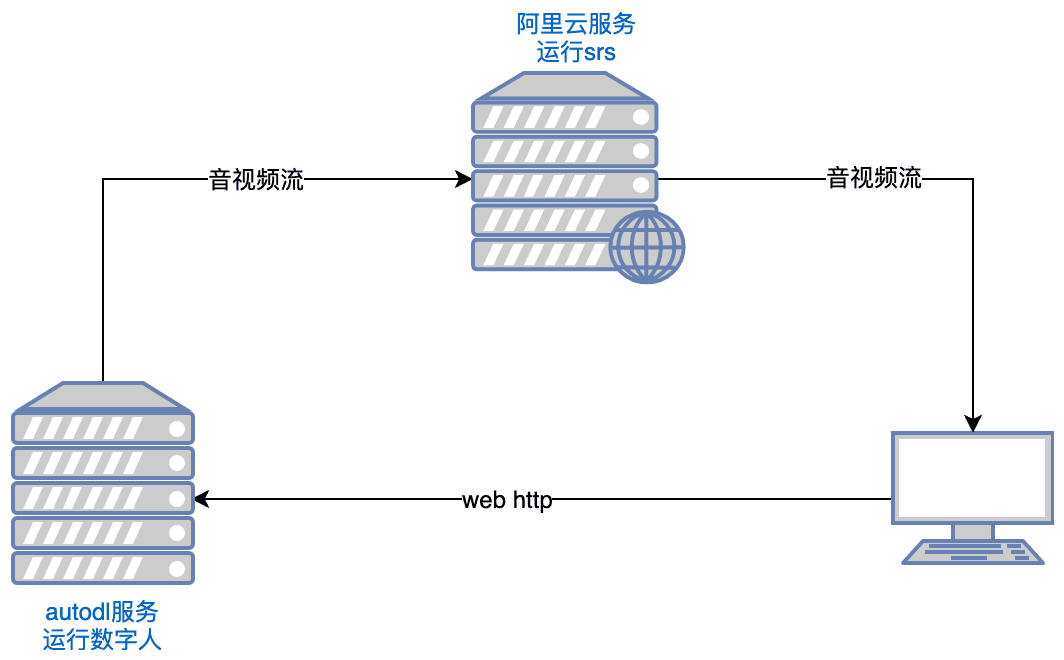

综合介绍
Auto-Audio-Book 是一个开源项目,托管在 GitHub 上。它能自动从网站爬取小说内容,并将其转换为带有多角色配音的有声书。开发者 zqq-nuli 使用 Python 3.10+ 编写,结合大模型(如 Gemini 和 CosyVoice2-0.5B)实现文本处理和语音合成。项目不仅支持基本的文本转音频,还能区分小说中的角色并分配不同声音,生成类似广播剧的效果。代码公开,用户可自由下载、修改。截至 2025 年 3 月 24 日,项目仍在开发中,GUI 未完全完善,但已能通过命令行完成全流程,适合技术爱好者和有声书制作者。
功能列表
- 小说爬取:从指定网站自动下载小说章节内容。
- 对话信息生成:利用 AI 分析文本,区分角色和对话。
- 多角色配音:为小说角色分配不同声音,支持主角、旁白和随机配音。
- 音频生成:将文本转为 MP3 格式的有声书,支持多线程加速。
- 管理工具:提供 GUI 辅助管理小说数据和音频文件。
- 开源可扩展:用户可修改代码,添加新功能或优化效果。
使用帮助
Auto-Audio-Book 需要一定的技术基础才能安装和使用。以下是详细的安装和操作指南,帮助你从零开始生成有声书。
安装流程
- 环境准备
- 安装 Python 3.10 或更高版本,从 https://www.python.org/downloads/ 下载。
- 安装
ffmpeg,用于音频处理。Windows 可从 https://ffmpeg.org/download.html 下载,Mac 用brew install ffmpeg,Linux 用sudo apt install ffmpeg。 - (可选)安装 MongoDB,用于 GUI 管理小说数据,下载地址:https://www.mongodb.com/try/download/community。
- 检查环境:在命令行输入
python --version和ffmpeg -version,确保版本显示正常。
- 下载代码
- 用 Git 克隆项目到本地:
git clone https://github.com/zqq-nuli/auto-audio-book.git - 进入项目目录:
cd auto-audio-book
- 用 Git 克隆项目到本地:
- 创建虚拟环境
- 使用
uv创建虚拟环境(需先安装uv,用pip install uv):uv venv --python 3.10 - 激活环境:
- Windows:
.\.venv\Scripts\activate - Mac/Linux:
source .venv/bin/activate
- Windows:
- 使用
- 安装依赖
- 在虚拟环境中安装所需库:
uv add -r requirements.txt - 如果缺少
requirements.txt,可手动安装核心库:pip install requests gTTS PyPDF2 pymongo
- 在虚拟环境中安装所需库:
- 配置 API Key
- 复制
