

在日新月异的翻译技术浪潮中,ChatGPT (Chat Generative Pre-trained Transformer) 的横空出世无疑吸引了全球目光。作为一种先进的 大语言模型 (Large Language Models, LLM),ChatGPT 展现出令人瞩目的自然语言处理能力,甚至在某些翻译任务中,其表现已能与专业翻译工具相媲美。然而,法律翻译领域以其高度的严谨性和专业性著称,在此特殊领域,ChatGPT 是否能够真正撼动当前主流 神经机器翻译 (Neural Machine Translation, NMT) 系统的地位?
本文将深入探讨一项最新研究,该研究通过对比 ChatGPT-4 与当前四大主流 NMT 系统在 英汉与汉英法律文本翻译 中的表现,旨在全面剖析它们各自的优势与不足。研究不仅揭示了两者在不同翻译方向上的性能差异,更细致地分析了它们在 术语翻译、语法结构以及风格规范 等方面所存在的典型错误。
研究背景:机器翻译技术发展与法律翻译的挑战
近年来,人工智能翻译技术取得了飞速发展,其中神经机器翻译技术尤为突出。众多学者致力于 NMT 的研究与优化,力求通过技术创新进一步提升 机器翻译 (Machine Translation, MT) 的质量。Feng 和 Zhang (2022) 的研究便指出,NMT 技术已迈入大规模实际应用阶段,尤其在英汉翻译领域,针对普通文本的翻译准确率已突破 90%,完全可以满足诸如新闻报道、产品说明、交通信息等日常场景的翻译需求。Li (2021) 的研究也观察到,基于神经网络技术的五种 在线机器翻译 (Online Machine Translation) 系统,其翻译质量已达到可接受水平,但在追求卓越方面仍有提升空间。
与此同时,大语言模型 在翻译领域的潜力也逐渐显现,部分研究表明,它们在某些翻译任务中的表现,已能与市场上一些专业的翻译平台并驾齐驱,甚至更胜一筹。例如,Yang (2023) 的研究发现,在越南语法律文本翻译方面,ChatGPT 与其他机器翻译系统以及人工翻译相比,并没有展现出明显的优势。然而,值得注意的是,ChatGPT 在自然语言处理、问题理解和用户交互等领域已取得了显著进展,甚至在句法复杂度方面,ChatGPT 的翻译结果已与人工翻译和 DeepL 翻译 相近。
然而,上述研究大多采用通用语料库,且翻译方向涵盖多种语言,鲜有研究聚焦于 ChatGPT 在英汉法律翻译领域的具体表现,更缺乏对 ChatGPT 与 NMT 系统在法律翻译质量方面差异的深入比较。
在全球化日益深入的背景下,英汉法律翻译的需求持续增长。ChatGPT 和 NMT 作为目前最先进的翻译技术,对其优劣势进行对比分析,不仅能为翻译系统的改进提供有益的参考,更能帮助法律翻译从业者更好地了解这些技术的能力边界,从而更明智地选择和使用翻译工具。
本研究旨在通过对比 ChatGPT-4 与四种主流 NMT 系统 (有道翻译、百度翻译、谷歌翻译和 DeepL 翻译) 在英汉和汉英法律文本翻译中的性能,系统评估它们在法律翻译领域的有效性。研究的核心问题包括:
- 在英汉和汉英法律文本翻译中,ChatGPT 与 NMT 系统,哪种表现更优异?
- 在相同的评估标准下,ChatGPT 和 NMT 系统在英汉翻译和汉英翻译中,哪种翻译方向的表现更佳?
- ChatGPT 和 NMT 系统在法律文本翻译中,各自产生的典型错误类型有何不同?
