
Qwen-AgentWorld是什么
Qwen-AgentWorld 是阿里巴巴通义实验室发布的首个原生语言世界模型(Language World Model, LWM)。与传统"提示进、动作出"的反应式智能体不同,核心逻辑是先预测环境会发生什么,再选择下一步动作。基于超过 1000 万条真实环境交互轨迹,通过 CPT→SFT→RL 三阶段端到端训练,单一模型同时覆盖 Terminal、Search、MCP、SWE、Web、OS、Android 七大领域。在同步推出的 AgentWorldBench 评测中,397B 版本以 58.71 的综合得分超越 GPT-5.4、Claude Opus 4.8 等前沿模型,且模型与评测基准均已开源。
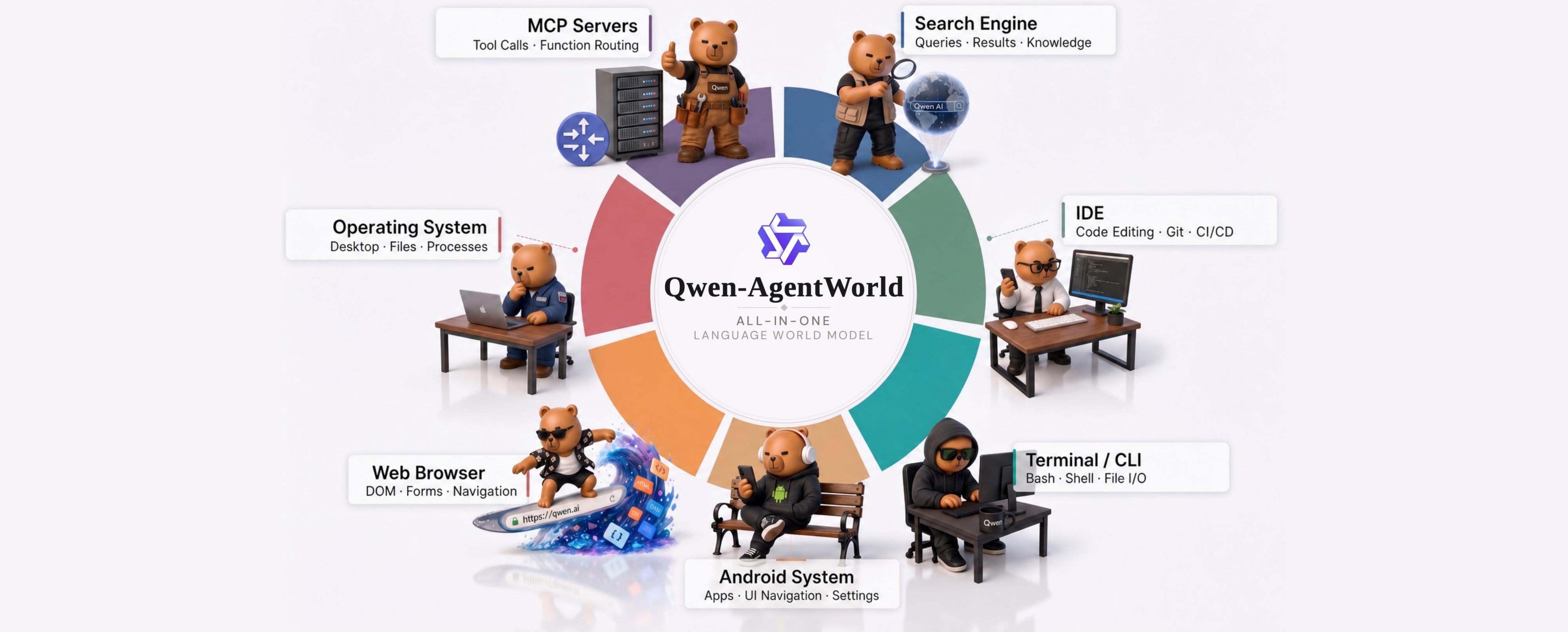
Qwen-AgentWorld的功能特色
- 原生世界建模:环境建模从继续预训练(CPT)阶段起即为训练目标,贯穿 CPT→SFT→RL 全流程,而非对通用大语言模型的事后适配
- 七大领域统一覆盖:单一模型同时覆盖文本类(MCP、Search、Terminal、SWE)与 GUI 类(Web、OS、Android)环境,实现跨领域知识迁移
- 轮次级信息论损失掩码:CPT 阶段通过 4 个表层统计量识别真正承载环境信息的对话轮,对其余轮施加掩码,精准注入环境知识
- 显式思维链推理:SFT 阶段通过拒绝采样筛选 7,094 条高质量思维链轨迹,将"下一状态预测"激活为显式推理模式
- 混合奖励强化学习:RL 阶段结合基于评分准则的 LLM 评判器与基于规则的验证器,提升模拟保真度
- 可控环境模拟:支持通过自然语言指令精确调控模拟器行为,可注入定向扰动(间歇性错误、分页响应、部分失败等)
Qwen-AgentWorld的核心优势
- 评测领先:AgentWorldBench 五维评测(Format、Factuality、Consistency、Realism、Quality)中,397B 版本综合得分 58.71,超越 GPT-5.4(58.25)、Claude Opus 4.8(56.59)、Gemini 3.1 Pro(54.57)
- 小模型大幅跃升:35B-A3B 经三阶段训练后整体均分提升 +8.66(47.73→56.39),超过 Claude Sonnet 4.6(56.04)
- 零样本环境泛化:成功模拟训练数据中完全不存在的 4,000 个 OpenClaw 环境,Claw-Eval 和 QwenClawBench 分别获得 +4.3 和 +7.1 的 Sim RL 增益
- 超越真实环境 RL:WideSearch 任务中可控 Sim RL 达到 50.3% F1,优于真实搜索引擎训练的 Real RL(45.6%)
- 跨领域涌现能力:LWM 预热训练可迁移至 7 个智能体基准(其中 3 个完全未出现在训练集中),Claw-Eval +11.3、BFCL v4 +9.0,无需额外 RL 微调
- 虚构世界安全训练:构建 1,000 个自包含虚构环境,防止智能体将模拟事实与真实世界知识混淆
Qwen-AgentWorld官网是什么
- GitHub 리포지토리:https://github.com/QwenLM/Qwen-AgentWorld
- 포옹하는 얼굴 모델 라이브러리::https://huggingface.co/collections/Qwen/qwen-agentworld
- 모델 범위:https://modelscope.cn/collections/Qwen/qwen-agentworld
- arXiv 기술 논문:http://arxiv.org/abs/2606.24597
Qwen-AgentWorld的操作步骤
- 克隆官方仓库:从 GitHub 下载 Qwen-AgentWorld 源码及示例代码
- 종속 환경 설치:根据仓库
