
综合介绍
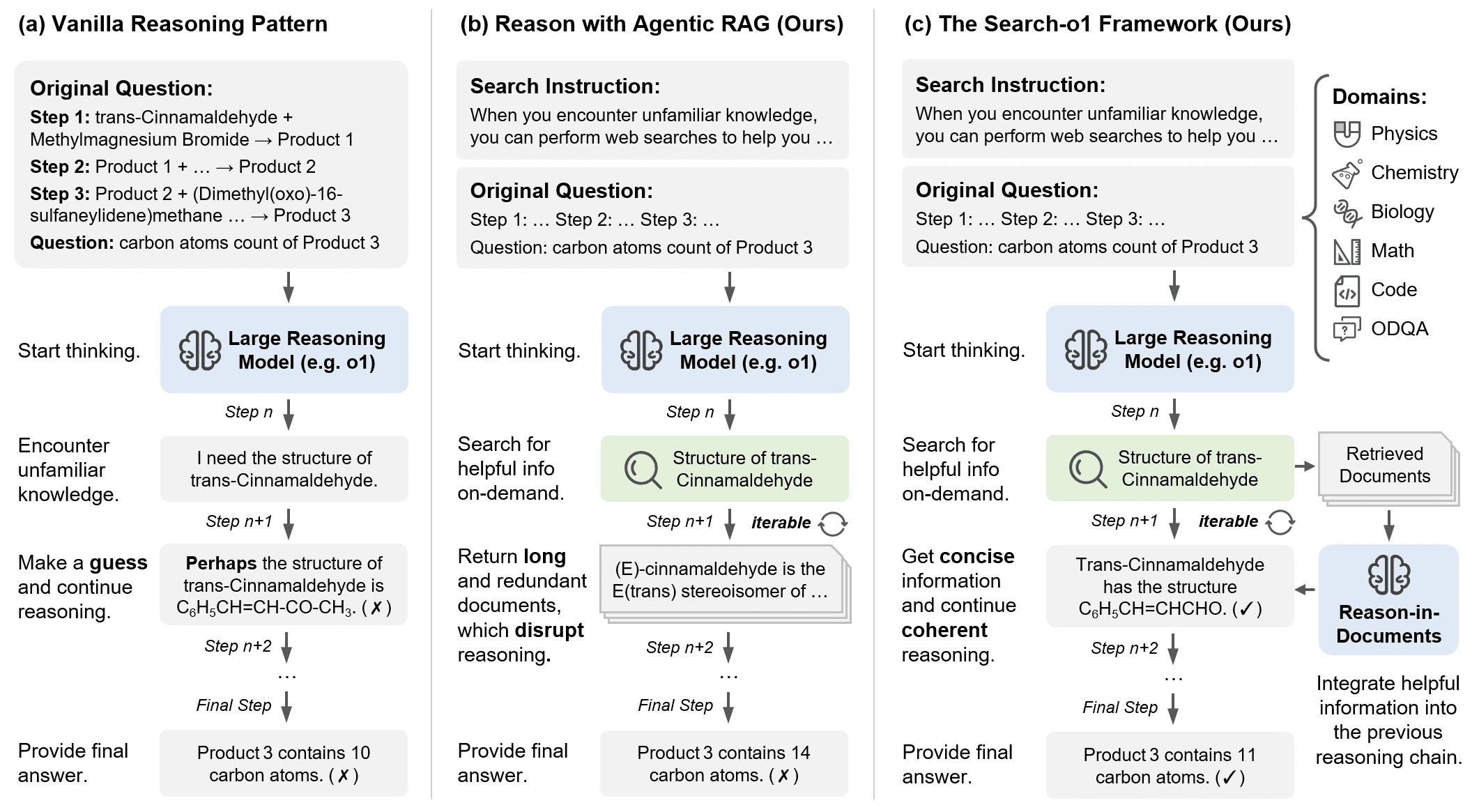
ImBD (Imitate Before Detect) 是一个开创性的机器生成文本检测项目,该项目发表于AAAI 2025会议。随着ChatGPT等大语言模型(LLMs)的广泛应用,识别AI生成的文本内容变得越来越具有挑战性。ImBD项目提出了一种新颖的"先模仿后检测"方法,通过深入理解和模仿机器文本的风格特征来提升检测效果。该方法首次提出对齐机器文本的风格偏好,建立了一个全面的文本检测框架,能够有效识别经过人工修改的机器生成文本。项目采用Apache 2.0开源许可证,提供了完整的代码实现、预训练模型和详细文档,方便研究人员和开发者在此基础上进行进一步的研究和应用开发。

演示地址:https://ai-detector.fenz.ai/ai-detector
功能列表
- 支持对机器生成文本的高精度检测
- 提供预训练模型用于直接部署和使用
- 实现了新型的文本风格特征对齐算法
- 包含详细的实验数据集和评估基准
- 提供完整的训练和推理代码
- 支持自定义训练数据进行模型微调
- 包含详细的API文档和使用示例
- 提供命令行工具便于快速测试和评估
- 支持批量文本处理功能
- 包含可视化工具展示检测结果
使用帮助
1. 环境配置
首先需要配置Python环境并安装必要的依赖:
git clone https://github.com/Jiaqi-Chen-00/ImBD
cd ImBD
pip install -r requirements.txt
2. 数据准备
在开始使用ImBD之前,需要准备好训练和测试数据。数据应包含以下两类:
- 人工编写的原始文本
- 机器生成或经过机器修改的文本
数据格式要求:
- 文本文件需要是UTF-8编码
- 每个样本占一行
- 建议将数据集按8:1:1的比例划分为训练集、验证集和测试集
3. 模型训练
运行以下命令开始训练:
python train.py \
--train_data path/to/train.txt \
--val_data path/to/val.txt \
--model_output_dir path/to/save/model \
--batch_size 32 \
--learning_rate 2e-5 \
--num_epochs 5
4. 模型评估
使用测试集评估模型性能:
python evaluate.py \
--model_path path/to/saved/model \
--test_data path/to/test.txt \
--output_file evaluation_results.txt
5. 文本检测
对单个文本进行检测:
python detect.py \
--model_path path/to/saved/model \
--input_text "要检测的文本内容" \
--output_format json
批量检测文本:
python batch_detect.py \
--model_path path/to/saved/model \
--input_file input.txt \
--output_file results.json
6. 高级功能
6.1 模型微调
如果需要针对特定领域的文本进行优化,可以使用自己的数据集对模型进行微调:
python finetune.py \
--pretrained_model_path path/to/pretrained/model \
--train_data path/to/domain/data \
--output_dir path/to/finetuned/model
6.2 可视化分析
使用内置的可视化工具分析检测结果:
python visualize.py \
--results_file path/to/results.json \
--output_dir path/to/visualizations
6.3 API服务部署
将模型部署为REST API服务:
python serve.py \
--model_path path/to/saved/model \
--host 0.0.0.0 \
--port 8000
7. 注意事项
- 建议使用GPU进行模型训练以提升效率
- 训练数据质量对模型性能有重要影响
- 定期更新模型以适应新的AI生成文本特征
- 在生产环境中部署时注意模型的版本管理
- 建议保存检测结果用于后续分析和模型优化
8. 常见问题解答
Q: 模型支持哪些语言?
A: 目前主要支持英语,其他语言需要使用相应的数据集进行训练。
Q: 如何提高检测准确率?
A: 可以通过增加训练数据、调整模型参数、使用领域特定数据进行微调来提升性能。
Q: 检测速度如何优化?
A: 可以通过批处理、模型量化、使用GPU加速等方式提升检测速度。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章

暂无评论...