
DeepSeek 실습: 단일 추출, 다중 부분 융합, 토픽 생성의 세 단계로 지식 그래프 구축하기

질문: 지식 그래프가 중요하고 딥서치 언어 모델이 핫한데, 지식 그래프를 빠르게 구축하는 데 사용할 수 있나요? 해보고 싶어요. DeepSeek 를 사용하여 정보를 추출하고, 지식을 통합하고, 무에서 유를 창조하는 데 얼마나 잘 작동하는지 확인해 보세요.
방법: 저는 DeepSeek의 지식 그래프 구축 기능을 테스트하기 위해 세 가지 실험을 해보았습니다:
- 단일 문서 빌드 매핑: DeepSeek에 기사를 제공하고 정보를 정확하게 파악하고 그래프를 작성할 수 있는지 확인하세요.
- 여러 문서 퓨전 매핑: 딥서치에게 여러 개의 기사를 제공하여 기존 그래프에 새로운 지식을 추가할 수 있는지 확인합니다.
- 테마 생성 매핑: 딥서치에게 기사가 아닌 아틀라스의 주제를 알려주고 스스로 아틀라스를 만들어낼 수 있는지 확인해 보세요.
결과: 실험을 통해 DeepSeek가 지식 그래프를 잘 구축하고 융합한다는 것이 입증되었지만 여전히 개선의 여지가 있습니다.
실험의 정확한 과정과 결과는 다음과 같으며, 좀 더 쉽게 설명해 드리겠습니다.
I. 단일 문서에서 지식을 추출하여 지도 만들기
목적: 기사에서 지식을 추출하고 지식 그래프를 구축하는 DeepSeek의 기능을 테스트합니다.
프로세스: 저는 네뷸라그래프 그래프 데이터베이스에 관한 기사를 찾아서 DeepSeek에게 그 기사를 읽고 핵심 정보를 추출한 다음 네뷸라그래프 데이터베이스 코드(nGQL)를 생성하여 지식 그래프를 만들도록 했습니다.
지침: "지식 그래프를 생성하는 데 도움을 줄 수 있나요? 제가 문서를 드리면 핵심 정보를 추출하고 nGQL 코드로 지식 그래프를 구축해 주세요."
운영: 기사 콘텐츠를 복사하여 DeepSeek에 직접 붙여넣습니다.
DeepSeek가 생성한 nGQL 코드:
# Schema 定义(TAG 类型)
CREATE TAG IF NOT EXISTS product (
name STRING,
description STRING
);
CREATE TAG IF NOT EXISTS company (
name STRING
);
CREATE TAG IF NOT EXISTS feature (
name STRING
);
CREATE TAG IF NOT EXISTS tool (
name STRING
);
CREATE TAG IF NOT EXISTS scenario (
name STRING
);
CREATE TAG IF NOT EXISTS language (
name STRING
);
CREATE TAG IF NOT EXISTS auth_service (
name STRING
);
CREATE TAG IF NOT EXISTS ecosystem (
name STRING
);
# Schema 定义(EDGE 类型)
CREATE EDGE IF NOT EXISTS has_feature ();
CREATE EDGE IF NOT EXISTS used_by ();
CREATE EDGE IF NOT EXISTS provides_tool ();
CREATE EDGE IF NOT EXISTS supports_language ();
