
简介
数据分块是检索增强生成(RAG)系统中的关键步骤。它将大型文档分解为较小的、可管理的片段,以便高效索引、检索和处理。本 README 提供了 RAG 管道中可用的各种分块方法概述。
https://github.com/adithya-s-k/AI-Engineering.academy/tree/main/RAG/01_Data_Ingestion
分块在 RAG 中的重要性
有效的分块对 RAG 系统至关重要,因为它可以:
- 通过创建连贯的自包含信息单元,提高检索准确性。
- 提升嵌入生成与相似性搜索的效率。
- 在生成响应时,允许更精确地选择上下文。
- 帮助管理语言模型和嵌入系统的 Token 限制。
分块方法
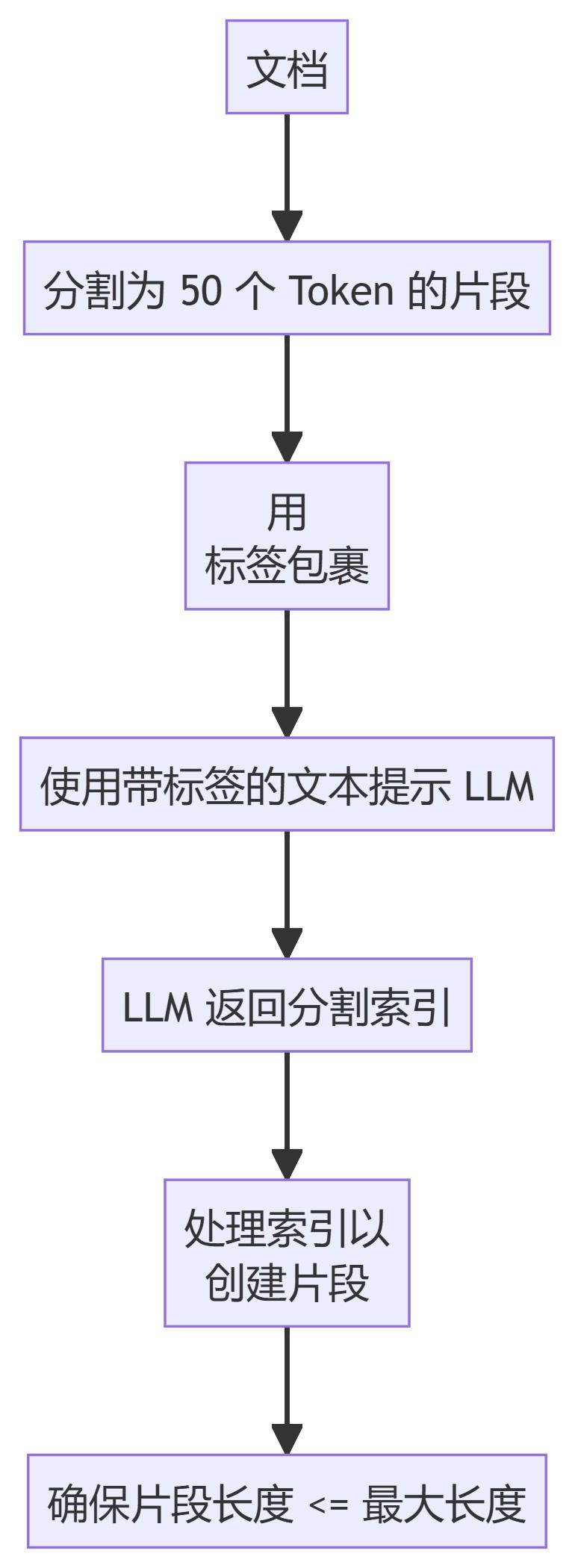
我们已实现了六种不同的分块方法,每种方法具有不同的优势和使用场景:
