

1. 소개
두 달 전, Qwen 팀은 최대 100만 토큰의 컨텍스트 길이를 지원하도록 Qwen2.5-Turbo를 업그레이드했습니다. 오늘, Qwen은 오픈 소스 Qwen2.5-1M 모델과 그에 상응하는 추론 프레임워크 지원을 공식적으로 출시했습니다. 다음은 이번 릴리스의 주요 내용입니다:
오픈 소스 모델: 다음과 같은 두 가지 새로운 오픈 소스 모델이 출시되었습니다. Qwen2.5-7B-Instruct-1M 노래로 응답 Qwen2.5-14B-Instruct-1M오픈 소스 Qwen 모델의 컨텍스트를 1M 길이로 확장한 것은 이번이 처음입니다.
추론 프레임워크: 개발자가 Qwen2.5-1M 모델 제품군을 보다 효율적으로 배포할 수 있도록, Qwen 팀은 다음을 기반으로 Qwen2.5-1M 모델을 완전히 오픈소스화했습니다. vLLM 추론 프레임워크에 통합된 희소주의 접근 방식을 사용하여 다음과 같이 1백만 개의 레이블이 지정된 입력을 더 빠르게 처리할 수 있습니다. 3배에서 7배.
기술 보고서: 또한 Qwen 팀은 훈련 및 추론 프레임워크의 디자인 사고와 절제 실험의 결과를 포함하여 Qwen2.5-1M 시리즈의 기술적 세부 사항을 공유했습니다.
모델 링크:https://www.modelscope.cn/collections/Qwen25-1M-d6cf9fd33f0a40
기술 보고서:https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2.5-1M/Qwen2_5_1M_Technical_Report.pdf
경험 링크:https://modelscope.cn/studios/Qwen/Qwen2.5-1M-Demo
2. 모델 성능
먼저, 긴 컨텍스트 작업과 짧은 텍스트 작업에서 Qwen2.5-1M 모델 제품군의 성능을 살펴 보겠습니다.
긴 컨텍스트 작업
컨텍스트 길이가 1백만인 경우 토큰 패스키 검색 작업에서 Qwen2.5-1M 모델 제품군은 1M 길이의 문서에서 숨겨진 정보를 정확하게 검색했으며, 7B 모델에서는 몇 가지 오류만 발생했습니다.
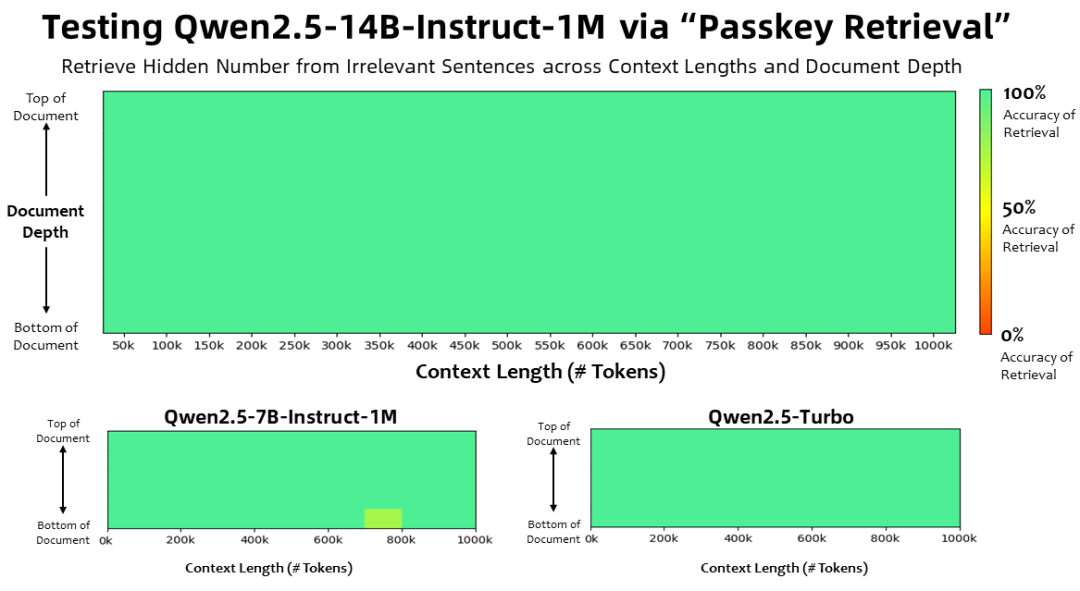
보다 복잡한 긴 컨텍스트 이해 작업을 위해 RULER, LV-Eval 및 LongbenchChat 테스트 세트가 선택되었습니다.