CREATE EDGE IF NOT EXISTS applicable_scenario ();
CREATE EDGE IF NOT EXISTS compatible_with ();
CREATE EDGE IF NOT EXISTS supports_auth ();
CREATE EDGE IF NOT EXISTS integrates_with ();
# 数据插入 - 核心产品
INSERT VERTEX product(name, description) VALUES
"NebulaGraph": ("NebulaGraph", "开源的分布式图数据库,支持千亿点万亿边数据集");
# 数据插入 - 产品特性
INSERT VERTEX feature(name) VALUES
"high_performance": ("高性能"),
"open_source": ("开源"),
"scalability": ("易扩展"),
"flexible_modeling": ("灵活数据建模"),
"read_write_balance": ("读写平衡"),
"compatibility": ("查询语言兼容性");
/* ... 此处省略 n多数据 ... */
결과: DeepSeek 코드는 구문도 정확하고 여러 데이터를 하나의 문으로 결합한다는 점에서 효율적입니다. 코드를 네뷸라그래프에 넣어 실행하면 다음과 같은 플롯이 나타납니다:
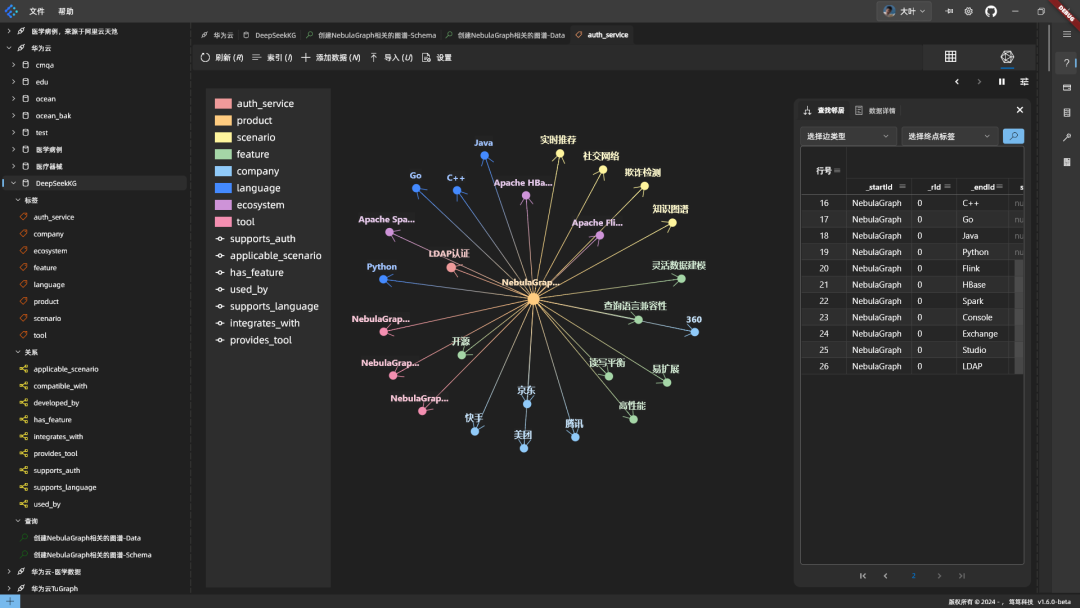
그래프는 네뷸라그래프를 중심으로 관련 정보를 표시합니다.
II. 여러 문서에 걸친 지식 통합
목적: 여러 기사의 지식을 융합하여 기존 그래프를 확장하는 DeepSeek의 기능을 테스트합니다.
프로세스: 먼저 하나의 기사로 그래프를 만든 다음, 딥시크에 (바이두의 백과사전에 있는) 네뷸라그래프에 대한 기사를 더 제공하여 새로운 지식을 기존 그래프에 병합합니다.
지침: "다음은 다른 글입니다. 매핑을 현재 테이블 구조와 혼합해 보세요. 테이블 구조를 변경하려면 ALTER 명령을 사용하세요."
운영: 네뷸라그래프와 360 백과사전 항목의 초록은 각각 딥시크릿에 제공되었습니다.
DeepSeek에서 생성한 nGQL 코드(네뷸라그래프 어휘집):
# 结构变更 1:为 product 标签增加版本和时间属性
ALTER TAG product ADD (
license STRING,
current_version STRING,
release_date STRING,
last_updated STRING
);
# 结构变更 2:新增开发关系类型
CREATE EDGE IF NOT EXISTS developed_by();
# 数据更新 - 补充产品属性
INSERT VERTEX product(name, description, license, current_version, release_date, last_updated)
VALUES
"NebulaGraph": ("NebulaGraph", "分布式图数据库", "Apache 2.0", "v3.3.0", "2019-05-15", "2022-11-14");
# 新增开发公司(复用 company 标签)
INSERT VERTEX company(name)
VALUES
"Yueshu": ("杭州悦数科技有限公司");
# 新增特性(复用 feature 标签)
INSERT VERTEX feature(name)
VALUES
