
Статья, которая поможет вам понять RAG (Retrieval Augmented Generation), концепцию теоретического введения + кодовую практику.

I. У LLM уже есть сильные возможности, зачем нам нужен RAG (Retrieval Augmentation Generation)?
Несмотря на то, что LLM продемонстрировала значительные возможности, ряд проблем по-прежнему вызывает озабоченность:
- Проблема иллюзии: LLM использует статистический вероятностный подход для генерации текста слово за словом, механизм, который по своей сути приводит к возможности получения результатов, которые кажутся логически строгими, но не основаны на фактах, так называемые "торжественные вымышленные заявления";
- (a) Проблемы своевременности: по мере расширения LLM увеличиваются затраты и циклы обучения. В результате данные, содержащие актуальную информацию, трудно включить в процесс обучения модели, что делает LLM менее способным справляться с такими чувствительными к времени вопросами, как "предложите, пожалуйста, текущий любимый фильм";
- Вопросы безопасности данных: в общих LLM нет внутренних данных предприятия и данных пользователей, поэтому предприятиям, желающим использовать LLM в целях обеспечения безопасности, лучше всего размещать все данные локально, а все бизнес-расчеты данных предприятия производить локально. Большая онлайн-модель выполняет только функцию обобщения;
II. Представляем вам RAG?
RAG (Retrieval Augmented Generation) - это технологическая схема, суть которой заключается в том, что когда перед LLM стоит задача ответить на вопрос или создать текст, LLM сначала проводит поиск в масштабной библиотеке документов и отфильтровывает материалы, тесно связанные с задачей, а затем точно направляет последующий процесс генерации ответа или построения текста на основе этих материалов, с целью повышения точности и надежности выводимой таким образом модели. Цель состоит в том, чтобы таким образом повысить точность и надежность результатов работы модели.
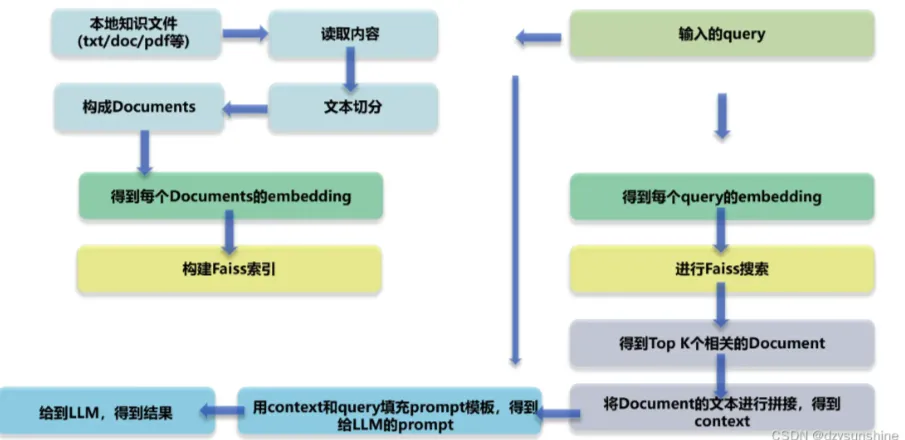
RAG Диаграмма технической архитектуры
III. Каковы основные модули RAG?
- Модуль 1: Анализ макета
- Чтение файлов со знанием местности (pdf, txt, html, doc, excel, png, jpg, голос и т.д.)
- Восстановление документов знаний
- Модуль II: Создание базы знаний
- Сегментация текста и построение текста док
- Встраивание текста в док
- Doc Text Build Index
- Модуль 3: Тонкая настройка Большой модели
- Модуль IV: Контрольная работа по знаниям на основе RAG
- Встраивание пользовательских запросов
- запрос Отзыв
- сортировка запросов
- K наиболее релевантных документов были объединены для создания контекста
- Создание подсказок на основе запроса и контекста
- Отправьте подсказку в большую модель, чтобы сгенерировать ответ
В чем преимущества RAG по сравнению с использованием LLM непосредственно для тестирования?
