텍처와 개선된 훈련 방법으로 인해 상당한 효율성 향상을 보여줍니다.

이번 릴리스의 하이라이트는 두 가지 MoE 모델의 가중치를 개방한 것입니다: Qwen3-235B-A22B(총 파라미터 235억 개, 활성화 220억 개) 및 Qwen3-30B-A3B(총 파라미터 300억 개, 활성화 30억 개). MoE는 추론 시 모델이 "전문가" 네트워크의 일부만 활성화할 수 있도록 하는 기법으로, 강력한 성능을 유지하면서 계산 요구 사항을 크게 줄여줍니다. MoE는 모델이 추론할 때 '전문가' 네트워크의 일부만 활성화하도록 허용하는 기술로, 강력한 성능을 유지하면서 계산 요구 사항을 크게 줄여주므로 광범위한 시나리오에서 대규모 모델을 배포하는 데 중요합니다.
또한 Apache 2.0 라이선스에 따라 6억에서 320억 사이의 파라미터 크기를 커버하는 6개의 고밀도 모델, 즉 Qwen3-32B, Qwen3-14B, Qwen3-8B, Qwen3-4B, Qwen3-1.7B 및 Qwen3-0.6B에 대한 가중치를 개방했습니다.
모델 사양 개요(고밀도 모델):
| 모델 | 레이어 | 헤드(Q/KV) | 넥타이 임베딩 | 컨텍스트 길이 |
|---|---|---|---|---|
| Qwen3-0.6B | 28 | 16 / 8 | 예 | 32K |
| Qwen3-1.7B | 28 | 16 / 8 | 예 | 32K |
| Qwen3-4B | 36 | 32 / 8 | 예 | 32K |
| Qwen3-8B | 36 | 32 / 8 | 아니요 | 128K |
| Qwen3-14B | 40 | 40 / 8 | 아니요 | 128K |
| Qwen3-32B | 64 | 64 / 8 | 아니요 | 128K |
모델 사양 개요(MoE 모델):
| 모델 | 레이어 | 헤드(Q/KV) | # 전문가(총 / 활성화됨) | 컨텍스트 길이 |
|---|---|---|---|---|
| Qwen3-30B-A3B | 48 | 32 / 4 | 128 / 8 | 128K |
| Qwen3-235B-A22B | 94 | 64 / 4 | 128 / 8 | 128K |
이러한 모델과 사전 학습된 버전(예: Qwen3-30B-A3B-Base)은 이미 허깅 페이스, 모델스코프, 캐글 등과 같은 주요 플랫폼에서 사용 중입니다. 모델 배포를 위해서는 SGLang과 vLLM 및 기타 프레임워크. 로컬 사용 시나리오의 경우 Ollama, LMStudio, MLX llama.cpp및 KT트랜스포머 및 기타 도구로 쉽게 액세스할 수 있습니다.
개발자는 다음을 사용할 수 있습니다. Qwen 채팅 웹 및 모바일 애플리케이션을 통해 Qwen3의 강력한 성능을 경험해 보세요.
핵심 기능 분석
Qwen3에는 몇 가지 주목할 만한 기능이 도입되었습니다:
- 하이브리드 사고 모드Qwen3는 두 가지 문제 해결 모드를 지원합니다:
- 사고 모드. 이 모델은 단계별 추론을 수행하고 사고 과정을 보여준 다음 최종 답을 제시합니다. 이는 심층 분석이 필요한 복잡한 문제에 적용됩니다.
- 비사고 모드. 이 모델은 속도가 중요하고 문제가 비교적 간단한 시나리오에 대해 거의 즉각적으로 빠르게 응답합니다.
이 설계는 사용자가 작업의 필요에 따라 모델의 '사고의 깊이'를 유연하게 제어할 수 있도록 해줍니다. 더 중요한 것은 이 하이브리드 모델을 통해 모델의 '사고 예산'을 안정적이고 효율적으로 제어할 수 있다는 점입니다. 아래 그림에서 볼 수 있듯이 Qwen3의 성능은 할당된 계산 추론 예산과 직접적으로 관련된 확장성과 원활한 개선을 보여줍니다. 사용자는 특정 작업에 대한 예산을 보다 쉽게 구성할 수 있으므로 비용 효율성과 추론 품질 간의 균형을 더 잘 찾을 수 있습니다. 이는 실제 애플리케이션에서 대규모 모델의 비용 관리를 위한 새로운 아이디어를 제공합니다.