requirements.txt配置 Python 环境,确保兼容 Transformers、vLLM 或 SGLang 等推理后端 - 모델 가중치 다운로드:从 Hugging Face 或 ModelScope 拉取预训练模型(支持 35B-A3B 和 397B-A17B 两个版本)
- 作为环境模拟器使用(范式一)::
- 将 Qwen-AgentWorld 配置为独立的环境模拟器节点
- 智能体执行动作后,向模拟器发送当前状态与动作,获取预测的下一状态观测
- 通过自然语言系统提示词注入可控扰动(如 API 错误、分页响应、不完整结果),开展 Sim RL 训练
- 作为统一智能体基础模型使用(范式二)::
- 直接加载 Qwen-AgentWorld 作为智能体 backbone,同一模型既负责动作决策又负责状态预测
- 利用内置的"下一状态预测"思维链能力,在多轮交互中先模拟环境响应再执行动作
- 无需额外 RL 微调,即可迁移到 Terminal、SWE、Web、MCP 等下游智能体任务
- 评测与验证:使用开源的 AgentWorldBench 基准对模型模拟质量进行五维评估(Format、Factuality、Consistency、Realism、Quality),验证部署效果
Qwen-AgentWorld的适用人群
- AI Agent 开发者与架构师:需要构建覆盖 Web、OS、Android、Terminal、MCP 等多领域交互能力的通用智能体,或希望将"先预测再行动"的世界建模能力集成到现有 Agent 框架中
- 强化学习(RL)研究人员:需要在低成本、高可控的模拟环境中训练智能体策略,避免真实环境试错带来的高成本和不可逆风险
- 软件工程自动化团队:从事代码生成、自动化测试、DevOps 工具链开发,需要准确模拟 IDE、git diff、编译错误等代码执行状态
- 大模型应用企业基础设施团队:负责搭建内部 Agent 训练沙箱,需要可控的环境模拟器来注入定向扰动(如 API 错误、分页响应),系统性暴露智能体薄弱环节
- 学术与科研机构:从事世界模型(World Model)、Agent 泛化能力、跨领域迁移学习等方向研究,可直接使用开源的 AgentWorldBench 进行系统性评测
Qwen-AgentWorld的常见问题
Q:它与传统大语言模型(LLM)有什么区别?
A:传统 LLM 主要训练目标是"下一 토큰 预测",而 Qwen-AgentWorld 从继续预训练(CPT)阶段起就将环境建模作为核心训练目标。它维护一个内部状态估计,能在多轮任务中保持上下文连贯,减少反复澄清的成本。
Q:支持哪些交互环境?
A:单一模型统一覆盖七大领域::
- 文本类:MCP(工具调用)、Search(搜索)、Terminal(终端)、SWE(软件工程)
- GUI 类:Web(网页)、OS(操作系统)、Android(安卓)
Q:什么是"两种应用范式"?
A:官方验证了世界建模增强智能体的两条互补路径:
- 范式一(解耦):Qwen-AgentWorld 作为独立的环境模拟器,替代真实环境进行 Sim RL 训练
- 范式二(统一):同一模型既预测环境状态又选择动作,LWM 预热训练可零样本迁移到多个智能体任务
Q:什么是"可控模拟"?为什么重要?
A:可控模拟指通过自然语言系统提示词精确调控模拟器行为,可注入定向扰动(如间歇性 API 错误、分页响应、不完整结果)。实验表明:不含控制指令的 Sim RL 几乎无提升,而可控扰动可将 MCPMark 提升 +12.3、WideSearch 提升 +16.3。可控性是 Sim RL 奏效的先决条件。
Q:Sim RL 真的比真实环境 RL 更好吗?
A:在 WideSearch 任务上,可控 Sim RL 达到 50.3% F1,确实超越了使用真实搜索引擎训练的 Real RL(45.6%)。此外,Sim RL 能以真实环境无法实现的方式定向塑造智能体行为(如增加
web_extractor 调用次数)。© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서

댓글 없음...