"acl_mechanism": ("ACL 机制"),
"linear_scaling": ("线性扩容"),
"data_recovery": ("数据恢复"),
"htap": ("HTAP 混合负载"),
"nGQL_language": ("nGQL 查询语言");
# 关系建立(复用已有关系类型)
INSERT EDGE has_feature()
VALUES
"NebulaGraph"->"acl_mechanism":(),
"NebulaGraph"->"linear_scaling":(),
"NebulaGraph"->"data_recovery":(),
"NebulaGraph"->"htap":(),
"NebulaGraph"->"nGQL_language":();
# 新增开发关系
INSERT EDGE developed_by()
VALUES
"NebulaGraph"->"Yueshu":();
DeepSeek가 생성한 nGQL 코드(360단어):
# 结构变更 1:为 company 标签增加创始人、成立时间和收入属性
ALTER TAG company ADD (founder STRING, founded_date STRING, revenue DOUBLE);
# 结构变更 2:新增事件类型 TAG
CREATE TAG IF NOT EXISTS event (
type STRING,
date STRING,
amount DOUBLE,
details STRING
);
# 数据更新:补充 360 公司信息
INSERT VERTEX company(name, founder, founded_date, revenue)
VALUES
"360": ("奇虎360", "周鸿祎", "2005-09", 116.15);
# 数据插入:产品生态(复用 product 标签)
INSERT VERTEX product(name)
VALUES
"360_Security_Guard": ("360安全卫士"),
"360_Browser": ("360安全浏览器"),
"360_Cloud": ("360安全云");
# 数据插入:重大事件(使用新增 event 标签)
INSERT VERTEX event(type, date, amount, details)
VALUES
"acquisition_360.com": ("域名收购", "2015-02-04", 1700.0, "1.1亿人民币收购 360.com"),
"privatization": ("私有化", "2015-12", 9300.0, "93 亿美元私有化交易");
# 关系建立:复用 developed_by 边连接产品
결과: DeepSeek는 새 문서에 따라 테이블 구조를 수정할 수 있습니다(예를 들어 제품 노래로 응답 회사 테이블과 필드) 및 새로운 관계 유형도 추가했습니다. 이 작업은 필요에 따라 ALTER 명령을 사용하여 테이블 구조를 변경할 수 있습니다. 작은 문제는 이 주석이 --nGQL이 인식되지 않으면 수동으로 변경하세요. # 통화 중입니다.
코드가 실행을 위해 데이터베이스에 저장되고 융합 매핑이 작동합니다:
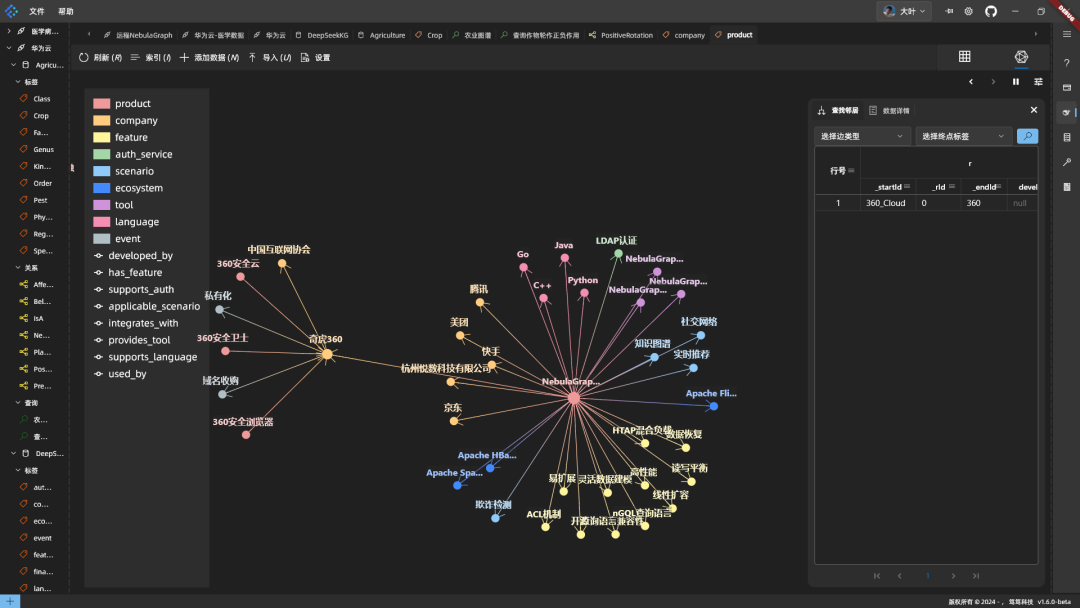
요약: DeepSeek는 그래프를 만들고 지식을 융합하는 데 좋습니다. 하지만 서버가 가끔 느리고 NebulaGraph는 스키마를 비동기적으로 변경하며 적용하는 데 시간이 걸립니다.
