
Klear-Reasoner是什么
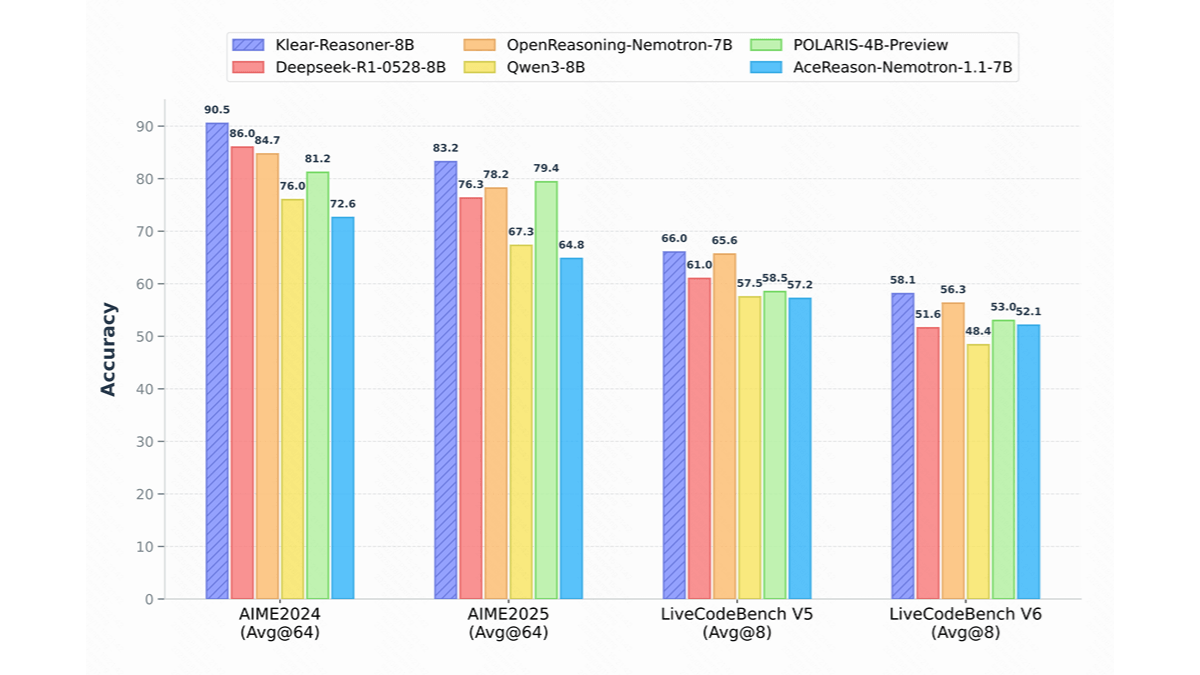
Klear-Reasoner 是快手推出的高性能推理模型,基于 Qwen3-8B-Base 进行开发。模型通过长思维链监督微调和强化学习训练,在数学和代码推理方面表现出色。Klear-Reasoner 的核心创新是 GPPO 算法,基于保留被裁剪的梯度信息,显著提升模型的探索能力和负样本的收敛速度。在 AIME 和 LiveCodeBench 等基准测试中,Klear-Reasoner 展现出卓越的性能,达到 8B 模型的顶尖水平。模型能解决复杂的数学问题,且能生成高质量的代码片段。Klear-Reasoner 广泛应用在教育、软件开发、金融科技等领域,为推理模型的发展提供宝贵的参考和复现路径。
Klear-Reasoner的功能特色
- 数学推理:模型擅长解决复杂的数学问题,为学生提供清晰的解题思路和步骤,帮助用户更好地理解和掌握数学知识。
- 代码生成与推理:能生成高质量的代码片段,辅助开发者快速实现功能模块。
- 长思维链推理:基于长思维链监督微调和强化学习,能提升模型在多步推理中的表现,支持处理复杂的推理任务。
- 数据质量优化:在训练过程中优先选择高质量数据源,同时保留部分错误样本,增强模型的探索能力。
Klear-Reasoner的核心优势
- 高效的训练方法:结合长思维链监督微调和强化学习,充分发挥两者优势,使模型在复杂推理任务上表现出色,为高性能推理奠定基础。
- 创新的GPPO算法:通过stop gradient操作解耦clip与梯度反向传播,保留所有token梯度信息,提升模型探索能力和负样本收敛速度,显著优化训练效率。
- 强大的推理能力:模型在数学和代码推理方面表现出色,能解决高难度数学竞赛题目并生成高质量代码片段,适用教育、软件开发等多领域,应用前景广阔。
- 数据质量与探索能力的平衡:模型优先选择高质量数据源,同时保留部分错误样本增强探索能力。
- 开源与可复现性:Klear-Reasoner的训练细节和全流程公开,且提供开源资源和详细文档,促进学术交流和技术进步。
Klear-Reasoner的官网是什么
- GitHub仓库:https://github.com/suu990901/KlearReasoner/
- HuggingFace模型库:https://huggingface.co/Suu/Klear-Reasoner-8B
- arXiv技术论文:https://arxiv.org/pdf/2508.07629
Klear-Reasoner的适用人群
- 学生:学生能解决数学难题,获取详细的解题步骤,更好地理解和掌握数学知识
- 软件开发者:软件开发者生成高质量的代码片段,快速实现功能模块,提高开发效率和代码质量。
- 金融科技从业者:金融科技从业者分析金融数据,进行风险评估和预测,助力更精准的决策制定。
- 科研人员:科研人员处理复杂的数据分析获得逻辑推理,提升科研效率。
- 智能客服团队:智能客服团队快速准确地解答用户复杂问题,提升用户体验和问题解决效率。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章


暂无评论...