- 광범위한 다국어 지원Qwen3 모델은 최대 119개 언어 및 방언. 이 광범위한 다국어 기능은 국제화된 애플리케이션의 새로운 가능성을 열어주며 전 세계 사용자가 모델을 활용할 수 있도록 지원합니다.
언어 계열 언어 및 방언 인도-유럽 영어, 프랑스어, 포르투갈어, 독일어, 루마니아어, 스웨덴어, 덴마크어, 불가리아어, 러시아어, 체코어, 그리스어, 우크라이나어, 스페인어, 네덜란드어, 슬로바키아어, 크로아티아어. 폴란드어, 리투아니아어, 노르웨이어 복말, 노르웨이어 니노르스크어, 페르시아어, 슬로베니아어, 구자라트어, 라트비아어, 이탈리아어, 오크어, 네팔어, 마라티아어, 벨로루시어. 세르비아어, 룩셈부르크어, 베네치아어, 아삼어, 웨일스어, 실레지아어, 아스투리아스어, 차티스가르히어, 아와디어, 마이틸리어, 보즈푸리어, 신드어, 아일랜드어, 파로어, 힌디어. 펀자브어, 벵골어, 오리야어, 타지크어, 동부 이디시어, 롬바르드어, 리구리아어, 시칠리아어, 프리울어, 사르디니아어, 갈리시아어, 카탈로니아어, 아이슬란드어, 토스크 알바니아어. 림부르크어, 다리어, 아프리칸스어, 마케도니아어, 신할라어, 우르두어, 마가히어, 보스니아어, 아르메니아어 중국-티베트어 중국어(중국어 간체, 중국어 번체, 광동어, 버마어), 미얀마어 아프리카-아시아 아랍어(표준, 나지디어, 레반트어, 이집트어, 모로코어, 메소포타미아어, 타이지-아데니어, 튀니지어), 히브리어, 몰타어 오스트로네시안 인도네시아어, 말레이어, 타갈로그어, 세부아노어, 자바어, 순다어, 미낭카바우어, 발리어, 반자르어, 판가시난어, 일로코어, 와라이어(필리핀) 드라비디안 타밀어, 텔루구어, 칸나다어, 말라얄람어 터키어 터키어, 북아제르바이잔어, 우즈벡어 북부, 카자흐어, 바슈키르어, 타타르어 타이카다이 태국어, 라오스어 우랄어 핀란드어, 에스토니아어, 헝가리어 오스트리아 아시아 베트남어, 크메르어 기타 일본어, 한국어, 바스크어, 아이티어, 파피아멘토어, 카부베르디아누어, 톡피신어, 스와힐리어, 스와힐리어 - 향상된 에이전트 기능Qwen3 모델은 코딩과 지능형 에이전트(에이전트)로서 작업을 수행하는 기능에 최적화되어 있습니다. 또한 다중 에이전트 협업 플랫폼을 지칭할 수 있는 MCP에 대한 지원도 강화했습니다. 아래 동영상 링크는 Qwen3가 어떻게 생각하고 환경과 상호 작용하는지(예: 도구 호출) 보여줍니다.동영상 프레젠테이션 링크: https://qianwen-res.oss-accelerate-overseas.aliyuncs.com/mcp.mov
교육 세부 정보: 데이터, 단계 및 최적화
Qwen3의 사전 학습 데이터의 양은 18조 토큰을 사용한 Qwen2.5와 119개 언어와 방언을 포괄하는 약 36조 토큰으로 두 배 가까이 많은 사전 학습 데이터를 보유한 Qwen3보다 훨씬 큽니다.
데이터 소스에는 웹 페이지뿐만 아니라 PDF와 같은 문서도 포함되어 있습니다. 팀은 다음을 활용합니다. Qwen2.5-VL 이 모델은 이러한 문서에서 텍스트를 추출하고 Qwen2.5를 사용하여 추출된 콘텐츠의 품질을 향상시켰습니다. 수학 및 코드 데이터의 비중을 높이기 위해 교과서, 퀴즈 쌍, 코드 스니펫과 같은 합성 데이터도 Qwen2.5-Math 및 Qwen2.5-Coder를 사용하여 생성했습니다.