- RecursiveCharacterTextSplitter
- TokenTextSplitter
- KamradtSemanticChunker
- KamradtModifiedChunker
- ClusterSemanticChunker
- LLMSemanticChunker
分块工作流
1. RecursiveCharacterTextSplitter
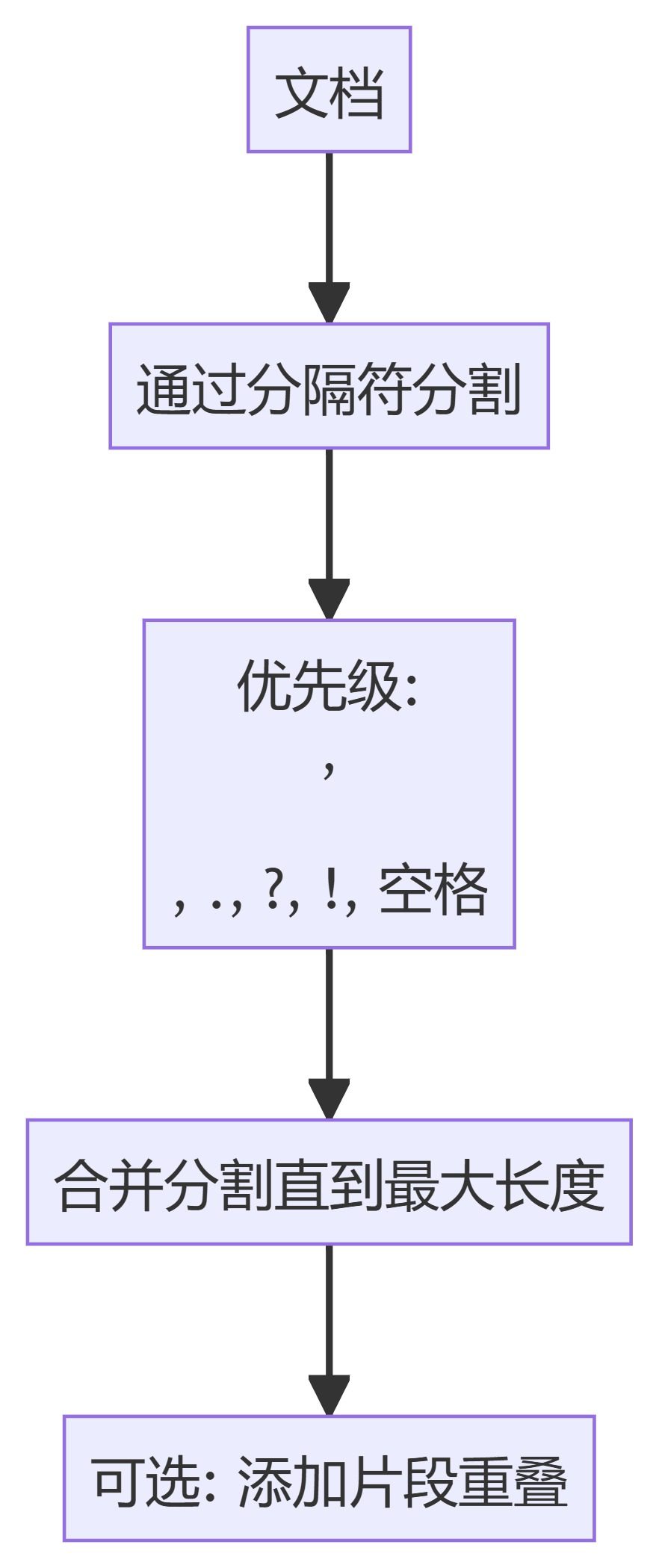
2. TokenTextSplitter

3. KamradtSemanticChunker
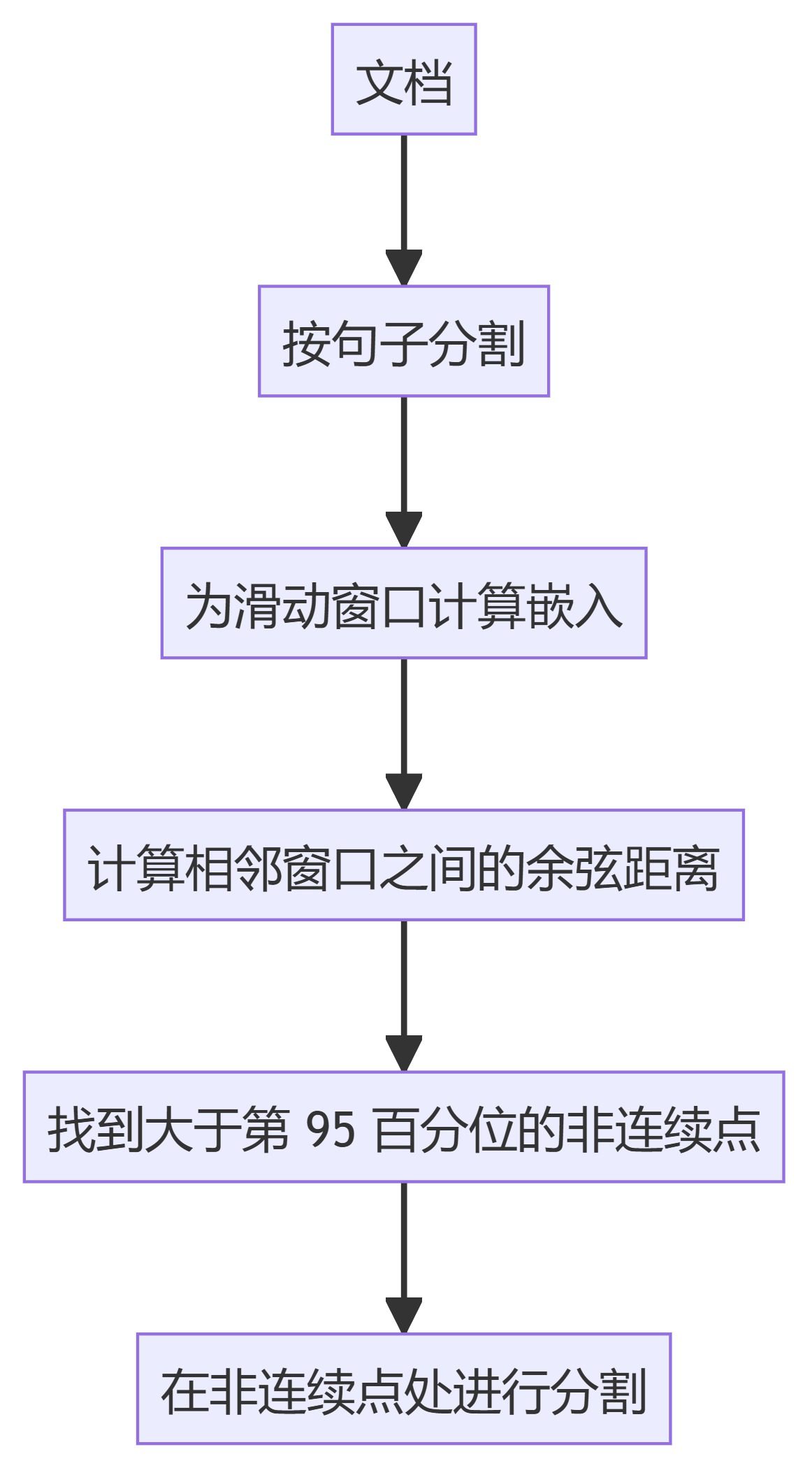
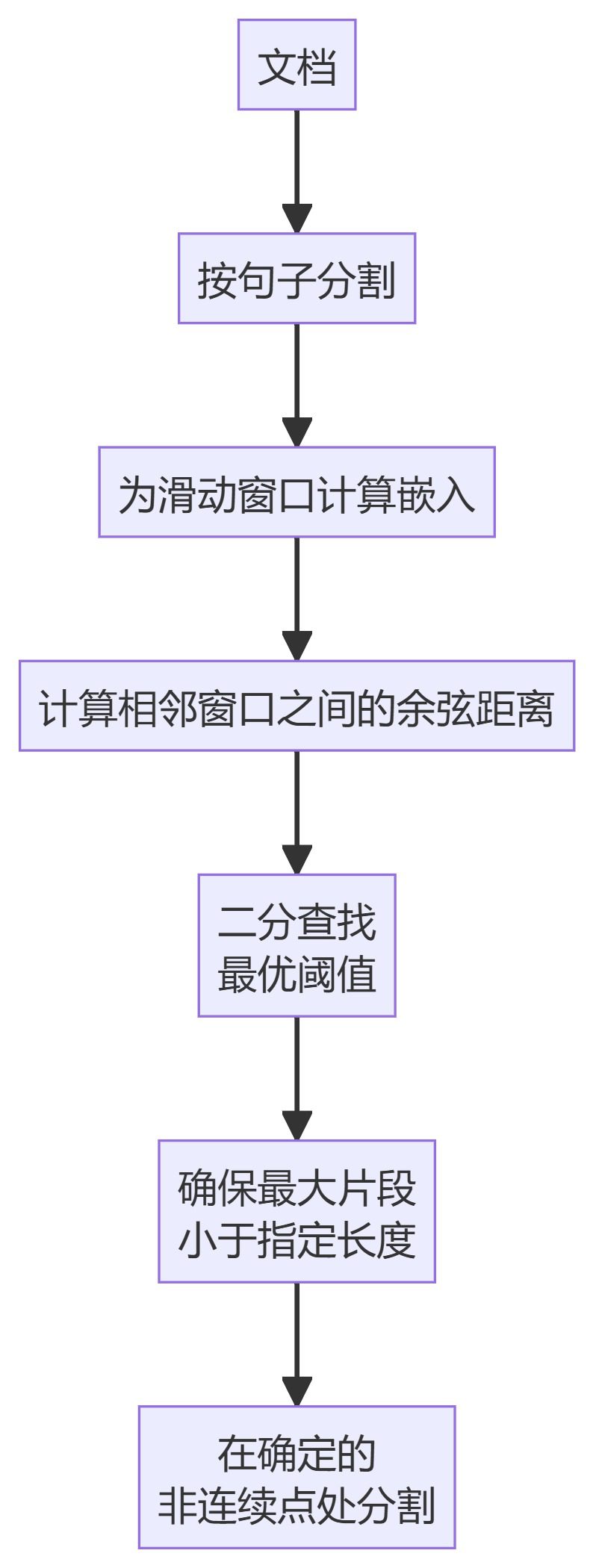
4. KamradtModifiedChunker
5. ClusterSemanticChunker