Подход RAG (Retrieval Augmented Generation) позволяет разработчикам значительно повысить точность ответов без необходимости заново обучать большие модели для каждой конкретной задачи, просто подключившись к внешней базе знаний, в которую можно вводить дополнительные информационные ресурсы. Такой подход особенно подходит для задач, которые сильно зависят от опыта. Ниже перечислены основные преимущества модели RAG:
- Масштабируемость: уменьшение размера модели и накладных расходов на обучение, а также упрощение процесса расширения и обновления базы знаний.
- Точность: благодаря ссылкам на источники пользователи могут проверить достоверность ответов, что, в свою очередь, повышает их доверие к выходным результатам модели.
- Управляемость: поддерживает гибкое обновление и персонализированную настройку содержания знаний.
- Интерпретируемость: покажите поисковые записи, от которых зависят предсказания модели, улучшая понимание и прозрачность.
- Универсальность: RAG может быть тонко настроен и адаптирован к широкому спектру сценариев применения, охватывая такие области, как вопросы и ответы, обобщение текста и диалоговые системы.
- Своевременность: использование методов поиска для получения самой свежей информации обеспечивает оперативность и точность ответов, что является явным преимуществом по сравнению с языковыми моделями, которые полагаются только на внутренние данные обучения.
- Настройка под конкретную отрасль: сопоставляя наборы текстовых данных с конкретными отраслями или сферами, RAG может обеспечить целевую экспертную поддержку.
- Безопасность: реализуя разделение ролей и контроль безопасности на уровне базы данных, RAG эффективно усиливает управление использованием данных, демонстрируя более высокую безопасность, чем потенциальная неоднозначность моделей тонкой настройки для управления правами на данные.
V. Сравните и сопоставьте RAG и SFT и расскажите, в чем заключаются различия?
Фактически, SFT является одним из наиболее распространенных и базовых решений вышеупомянутых проблем LLM, а также фундаментальным шагом в реализации приложений LLM. Далее необходимо сравнить эти два подхода по нескольким параметрам:
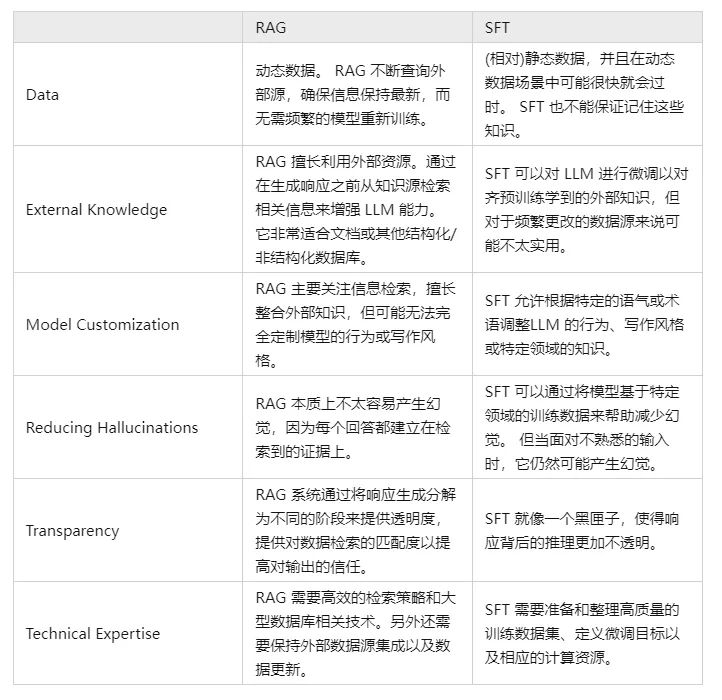
Разумеется, эти два метода не являются "или-или", и разумно и необходимо сочетать потребности бизнеса с преимуществами обоих методов и использовать их разумным образом.
