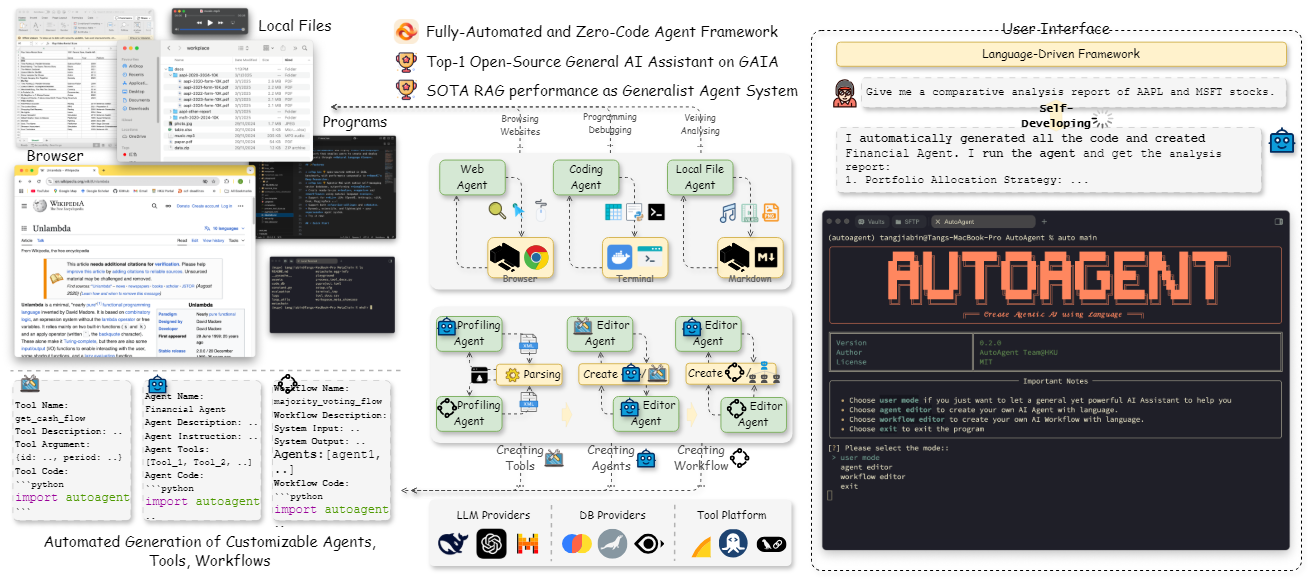

综合介绍
FireRedASR 是由小红书 FireRed 团队开发并开源的语音识别模型,专注于提供高精度、多语言支持的自动语音识别(ASR)解决方案。项目托管于 GitHub,面向开发者与研究者,提供工业级设计,支持普通话、中文方言、英语以及歌词识别等场景。FireRedASR 分为两个主要版本:FireRedASR-LLM 追求极致精度,适用于专业需求;FireRedASR-AED 兼顾效率与性能,适合实时应用。截至2025年,该模型在中文普通话测试中刷新了最优纪录(CER 3.05%),并在多场景测试中表现出色,广泛适用于智能助手、视频字幕生成等领域。


