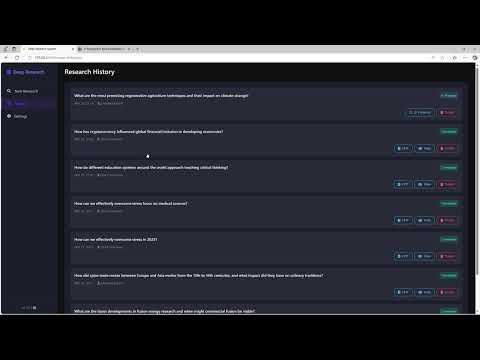

综合介绍
CogAgent是由清华大学数据挖掘研究组(THUDM)开发的开源视觉语言模型,旨在实现跨平台的图形用户界面(GUI)自动化操作。该模型基于CogVLM(GLM-4V-9B),支持中英文双语交互,能够通过屏幕截图和自然语言进行任务执行。CogAgent在多个平台和类别的GUI任务中取得了领先的性能,适用于Windows、macOS和Android等多种计算设备。其最新版本CogAgent-9B-20241220在GUI感知、推理准确性、操作空间完整性和任务泛化性方面有显著提升。
CogAgent-9B-20241220模型基于 GLM-4V-9B,这是一个双语开源的 VLM 基础模型。通过数据收集和优化、多阶段训练和策略改进,CogAgent-9B-20241220在 GUI 感知、推理预测精度、动作空间完整性和跨任务泛化能力方面取得了显著进步。该模型支持双语(中文和英文)交互,包括截图和语言输入。这个版本的 CogAgent 模型已经被应用于智谱 AI 的 GLM-PC 产品中。


功能列表
- 高分辨率图像理解和处理(支持1120x1120分辨率)
- GUI界面自动化操作能力
- 跨平台兼容的界面交互
- 视觉问答(VQA)任务处理
- 图表理解与分析(ChartQA)
- 文档视觉问答(DocVQA)
- 信息视觉问答(InfoVQA)
- 场景文本理解(ST-VQA)
- 通用知识视觉问答(OK-VQA)
使用帮助
1. 环境配置
1.1 基础要求:
- Python 3.8或更高版本
- CUDA支持的GPU设备
- 足够的显存空间(推荐至少16GB)
1.2 安装步骤:
# 克隆项目仓库
git clone https://github.com/THUDM/CogAgent.git
cd CogAgent
# 安装依赖
pip install -r requirements.txt
2. 模型加载与使用
2.1 模型下载:
- 从Hugging Face平台下载模型权重文件
- 支持两种版本:cogagent-18b和cogagent-9b
2.2 基本使用流程:
from cogagent import CogAgentModel
# 初始化模型
model = CogAgentModel.from_pretrained("THUDM/CogAgent")
# 加载图像
image_path = "path/to/your/image.jpg"
response = model.process_image(image_path)
# 执行GUI操作
gui_command = model.generate_gui_command(image_path, task_description)
model.execute_command(gui_command)
3. 主要功能使用说明
3.1 图像理解功能:
- 支持多种图像格式输入
- 可处理高达1120x1120分辨率的图像
- 提供详细的图像内容描述和分析
3.2 GUI自动化操作:
- 支持识别界面元素
- 可执行点击、拖拽、输入等操作
- 提供操作验证和错误处理机制
3.3 视觉问答功能:
- 支持自然语言提问
- 提供详细的图像相关答案
- 可处理复杂的推理问题
4. 性能优化建议
4.1 显存管理:
- 使用适当的批处理大小
- 及时清理未使用的模型实例
- 控制并发处理任务数量
4.2 推理速度优化:
- 使用FP16精度加速推理
- 启用模型量化减少资源占用
- 优化图像预处理流程
5. 常见问题解决
5.1 内存问题:
- 检查显存使用情况
- 适当调整批处理大小
- 使用梯度检查点技术
5.2 精度问题:
- 确保输入图像质量
- 调整模型参数配置
- 验证预处理步骤正确性
主要功能操作流程
- 单步操作:通过简单的自然语言指令执行单步操作,如打开应用程序、点击按钮等。
- 多步操作:支持复杂的多步操作任务,通过连续的指令实现自动化工作流。
- 任务记录与回放:记录用户操作历史,并支持回放功能,方便调试和优化。
- 错误处理:内置错误处理机制,能够识别并处理常见的操作错误,确保任务顺利完成。
特色功能
- 高效推理:在BF16精度下,模型推理需要至少29GB的GPU内存,推荐使用A100或H100 GPU。
- 灵活部署:支持在多种硬件平台上部署,包括HuggingFace、ModelScope和WiseModel等。
- 社区支持:活跃的开源社区,提供技术支持和问题解答,帮助开发者快速上手。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章



暂无评论...