Модуль 1: Анализ макета
Зачем мне нужен анализ планировки?
Хотя основная ценность технологии RAG (Retrieval Augmented Generation) заключается в сочетании поиска и генерации для повышения точности и связности текстового контента, ее функциональные границы могут быть расширены за счет анализа компоновки в конкретных областях применения, таких как разбор документов, интеллектуальный авторский поиск и построение диалогов, особенно когда необходимо обрабатывать структурированную или полуструктурированную информацию.
Это связано с тем, что подобная информация часто встраивается в определенную структуру макета и требует глубокого понимания элементов страницы и их взаимосвязей.
Кроме того, когда модель RAG сталкивается с источниками данных, содержащими богатые мультимедийные или мультимодальные компоненты, такие как веб-страницы, PDF-файлы, текстовые записи, документы Word, изображения, голосовые клипы, табличные данные и другой сложный контент, становится крайне важно иметь базовые возможности анализа макета, чтобы эффективно воспринимать и использовать такую нетекстовую информацию. Эта способность помогает модели точно анализировать различные информационные единицы и успешно интегрировать их в осмысленную общую интерпретацию.
шаг 1: сбор документов о местных знаниях
q1: Как собрать документы, содержащие местные знания?
Доступ к файлам локальных знаний включает в себя процесс извлечения информации из различных источников данных (например, .txt, .pdf, .html, .doc, .xlsx, .png, .jpg, аудиофайлов и т. д.). Для разных типов файлов необходимы особые стратегии доступа и разбора, чтобы эффективно получать содержащиеся в них знания. Далее мы расскажем о методах доступа и трудностях для различных источников данных.
q2: Как получить содержимое богатого текста txt?
- Введение: насыщенный текст в основном хранится в txt-файле, потому что макет относительно аккуратный, поэтому способ получения относительно прост
- Практические навыки:
- [Анализ макета - чтение насыщенного текста txt].
q3: Как получить содержимое PDF-документа?
- Введение: PDF документы в данных является более сложным, в том числе текст, изображения, таблицы и другие различные стили данных, поэтому процесс разбора будет более сложным!
- Практические навыки:
- [Анализ макета--PDF парсинг магия pdfplumber
- Анализ макета - парсер PDF PyMuPDF
q4: Как получить содержимое HTML-документа?
- Введение: PDF документы в данных является более сложным, в том числе текст, изображения, таблицы и другие различные стили данных, поэтому процесс разбора будет более сложным!
- Практические навыки:
- Анализ макета - парсинг HTML BeautifulSoup
q5: Как получить содержимое документа Doc?
- Введение: данные документа Doc стали более сложными, включая текст, изображения, таблицы и другие различные стили данных, поэтому процесс разбора будет более сложным!
- Практические навыки:
- Анализ макета - артефакт python-docx для разбора документов].
q6: Как использовать OCR для получения содержимого изображения?
- Введение: оптическое распознавание символов (OCR). Персонаж Распознавание, OCR) - это процесс анализа и распознавания файлов изображений с текстовой информацией для получения текстовой информации и информации о макете. Это также означает, что текст на изображении распознается и возвращается в виде текста.
- Мысли:
- Распознавание текста: распознавание хорошо расположенных текстовых областей, основной задачей является решение проблемы того, что представляет собой каждый текст, текстовая область на изображении в преобразовании символьной информации.
- Обнаружение текста: решается проблема, где находится текст и каков его объем;
- Текущий проект OCR с открытым исходным кодом
- Тессеракт
- PaddleOCR
- EasyOCR
- китаевед
- китайский демократ
- TrWebOCR
- cnocr
- hn_ocr
- Теоретические исследования:
- Анализ макета - инструмент разбора изображений OCR]
- Практические навыки:
- [Анализ макета - тессеракт OCR].
