
综合介绍
X-Dyna 是由字节跳动开发的一个开源项目,旨在通过零样本扩散技术生成动态人像动画。该项目利用驱动视频中的面部表情和身体动作来动画化单个人像图像,生成逼真且具有上下文感知的动态效果。X-Dyna 通过引入动态适配器模块,将参考图像的外观上下文无缝集成到扩散骨干网络的空间注意力中,从而增强了人像视频动画的生动性和细节表现力。
相关推荐:StableAnimator:生成高质量保持人物特征的视频动画 、DisPose:生成人体姿态精准控制的视频,创作跳舞的小姐姐 、MOFA Video:运动场适配技术将静态图像转换为视频

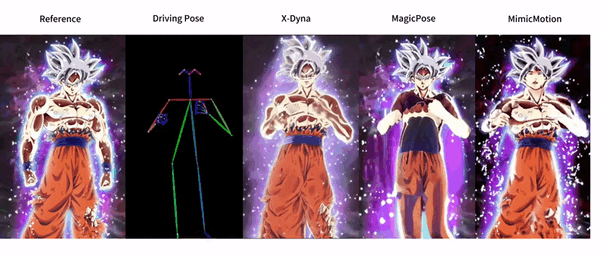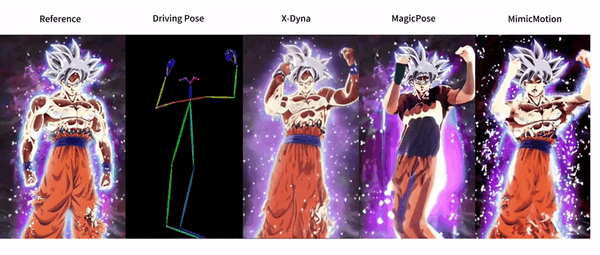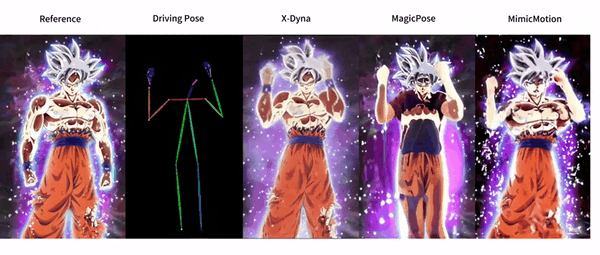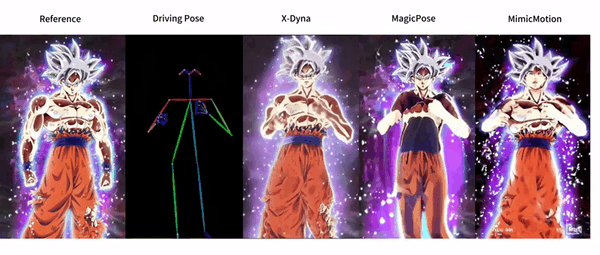
功能列表
- 动态人像动画生成:利用驱动视频中的面部表情和身体动作生成逼真的动态人像动画。
- 零样本扩散技术:无需预先训练数据即可生成高质量动画。
- 动态适配器模块:集成参考图像上下文,增强动画的细节和生动性。
- 面部表情转移:通过本地控制模块捕捉面部表情,实现精确的表情转移。
- 评价代码:提供多种评价指标(如DTFVD、Face-Cos、Face-Det、FID等)用于评估动画质量。
- 开源代码和模型:提供完整的推理代码和预训练模型,方便用户使用和二次开发。
使用帮助
安装流程
- 克隆项目仓库:
git clone https://github.com/bytedance/X-Dyna.git
cd X-Dyna
- 安装依赖:
pip install -r requirements.txt
- 安装 PyTorch 2.0 环境:
bash env_torch2_install.sh
使用方法
- 准备输入图像和驱动视频:
- 输入图像:单个人像图像。
- 驱动视频:包含目标面部表情和身体动作的视频。
- 运行推理代码生成动画:
python inference_xdyna.py --input_image path_to_image --driving_video path_to_video
- 评估生成的动画质量:
- 使用提供的评价代码和数据集评估生成的动画质量。
python evaluate.py --generated_video path_to_generated_video --metrics DTFVD,Face-Cos,Face-Det,FID
详细功能操作流程
- 动态人像动画生成:
- 选择一张静态人像图像作为输入。
- 选择一个包含目标动作和表情的驱动视频。
- 运行推理代码生成动态人像动画。
- 面部表情转移:
- 使用本地控制模块捕捉驱动视频中的面部表情。
- 将捕捉到的表情转移到输入图像中,实现精确的表情动画。
- 动态适配器模块:
- 动态适配器模块将参考图像的外观上下文无缝集成到扩散骨干网络的空间注意力中。
- 通过这种方式,生成的动画能够保留更多的细节和生动性。
- 评价代码:
- 提供多种评价指标(如DTFVD、Face-Cos、Face-Det、FID等)用于评估生成的动画质量。
- 用户可以根据这些指标对生成的动画进行全面评估。
- 开源代码和模型:
- 项目提供完整的推理代码和预训练模型,用户可以方便地进行二次开发和定制化应用。
常见问题:
- 动画不流畅:尝试增加
num_mix或调整ddim_steps。 - 面部表情不匹配:确保选择的
best_frame对应于驱动视频中与源图像表情最相似的帧。
高级使用:
- 优化性能:可以通过使用LCM LoRA模型减少推理步数,从而提高生成速度。
- 自定义模型:如果您有特定的需求,可以根据README中的指导修改或扩展模型。
通过以上步骤,用户可以轻松上手使用 X-Dyna 生成高质量的动态人像动画,并对生成的动画进行全面评估和优化。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章


暂无评论...