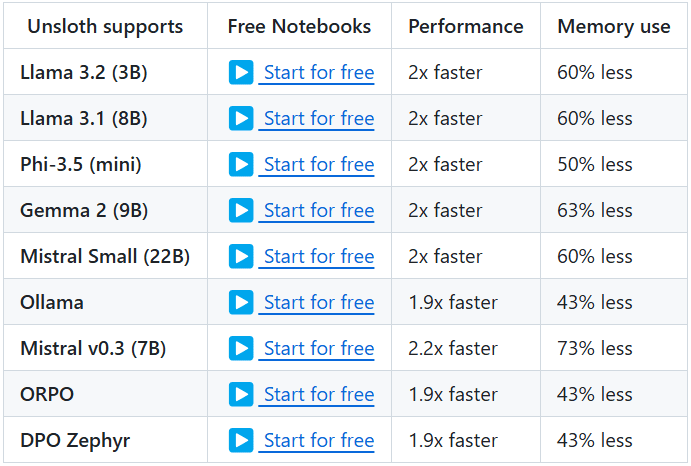
One Shot LoRA : la plateforme tout-en-un pour la génération rapide de modèles vidéo LoRA
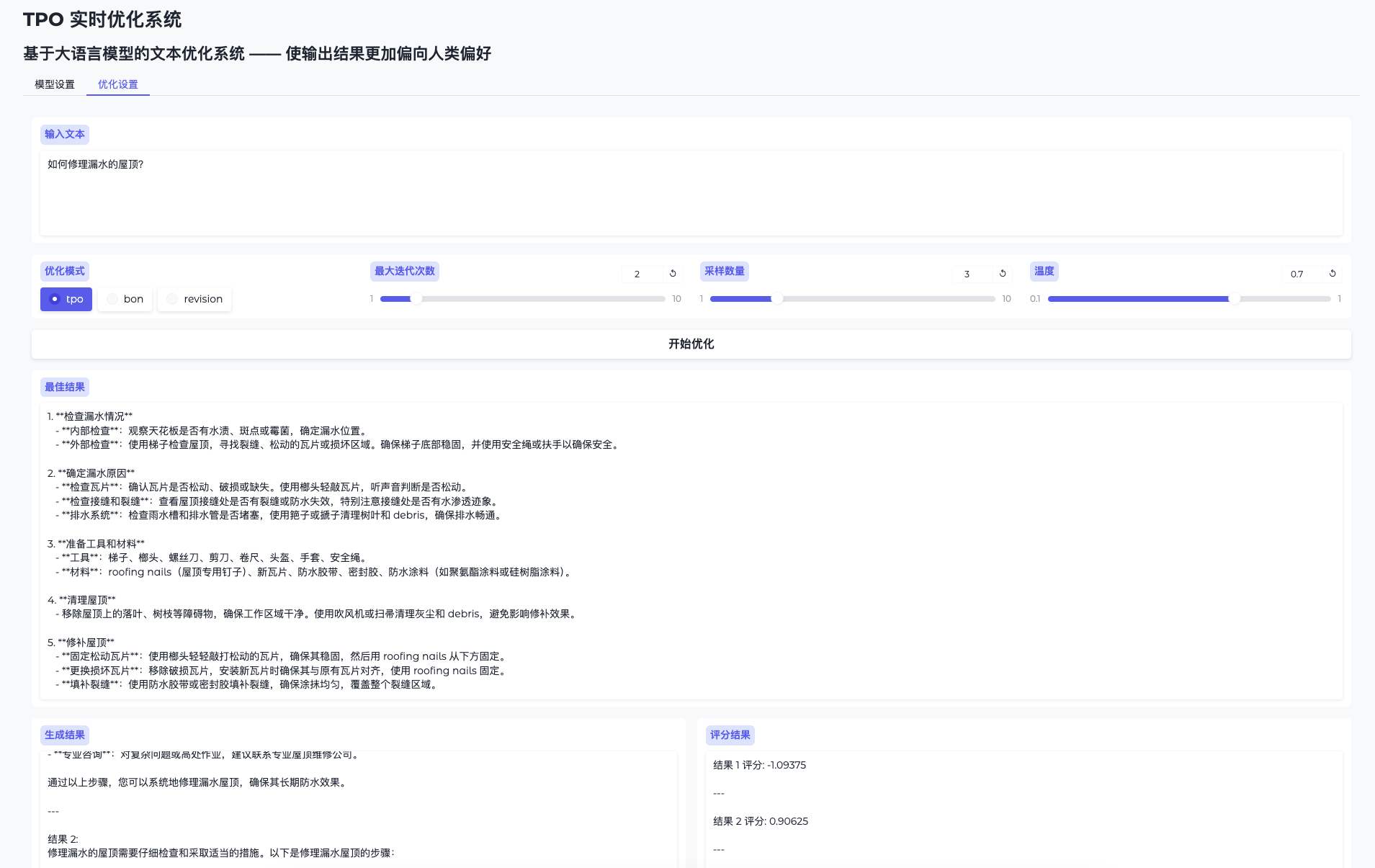