사전 교육 과정은 세 단계로 나뉩니다:
- S1 단계. 30조 달러 이상 토큰 사전 학습은 4K 토큰의 컨텍스트 길이에 대해 수행되며, 이 단계는 모델에 기본적인 언어 기술과 일반적인 지식을 제공하는 것을 목표로 합니다.
- S2 단계. 지식 집약적인 데이터(예: STEM, 코딩, 추론 작업)의 비율을 높이고, 데이터 세트를 최적화하며, 추가로 5조 개의 토큰에 대한 사전 학습을 계속합니다.
- S3 단계. 고품질의 긴 컨텍스트 데이터를 사용하면 모델의 컨텍스트 길이가 32K 토큰(일부 모델의 경우 128K까지)으로 확장되어 모델이 긴 입력을 효율적으로 처리할 수 있습니다.

개선된 모델 아키텍처, 늘어난 학습 데이터, 더 효율적인 학습 방법 덕분에 Qwen3 고밀도 기본 모델의 전반적인 성능은 훨씬 더 많은 수의 공변수를 가진 Qwen2.5 기본 모델 수준에 도달했습니다. 예를 들어, Qwen3-1.7B/4B/8B/14B/32B-Base는 각각 Qwen2.5-3B/7B/14B/32B/72B-Base와 비슷한 성능을 발휘합니다. 특히, Qwen3 고밀도 베이스 모델은 STEM, 코딩, 추론과 같은 영역에서 더 큰 Qwen2.5 모델보다 성능이 뛰어납니다.
Qwen3-MoE 기본 모델의 경우, 약 10% 활성화 파라미터만 사용하여 Qwen2.5 고밀도 기본 모델과 유사한 성능을 달성하므로 학습 및 추론 비용을 크게 절감할 수 있습니다.
교육 후 프로세스

단계적 추론과 빠른 응답 기능을 결합한 혼합 모드 모델을 개발하기 위해 Qwen 팀은 4단계의 사후 교육 프로세스를 구현했습니다:
- 긴 CoT 콜드 스타트. 수학, 코딩, 논리적 추론, STEM 등 다양한 작업과 영역을 포괄하는 긴 사고 데이터 체인을 사용하여 모델을 미세 조정하여 기초적인 추론 능력을 키울 수 있도록 합니다.
- 추론 기반 RL. 강화 학습에 대한 계산 리소스 투자를 확대하고 규칙 기반 보상(RBR)을 활용하여 모델의 탐색 및 활용을 강화하여 추론 성능을 더욱 향상시킵니다.
- 사고 패턴 융합. 비사고 능력을 사고 모델에 통합합니다. 추론과 신속한 대응 능력의 통합은 2단계의 강화된 사고 모델에서 생성된 긴 CoT 데이터와 일반화된 명령 미세 조정 데이터를 혼합하여 미세 조정함으로써 이루어집니다.
- 일반 강화 학습(일반 RL). 강화 학습은 20개 이상의 일반 도메인 작업에 적용되어 모델의 일반 기능(예: 명령어 준수, 형식 준수, 상담원 기능 등)을 더욱 강화하고 바람직하지 않은 동작을 수정합니다.
Qwen3로 개발
다음은 다양한 프레임워크에서 Qwen3를 사용하는 방법에 대한 간략한 가이드입니다. 첫 번째는 허깅 페이스 트랜스포머 라이브러리에서 Qwen3-30B-A3B를 사용하는 표준 예제입니다:
from modelscope import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-30B-A3B"
# 加载 tokenizer 和模型
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# 准备模型输入
prompt = "给我简要介绍一下大型语言模型。"
messages = [
{"role": "user", "content": prompt}
]
# apply_chat_template 用于构建符合 Qwen 对话格式的输入
# enable_thinking=True 启用思考模式 (默认为 True)
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True # 在思考模式和非思考模式间切换,默认为 True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# 进行文本生成
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768 # 设置最大生成 token 数
)
# 提取生成的内容部分 (去除输入部分)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# 解析思考内容 (如果存在)
# 寻找 '</think>' 对应的 token id (151668)
try:
# rindex 从后往前查找 151668
index = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:
# 如果没有找到 '</think>',说明没有思考内容
index = 0
# 分别解码思考内容和最终回复内容
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")
print("思考内容:", thinking_content)
print("最终回复:", content)
사고 모드를 비활성화하려면 enable_thinking 매개변수를 False로 설정하면 됩니다:
text = tokenizer.apply_chat_template( messages, tokenize=False, add_generation_prompt=True, enable_thinking=False # 默认为 True )
모델 배포의 경우, sglang>=0.4.6.post1 또는 vllm>=0.8.4를 사용하여 OpenAI API와 호환되는 엔드포인트를 만들 수 있습니다:
- SGLang 사용.