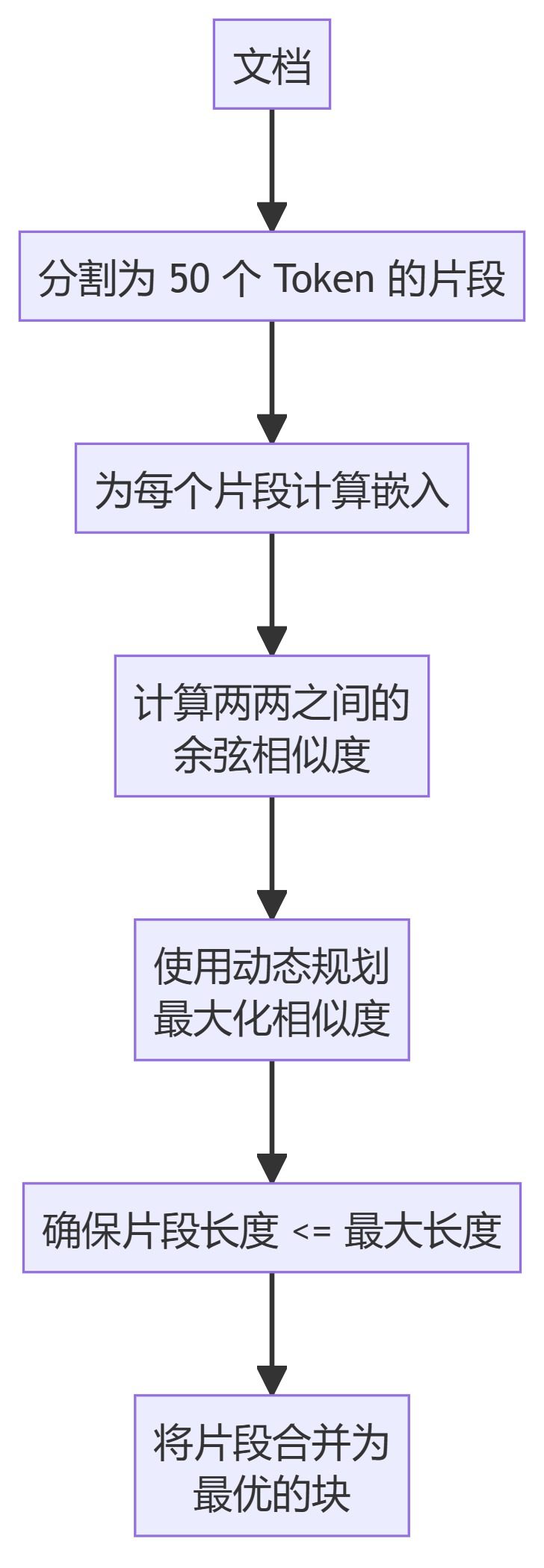
6. LLMSemanticChunker
方法描述
- RecursiveCharacterTextSplitter:基于分隔符的层次结构分割文本,优先考虑文档中的自然断点。
- TokenTextSplitter:将文本分割为固定数量 Token 的块,确保分割发生在 Token 边界。
- KamradtSemanticChunker:使用滑动窗口嵌入识别语义不连续点,并据此分割文本。
- KamradtModifiedChunker:改进版的 KamradtSemanticChunker,使用二分搜索找到分割的最佳阈值。
- ClusterSemanticChunker:将文本分割成小块,计算嵌入,并使用动态规划根据语义相似性创建最优分块。
