
综合介绍
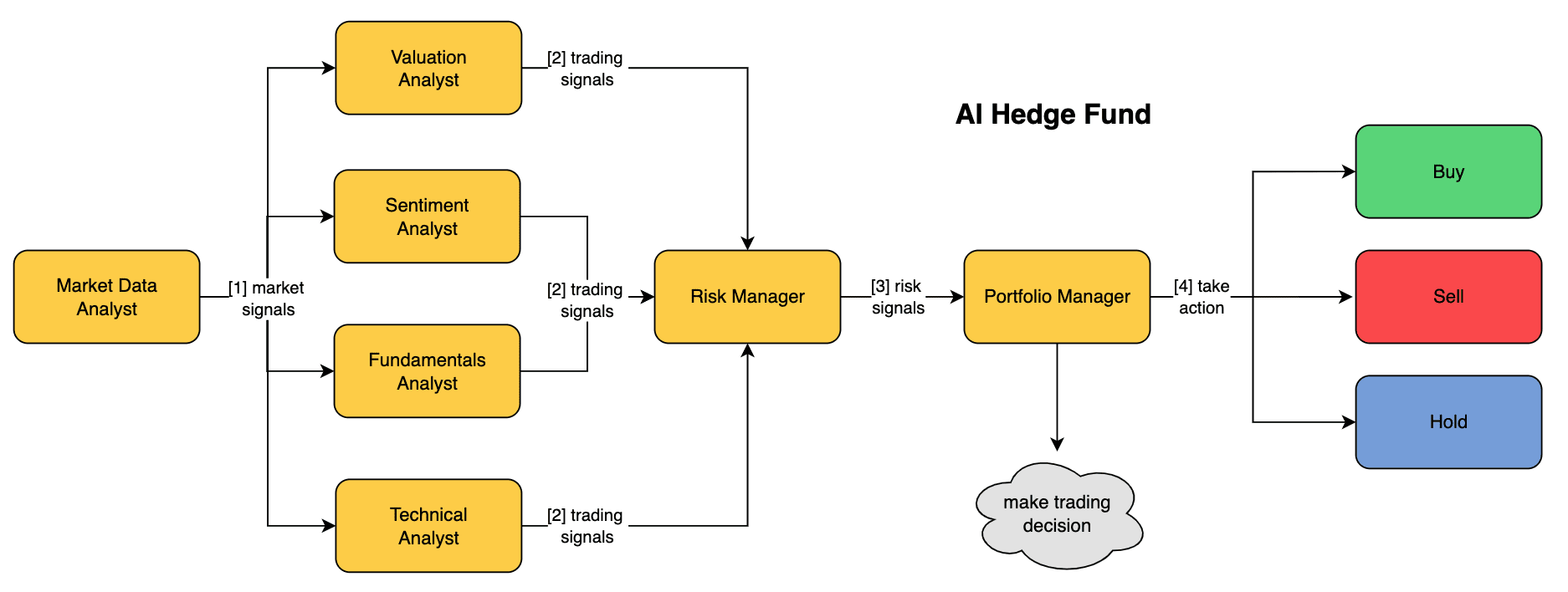
StableAnimator 是一个创新的端到端身份保留视频扩散框架,能够在不进行任何后期处理的情况下,基于参考图像和一系列姿势合成高质量的视频。该项目由 Fudan University、Microsoft Research Asia、Huya Inc 和 Carnegie Mellon University 的研究人员合作开发。StableAnimator 通过引入全局内容感知面部编码器和分布感知身份适配器,确保了视频中的身份一致性。该框架在多个基准测试中表现出色,能够生成高保真、身份保留的人像动画。

功能列表
- 身份保留视频生成:基于参考图像和姿势序列生成高质量的视频,确保身份一致性。
- 无后期处理:生成的视频无需使用任何面部交换工具或面部修复模型进行后期处理。
- 全局内容感知面部编码器:通过与图像嵌入交互,进一步优化面部嵌入。
- 分布感知身份适配器:在保持身份一致性的同时,防止时间层干扰。
- Hamilton-Jacobi-Bellman 优化:在推理过程中,通过求解 HJB 方程进一步增强面部质量。
使用帮助
安装流程
- 克隆仓库:在终端中运行以下命令克隆 StableAnimator 仓库:
git clone https://github.com/Francis-Rings/StableAnimator.git
- 安装依赖:进入仓库目录并安装所需依赖:
cd StableAnimator
pip install -r requirements.txt
- 运行应用:使用以下命令启动应用:
python app.py
使用流程
- 准备参考图像和姿势序列:确保你有一张参考图像和一系列姿势图像,这些图像将用于生成动画。
- 运行推理脚本:使用以下命令运行推理脚本,生成视频动画:
python inference_basic.py --reference_image path_to_reference_image --pose_sequence path_to_pose_sequence
- 查看生成结果:生成的视频将保存在指定的输出目录中,你可以使用任何视频播放器查看结果。
详细功能操作
- 身份保留视频生成:通过提供参考图像和姿势序列,StableAnimator 能够生成高质量的视频动画,确保视频中的人物身份与参考图像一致。
- 全局内容感知面部编码器:该模块通过与图像嵌入交互,进一步优化面部嵌入,确保生成的视频中面部细节的高保真度。
- 分布感知身份适配器:在生成视频的过程中,该模块通过对齐技术,防止时间层干扰,确保视频中的身份一致性。
- Hamilton-Jacobi-Bellman 优化:在推理过程中,通过求解 HJB 方程,进一步增强生成视频中面部的质量和一致性。
© 版权声明
文章版权归 AI分享圈 所有,未经允许请勿转载。
相关文章


暂无评论...