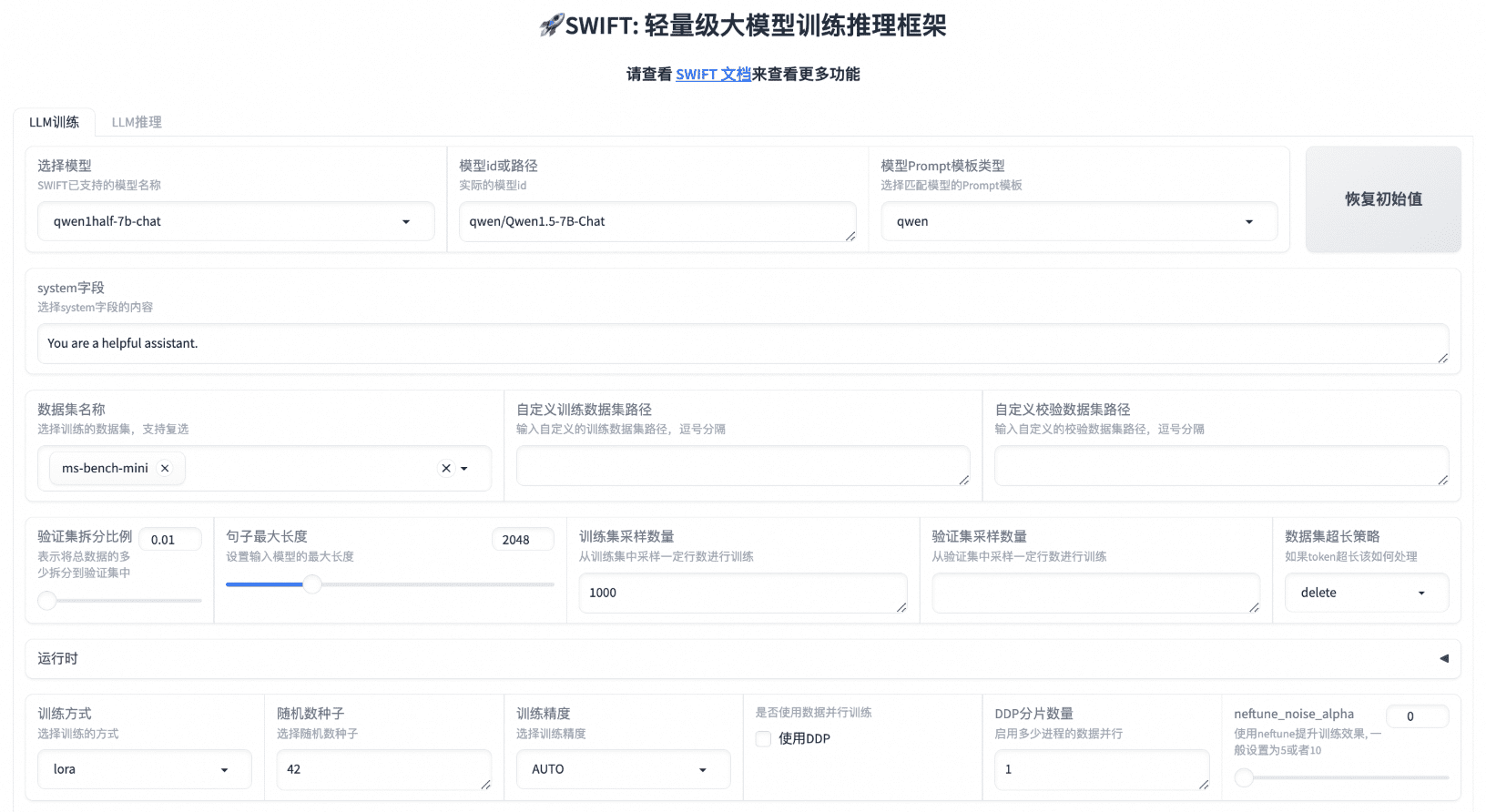
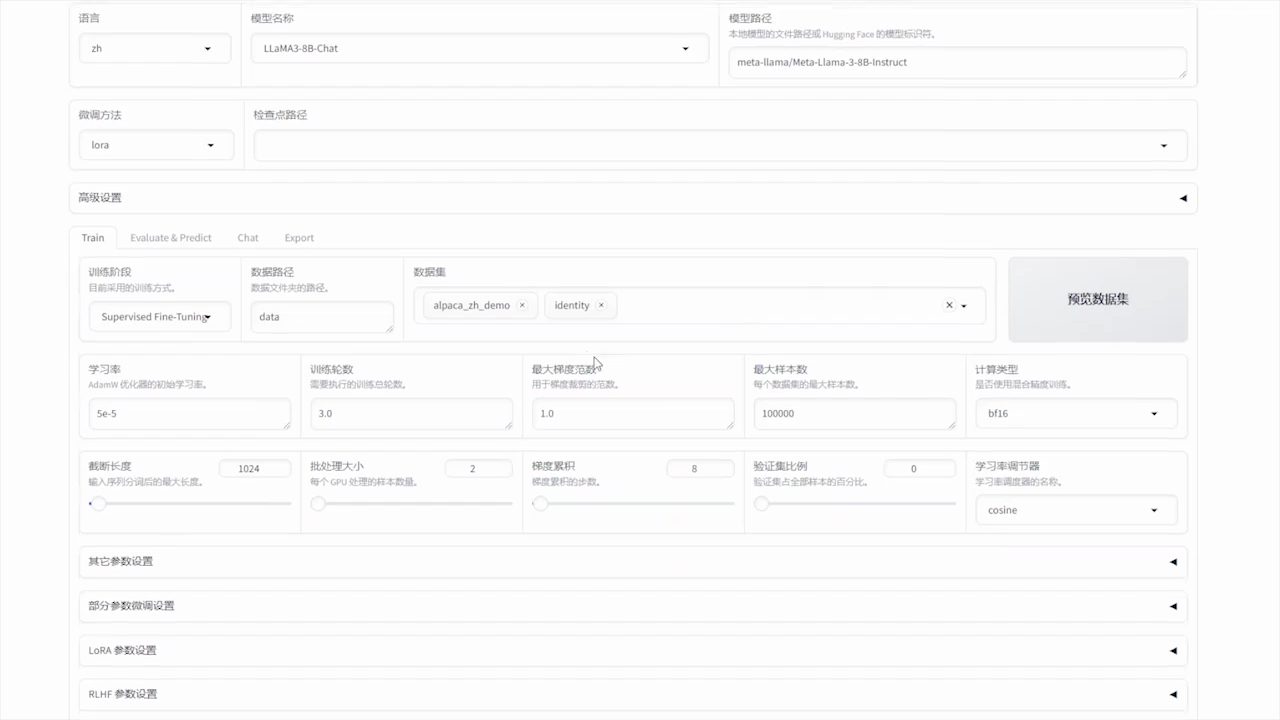
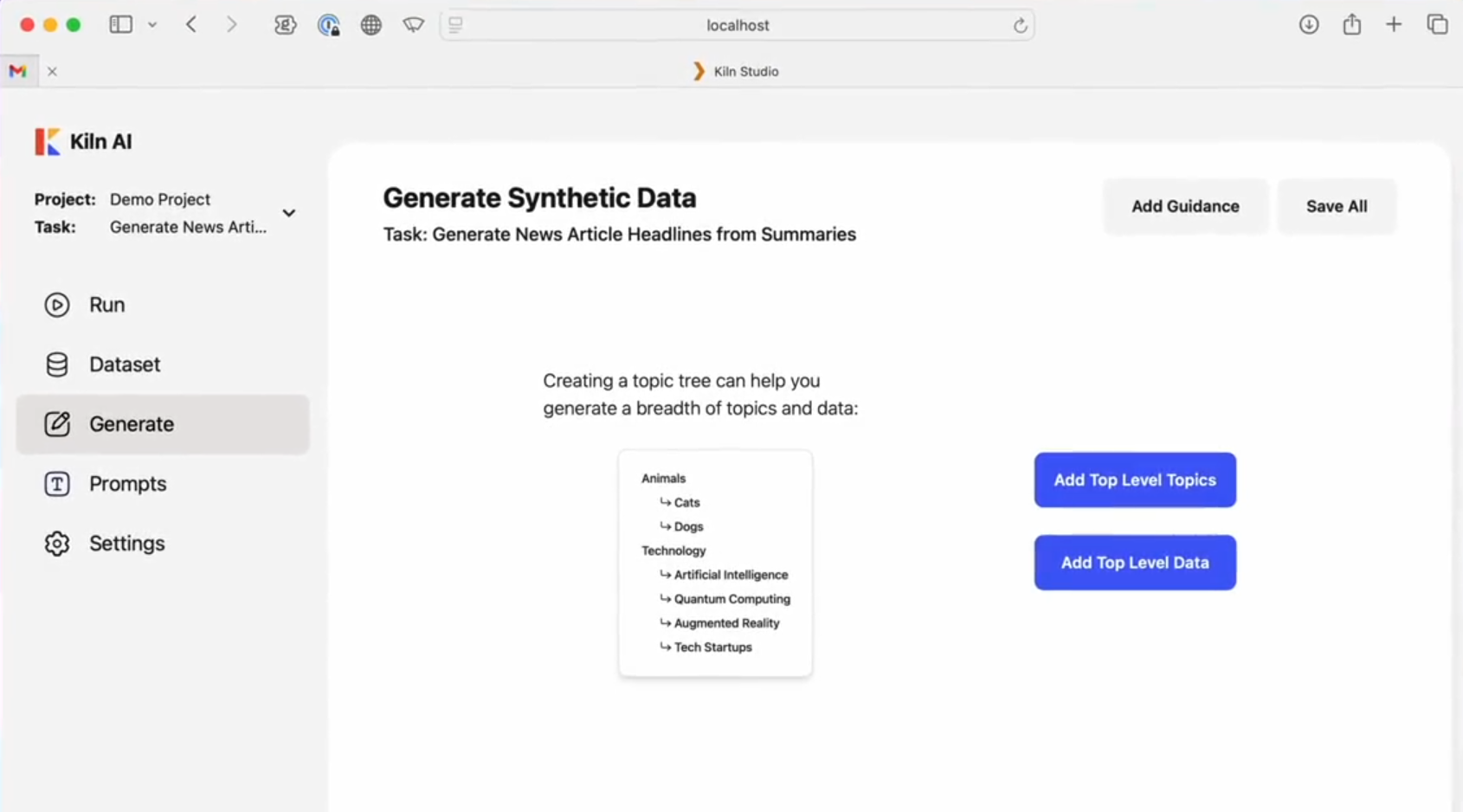
Introduction générale One Shot LoRA est une plateforme destinée à générer des modèles LoRA de haute qualité à partir de vidéos. Les utilisateurs peuvent rapidement et facilement former des modèles LoRA de boutique à partir de vidéos sans avoir à se connecter ou à stocker des données privées. La plateforme prend en charge Hunyua...