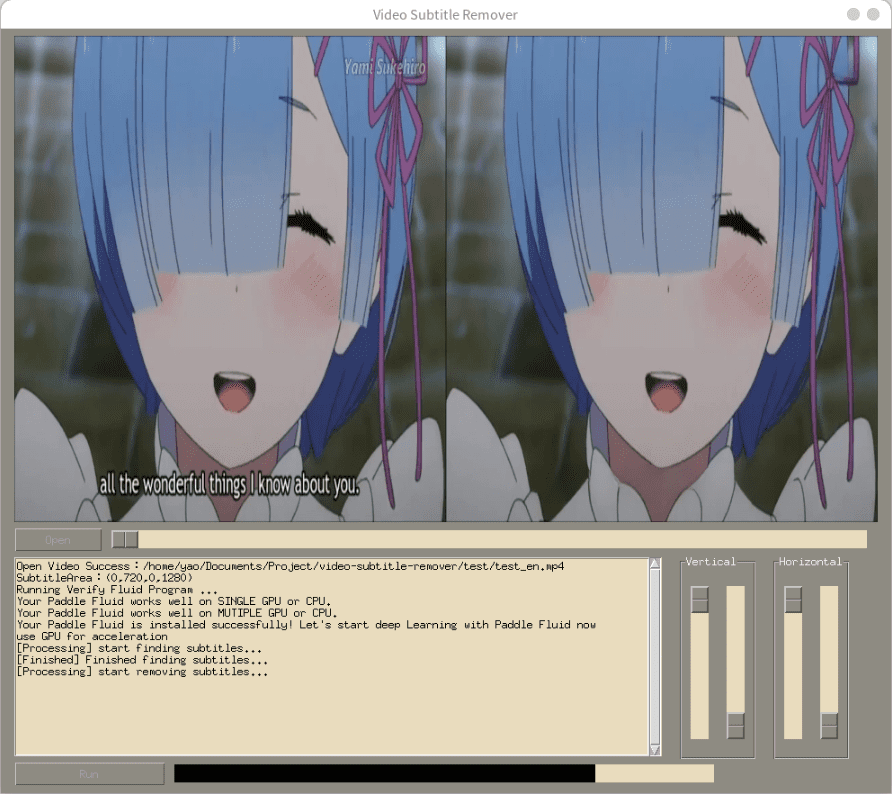

综合介绍
Wav2Lip 是一个开源的高精度口型同步生成工具,旨在将任意音频与视频中的口型进行精准同步。该工具由 Rudrabha Mukhopadhyay 等人在 ACM Multimedia 2020 上发布,利用先进的 AI 技术,能够在各种环境下实现高质量的口型同步。Wav2Lip 适用于研究、学术和个人用途,提供了完整的训练代码、推理代码和预训练模型。
项目已经很久没有迭代,这是一个最近的优化版:Easy-Wav2Lip:高质量视频唇同步的工具,优化版Wav2Lip 。关于 Wav2Lip 如何集成你可以参考 Translation Starter:开源视频内容翻译同步工具|语言转换|唇形同步 。
Wav2Lip 在 Sync Labs 提供免费托管。
Colab笔记:
https://colab.research.google.com/drive/1IjFW1cLevs6Ouyu4Yht4mnR4yeuMqO7Y#scrollTo=Qgo-oaI3JU2u
https://colab.research.google.com/drive/1tZpDWXz49W6wDcTprANRGLo2D_EbD5J8?usp=sharing
功能列表
- 高精度口型同步 :将任意音频与视频中的口型进行精准同步。
- 多语言支持 :适用于各种语言和声音,包括 CGI 面孔和合成声音。
- 开源和免费 :代码完全公开,用户可以自由使用和修改。
- 交互式演示 :提供在线演示,用户可以上传视频和音频文件进行体验。
- 预训练模型 :提供多种预训练模型,用户可以直接使用或进行二次训练。
- 完整的训练代码 :包括口型同步判别器和 Wav2Lip 模型的训练代码。
使用帮助
安装流程
- 克隆仓库 :
bash复制
git clonehttps://github.com/Rudrabha/Wav2Lip
- 安装依赖 :
bash复制
pip install -r requirements.txt
- 下载预训练模型 :将预训练模型下载到指定目录,例如
face_detection/detection/sfd/s3fd.pth。 - 运行推理代码 :
bash复制
python inference.py --checkpoint_path <ckpt> --face <video.mp4> --audio <an-audio-source>
使用流程
- 访问本地服务器 :在浏览器中打开
http://localhost:3000。 - 输入提示 :在输入框中输入你想生成的图像描述,图像会实时生成。
- 查看和下载图像 :生成的图像会显示在页面上,未来版本将添加下载按钮。
- 使用一致性模式 :启用一致性模式以生成一致的图像,保持背景或主要对象的一致性。
- 查看图像历史 :使用图像历史功能查看所有生成的图像,并在它们之间导航。
高级功能
- 增强提示 :使用增强提示选项优化生成结果。
- 选择模型 :根据需要选择不同的AI模型。
- 自定义开发 :由于Wav2Lip是开源的,用户可以根据自己的需求进行二次开发。
Wav2Lip Windows一键安装包(内存优化版)
链接:https://pan.quark.cn/s/4755eabcdf52
提取码:Xr86
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章


暂无评论...