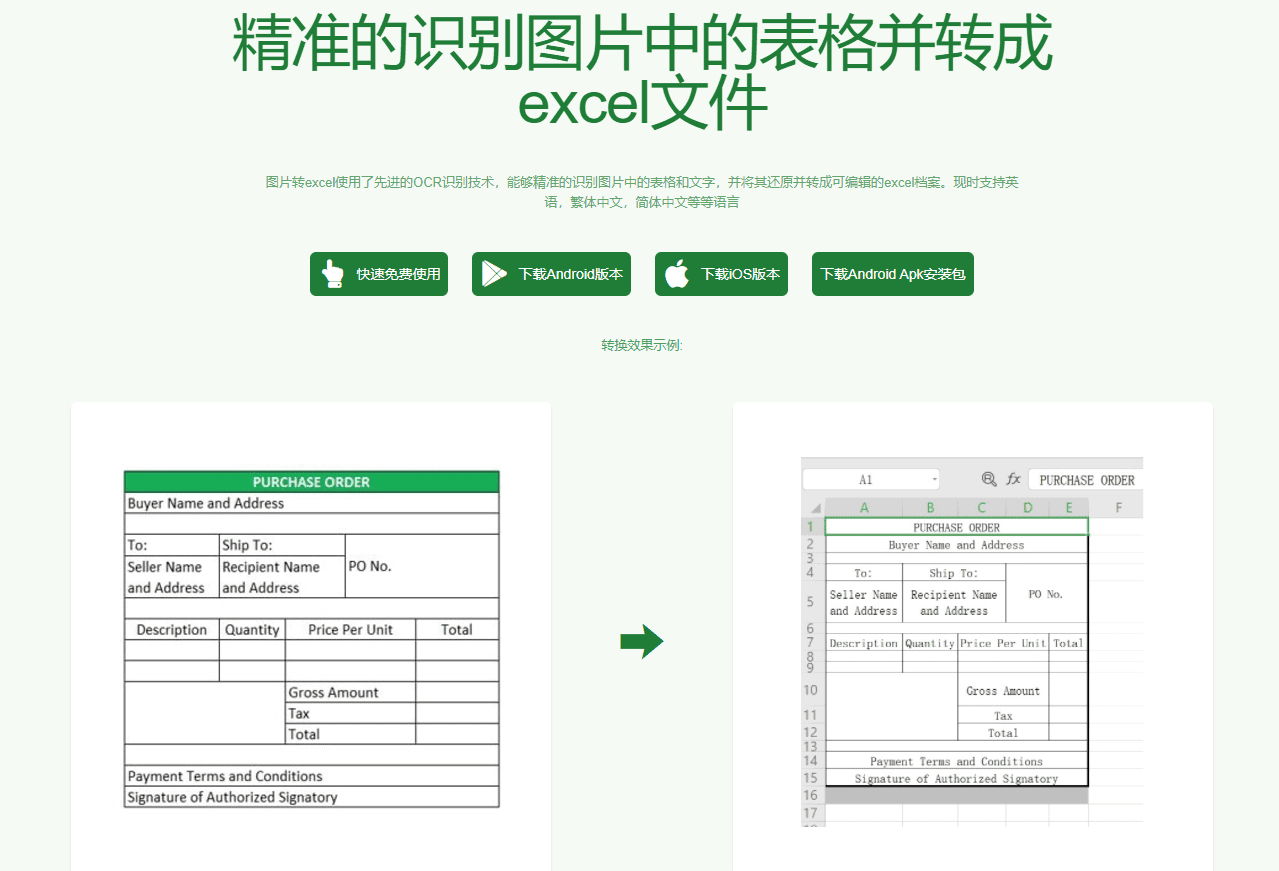

综合介绍
Crawl4LLM 是一个由清华大学和卡内基梅隆大学联合开发的开源项目,专注于优化大模型(LLM)预训练的网页爬取效率。它通过智能选择高质量网页数据,显著减少无效爬取,号称能将原本需要爬取100个网页的工作量缩减到21个,同时保持预训练效果。项目托管在 GitHub 上,提供详细代码和配置文档,适合开发者和研究人员使用。Crawl4LLM 的核心在于其数据选择算法,能评估网页对模型训练的价值,优先抓取有用内容,已在学术界和开发者社区中引发关注。