- [Анализ макета - OCR Magic PaddleOCR]
- [Анализ макета - артефакты OCR hn_ocr]
q7: Как использовать ASR для получения содержания речи?
- Псевдоним: Автоматическое распознавание речи AutomaTlc Speech RecogniTlon, (ASR)
- Введение: Преобразование речевого сигнала в соответствующее текстовое сообщение - это как "слуховая система машины", которая позволяет машине преобразовывать речевой сигнал в соответствующий текст или команду посредством распознавания и понимания.
- Цель: преобразование лексического содержания человеческой речи в читаемый компьютером ввод (например, нажатие клавиш, двоичные коды или последовательности символов).
- Мысли:
- Предварительная обработка акустического сигнала: для более эффективного извлечения признаков часто также требуется фильтрация захваченного звукового сигнала, кадрирование и другие предварительные обработки, сигнал, который будет анализироваться на основе извлечения исходного сигнала;
- Извлечение признаков: преобразование звукового сигнала из временной области в частотную, чтобы получить подходящие векторы признаков для акустической модели.
- Акустическое моделирование: расчет баллов для каждого вектора признаков по акустическим характеристикам, основанным на акустических свойствах;.
- Моделирование языка: вычисление вероятности того, что звуковой сигнал соответствует последовательности возможных фраз, на основе лингвистически значимых теорий.
- Словарь и декодирование: на основе имеющегося словаря последовательность фраз декодируется для получения окончательного возможного представления текста
- Теоретический самоучитель:
- Распознавание речи для анализа макета
- Практические навыки:
- [Анализ речевого оформления текста].
- Анализ макета WeTextProcessing
- [Анализ макета - ASR инструмент Wenet].
- Анализ макета Обучение ASR
шаг 2: восстановление документов знаний
q1: Зачем нужно восстановление документов знаний?
Получение документов с локальными знаниями содержит после прочтения данных из нескольких источников (txt, pdf, html, doc, excel, png, jpg, голос и т.д.), легко разбить многострочный абзац на несколько абзацев, что приводит к тому, что абзацы встречаются разделенными, поэтому необходимо заново организовать абзацы в соответствии с логикой содержания.
q2: Как восстановить документы, содержащие знания?
- Методология I: восстановление документов знаний на основе правил
- Метод 2: Контекстное сращивание на основе Bert NSP
Шаг 3: Анализ макета - стратегии оптимизации
- Теоретические исследования:
- [Анализ макета - стратегии оптимизации].
шаг 4: Домашнее задание
- Описание задания: Используйте описанную выше методологию для анализа макета данных [ChatGLM Evaluation Challenge - Finance track dataset] в рамках [SMP 2023 ChatGLM Finance Big Model Challenge].
- Эффективность задачи: анализ эффективности и результативности различных методов
Модуль II: Создание базы знаний
Зачем вам нужно создание базы знаний?
Создание базы знаний в RAG (Retrieval-Augmented Generation) очень важно по нескольким причинам, включая, но не ограничиваясь, следующими:
- Расширение возможностей модели: хотя крупномасштабные языковые модели, такие как семейство GPT, обладают мощными возможностями генерации и понимания языка, их возможности ограничены набором обучающих данных, и они не могут точно ответить на некоторые вопросы, основанные на конкретных фактах или подробной справочной информации. Создавая базу знаний, RAG может дополнить ограниченные знания модели, позволяя ей извлекать самую свежую и точную информацию для создания ответов.
- Обновление информации в режиме реального времени: база знаний может обновляться и расширяться в режиме реального времени, чтобы обеспечить доступ модели к последнему содержанию знаний, что особенно важно при работе с информацией, чувствительной ко времени, такой как новостные события, научно-технические достижения и так далее.
