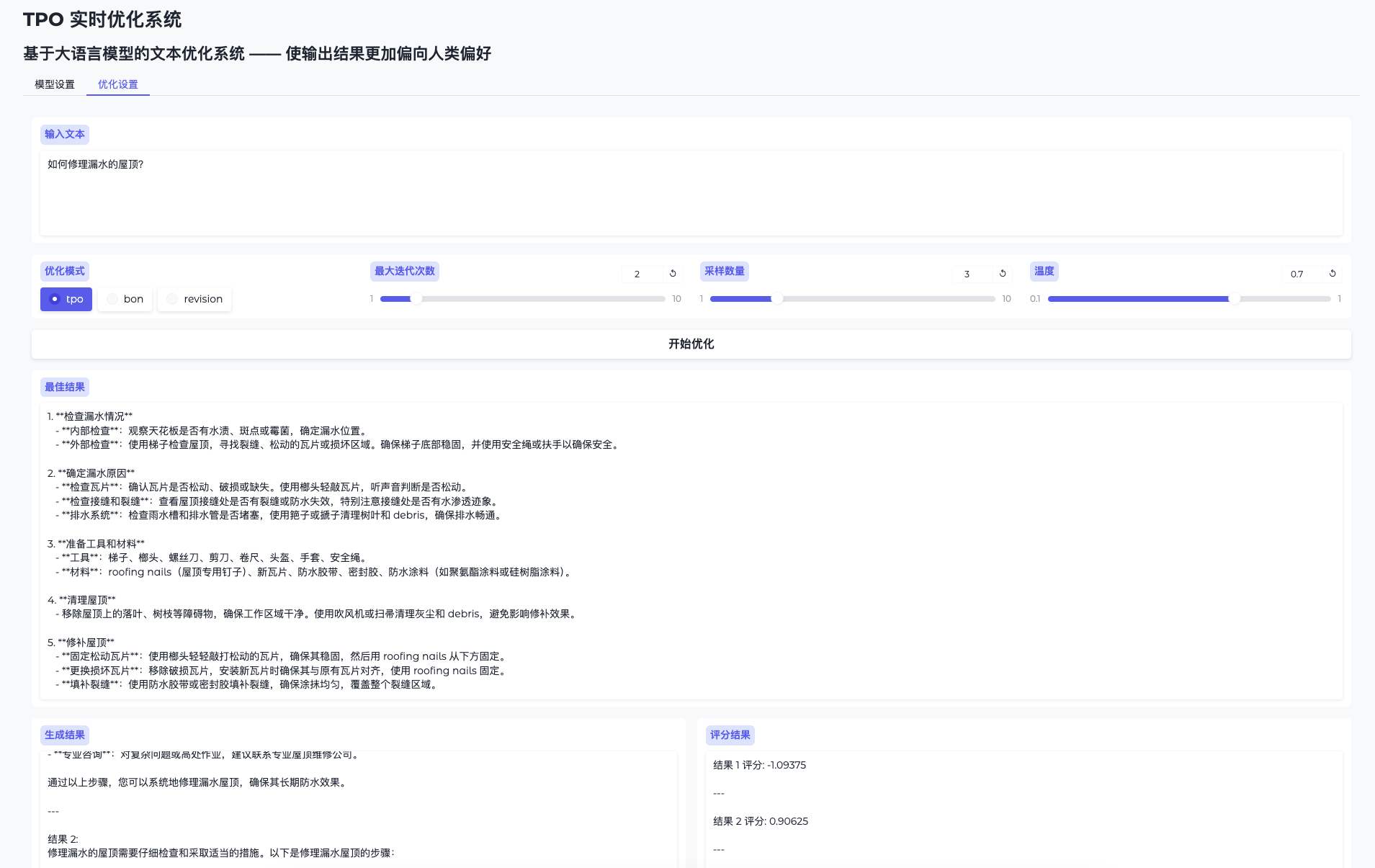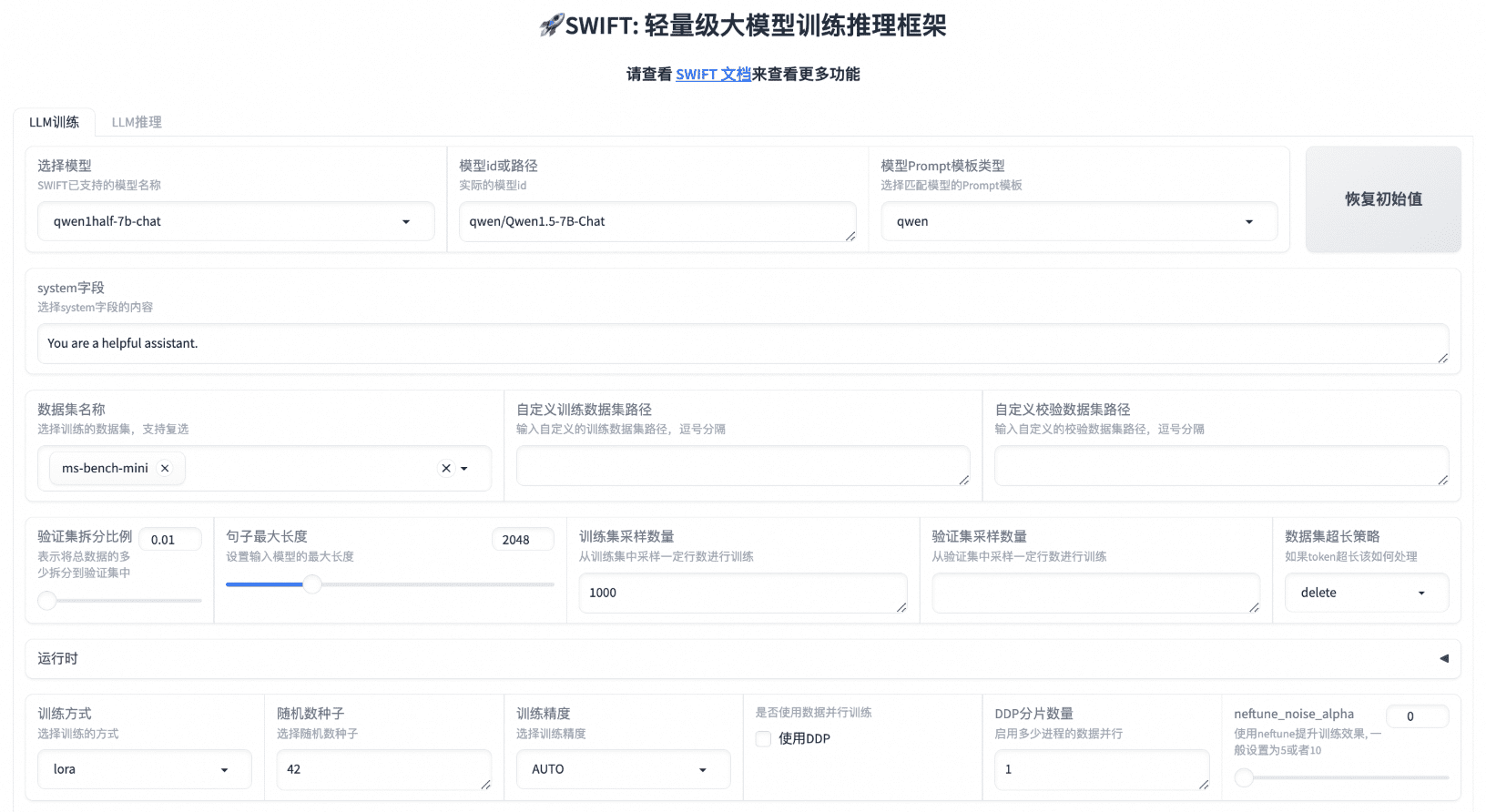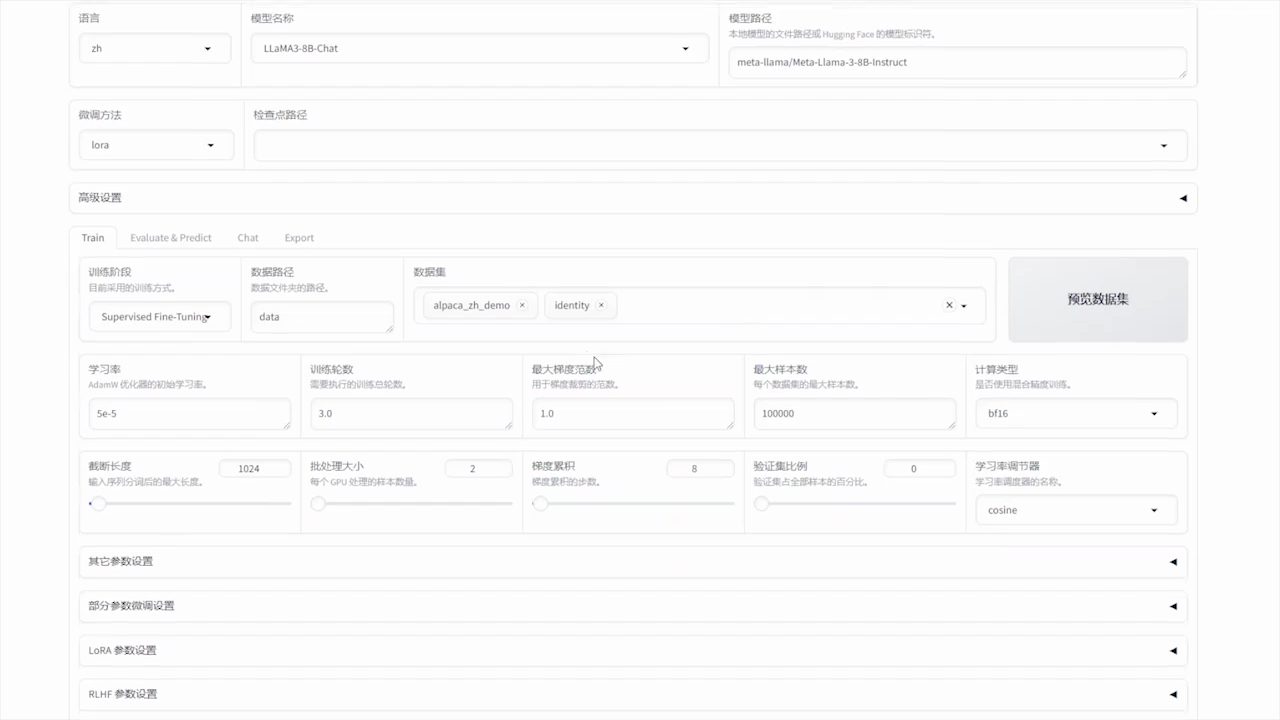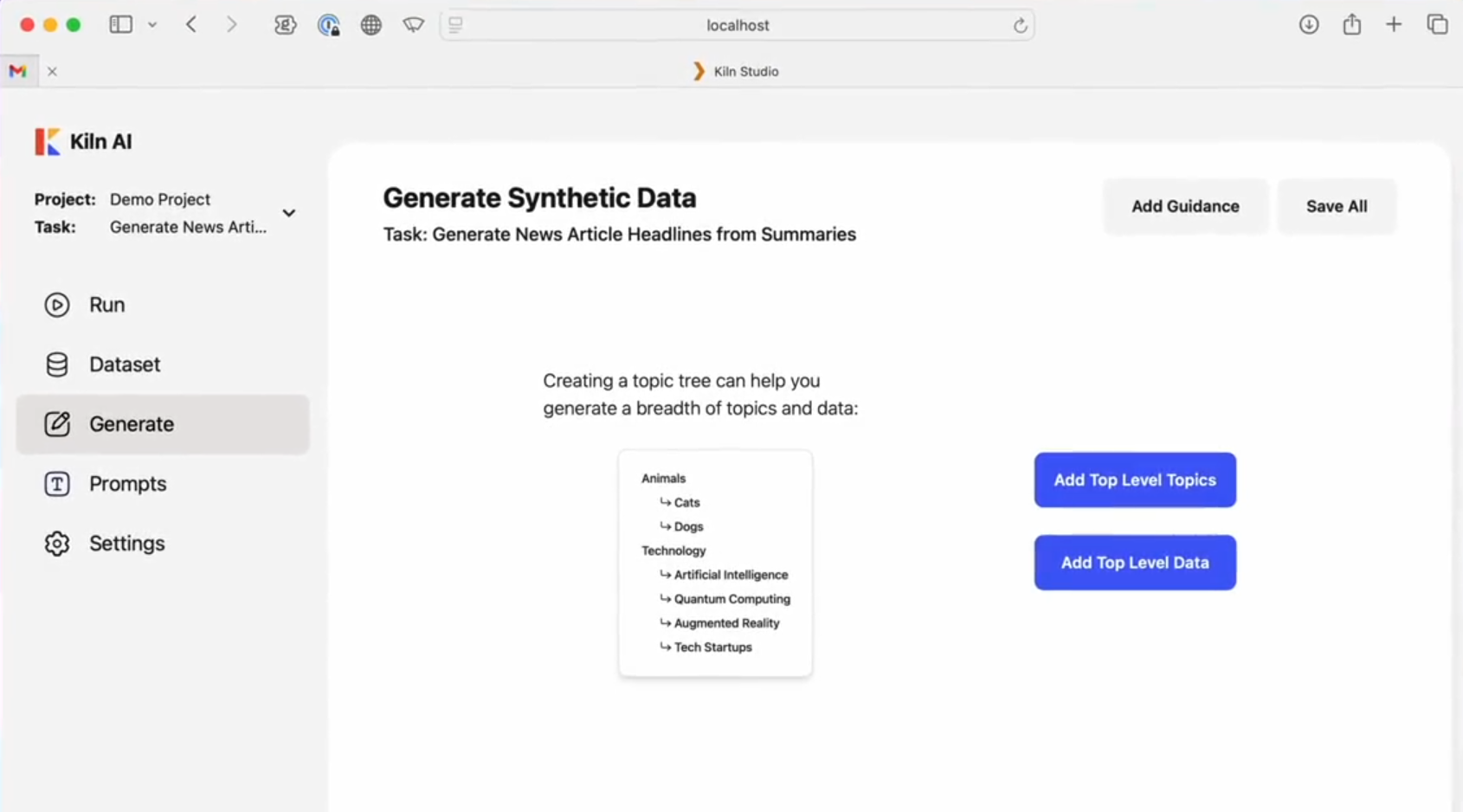