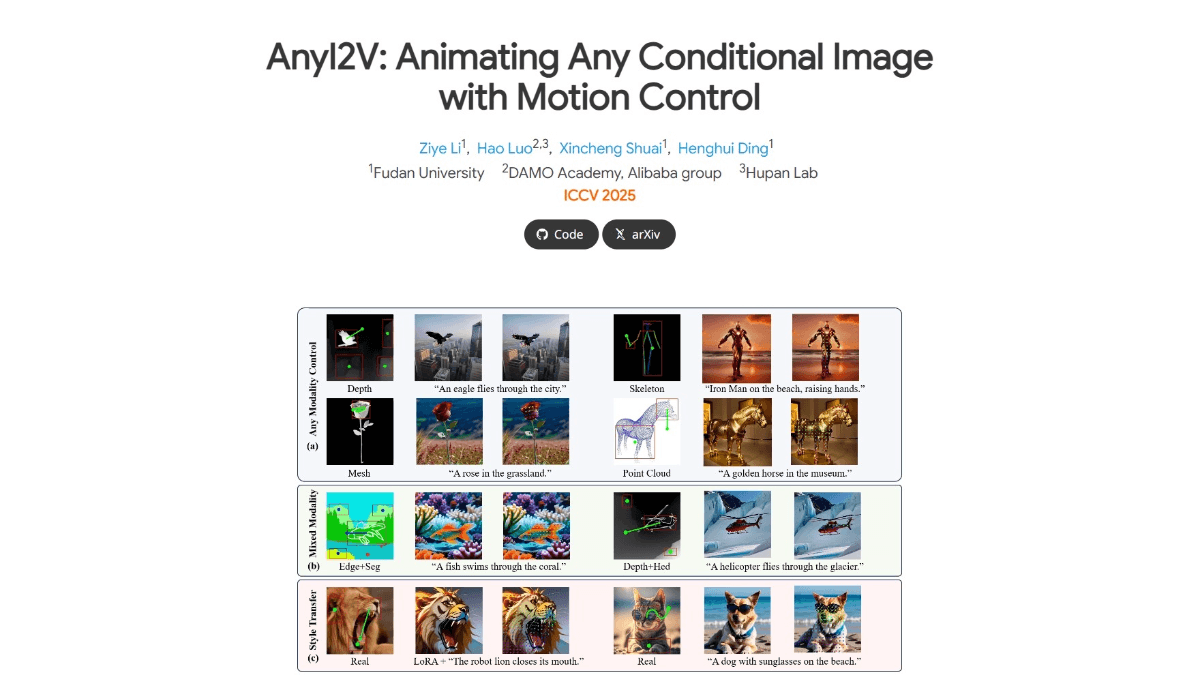

综合介绍
DisPose是一个创新的开源人工智能项目,专注于可控的人物图像动画生成。该项目由研究团队开发并在GitHub上开源,采用先进的深度学习技术,通过分解骨骼姿态信息来实现精确的人物动画控制。DisPose的核心创新在于将稀疏的骨骼姿态信息分解为运动场引导和关键点对应两个关键组件,这种独特的方法使得生成的动画更加自然流畅,且具有更强的可控性。项目不仅提供了完整的代码实现,还包含了预训练模型,使研究人员和开发者能够快速部署和使用这一技术。
同类项目:StableAnimator:生成高质量保持人物特征的视频动画

功能列表
- 人体姿态检测和关键点提取
- 运动场生成和控制
- 人物图像动画合成
- 多关节点精确控制
- 人脸和手部细节处理
- 批量视频处理能力
- 姿态迁移和动作重定向
- 实时姿态估计和跟踪
- 自定义动画控制参数调节
- 高质量动画效果输出
使用帮助
1. 环境配置
DisPose需要以下基本环境配置:
- Python 3.10或更高版本
- PyTorch 2.0.1及以上
- TorchVision 0.15.2及以上
- CUDA 12.4(用于GPU加速)
安装步骤:
# 创建conda环境
conda create -n dispose python==3.10
conda activate dispose
# 安装依赖
pip install -r requirements.txt
2. 模型准备
- 从Hugging Face下载预训练模型权重文件:
- 访问 https://huggingface.co/lihxxx/DisPose
- 下载 DisPose.pth 文件
- 将文件放置在 ./pretrained_weights/ 目录下
3. 核心功能使用流程
3.1 姿态检测
系统使用DWPose检测器进行人体姿态检测,可以识别以下关键点:
- 身体骨骼关节点(18个)
- 面部特征点(68个)
- 手部关键点(21个/手)
3.2 图像预处理
# 处理参考图像
ref_image = load_image(image_path)
pose_img, ref_pose = get_image_pose(ref_image)
3.3 视频处理
# 处理视频序列
video_pose, body_points, face_points = get_video_pose(
video_path=video_path,
ref_image=ref_image,
sample_stride=1
)
3.4 动画生成控制
系统提供多个参数用于控制动画生成:
- 运动场强度调节
- 关键点对应权重
- 姿态迁移程度
- 时序平滑度
4. 高级功能说明
- 姿态迁移:
- 支持从源视频到目标人物的姿态迁移
- 保持人物身份特征不变
- 自动适应不同体型差异
- 动作编辑:
- 支持局部动作修改
- 提供关键帧编辑功能
- 可调整动作速度和幅度
- 批处理能力:
- 支持批量视频处理
- 提供并行处理选项
- 自动资源调度优化
5. 注意事项
- 确保输入图像质量清晰,人物姿态完整可见
- GPU显存建议至少8GB以上
- 处理高分辨率视频时注意调整sample_stride参数
- 定期检查并更新依赖包版本
- 建议在处理大量数据前先进行小规模测试
6. 常见问题解决
- 内存问题:
- 使用release_memory()释放未使用的资源
- 适当调整批处理大小
- 使用低分辨率进行测试
- 性能优化:
- 启用GPU加速
- 使用适当的采样步长
- 优化输入图像分辨率
- 质量提升:
- 使用高质量参考图像
- 调整模型参数
- 进行后处理优化
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章


暂无评论...