

介绍
自查询 RAG(Self-Query RAG) 是一种先进的检索增强生成(RAG)方法,它通过在摄取阶段引入元数据提取以及在检索阶段引入智能查询解析,从而增强了传统 RAG 流程。
https://github.com/adithya-s-k/AI-Engineering.academy/tree/main/RAG/07_Self_Query_RAG
动机
传统的 RAG 系统经常难以处理涉及语义相似性和特定元数据约束的复杂查询。自查询 RAG 通过利用元数据,并使用大语言模型(LLM)智能解析用户查询,解决了这些挑战。
方法详情
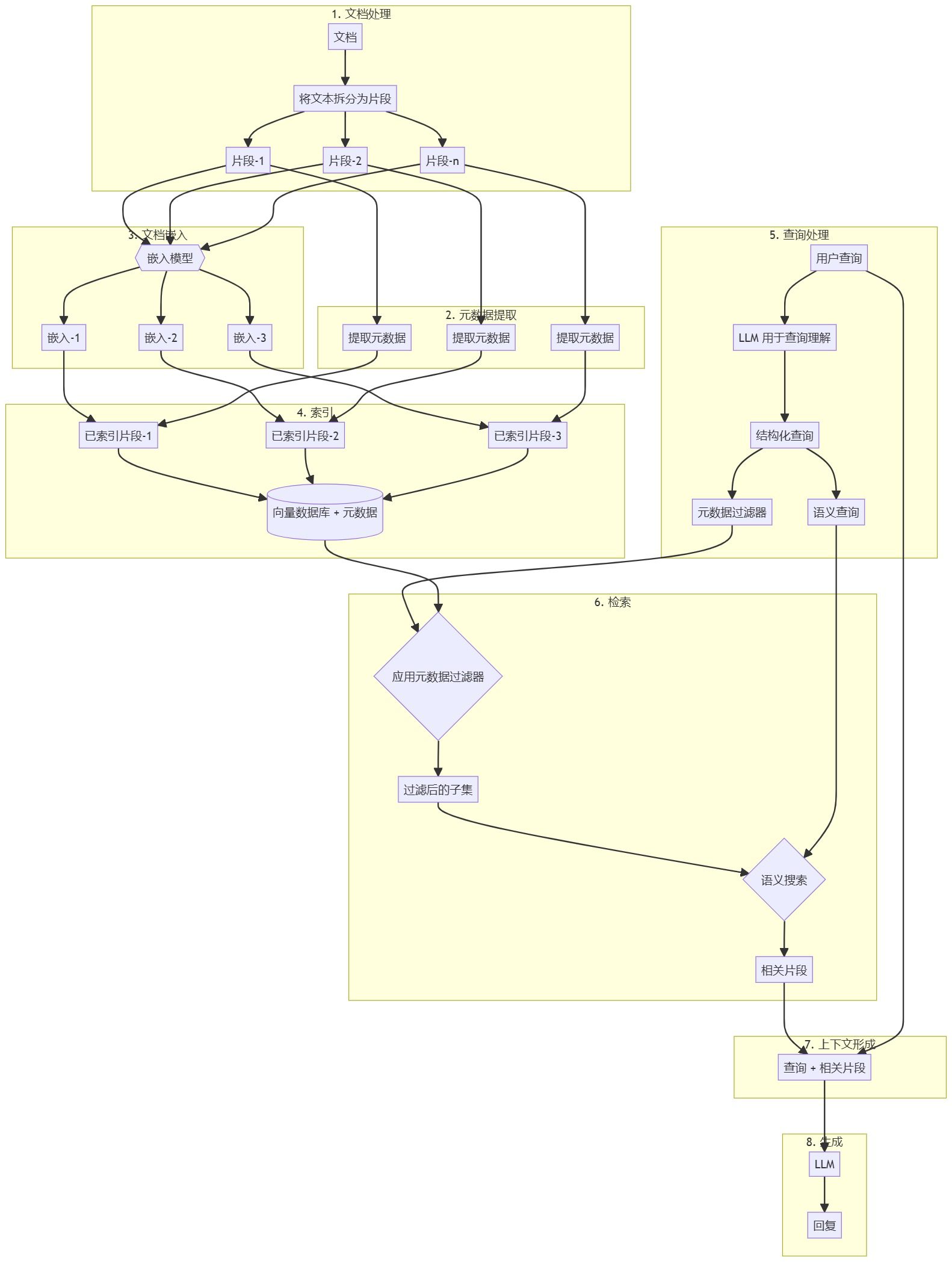
文档预处理和向量存储创建
- 将文档拆分为可管理的小块。
- 从每个小块中提取元数据(例如日期、作者、类别)。
- 使用适当的嵌入模型对每个小块进行嵌入。
- 将小块、其嵌入向量和关联元数据索引到向量数据库中。
自查询 RAG 工作流程
- 用户提交自然语言查询。
- 使用大语言模型(LLM)解析查询以理解用户意图和查询结构。
- LLM 生成:
a) 基于查询的元数据过滤条件。
b) 用于内容相关检索的语义搜索查询。 - 应用元数据过滤器以缩小搜索范围。
- 在过滤后的子集上执行语义搜索。
- 检索到的文档块与用户原始查询结合以形成上下文。
- 将上下文传递给大语言模型(LLM),生成最终回答。
自查询 RAG 的关键特征
- 元数据提取:通过结构化信息增强文档表示。
- 智能查询解析:利用 LLM 理解用户的复杂查询。
- 混合检索:结合元数据过滤和语义搜索。
- 灵活查询:允许用户以自然语言隐式指定元数据约束。
此方法的好处
- 提升检索准确性:元数据过滤器有助于将搜索范围缩小到更相关的文档。
- 处理复杂查询:可以解释并回应涉及内容相似性和元数据约束的查询。
- 高效检索:元数据过滤可以显著减少需要语义搜索的文档数量。
- 增强上下文:元数据提供额外的结构化信息,从而改进响应生成。
结论
自查询 RAG 通过引入元数据提取和智能查询解析,增强了传统 RAG 流程。这种方法使得检索更精准、更高效,尤其适用于涉及语义相似性和特定元数据约束的复杂查询。通过利用大语言模型(LLM)实现查询理解,自查询 RAG 能为 AI 问答系统提供更准确且与上下文相关的响应。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章


暂无评论...