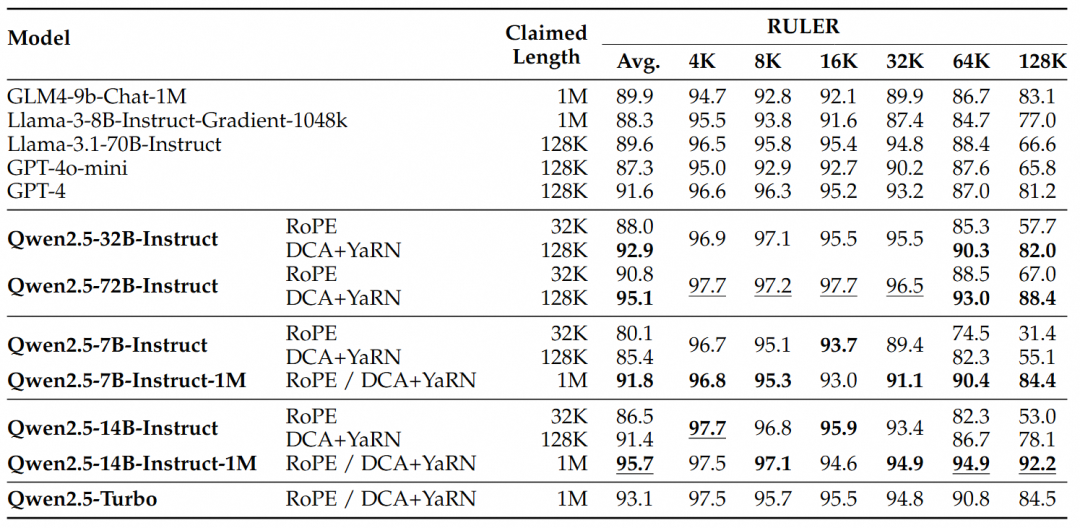
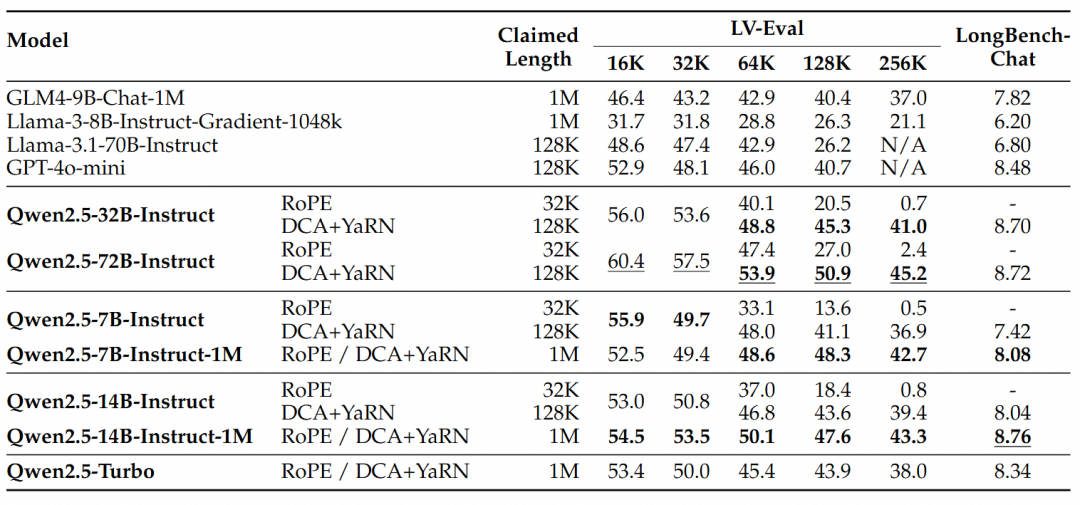
이러한 결과를 통해 다음과 같은 주요 결론을 도출할 수 있습니다:
- 128K 버전보다 성능이 훨씬 뛰어납니다:Qwen2.5-1M 모델 제품군은 대부분의 긴 컨텍스트 작업, 특히 64K 이상의 작업을 처리할 때 이전 128K 버전보다 훨씬 뛰어난 성능을 발휘합니다.
- 성능상의 이점은 분명합니다:Qwen2.5-14B-Instruct-1M 모델은 Qwen2.5-Turbo를 능가할 뿐만 아니라 여러 데이터 세트에서 GPT-4o-mini를 지속적으로 능가하여 긴 컨텍스트 작업에 적합한 오픈 소스 모델을 제공합니다.
짧은 순차 작업
긴 시퀀스 작업에서의 성능뿐만 아니라 짧은 시퀀스에서의 모델 성능도 똑같이 중요합니다. 널리 사용되는 학술 벤치마크에서 Qwen2.5-1M 시리즈 모델과 이전 128K 버전을 비교했으며, 비교를 위해 GPT-4o-mini를 추가했습니다. 