python -m sglang.launch_server --model-path Qwen/Qwen3-30B-A3B --reasoning-parser qwen3
- vLLM 사용.
vllm serve Qwen/Qwen3-30B-A3B --enable-reasoning --reasoning-parser deepseek_r1
(참고: 이 글의 원본은 deepseek_r1 파서를 사용하며, 개발자는 Qwen3와의 호환성을 확인해야 합니다).
로컬 개발 환경에서는 다음과 같은 간단한 명령으로 ollama를 사용할 수 있습니다. ollama 를 실행하여 모델과 상호 작용할 수 있습니다. 또한 LMStudio, llama.cpp, ktransformers와 같은 도구는 로컬에서 Qwen3를 빌드하고 실행하는 것을 지원합니다.
고급 사용법: 사고 모드의 동적 전환
Qwen3는 enable_thinking = True일 때 사용자가 모델의 동작을 동적으로 제어할 수 있는 "소프트 스위칭" 메커니즘을 제공합니다. 구체적으로, 사용자 질문이나 시스템 메시지에 /think 또는 /no_think 태그를 추가하여 모델의 사고 모드를 라운드마다 전환할 수 있습니다. 여러 라운드의 대화에서 모델은 가장 최근의 지시를 따릅니다.
다음은 다중 라운드 대화의 예입니다:
from transformers import AutoModelForCausalLM, AutoTokenizer
class QwenChatbot:
def __init__(self, model_name="Qwen/Qwen3-30B-A3B"):
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
# 注意:实际运行时需要确保有足够的 GPU 显存加载模型
# device_map="auto" 可能需要根据实际硬件调整
self.model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto", # 自动选择合适的精度
device_map="auto" # 自动分配模型到可用设备
)
self.history = [] # 用于存储对话历史
def generate_response(self, user_input):
# 将当前用户输入加入历史记录
messages = self.history + [{"role": "user", "content": user_input}]
# 使用 apply_chat_template 构建输入
# 注意:这里没有显式设置 enable_thinking,会使用模型的默认行为或最近的 /think /no_think 指令
text = self.tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
inputs = self.tokenizer(text, return_tensors="pt").to(self.model.device)
# 生成回复
response_ids = self.model.generate(
**inputs,
max_new_tokens=32768 # 设置最大生成 token 数
)[0][len(inputs.input_ids[0]):].tolist() # 提取生成内容
# 解码回复文本
response = self.tokenizer.decode(response_ids, skip_special_tokens=True).strip()
# 更新对话历史
self.history.append({"role": "user", "content": user_input})
# 注意:此处仅添加解码后的纯文本回复,未处理思考内容
# 如果需要保留或展示思考过程,需要像之前的例子一样解析 output_ids
self.history.append({"role": "assistant", "content": response})
# 返回解码后的回复文本
return response
# 示例用法
if __name__ == "__main__":
# 确保在有足够资源的机器上运行
try:
chatbot = QwenChatbot()
# 第一次输入 (默认启用思考模式)
user_input_1 = "strawberries 这个单词里有多少个 'r'?"
print(f"用户: {user_input_1}")
response_1 = chatbot.generate_response(user_input_1)
print(f"助手: {response_1}")
print("----------------------")
# 第二次输入,使用 /no_think 禁用思考模式
user_input_2 = "那么,blueberries 这个单词里有多少个 'r'? /no_think"
print(f"用户: {user_input_2}")
response_2 = chatbot.generate_response(user_input_2)
print(f"助手: {response_2}")
print("----------------------")
# 第三次输入,使用 /think 再次启用思考模式
user_input_3 = "真的吗?请再想想。 /think"
print(f"用户: {user_input_3}")
response_3 = chatbot.generate_response(user_input_3)
print(f"助手: {response_3}")
except Exception as e:
print(f"运行出错: {e}")
print("请确保已安装所需依赖,并拥有足够的计算资源(如 GPU 显存)。")
상담원 사용법: 도구 호출
Qwen3는 도구 호출 기능이 뛰어납니다. 권장 사용 Qwen-Agent 프레임워크(https://github.com/QwenLM/Qwen-Agent)를 사용하여 Qwen3의 에이전트 기능을 최대한 활용할 수 있습니다. Qwen-Agent는 내부적으로 도구 호출을 위한 템플릿과 파서를 캡슐화하여 개발 복잡성을 간소화합니다.