FireRedASR:WebUI一键安装包:https://github.com/jianchang512/fireredasr-ui
功能列表
- 支持普通话、中文方言和英语的语音转文字,识别准确率业界领先。
- 提供歌词识别功能,特别适用于多媒体内容处理。
- 包含 FireRedASR-LLM 和 FireRedASR-AED 两个版本,分别满足高精度和高效推理需求。
- 开源模型与推理代码,支持社区二次开发与定制化应用。
- 可处理多种音频输入场景,如短视频、直播、语音输入等。
- 支持批量音频处理,适合大规模数据转录任务。
使用帮助
安装流程
FireRedASR 需要一定的开发环境配置才能运行,以下是详细的安装步骤:
1.克隆项目仓库
打开终端,输入以下命令,将 FireRedASR 项目克隆到本地:
git clone https://github.com/FireRedTeam/FireRedASR.git
完成后,进入项目目录:
cd FireRedASR
- 创建 Python 环境
推荐使用 Conda 创建独立的 Python 环境,确保依赖隔离。运行以下命令:
conda create --name fireredasr python=3.10
激活环境:
conda activate fireredasr
- 安装依赖
项目提供了一个requirements.txt文件,包含所有必需的依赖包。安装命令如下:
pip install -r requirements.txt
等待安装完成,确保网络畅通,可能需要科学上网工具加速下载。
- 下载预训练模型
- FireRedASR-AED-L:直接从 GitHub 或 Hugging Face 下载预训练模型,放入
pretrained_models/FireRedASR-AED-L文件夹。 - FireRedASR-LLM-L:除下载模型外,还需下载 Qwen2-7B-Instruct 模型,放入
pretrained_models文件夹,并在FireRedASR-LLM-L目录下创建软链接:
ln -s ../Qwen2-7B-Instruct
- 验证安装
运行以下命令检查安装是否成功:
python speech2text.py --help
如果显示帮助信息,说明环境配置正确。
如何使用
FireRedASR 提供命令行和 Python API 两种使用方式,以下详细介绍主要功能的操作流程。
命令行操作
- 单文件转录(AED 模型)
使用 FireRedASR-AED-L 处理音频文件(最长支持 60 秒):
python speech2text.py --wav_path examples/wav/BAC009S0764W0121.wav --asr_type "aed" --model_dir pretrained_models/FireRedASR-AED-L
--wav_path:指定音频文件路径。--asr_type:选择模型类型,此处为 "aed"。--model_dir:指定模型文件夹。
输出结果会显示在终端,例如转录的文本内容。
- 单文件转录(LLM 模型)
使用 FireRedASR-LLM-L 处理音频(最长支持 30 秒):
python speech2text.py --wav_path examples/wav/BAC009S0764W0121.wav --asr_type "llm" --model_dir pretrained_models/FireRedASR-LLM-L
参数含义同上,输出为转录文本。
Python API 操作
- 加载模型并转录
在 Python 脚本中调用 FireRedASR 模型:
from fireredasr.models.fireredasr import FireRedAsr
# 初始化 AED 模型
model = FireRedAsr.from_pretrained("aed", "pretrained_models/FireRedASR-AED-L")
batch_uttid = ["BAC009S0764W0121"]
batch_wav_path = ["examples/wav/BAC009S0764W0121.wav"]
results = model.transcribe(
batch_uttid, batch_wav_path,
{"use_gpu": 1, "beam_size": 3, "nbest": 1, "decode_max_len": 0}
)
print(results)
- from_pretrained:加载指定模型。
- transcribe:执行转录任务,返回结果为文本列表。
- 调整参数优化结果
- use_gpu:设为 1 使用 GPU 加速,设为 0 使用 CPU。
- beam_size:搜索束宽度,越大精度越高但耗时增加,默认 3。
- nbest:返回最佳结果数量,默认 1。
特色功能操作
- 歌词识别
FireRedASR-LLM 在歌词识别上表现优异。将歌曲音频输入(确保不超过 30 秒),运行:python speech2text.py --wav_path your_song.wav --asr_type "llm" --model_dir pretrained_models/FireRedASR-LLM-L**输出为歌曲文本,识别率可达业内领先水平。 **
- 多语言支持
对于方言或英语音频,直接使用上述命令或 API,模型会自动适配。例如处理英语音频:model = FireRedAsr.from_pretrained("llm","pretrained_models/FireRedASR-LLM-L") results = model.transcribe(["english_audio"],["path/to/english.wav"],{"use_gpu":1}) print(results)
注意事项
- 音频长度限制:AED 支持最长 60 秒,超过可能出现幻觉问题;LLM 支持 30 秒,超长行为未定义。
- 批量处理:确保输入音频长度相近,避免性能下降。
- 硬件要求:推荐使用 GPU 运行大模型,CPU 可能较慢。
通过以上步骤,用户可以轻松上手 FireRedASR,完成从安装到使用的全流程,适用于多种语音识别场景。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章



暂无评论...