- LLMSemanticChunker:利用语言模型确定文本中适当的分割点。
使用方法
要在您的 RAG 流程中使用这些分块方法:
- 从
chunkers模块中导入所需的分块器。 - 使用适当的参数初始化分块器(例如,最大分块大小、重叠)。
- 将您的文档传递给分块器以获取分块结果。
示例:
from chunkers import RecursiveCharacterTextSplitter
chunker = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
chunks = chunker.split_text(your_document)
如何选择分块方法
选择分块方法取决于您的具体用例:
- 对于简单的文本分割,可以使用 RecursiveCharacterTextSplitter 或 TokenTextSplitter。
- 如果需要语义感知的分割,可以考虑 KamradtSemanticChunker 或 KamradtModifiedChunker。
- 对于更高级的语义分块,请使用 ClusterSemanticChunker 或 LLMSemanticChunker。
选择方法时需要考虑的因素:
- 文档结构和内容类型
- 所需的分块大小和重叠
- 可用的计算资源
- 检索系统的特定要求(例如,基于向量还是基于关键词)
可以尝试不同的方法,找到最适合您的文档和检索需求的方法。
与 RAG 系统的集成
完成分块后,通常会执行以下步骤:
- 为每个分块生成嵌入(适用于基于向量的检索系统)。
- 在选定的检索系统中索引这些分块(例如,向量数据库、倒排索引)。
- 在回答查询时,使用检索步骤中的索引分块。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章


暂无评论...