- Повышенная точность: RAG объединяет процессы поиска и генерации информации, что позволяет повысить точность ответов на вопросы за счет поиска релевантных документов перед генерацией ответов. Таким образом, ответы, генерируемые моделью, основываются не только на ее внутренних параметризованных знаниях, но и на внешней базе знаний, состоящей из надежных источников.
- Уменьшение избыточной подгонки и галлюцинаций: большие модели иногда страдают от чрезмерной зависимости от внутренних закономерностей и подвержены галлюцинациям, т. е. генерируют ответы, которые кажутся разумными, но не являются таковыми. RAG может снизить вероятность таких ошибок, приводя окончательные доказательства из базы знаний.
- Повышенная интерпретируемость: RAG не только дает ответ, но и указывает на источник ответа, повышая прозрачность и достоверность результатов, полученных с помощью модели.
- Поддержка персонализации и приватизации: предприятия или индивидуальные пользователи могут создавать эксклюзивные базы знаний для удовлетворения потребностей конкретных областей или частной персонализации, делая большую модель более подходящей для конкретных сценариев и предприятий.
Таким образом, создание базы знаний является одним из основных механизмов, позволяющих моделям RAG добиваться эффективного и точного поиска и генерации ответов, что значительно повышает производительность и надежность модели в практических приложениях.
шаг 1: разбивка текста на части
- Зачем мне нужно разбивать текст на куски?
- Риск упустить информацию: попытка извлечь векторы встраивания для всего документа сразу, хотя и захватывает общий контекст, может также упустить много важной информации, относящейся к конкретной теме, что может привести к созданию менее точной или отсутствующей информации.
- Ограничение размера чанка: размер чанка является ключевым ограничивающим фактором при использовании таких моделей, как OpenAI. Например, модель GPT-4 имеет ограничение на размер окна в 32К. Хотя в большинстве случаев это ограничение не является проблемой, важно учитывать размер чанка с самого начала.
- Необходимо учитывать два основных фактора:
- Случай ограничения токенов для моделей встраивания;
- Влияние семантической целостности на общую эффективность поиска;
- Практические навыки:
- [Построение базы знаний - разбивка текста на части].
- [Построение базы знаний - стратегии оптимизации нарезки и нарезки документов]
шаг 2: Векторизация доксов (эмбедирование)
q1: Что такое векторизация Docs (embdeeing)?
Встраивание - это также информационно насыщенное представление семантического смысла текста, где каждое встраивание - это вектор чисел с плавающей точкой, причем расстояние между двумя встраиваниями в векторном пространстве коррелирует с семантическим сходством между двумя исходными текстами в оригинальном формате. Например, если два текста похожи, их векторные представления также должны быть похожи, и этот набор массивов представлений в векторном пространстве описывает тонкие различия между текстами. Проще говоря, встраивание помогает компьютерам понять "смысл" человеческой информации. Встраивание может быть использовано для получения "релевантности" признаков в тексте, изображениях, видео или другой информации, что обычно используется на прикладном уровне в поиске, рекомендациях, классификации и других приложениях. Этот вид корреляции широко используется в поиске, рекомендациях, классификации и кластеризации.
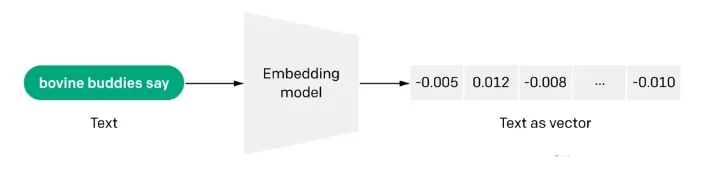
q2: Как работает встраивание?
В качестве примера приведем три предложения:
- "Кошка гонится за мышкой".
- "Котенок охотится на грызунов".
- "Я люблю сэндвичи с ветчиной". Я люблю сэндвичи с ветчиной.