찾을 수 있습니다:
- 짧은 텍스트 작업에서 Qwen2.5-7B-Instruct-1M 및 Qwen2.5-14B-Instruct-1M의 성능은 128K 버전과 비슷하며, 긴 시퀀스 처리 기능이 추가되어도 기본 기능이 저하되지 않았습니다.
- 짧은 텍스트 작업에서 Qwen2.5-14B-Instruct-1M 및 Qwen2.5-Turbo는 GPT-4o-mini와 비교해 비슷한 성능을 달성하는 반면 컨텍스트 길이는 GPT-4o-mini의 8배에 달합니다.
3. 주요 기술
긴 컨텍스트 교육
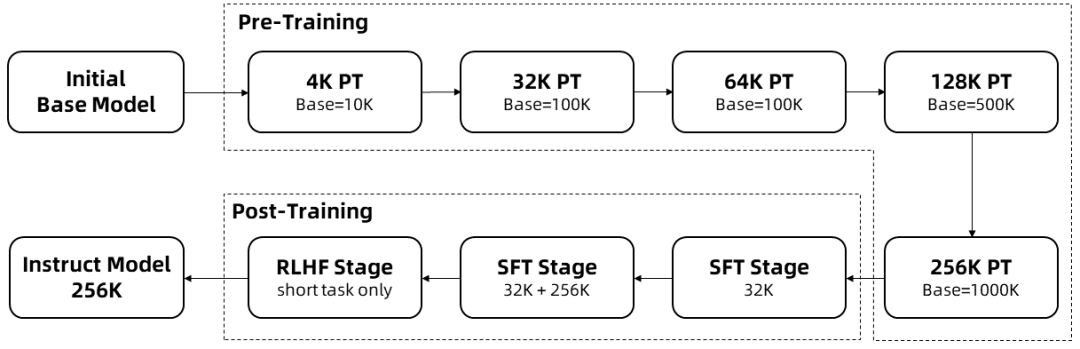
긴 시퀀스의 훈련에는 많은 계산 리소스가 필요하므로, 단계적으로 길이를 확장하는 방법을 사용하여 Qwen2.5-1M의 컨텍스트 길이를 4K에서 256K로 여러 단계에 걸쳐 확장했습니다:
사전 학습된 Qwen2.5의 중간 체크포인트에서 시작하며, 이 시점에서 컨텍스트 길이는 4K입니다.
사전 교육 단계 중또한 컨텍스트 길이를 4K에서 256K로 점진적으로 늘리고, 조정된 기본 주파수 체계를 사용하여 RoPE 기본 주파수를 10,000에서 10,000,000으로 늘렸습니다.
모니터링 미세 조정 단계 중를 두 단계로 나누어 짧은 시퀀스에서도 성능을 유지합니다:
1단계: 미세 조정은 Qwen2.5의 128K 버전과 동일한 데이터 및 단계 수가 사용되는 짧은 명령어(최대 32K 길이)에 대해서만 수행됩니다.
2단계: 짧은 명령어(최대 32K)와 긴 명령어(최대 256K)를 혼합하여 짧은 작업의 품질을 유지하면서 긴 작업의 성능을 향상시킵니다.
집중 학습 단계를 사용하여 짧은 텍스트(최대 8K 토큰)로 모델을 훈련했습니다. 짧은 텍스트로 훈련한 경우에도 사람이 선호하는 정렬의 향상은 긴 컨텍스트 작업에도 잘 일반화된다는 사실을 발견했습니다. 위의 학습을 통해 최대 256K 토큰 길이의 시퀀스를 처리할 수 있는 Instruct 모델을 완성했습니다.
위의 학습을 통해 256K 컨텍스트 길이의 명령어 미세 조정 모델을 얻습니다.
길이 외삽
위의 학습 과정에서 모델의 컨텍스트 길이는 256K 토큰에 불과합니다. 이를 100만 토큰까지 확장하기 위해 길이 추정 기법이 사용됩니다.
현재 회전 위치 인코딩을 기반으로 하는 대규모 언어 모델은 긴 문맥 작업에서 성능이 저하되는데, 이는 주로 주의 가중치를 계산할 때 학습 과정에서 보이지 않는 쿼리와 키 사이의 큰 상대 위치 거리로 인해 발생합니다. 이 문제를 해결하기 위해 Qwen2.5-1M은 과도하게 큰 상대적 위치를 더 작은 값으로 다시 매핑하여 이 문제를 해결하는 이중 청크 주의(DCA) 접근 방식을 사용합니다.
