

DreamOmni2是什么
DreamOmni2是港科大贾佳亚团队开源的多模态AI图像编辑与生成模型。能同时处理文本和图像指令,支持多张参考图,为创作者提供更灵活的创作方式。模型采用三阶段数据合成流程进行训练,联合训练生成/编辑模型与视觉语言模型,有效保持图像主体的身份特征。DreamOmni2在多模态指令编辑与生成任务中表现出色,优于当前开源模型,在某些方面比肩或超越商业模型。可应用于产品摄影、设计工作流、肖像编辑和创意绘画等多个场景。
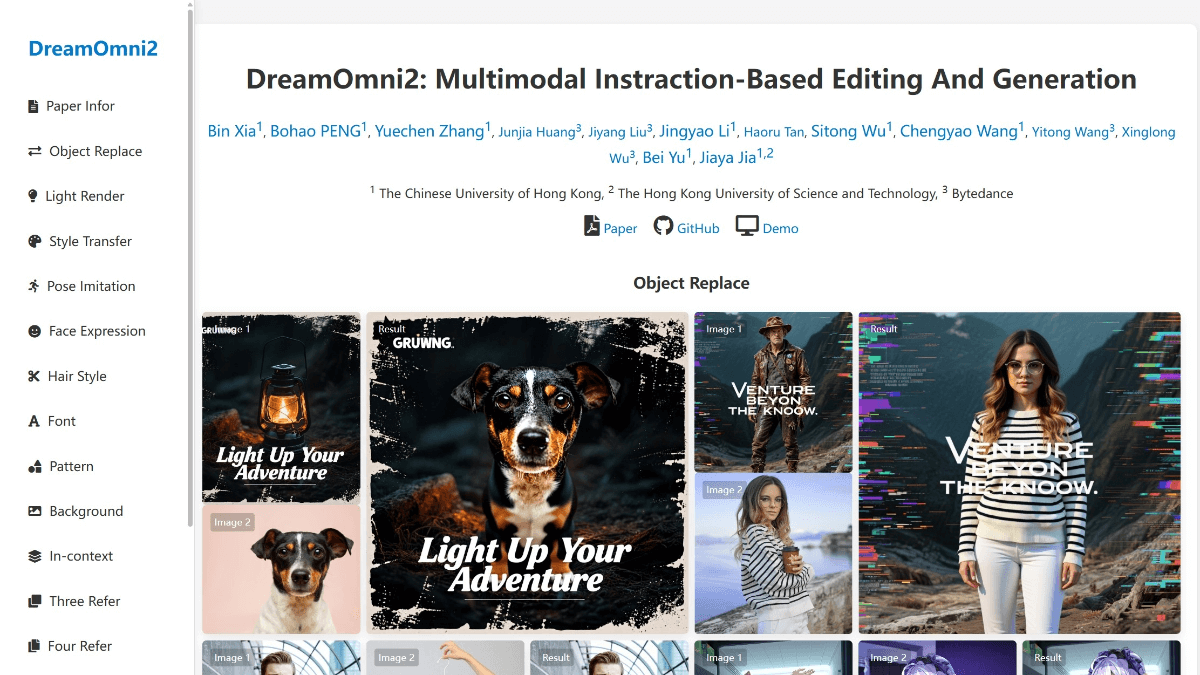
DreamOmni2的功能特色
- 多模态指令处理:支持文本和图像指令,可同时处理具体物体和抽象概念,如材质、纹理、风格等,为创作者提供更丰富的表达方式。
- 多参考图能力:能结合多张参考图像进行编辑和生成,为创作者提供更高的灵活性,满足复杂多样的创作需求。
- 数据合成与训练:采用三阶段数据合成流程,包括特征混合方法、编辑和提取模型生成训练数据,还设计了索引编码和位置编码偏移方案,避免多图像输入时像素混淆,提升模型的训练效果和生成质量。
- 联合训练:将生成/编辑模型与视觉语言模型(VLM)联合训练,更好地处理复杂指令,使模型能更准确地理解并执行用户的多模态指令。
- 身份一致性保持:在编辑过程中,能有效保持图像主体的身份特征,确保编辑后的图像与原主体的一致性,避免因编辑导致的主体特征丢失或混淆。
- 性能优势:在多模态指令编辑与生成任务中,DreamOmni2显著优于当前SOTA开源模型,甚至在一些方面比肩或超越商业模型,为用户提供更高质量的图像编辑和生成结果。
- 开源与易用性:代码、模型权重和训练数据集可在GitHub和Hugging Face上免费获取,支持本地运行,方便用户在具有足够显存的CUDA兼容GPU上进行本地推理,降低了使用门槛,提高了模型的可及性。
DreamOmni2的核心优势
- 多模态指令理解:能同时处理文本和图像指令,精准理解并执行复杂的编辑任务,如材质、纹理、风格等抽象概念的修改。
- 多参考图支持:可结合多张参考图进行编辑和生成,为创作者提供更高的灵活性,满足多样化创作需求。
- 身份一致性保持:在编辑过程中,有效保持图像主体的身份特征,确保编辑后的图像与原主体高度一致,避免主体特征丢失或混淆。
- 联合训练机制:将生成/编辑模型与视觉语言模型联合训练,提升对复杂指令的理解和执行能力,生成更符合用户意图的图像。
- 性能卓越:在多模态指令编辑与生成任务中,性能显著优于当前开源模型,甚至在某些方面超越商业模型,提供高质量的图像编辑和生成效果。
DreamOmni2官网是什么
- 项目官网:https://pbihao.github.io/projects/DreamOmni2/index.html
- Github仓库:https://github.com/dvlab-research/DreamOmni2
- arXiv技术论文:https://arxiv.org/pdf/2510.06679
- 体验地址:https://huggingface.co/spaces/wcy1122/DreamOmni2-Gen
DreamOmni2的适用人群
- 创意设计师:能快速实现设计想法,生成多种风格的设计稿,提高工作效率。
- 摄影师:用于产品摄影后期处理,提升产品视觉效果,满足不同客户的需求。
- 艺术家:快速创作绘画作品,探索不同风格和创意,激发艺术灵感。
- 广告从业者:快速生成广告素材,满足不同广告主题和风格的要求。
- 个人创作者:轻松实现创意想法,制作个性化的图像内容,满足个人创作需求。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章


暂无评论...