Если бы люди классифицировали эти три предложения, то предложение 1 и предложение 2 имели бы почти одинаковый смысл, а предложение 3 - совершенно разный. Но мы видим, что в оригинальных английских предложениях в предложении 1 и предложении 2 одинаково только слово "The", и нет других одинаковых слов. Как компьютер может понять значение первых двух предложений? Встраивание сжимает дискретную информацию (слова и символы) в распределенные данные с непрерывными значениями (векторы). Если бы мы изобразили предыдущую фразу на графике, это выглядело бы примерно так:
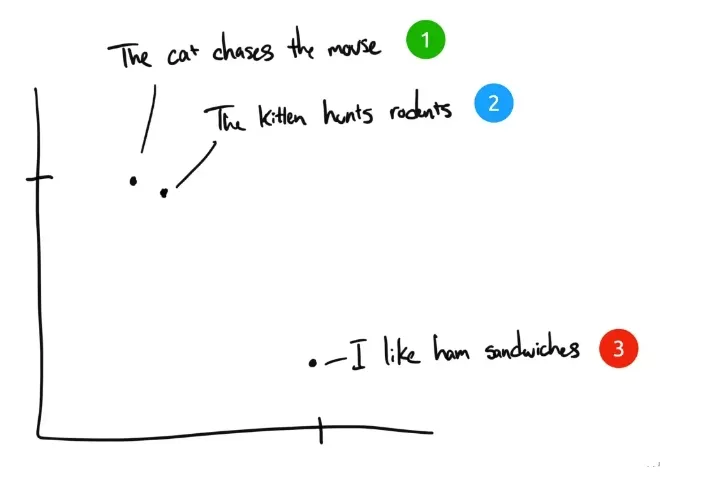
После сжатия текста в понятное компьютеру многомерное векторное пространство предложения 1 и 2 располагаются рядом друг с другом, поскольку имеют схожие смыслы. Предложение 3 находится дальше, потому что оно не связано с ними. Если бы у нас была четвертая фраза, "Салли ела швейцарский сыр", она, вероятно, находилась бы где-то между предложением 3 (сыр идет на сэндвичи) и предложением 1 (мыши любят швейцарский сыр).
q3: Преимущества подхода семантического поиска Embedding по сравнению с поиском по ключевым словам?
- Семантическое понимание: методы поиска на основе вкраплений представляют текст в виде векторов слов, что позволяет модели улавливать семантические ассоциации между словами, в отличие от поиска на основе ключевых слов, который, как правило, фокусируется на буквальном совпадении и может игнорировать семантические связи между словами.
- Устойчивость к ошибкам: поскольку методы, основанные на вкраплениях, способны понять взаимосвязь между словами, они лучше справляются с такими случаями, как орфографические ошибки, синонимы и близкие синонимы. В то время как методы поиска по ключевым словам относительно слабо справляются с такими случаями.
- Поддержка нескольких языков: многие методы встраивания поддерживают несколько языков, что помогает осуществлять межъязыковой поиск текста. Например, вы можете использовать китайский ввод для запроса английского текста, в то время как методы поиска по ключевым словам затруднены.
- Понимание контекста: методы, основанные на вкраплениях, более выгодны в случае многозначности слова, поскольку они способны присваивать словам различные векторные представления в зависимости от контекста. В то время как методы поиска, основанные на ключевых словах, могут быть не в состоянии хорошо различать значение одного и того же слова в разных контекстах.
q4: Каковы ограничения поиска встраивания?
- Ограничения на количество входных слов: даже если с помощью технологии встраивания в крупномасштабную модель выбираются фрагменты текста, наиболее соответствующие запросу, ограничение на количество словарного запаса все равно существует. Когда поиск охватывает широкий диапазон текстов, для контроля количества контекстной лексики, вводимой в модель, обычно устанавливается порог TopK K для результатов поиска, но это неизбежно приводит к проблеме пропуска информации.