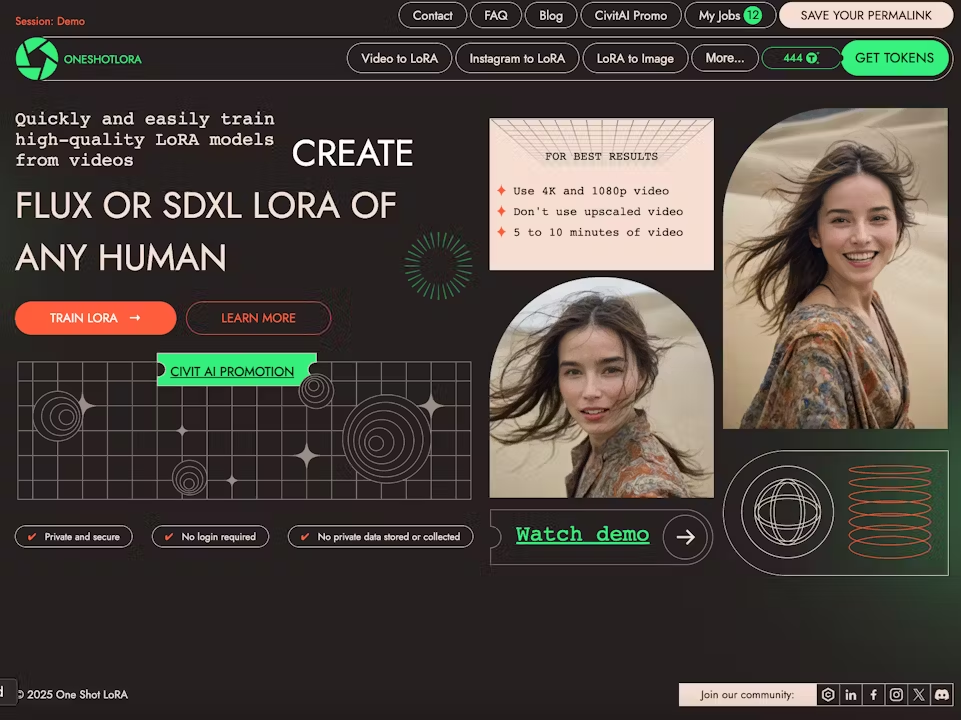
One Shot LoRA: die All-in-One-Plattform für die schnelle Erstellung von Video-LoRA-Modellen
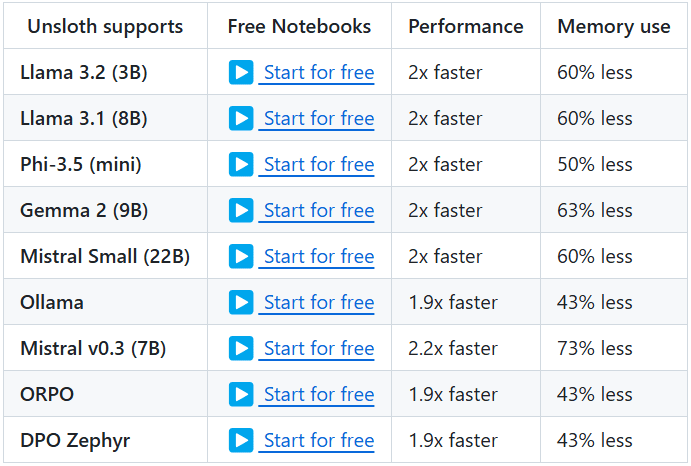
Allgemeine Einführung One Shot LoRA ist eine Plattform, die sich auf die Erstellung hochwertiger LoRA-Modelle aus Videos konzentriert. Benutzer können schnell und einfach Boutique LoRA-Modelle aus Videos trainieren, ohne sich anzumelden oder private Daten zu speichern. Die Plattform unterstützt Hunyua...