研究设计:严谨的评测体系
为了确保研究结果的有效性与可靠性,本研究在 源文本 (source texts, ST) 的选择上,严格遵循以下原则:
- 全面性 (comprehensiveness): 选取的文本涵盖民法、刑法、商法、行政法等多个法律子领域,力求研究结果具有广泛的适用性和代表性。
- 时效性 (timeliness): 仅选择当前仍在生效的法律文本,以真实反映当前法律翻译的实际需求与挑战。
- 多样性 (diversity): 选择的法律文本在结构、难度、语境等方面均有所差异,以全面评估 NMT 和 ChatGPT 对不同类型法律文本的翻译质量。
- 真实性 (authenticity): 选取的法律法规均来自公开渠道,便于同行进行评审,并验证研究结果的客观性。
- 参考性 (referentiality): 选取的文本均有官方或权威的翻译版本作为参考,以便对 NMT 和 ChatGPT 的翻译质量进行自动评估。
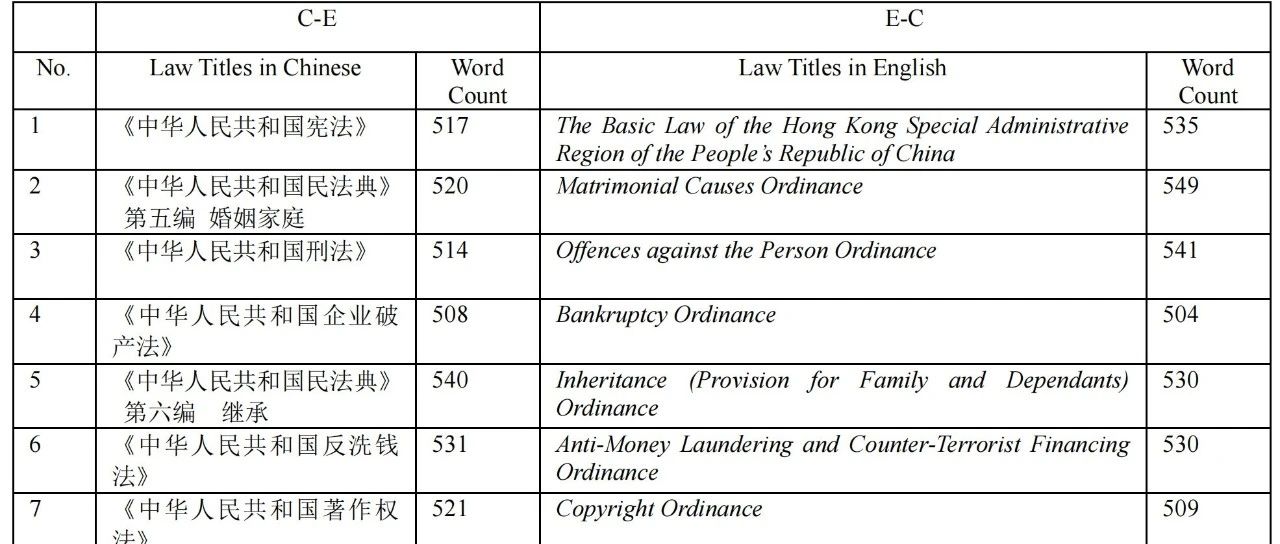
基于上述原则,研究人员从 14 部不同的中国法律中,精选出 15 篇中文文本作为汉英翻译的源文本,每篇文本长度控制在 500 至 550 个字符。为确保翻译评估的准确性和权威性,研究采用了中国法律信息数据库提供的官方英文译本作为 目标文本 (target texts, TT) 的参考译文。 同样地,为了便于与汉英翻译进行对比,研究人员从香港法律的电子版中选取了 15 篇相应的英文法律文本,长度同样控制在 500 至 550 个单词,作为英汉翻译的源文本。这些英文文本的官方中文版本(同样来自香港法律的电子版)则被用作目标文本的参考译文。
在研究方法上,本研究选择了 ChatGPT-4 以及当前主流的 NMT 系统作为研究对象,并采用 双语评估替补 (Bilingual Evaluation Understudy, BLEU) 作为评估机器翻译质量的核心指标。BLEU 是一种国际通用的机器翻译评估指标,其分数越高,代表翻译质量越好。研究团队利用试译宝平台提供的翻译评估工具来计算 BLEU 分数,从而对各系统的翻译质量进行量化评估。
研究的具体步骤如下:首先,将 30 篇源文本分别导入有道翻译、百度翻译、谷歌翻译和 DeepL 翻译等 NMT 系统进行翻译,同时使用 ChatGPT-4 进行翻译。随后,将 NMT 系统和 ChatGPT-4 生成的目标文本复制到 Word 文档中。接着,使用 “试译宝 - 翻译评估工具” 计算目标文本的 BLEU 分数。最后,运用 SPSS 27 统计软件对目标文本的 BLEU 值进行统计分析。
结果:量化评估与统计分析
汉英翻译质量对比
- 在汉英翻译中,ChatGPT 的平均 BLEU 分数最低,标准差最高,这表明其汉英法律翻译质量相对 NMT 系统而言,不仅偏低,且稳定性也稍逊一筹。
- 有道翻译 取得了最高的平均 BLEU 分数,谷歌翻译 紧随其后,DeepL 翻译 和 百度翻译 的得分则较为接近。
- 方差分析结果显示,各系统间的 BLEU 分数 差异不显著 (p = 0.119)。
- 然而,多重比较测试进一步揭示,ChatGPT 与有道翻译之间存在显著性差异,NMT 系统内部的百度翻译和有道翻译之间也存在显著性差异。
- 总体而言,ChatGPT 在汉英法律翻译方面的质量略低于 NMT 系统,但两者之间的差距并未达到显著水平 (p = 0.258)。
英汉翻译质量对比
- 在英汉翻译方面,ChatGPT 的平均 BLEU 分数依然最低,而有道翻译则再次斩获最高平均分。DeepL 翻译紧随有道翻译之后,百度翻译和谷歌翻译的得分相对靠后。
- 经检验,各系统得分数据的峰度和偏度绝对值均大于 1.96,表明数据 不符合正态分布。
- 因此,研究采用 Kruskal-Wallis 非参数检验,结果显示,五个系统之间的 BLEU 分数存在 显著差异 (p < 0.001)。
- 两两比较分析进一步发现,ChatGPT 与其余四个 NMT 系统之间的差异均达到显著水平,而四个 NMT 系统彼此之间的差异则 不显著。