III. 테마 생성: 무에서 유를 창조하는 농업 매핑
목적: 기사 없이 토픽을 기반으로 지식 그래프를 생성하는 DeepSeek의 기능을 테스트합니다.
프로세스: 새 대화를 생성하고 "농업"이라는 주제에 대해 DeepSeek가 직접 매핑 코드를 생성하도록 합니다. 어떤 기사도 제공되지 않으며, "자유 주제"입니다.
지침: "농업 지식 그래프를 만들고 싶습니다. 네뷸라그래프 데이터베이스를 사용하고 nGQL 스크립트를 생성합니다. 테이블 이름은 큰 혹, 속성 이름은 작은 혹. 스키마 이름은 충돌을 피하기 위해 ``로 감쌉니다. 최소 3000개의 노드를 생성합니다."
DeepSeek에서 생성한 nGQL 코드(일부):
# ======================================= #
# 创建图空间
# ======================================= #
CREATE SPACE `Agriculture` (vid_type = FIXED_STRING(32));
USE `Agriculture`;
# ======================================= #
# 定义标签 Schema(大驼峰命名)
# ======================================= #
CREATE TAG IF NOT EXISTS `Crop` (
`cropId` int,
`cropName` string,
`growthPeriod` int,
`suitableTemp` string,
`yieldPerMu` float
);
# ======================================= #
# 此处省略好多脚本
# ======================================= #
문제점 및 개선 사항:
- 노드 수 제한: 3000개의 노드로 시작한 DeepSeek는 이를 거부하고 Python이 CSV 코드를 가져오도록 했습니다. 저는 파이썬을 사용하고 싶지 않았기 때문에 노드 수를 줄였습니다.
- 주석에 대한 질문이 다시 나옵니다: 코드 주석은 다시 다음과 같습니다. --이 문제가 다시 지적되었습니다.
개선 지침: "주석에 #를 사용하고, 파이썬 코드는 사용하지 마세요, 노드가 3000개는 너무 많아요. 50개 노드에 대한 ngql 스크립트만 주세요."
후속 대화 및 지침을 따르세요: 지도를 다듬기 위해 계속해서 DeepSeek에 데이터를 추가하고, 연관성을 강화하고, 분류(문, 목, 과, 속, 종)별로 지도를 정리하고, 작물 순환 데이터를 생성해 달라고 요청하면서 대화를 이어갔습니다.
예를 들어, 제 지시 사항입니다:
- "더 강력한 데이터 연계를 위한 보충 데이터."
- "[문, 목, 과, 속, 종의] 이러한 분류에 대한 아틀라스를 만드세요."
- "금기 사항을 파악하고 기존 작물의 로테이션에서 작물을 얻을 수 있습니다."
- "매핑된 작물 조직 데이터를 결합하여 이전 형식의 nGQL 스크립트 제공"
실험적 막간: DeepSeek, 한 번. 삽입 문은 nGQL에서 지원하지 않는 Cypher 구문을 사용하고 있어 지적되어 변경되었습니다.
지침: "이 삽입 문은 nGQL 구문이 아닙니다. DDL이 먼저 오고 DML이 두 번째로 오도록 변경하세요."
