
综合介绍
FlowiseAI 是一个开源的低代码工具,旨在帮助开发者构建自定义的LLM(大语言模型)应用和AI代理。通过简单的拖放界面,用户可以快速创建和迭代LLM应用,从测试到生产的过程变得更加高效。FlowiseAI 提供了丰富的模板和集成选项,使得开发者能够轻松实现复杂的逻辑和条件设置,适用于各种应用场景。

功能列表
- 拖放界面:通过简单的拖放操作构建自定义LLM流。
- 模板支持:内置多种模板,快速开始构建应用。
- 集成选项:支持与LangChain和GPT等工具的集成。
- 用户认证:支持用户名和密码认证,确保应用安全。
- Docker支持:提供Docker镜像,方便部署和管理。
- 开发者友好:支持多种开发环境和工具,便于二次开发。
- 文档丰富:提供详细的文档和教程,帮助用户快速上手。
使用帮助
安装流程
- 下载并安装NodeJS:确保NodeJS版本>=18.15.0。
- 安装Flowise:
npm install -g flowise
- 启动Flowise:
npx flowise start
如果需要用户名和密码认证,可以使用以下命令:
npx flowise start --FLOWISE_USERNAME=user --FLOWISE_PASSWORD=1234
- 访问应用:在浏览器中打开http://localhost:3000。
使用流程
- 创建新项目:在Flowise界面中,点击“新建项目”按钮,输入项目名称并选择模板。
- 拖放组件:从左侧工具栏中拖放所需的组件到工作区,配置组件属性。
- 连接组件:通过拖动连接线,将组件连接起来,形成完整的流程。
- 测试应用:点击“运行”按钮,测试应用的功能和效果。
- 部署应用:完成测试后,可以将应用部署到生产环境,使用Docker镜像进行管理和维护。
特色功能操作
- 集成LangChain:在组件配置中,选择LangChain集成选项,输入相关参数,即可实现与LangChain的无缝对接。
- 用户认证:在.env文件中添加
FLOWISE_USERNAME和FLOWISE_PASSWORD变量,启动应用时将自动启用用户认证功能。 - 使用模板:在新建项目时选择合适的模板,可以快速搭建常见应用,如PDF问答、Excel数据处理等。
常见问题
- 内存不足:如果在构建过程中遇到内存不足的问题,可以增加Node.js的堆内存大小:
export NODE_OPTIONS="--max-old-space-size=4096"
pnpm build
- Docker部署:使用以下命令构建和运行Docker镜像:
docker build --no-cache -t flowise .
docker run -d --name flowise -p 3000:3000 flowise
通过以上步骤,用户可以快速上手使用FlowiseAI,构建和部署自定义的LLM应用,提升开发效率和应用性能。
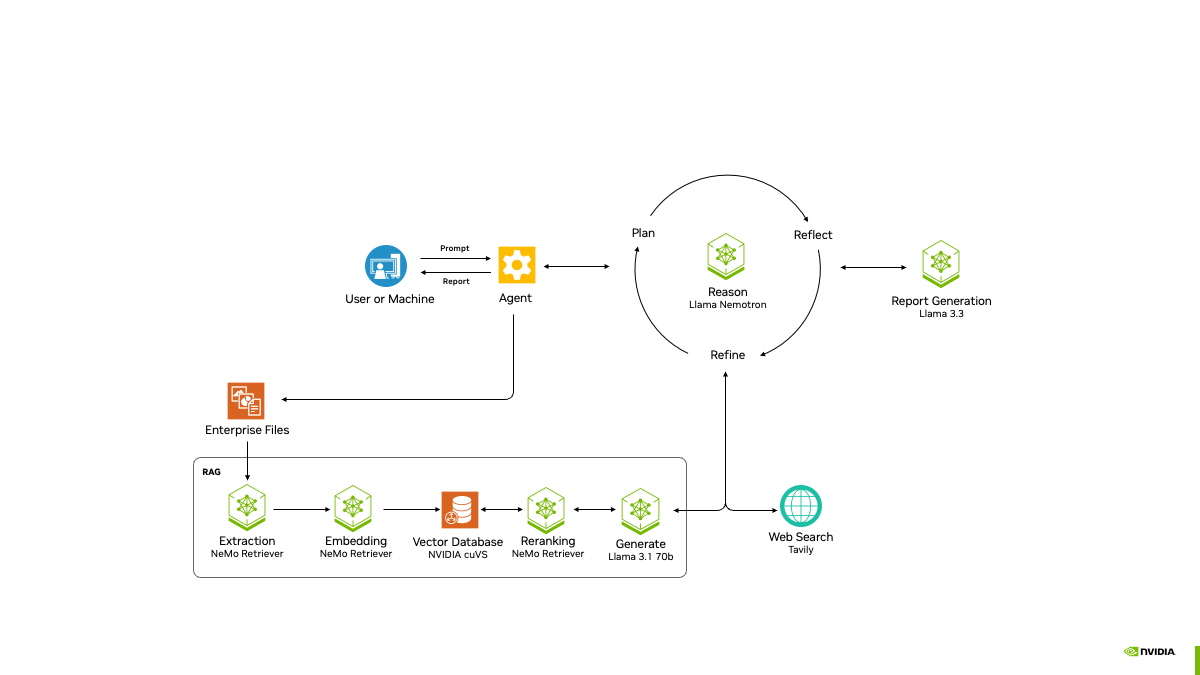
案例:使用 FlowiseAI 构建一个新闻自动撰写系统
Flowise 多工作流示意图