이 작업은 다음과 같이 수행할 수 있습니다. MCP 구성 파일을 사용하거나, Qwen-Agent의 통합 도구를 사용하거나, 다른 도구를 직접 통합하여 사용 가능한 도구 집합을 정의할 수 있습니다.
import os
from qwen_agent.agents import Assistant
# 定义 LLM 配置
llm_cfg = {
'model': 'Qwen3-30B-A3B', # 指定使用的 Qwen3 模型
# 如果使用阿里云 ModelScope 提供的 DashScope API:
# 'model_type': 'qwen_dashscope',
# 'api_key': os.getenv('DASHSCOPE_API_KEY'), # 需要设置环境变量
# 如果使用兼容 OpenAI API 的自定义端点 (例如 VLLM 或 SGLang 部署的):
'model_server': 'http://localhost:8000/v1', # 替换为你的 API 地址
'api_key': 'EMPTY', # 对于本地部署或不需要 key 的情况
# 可选:其他生成参数配置
# 'generate_cfg': {
# # 如果模型的原始输出将思考过程 <think>...</think> 包含在最终内容里,设为 True
# # 如果 VLLM/SGLang 等框架已分离 reasoning_content 和 content,则设为 False 或不设置
# 'thought_in_content': False,
# },
}
# 定义工具列表
tools = [
{'mcpServers': { # 可以指定 MCP 配置文件或直接定义服务
'time': { # 定义一个名为 'time' 的工具
'command': 'uvx', # 使用 uvx 启动
# 启动参数,运行 mcp-server-time,并设置时区
'args': ['mcp-server-time', '--local-timezone=Asia/Shanghai']
},
"fetch": { # 定义一个名为 'fetch' 的工具,用于访问网页
"command": "uvx",
"args": ["mcp-server-fetch"]
}
}
},
'code_interpreter', # 使用 Qwen-Agent 内置的代码解释器工具
# 可以继续添加其他自定义或内置工具
]
# 初始化 Agent
# 需要确保 uvx 和相应的 mcp-server-* 已安装并配置好
bot = Assistant(llm=llm_cfg, function_list=tools)
# 流式生成调用示例
messages = [{'role': 'user', 'content': '访问 https://qwenlm.github.io/blog/ 页面,并介绍一下 Qwen 的最新进展。'}]
responses = None # 初始化 responses 变量
# bot.run 返回一个生成器,用于流式输出
for responses in bot.run(messages=messages):
# 可以在这里处理中间步骤的输出,例如工具调用和观察结果
# print(responses) # 打印每个中间步骤或最终回复
pass # 循环结束后,responses 将包含最终的完整回复
# 打印最终的回复内容
if responses:
print(responses)
else:
print("未能获取到回复。")
(참고: 에이전트 예제를 실행하려면 qwen-agent 라이브러리 및 관련 종속성을 설치하고, uvx 및 mcp-server-* 도구를 사용할 수 있는지 확인해야 합니다.)
향후 전망
Qwen3는 일반 인공 지능(AGI)과 초인공지능(ASI)을 향한 여정에서 중요한 이정표로 여겨집니다. 이 모델은 사전 학습과 강화 학습을 확장함으로써 더 높은 수준의 지능을 달성합니다. 하이브리드 사고 패턴의 융합으로 사용자는 사고 예산을 유연하게 제어할 수 있으며, 광범위한 언어 지원으로 글로벌 접근성이 향상됩니다.
앞으로 Qwen 팀은 데이터 확장을 위한 모델 아키텍처 및 훈련 방법 최적화, 모델 크기 증가, 컨텍스트 길이 확장, 양식 지원 확대, 환경 피드백을 통한 강화 학습 발전 등 여러 차원에서 모델 기능을 지속적으로 개선하여 장기적인 추론을 가능하게 할 계획입니다. 팀은 업계가 '모델'을 훈련하는 시대에서 '인텔리전스'(에이전트)를 훈련하는 시대로 나아가고 있다고 믿습니다. 다음 단계에서는 업무와 생활에 더욱 의미 있는 발전을 가져올 것으로 기대합니다.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서



댓글 없음...