.env.example文件为.env:copy .env.example .env # Windows cp .env.example .env # Mac/Linux - 编辑
.env文件,填入大模型 API Key,例如 Gemini 的密钥,可从对应平台申请。
- 复制
使用步骤
- 爬取小说
- 选择小说网站(如 https://m.ilwxs.com/),项目默认支持无防护站点。
- 运行爬取脚本:
python app/getBookList.py - 然后获取章节列表并保存内容:
python app/getZjList.py python app/saveBooks.py
- 生成对话信息
- 用 AI 处理章节,区分角色和对话:
python app/saveBookJson.py - 输出结果保存为 JSON 文件,用于后续配音。
- 用 AI 处理章节,区分角色和对话:
- 配置角色声音
- 运行脚本创建角色表:
python app/createUser.py - 手动指定主角和旁白的声音(支持 CosyVoice2-0.5B 等模型)。其他角色可随机分配:
- 超过 50 句台词的角色用独立声音。
- 少于 50 句的用旁白声音。
- 运行脚本创建角色表:
- 生成音频
- 运行音频生成脚本:
python app/createAudio.py - 支持多线程加速,例如开 20 线程:
python app/createAudio.py --threads 20 - 输出为 MP3 文件,存放在项目目录。
- 运行音频生成脚本:
- 管理音频(可选)
- 用 GUI 工具排序音频:
python gui/gui.py - 或批量删除喜马拉雅作品:
python gui/gui2.py
- 用 GUI 工具排序音频:
操作注意
- 效率优化:一台电脑单线程一晚可处理 300 章。测试显示,5 台机器每台 20 线程,5 小时可生成 2000 章。
- 错误排查:若有漏章,检查网络或重新运行对应章节脚本。
- 模型限制:硅基模型对 IP 有限制,多机并行需抢占服务器。
示例流程
假设你要转换一本小说:
- 爬取 https://m.ilwxs.com/ 的小说《某某》,保存章节。
- 生成对话信息,识别主角 A 和旁白。
- 配置 A 用中文男声,旁白用女声,其他随机。
- 运行多线程生成,得到
chapter1.mp3等文件。
完成后,可上传至喜马拉雅等平台,成品示例见 https://www.ximalaya.com/album/88023000。
应用场景
- 有声书制作
把网络小说转为多角色有声书,上传平台分享或盈利。 - 学习实验
技术爱好者用它学习爬虫、AI 和音频处理技术。 - 个人娱乐
将喜欢的小说转为音频,随时随地收听。
QA
- 支持哪些大模型?
当前支持 Gemini 和 CosyVoice2-0.5B,需自行申请 API Key。 - 为什么有些章节没生成?
可能是网络中断或爬取失败,检查日志后重跑对应章节。 - 如何提高音频质量?
默认模型效果有限,可替换为其他 TTS 引擎,需修改代码。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章


暂无评论...