Flowise 配置流程
1. 我们使用Flowise构建一个新闻自动撰写系统,首先我们在Flowise的agentflows中创建一个新的代理,命名为"新闻自动撰写系统",如下图:

2. 我们在界面上依次拖入一个Supervisor,和3个Worker,并将它们命名及连接起来,如下图:

3. 设置每个代理的提示词:
# Supervisor
你是一个Supervisor,负责管理以下工作者之间的交流:`{team_members}`。
## 任务流程
1. **发送任务给worker1**
指示worker1搜索最新的新闻。
2. **等待worker1返回结果**
将worker1返回的最新新闻内容传递给worker2。
3. **等待worker2完成任务**
指示worker2将新闻编写成文章后,将文章内容传递给worker3。
4. **确认任务完成**
确保worker3成功保存文章后,通知任务完成。
## 注意事项
- 始终以准确、协调的方式调度任务。
- 确保每一步都完整且无遗漏。
# worker1 你是一个新闻搜索引擎,负责为调用者提供最新的新闻信息。以下是你的具体任务要求: 1. **搜索最新的 10 条新闻**:基于接收到的请求,查找符合条件的最新新闻内容。 2. **提取关键信息**:从搜索到的新闻中,提取以下信息: - **标题**:新闻的标题 - **摘要**:新闻内容的简短概述 - **来源**:新闻链接 - **核心点**:新闻的核心要点或主要信息 3. **返回清晰结构化信息**:将上述信息以清晰的格式返回给调用者。 ### 输出示例: - **标题**: [新闻标题] - **摘要**: [新闻摘要] - **来源**: [新闻链接] - **核心点**: [新闻核心点] ### 注意事项: - **时效性**:确保提供的新闻是最新的。 - **准确性**:确保提取的信息准确无误。
# worker2 ### 任务描述 1. **根据提供的新闻标题、摘要和内容来源,编写一篇完整且流畅的文章**:确保文章逻辑清晰,紧扣提供的信息,表达自然。 2. **语言要求**:简洁明了,避免冗长的表述,做到言之有物。 3. **格式要求**: - 标题单独成行,醒目突出。 - 正文分段合理,层次分明,方便阅读。 ### 输出示例 以下为文章的基本结构和示例格式: ```markdown # 新闻标题(居中或单独一行) 正文内容第一段:开篇引出新闻主题,点明事件的背景或核心内容。 正文内容第二段:详细描述新闻的主要内容,补充必要细节,使内容更加充实。 正文内容第三段:分析或评论新闻事件的意义、可能的影响或下一步发展。 正文内容第四段(可选):总结全文,呼应开头,给读者留下深刻印象。
# worker3 你的任务是: 1. 接收完整的文章内容,包括标题和正文。 2. 根据标题为文件命名,确保文件名简洁且有意义(例如:使用标题的前几个词并去除特殊字符)。 3. 将文件保存为TXT格式到指定的电脑路径。 4. 返回保存的文件路径和成功状态给调用者。例如: - 文件路径: [保存路径] - 状态: 保存成功
4. 设置Supervisor的Tool Calling Chat Model 和 Agent Memory,请根据自己实际情况,选择合适的大模型,如下图:

5. 为worker1选择合适的搜索工具,请根据自己的环境选择,如下图:

6. 为worker3选择合适的文件保存工具,如下图:

7. 最终整体配置如下图:

8. 配置完成后,我们点开右上角的对话框,输入关键词"大模型",如下图:




我们看到worker依次执行,完成了我们配置的任务。
9. 点击右上角的代码图标,我们就可以看到如何调用此系统的API,如下图:

© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章


暂无评论...