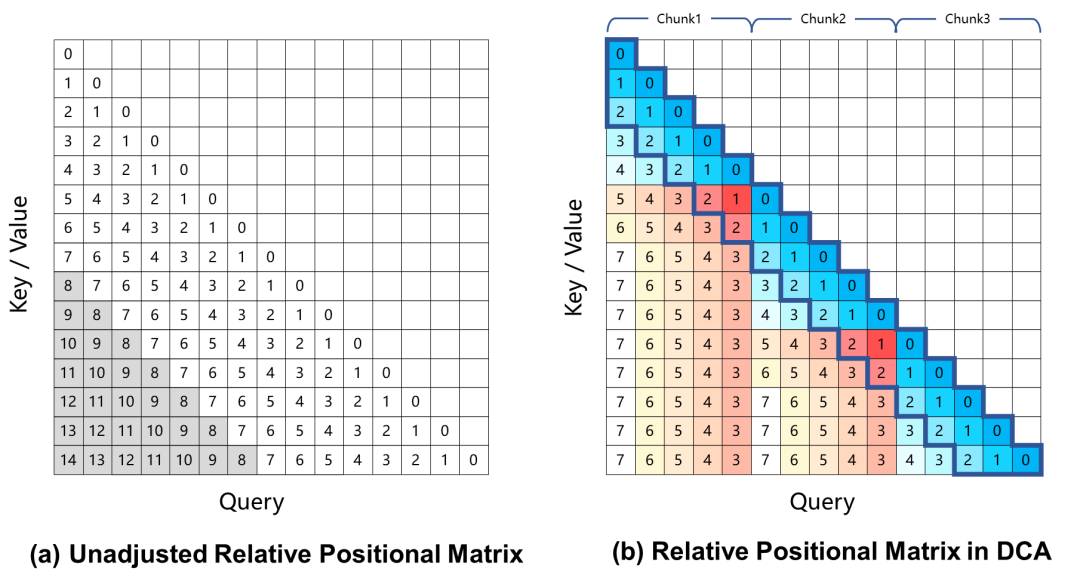
Qwen2.5-1M 모델과 이전 128K 버전은 길이 외삽 방법을 사용하거나 사용하지 않고 평가했습니다.
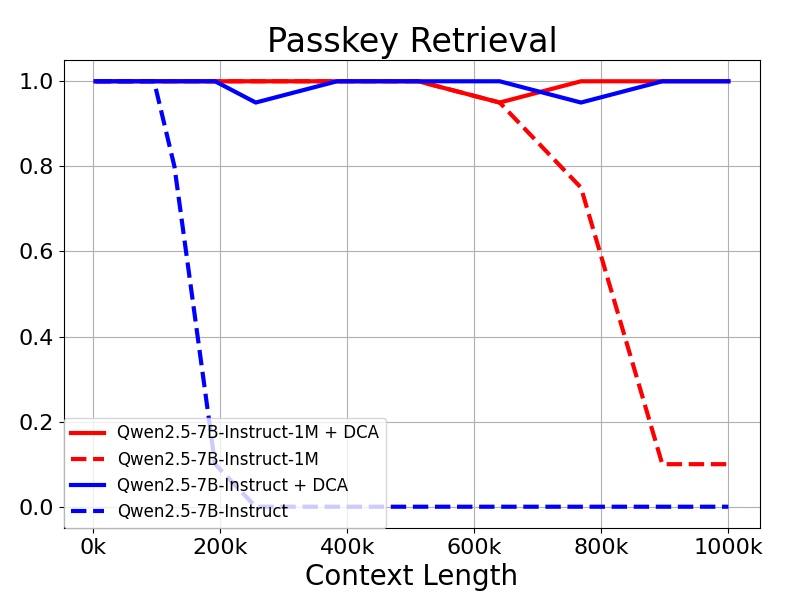
그 결과, Qwen2.5-7B-Instruct와 같이 32K 토큰으로만 훈련된 모델조차도 패스키의 100만 토큰 컨텍스트를 처리하는 데 성공하지 못하는 것으로 나타났습니다. 검색 또한 이 작업은 거의 완벽에 가까운 정확도를 달성합니다. 이는 추가 교육 없이도 지원되는 컨텍스트의 길이를 크게 확장할 수 있는 DCA의 힘을 보여줍니다.
희소 주의 메커니즘(입자 물리학)
긴 문맥 언어 모델의 경우 추론 속도는 사용자 경험에 매우 중요합니다. 사전 입력 단계의 속도를 높이기 위해 연구팀은 다중 추론에 기반한 희소주의 메커니즘을 도입했습니다. 또한 몇 가지 개선 사항을 제안합니다:
- 청크드 프리필: 모델이 최대 100만 길이의 시퀀스를 처리하는 데 직접 사용되는 경우, MLP 계층의 활성화 가중치로 인해 Qwen2-5-7B의 경우 최대 71GB에 달하는 막대한 메모리 오버헤드가 발생합니다. Qwen2.5-7B를 예로 들면 이 부분의 오버헤드는 71GB에 달합니다. 청크드 프리필을 적용하면 입력 시퀀스를 32768개의 길이로 청크화하여 하나씩 미리 채울 수 있으며 MLP 계층에서 활성화 가중치의 메모리 사용량을 96.7%까지 줄일 수 있어 장치의 메모리 요구량을 크게 줄일 수 있습니다.