- 综合来看,NMT 系统在英汉法律文本翻译方面的质量显著高于 ChatGPT。
英汉与汉英翻译质量总体对比
- 独立样本 T 检验结果表明,无论是 ChatGPT 还是 NMT 系统,在英汉和汉英两个翻译方向上,其翻译质量均存在显著差异 (p < 0.001)。
- 值得注意的是,汉英翻译的 BLEU 得分显著高于英汉翻译,这表明无论是 ChatGPT 还是 NMT 系统,在汉英法律翻译任务中均表现更出色。
讨论:错误类型分析与系统优劣势
为了更深入地理解 ChatGPT 和 NMT 系统在法律文本翻译中的表现,本研究进一步采用了案例分析法,对它们在法律文本翻译中出现的错误类型进行了细致的剖析。研究将主要错误归纳为以下三大类:术语翻译错误、语法和句法结构错误,以及风格和格式错误。
汉英翻译错误分析
- 术语翻译: 在法律术语翻译方面,ChatGPT 和 NMT 系统表现出相近的水平,术语翻译的准确率都相对较高,难以直接区分优劣。例如,“有期徒刑” (fixed-term imprisonment) 和 “无期徒刑” (life imprisonment) 等术语,各系统均能准确翻译。但对于 “拘役” (criminal detention) 的翻译,部分系统与参考译文 “limited incarceration” 存在差异,例如 DeepL 将 “管制” 翻译为 “control”,略显不够精准。
- 语法和句法结构: 在语法和句法结构方面,各系统也各有优劣。例如,在翻译 “十年以上有期徒刑” 时,谷歌翻译的译文出现明显的逻辑错误,表达存在自相矛盾之处。而在翻译 “致人死亡或者以特别残忍手段致人重伤造成严重残疾的” 这一复杂语句时,ChatGPT 的译文相对简洁明了,而部分 NMT 系统的译文则存在潜在的歧义。
- 风格和格式: 在风格和格式方面,ChatGPT 和 NMT 系统均未出现明显的格式错误,翻译结果的结构与原文保持一致,基本符合法律文件的典型格式要求。但部分 NMT 系统的译文在风格上略显不足,例如 DeepL 将 “intentionally inflicts bodily harm” 翻译为 “intentionally inflicts bodily harm”,略显生硬,百度翻译使用的 “those who...” 在法律英语中也相对不常见。
英汉翻译错误分析
- 术语翻译: 在英汉翻译中,ChatGPT 在法律术语的准确把握上略逊一筹。例如,ChatGPT 将 “with intent to murder” 翻译为 “以谋杀”,表达过于简单,未能充分体现原文所蕴含的法律意图。又如,ChatGPT 将 “be guilty of an offence triable upon indictment” 翻译为 “犯有可被起诉的罪行”,忽略了 “indictment (起诉)” 这一关键的法律程序步骤。相比之下,NMT 系统在中英法律术语翻译方面,能够提供更为精准的翻译结果。
- 语法和句法结构: NMT 系统在语法准确性和句式结构的规范性方面,整体优于 ChatGPT。 以 DeepL 为例,其将 “shall be guilty of an offence triable upon indictment, and shall be liable to imprisonment for life” 翻译为 “即属犯可循公诉程序审讯的罪行, 可处终身监禁”,译文句式结构清晰严谨,符合法律文本的表达习惯。
- 风格和格式: 在翻译法律文本中常见的修订条款时,NMT 系统的翻译更为规范,更贴近中文法律文本的表达习惯。
综合来看,在英汉法律翻译任务中,NMT 系统不仅在术语翻译的准确性上更胜一筹,还在语法结构、直译准确性以及正式表达等方面均展现出更为出色的性能。
论文链接:https://tpls.academypublication.com/index.php/tpls/article/view/8692
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章


暂无评论...