최종 데이터 볼륨: 몇 차례의 대화가 끝나면 데이터의 양이 표시됩니다:

매핑 효과: 임의의 노드 몇 개를 펼쳐서 확인합니다:
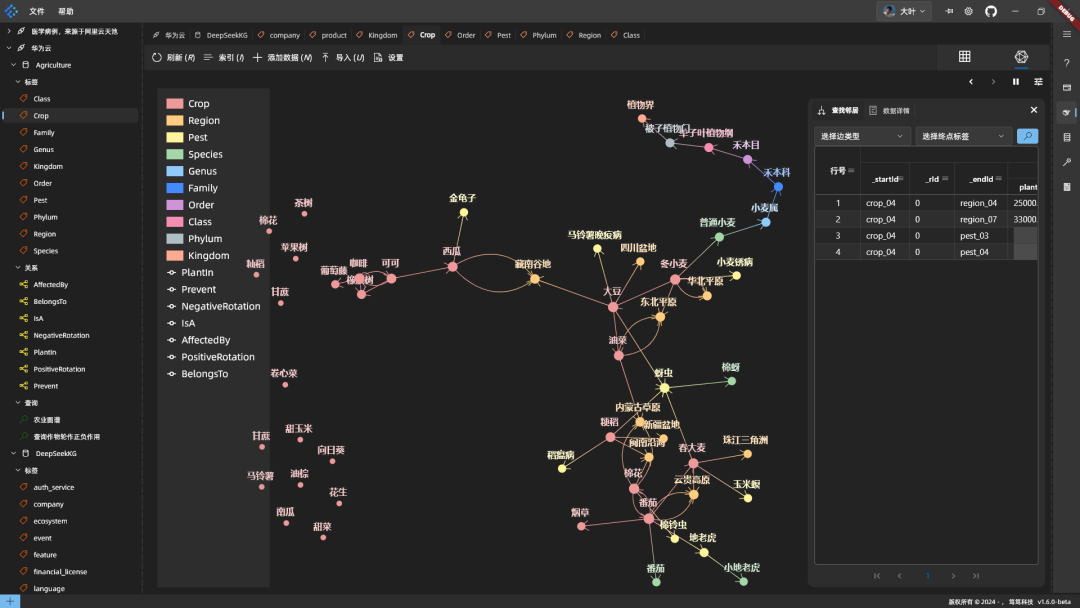
회전 종 수익률 향상 조합의 예입니다: 외래종 재배의 수확량 향상 조합 효과:
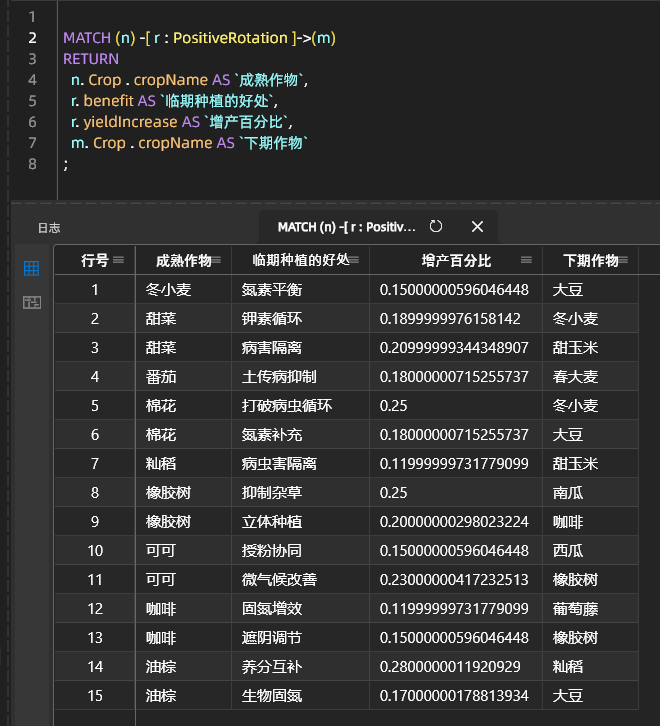
IV. 요약
결론: DeepSeek는 지식 그래프 구성 및 융합에 탁월하며, 실험을 통해 그 기능이 입증되었습니다:
- 정보를 빠르고 정확하게 추출할 수 있습니다: DeepSeek는 텍스트에서 핵심 정보를 빠르게 추출하고, 규정을 준수하는 nGQL 스크립트를 생성하며, 엔티티, 관계 및 이벤트를 인식하는 강력한 언어 이해력을 갖추고 있습니다.
- 지식을 통합하는 강력한 능력: DeepSeek는 여러 기사의 지식을 잘 융합하고, 새로운 기사를 기반으로 그래프를 확장 및 업데이트하며, 그래프의 완전성과 정확성을 보장합니다.
- 무에서 지도를 만들 수 있습니다: 어떤 문서도 주제별로 차트를 생성할 수 없습니다. 생성 과정에서 약간의 구문 문제가 있지만 조정하면 통과 가능한 스크립트가 생성됩니다.
- 세부 사항을 최적화해야 합니다: DeepSeek에서 생성된 스크립트에는 때때로 잘못된 주석과 같은 구문 문제가 있습니다. 많은 수의 노드를 생성할 때 서버의 응답 속도가 느려질 수 있습니다. 실제로 사용할 때 이러한 문제에 주의를 기울여야 합니다.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 게시물



댓글 없음...