- 통합 길이 추정 체계: DCA 기반 길이 추정 체계를 희소주의 메커니즘에 통합하여 추론 프레임워크가 긴 시퀀스 작업에서 추론 효율성과 정확성을 모두 높일 수 있도록 지원합니다.
- 희소성 최적화: 원래의 다중 추론 방식은 각 주의 헤드에 대한 최적의 희소화 구성을 결정하기 위해 오프라인 검색이 필요합니다. 이 검색은 일반적으로 짧은 시퀀스에서 수행되며, 전체 주의 가중치의 메모리 요구량이 크기 때문에 긴 시퀀스에서는 잘 작동하지 않습니다. 저희는 100만 개 길이의 시퀀스에서 희소화 구성을 최적화하여 희소주의로 인한 정확도 손실을 크게 줄일 수 있는 방법을 제안합니다.
- 기타 최적화: 전체 프레임워크의 잠재력을 최대한 활용하기 위해 운영자 효율성 최적화 및 동적 청킹 파이프라인 병렬 처리와 같은 기타 최적화 기능을 도입했습니다.
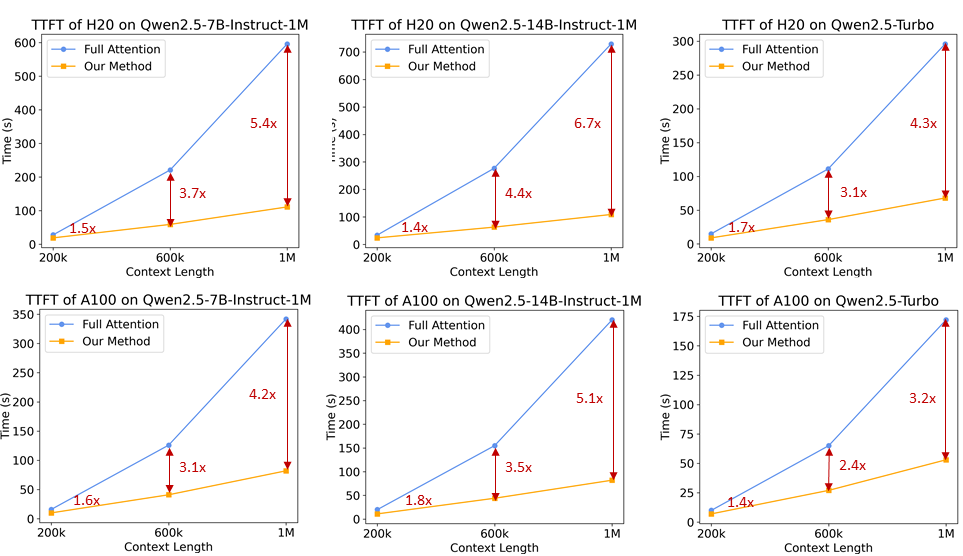
이러한 개선 사항을 통해 추론 프레임워크는 1M 토큰 길이 서열의 사전 채우기 속도가 3.2배에서 6.7배로 증가했습니다.
4. 모델 배포
시스템 준비
최상의 성능을 위해 최적화된 코어를 지원하는 암페어 또는 호퍼 아키텍처의 GPU를 사용하는 것이 좋습니다.
다음 요구 사항을 충족하는지 확인하세요:
- CUDA 버전: 12.1 또는 12.3
- Python 버전: >=3.9 및 <=3.12
메모리 요구 사항, 1M 길이 시퀀스 처리를 위한 메모리 요구 사항:
- Qwen2.5-7B-Instruct-1M: 최소 120GB의 비디오 메모리(멀티 GPU 합계)가 필요합니다.
- Qwen2.5-14B-Instruct-1M: 최소 320GB의 비디오 메모리(멀티 GPU 합계)가 필요합니다.
GPU 메모리가 이러한 요구 사항을 충족하지 않는 경우에도 짧은 작업에는 Qwen2.5-1M을 사용할 수 있습니다.