功能列表
- 智能数据选择:根据网页对大模型预训练的影响力,筛选高价值内容。
- 多种爬取模式:支持 Crawl4LLM 模式、随机爬取等,灵活应对不同需求。
- 高效爬取引擎:利用多线程和优化配置,显著提升爬取速度。
- 数据提取与存储:将爬取的网页ID和文本内容保存为可用于模型训练的文件。
- 支持大规模数据集:兼容 ClueWeb22 等数据集,适合学术研究和工业应用。
- 配置自定义:通过 YAML 文件调整爬取参数,如线程数和文档数量上限。
使用帮助
安装流程
Crawl4LLM 需要在支持 Python 的环境中运行,以下是详细安装步骤:
- 环境准备
- 确保系统安装 Python 3.10 或更高版本。
- 创建虚拟环境以避免依赖冲突:
python -m venv crawl4llm_env source crawl4llm_env/bin/activate # Linux/Mac crawl4llm_env\Scripts\activate # Windows
- 克隆项目
- 从 GitHub 下载源码:
git clone https://github.com/cxcscmu/Crawl4LLM.git cd Crawl4LLM
- 从 GitHub 下载源码:
- 安装依赖
- 运行以下命令安装所需库:
pip install -r requirements.txt - 注意:依赖文件列出了爬虫运行所需的所有 Python 包,确保网络畅通。
- 运行以下命令安装所需库:
- 下载分类器
- 项目使用 DCLM fastText 分类器评估网页质量,需手动下载模型文件至
fasttext_scorers/目录。 - 示例路径:
fasttext_scorers/openhermes_reddit_eli5_vs_rw_v2_bigram_200k_train.bin。 - 可从官方资源或相关链接获取。
- 项目使用 DCLM fastText 分类器评估网页质量,需手动下载模型文件至
- 准备数据集
- 如果使用 ClueWeb22 数据集,需申请访问权限并将其存储在 SSD 上(路径需在配置中指定)。
如何使用
Crawl4LLM 的操作主要通过命令行完成,分为配置、爬取和数据提取三个步骤。以下是详细流程:
1. 配置爬取任务
- 在
configs/目录下创建一个 YAML 文件(如my_config.yaml),内容示例:cw22_root_path: "/path/to/clueweb22_a" seed_docs_file: "seed.txt" output_dir: "crawl_results/my_crawl" num_selected_docs_per_iter: 10000 num_workers: 16 max_num_docs: 20000000 selection_method: "dclm_fasttext_score" order: "desc" wandb: false rating_methods: - type: "length" - type: "fasttext_score" rater_name: "dclm_fasttext_score" model_path: "fasttext_scorers/openhermes_reddit_eli5_vs_rw_v2_bigram_200k_train.bin"
- 参数说明:
cw22_root_path:ClueWeb22 数据集路径。seed_docs_file:初始种子文档列表。num_workers:线程数,根据机器性能调整。max_num_docs:最大爬取文档数。selection_method:数据选择方式,推荐使用dclm_fasttext_score。
2. 运行爬虫
- 执行爬取命令:
python crawl.py crawl --config configs/my_config.yaml - 爬取完成后,文档 ID 会保存在
output_dir指定路径下的文件中。
3. 提取文档内容
- 使用以下命令将爬取的文档 ID 转换为文本:
python fetch_docs.py --input_dir crawl_results/my_crawl --output_dir crawl_texts --num_workers 16 - 输出结果为文本文件,可直接用于后续模型训练。
4. 查看单个文档
- 若需检查特定文档及其链接,可运行:
python access_data.py /path/to/clueweb22 <document_id>
特色功能操作
- 智能选择网页
- Crawl4LLM 的核心在于其数据筛选能力。它通过 fastText 分类器评估网页内容长度和质量,优先抓取对模型训练更有帮助的页面。用户无需手动筛选,系统自动完成优化。
- 操作方法:在 YAML 配置中设置
selection_method为dclm_fasttext_score,并确保模型路径正确。
- 多线程加速
- 通过
num_workers参数调整线程数。例如,16 核 CPU 可设为 16,充分利用计算资源。 - 注意:线程数过高可能导致内存溢出,建议根据机器配置测试。
- 通过
- 支持大规模爬取
- 项目针对 ClueWeb22 等超大数据集设计,适合需要处理亿级网页的研究场景。
- 操作建议:将数据存放于 SSD,确保 I/O 性能;设置
max_num_docs为目标文档数(如 2000 万)。
使用技巧
- 调试与日志:启用
wandb: true可记录爬取过程,便于分析效率。 - 优化存储:爬取结果较大,建议预留足够磁盘空间(如数百 GB)。
- 扩展功能:结合 DCLM 框架,可直接将提取的文本用于大模型预训练。
通过以上步骤,用户可快速上手 Crawl4LLM,实现高效网页数据爬取和优化预训练流程。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章


暂无评论...