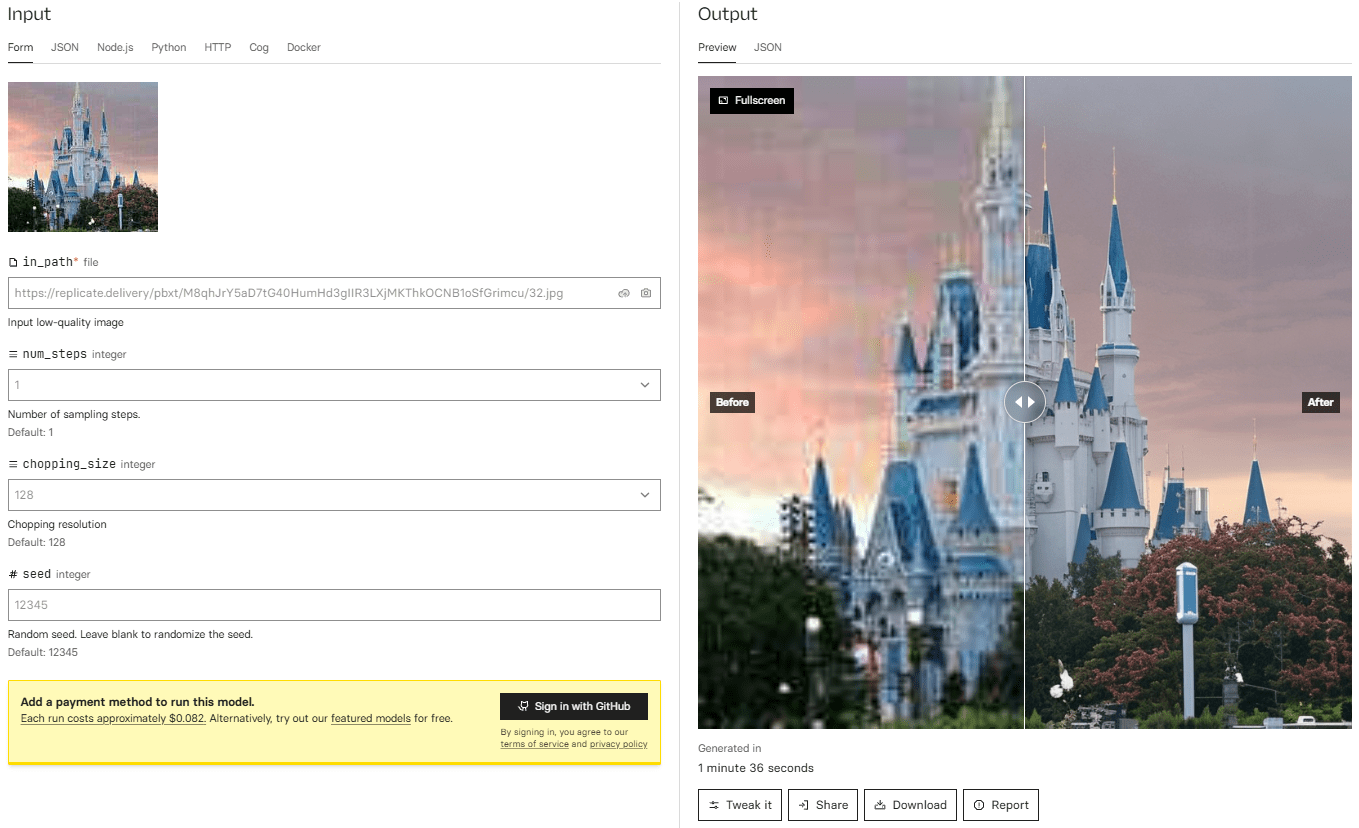

综合介绍
STAR (Spatial-Temporal Augmentation with Text-to-Video Models) 是由南京大学、字节跳动和西南大学联合开发的创新型视频超分辨率框架。该项目致力于解决真实世界视频超分辨率处理中的关键问题,通过结合文本到视频(T2V)扩散模型的先验知识,实现了视频画面的高质量增强。STAR模型的突出特点在于其能够同时保持空间细节的真实性和时序一致性,这在传统的GAN based方法中往往难以兼顾。项目提供了两个版本的实现:基于I2VGen-XL的轻量级和重度降质处理模型,以及基于CogVideoX-5B的重度降质处理模型,能够适应不同场景下的视频增强需求。

功能列表
- 支持多种类型视频降质处理(轻度和重度)的超分辨率重建
- 自动化提示词生成功能,支持使用Pllava等工具生成视频描述
- 提供在线Demo演示平台(HuggingFace Spaces)
- 支持720x480分辨率的视频输入处理
- 提供完整的推理代码和预训练模型
- 集成本地信息增强模块(LIEM),提升画面细节重建质量
- 支持批量视频处理
- 提供灵活的模型权重选择
使用帮助
1. 环境配置
首先需要配置运行环境,具体步骤如下:
- 克隆代码仓库:
git clone https://github.com/NJU-PCALab/STAR.git
cd STAR
- 创建并激活conda环境:
conda create -n star python=3.10
conda activate star
pip install -r requirements.txt
sudo apt-get update && apt-get install ffmpeg libsm6 libxext6 -y
2. 模型选择和下载
STAR提供了两种版本的模型:
- I2VGen-XL based模型:
- light_deg.pt:适用于轻度降质视频处理
- heavy_deg.pt:适用于重度降质视频处理
- CogVideoX-5B based模型:
- 专门用于处理重度降质视频
- 仅支持720x480分辨率输入
从HuggingFace下载相应模型权重并放置在pretrained_weight/目录下。
3. 视频处理流程
- 准备测试数据:
- 将待处理视频放入
input/video/目录 - 提示词准备(三种选择):
- 无提示词
- 使用Pllava自动生成
- 手动编写视频描述
- 将待处理视频放入
- 配置处理参数:
- 修改
video_super_resolution/scripts/inference_sr.sh中的路径配置:- video_folder_path:输入视频路径
- txt_file_path:提示词文件路径
- model_path:模型权重路径
- save_dir:输出保存路径
- 修改
- 启动推理:
bash video_super_resolution/scripts/inference_sr.sh
注意:如遇到内存溢出(OOM)问题,可以在inference_sr.sh中调小frame_length参数。
4. CogVideoX-5B模型特殊配置
如果使用CogVideoX-5B模型,需要额外步骤:
- 创建专用环境:
conda create -n star_cog python=3.10
conda activate star_cog
cd cogvideox-based/sat
pip install -r requirements.txt
- 下载额外依赖:
- 需要下载VAE和T5 Encoder
- 更新
cogvideox-based/sat/configs/cogvideox_5b/cogvideox_5b_infer_sr.yaml中的路径配置 - 替换transformer.py文件
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章

暂无评论...