종속성 설치
당분간은 사용자 지정 브랜치에서 vLLM 리포지토리를 복제하여 수동으로 설치해야 합니다. 연구팀은 해당 브랜치를 vLLM 프로젝트에 커밋하는 작업을 진행 중입니다.
git clone -b dev/dual-chunk-attn git@github.com:QwenLM/vllm.git cd vllm pip install -e . -v
OpenAI 호환 API 서비스 시작
ModelScope에서 모델을 다운로드하도록 지정합니다.
export VLLM_USE_MODELSCOPE=True
OpenAI 호환 API 서비스 출시
vllm serve Qwen/Qwen2.5-7B-Instruct-1M \ --tensor-parallel-size 4 \ --max-model-len 1010000 \ --enable-chunked-prefill --max-num-batched-tokens 131072 \ --enforce-eager \ --max-num-seqs 1
매개변수 설명:
--tensor-parallel-size- 설정은 사용하는 GPU 수입니다. 7B 모델은 최대 4개의 GPU를, 14B 모델은 최대 8개의 GPU를 지원합니다.
--max-model-len- 최대 입력 시퀀스 길이를 정의합니다. 메모리 부족 문제가 발생하면 이 값을 줄이세요.
--max-num-batched-tokens- 청크 미리 채우기의 블록 크기를 설정합니다. 값이 작을수록 활성화 메모리 사용량이 줄어들지만 추론 속도가 느려질 수 있습니다.
- 최적의 성능을 위해 권장되는 값은 131072입니다.
--max-num-seqs- 동시에 처리되는 시퀀스 수를 제한합니다.
모델과 상호 작용하기
배포된 모델과 상호 작용하는 데 사용할 수 있는 방법은 다음과 같습니다:
옵션 1.
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen/Qwen2.5-7B-Instruct-1M",
"messages": [
{
"role": "user",
"content": "Tell me something about large language models."
}
],
"temperature": 0.7,
"top_p": 0.8,
"repetition_penalty": 1.05,
"max_tokens": 512
}'
옵션 2. 파이썬 사용
from openai import OpenAI
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
prompt = (
"""There is an important info hidden inside a lot of irrelevant text.
Find it and memorize them. I will quiz you about the important information there.\n\n
The pass key is 28884. Remember it. 28884 is the pass key.\n"""
+ "The grass is green. The sky is blue. The sun is yellow. Here we go. There and back again. " * 800
+ "\nWhat is the pass key?"
)
# The prompt is 20k long. You can try a longer prompt by replacing 800 with 40000.
chat_response = client.chat.completions.create(
model="Qwen/Qwen2.5-7B-Instruct-1M",
messages=[
{"role": "user", "content": prompt},
],
temperature=0.7,
top_p=0.8,
max_tokens=512,
extra_body={
"repetition_penalty": 1.05,
},
)
print("Chat response:", chat_response)
모델이 PDF 파일 등을 읽을 수 있도록 Qwen-Agent와 같은 다른 프레임워크를 살펴볼 수도 있습니다.
5. Magic Hitch API-Inference를 사용하여 직접 호출합니다.
Magic Match 플랫폼의 API-Inference는 처음으로 Qwen2.5-7B-Instruct-1M 및 Qwen2.5-14B-Instruct-1M 모델도 지원합니다. Magic Hitch 사용자는 API 호출을 통해 해당 모델을 직접 사용할 수 있습니다. 구체적인 API 추론 사용법은 모델 페이지(예: https://modelscope.cn/models/Qwen/Qwen2.5-14B-Instruct-1M )에 설명되어 있습니다:

또는 API-추론 설명서를 참조하세요: https://www.modelscope.cn/docs/model-service/API-Inference/intro
백그라운드에서 산술 지원을 제공해준 AliCloud Hundred Refinement Platform에 감사드립니다.
올라마 및 라마파일 사용
현지에서 쉽게 사용할 수 있도록 Magic Hitch는 처음에 Qwen2.5-7B-Instruct-1M 모델의 GGUF 버전과 llamafile 버전을 제공합니다. Ollama 프레임워크로 호출하거나 llamafile을 직접 풀업하여 사용할 수 있습니다.
1. 올라마 통화
먼저 사용 설정에서 올라마를 설정합니다:
ollama serve
그런 다음 ollama run 명령을 사용하여 매직 히치에서 GGUF 모델을 직접 실행할 수 있습니다:
ollama run modelscope.cn/modelscope/Qwen2.5-7B-Instruct-1M-GGUF실행 결과:
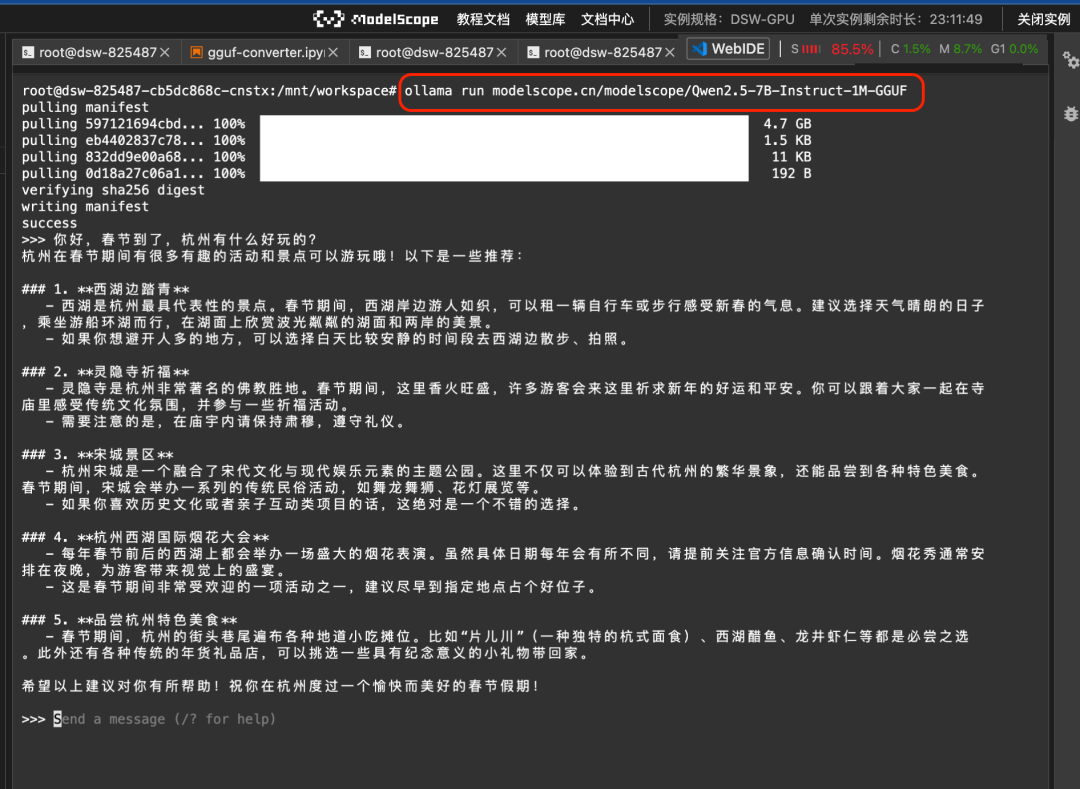
2. 라마파일 모델 직접 풀업
라마파일 빅 모델과 런타임 환경이 모두 하나의 실행 파일에 캡슐화되어 있는 솔루션을 제공합니다. Magic Ride 명령줄과 llamafile의 통합을 통해 Linux/Mac/Windows 등 다양한 운영체제 환경에서 클릭 한 번으로 빅 모델을 실행할 수 있습니다:
modelscope llamafile --model Qwen-Llamafile/Qwen2.5-7B-Instruct-1M-llamafile실행 결과:
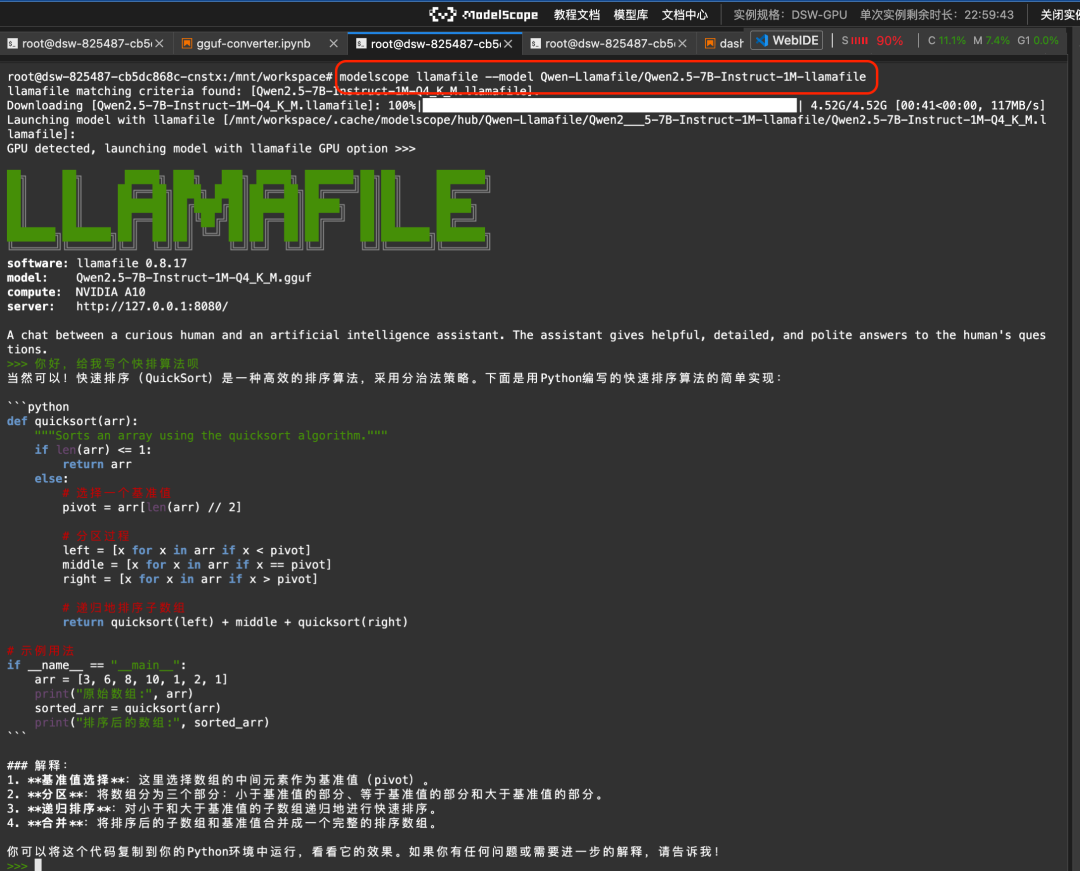
자세한 문서는 https://www.modelscope.cn/docs/models/advanced-usage/llamafile 에서 확인할 수 있습니다.
6. 모델 미세 조정
여기서는 ms-swift를 사용하여 Qwen/Qwen2.5-7B-Instruct-1M을 미세 조정하는 방법을 소개합니다.
미세 조정을 시작하기 전에 환경이 제대로 설치되어 있는지 확인하세요:
# 安装ms-swift git clone https://github.com/modelscope/ms-swift.git cd ms-swift pip install -e .
사용자 지정 데이터 세트에 대해 실행 가능한 미세 조정 데모와 스타일을 제공하며, 미세 조정 스크립트는 다음과 같습니다:
쿠다_보이는_장치=0
swift sft \
--model Qwen/Qwen2.5-7B-Instruct-1M \
--train_type lora \
--dataset 'AI-ModelScope/alpaca-gpt4-data-zh#500' \
'AI-ModelScope/alpaca-gpt4-data-en#500' \
'swift/self-cognition#500' \
--torch_dtype bfloat16 \
--num_train_epochs 1 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--learning_rate 1e-4 \
--lora_rank 8 \
--lora_alpha 32 \
--target_modules all-linear \
--gradient_accumulation_steps 16 \
--eval_steps 50 \
--save_steps 50 \
--save_total_limit 5 \
--logging_steps 5 \
--max_length 2048 \
--output_dir output \
--warmup_ratio 0.05 \
--dataloader_num_workers 4 \
--model_author swift \
--model_name swift-robot
비디오 메모리 사용량 교육:

사용자 정의 데이터 세트 형식: (`--데이터 세트 `를 사용하여 직접 지정하면 됩니다.)
{"messages": [{"role": "user", "content": "<query>"}, {"role": "assistant", "content": "<response>"}, {"role": "user", "content": "<query2>"}, {"role": "assistant", "content": "<response2>"}]}
추론 스크립트:
CUDA_VISIBLE_DEVICES=0 \
swift infer \
--adapters output/vx-xxx/checkpoint-xxx \
--stream true \
--max_new_tokens 2048
모델을 ModelScope로 푸시합니다:
CUDA_VISIBLE_DEVICES=0 swift export \
--adapters output/vx-xxx/checkpoint-xxx \
--push_to_hub true \
--hub_model_id '' \
--hub_token ''
7. 다음 단계는 무엇인가요?
Qwen2.5-1M 제품군은 긴 시퀀스 처리 작업을 위한 훌륭한 오픈 소스 옵션을 제공하지만, 연구팀은 긴 컨텍스트 모델에는 여전히 개선의 여지가 많다는 것을 잘 알고 있습니다. 우리의 목표는 짧은 작업과 긴 작업 모두에서 뛰어난 모델을 구축하여 실제 애플리케이션 시나리오에서 진정으로 유용하게 사용할 수 있도록 하는 것입니다. 이를 위해 팀은 리소스가 제한된 환경에서도 이러한 모델을 최적의 성능으로 효율적으로 배포할 수 있도록 보다 효율적인 학습 방법, 모델 아키텍처 및 추론 접근 방식을 연구하고 있습니다. 이러한 노력이 롱컨텍스트 모델의 새로운 가능성을 열어 적용 범위를 획기적으로 확장하고 이 분야의 경계를 계속 넓혀갈 것이라고 확신하며, 앞으로도 계속 지켜봐 주세요!
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서




댓글 없음...