- Только текстовые данные: GPT-3.5 и многие крупномасштабные языковые модели на данном этапе еще не обладают возможностями распознавания изображений, однако в процессе поиска знаний для полного понимания многих ключевых сведений часто требуется сочетание графики и текста. Например, трудно точно понять смысл схематических диаграмм в научных статьях и графиков данных в финансовых отчетах, основываясь только на тексте.
- (b) Импровизация большой модели: когда найденной литературы недостаточно, чтобы поддержать большую модель для точного ответа на вопрос, модель может быть подвергнута определенной степени "импровизации", то есть предположениям и дополнениям, основанным на ограниченной информации, для того чтобы завершить ответ в меру своих возможностей.
- Теоретические исследования:
- [Создание базы знаний - Векторизация доков].
- Практические навыки:
- [Docs Vectorisation - Tencent Word Vector]
- [Docs vectorisation - sbt].
- [Docs vectorisation - SimCSE]
- [Docs векторизация - text2vec].
- [Docs vectorisation - SGPT]
- [Docs векторизация -- BGE -- Smart Source с открытым исходным кодом самая сильная семантическая векторная модель].
- [Docs vectorisation - M3E: крупномасштабное гибридное встраивание].
шаг 3: Создание индекса документов
- представить (кого-л. на работу и т.д.)
- Практические навыки:
- [Docs build index - Faiss].
- [Docs build index - milvus].
- [Docs Building Indexes - Elasticsearch]
Модуль 3: Тонкая настройка Большой модели
Зачем нам нужна точная настройка больших моделей?
Как правило, существует несколько причин для тонкой настройки большой модели:
- Первая причина заключается в том, что, поскольку количество параметров в большой модели очень велико, стоимость ее обучения очень высока, и каждая компания занимается обучением большой модели с нуля, что очень неэффективно с точки зрения затрат;
- Вторая причина заключается в том, что подход Prompt Engineering - это относительно простой способ начать работу с большими моделями, но у него есть очевидные недостатки. Поскольку обычно принципы реализации больших моделей имеют ограничения на длину входной последовательности, подход Prompt Engineering может сделать Prompt очень длинным.
Чем длиннее Prompt, тем выше стоимость вывода большой модели, поскольку стоимость вывода положительно коррелирует с квадратом длины Prompt. Кроме того, слишком длинный Prompt будет обрезан, поскольку он превышает предел, что, в свою очередь, приведет к снижению качества вывода большой модели. Для индивидуальных пользователей, если они решают некоторые проблемы в своей повседневной жизни и работе, обычно не представляет большой проблемы использовать Prompt Engineering напрямую. Однако для предприятий, предоставляющих услуги внешнему миру, чтобы получить доступ к возможностям больших моделей в своих собственных сервисах, стоимость обоснования является фактором, который необходимо учитывать, и тонкая настройка является относительно лучшим решением.
- Третья причина заключается в том, что эффект от Prompt Engineering не соответствует требованиям, а у предприятия есть более качественные собственные данные, которые можно использовать для более эффективного расширения возможностей большой модели в конкретной области. В этом случае тонкая настройка будет очень кстати.
- Четвертая причина - использование возможностей больших моделей в персонализированных сервисах, когда обучение легкой точно настроенной модели для данных каждого пользователя является хорошим решением.
- Пятая причина - безопасность данных. Если данные не планируется передавать стороннему сервису больших моделей, то создание собственной большой модели очень необходимо. Обычно такие большие модели с открытым исходным кодом нуждаются в тонкой настройке на основе собственных данных, чтобы удовлетворить потребности бизнеса.
Как точно настроить большую модель?
q1: Вопрос тонкой настройки технических маршрутов для больших моделей
Тонкая настройка больших моделей с точки зрения масштаба параметров разделена на два технических направления:
- Технический маршрут 1: Для полного количества параметров, полного количества обучения, этот путь называется полной точной настройкой FFT (Full Fine Tuning).
- Технический маршрут II: обучению подвергаются только некоторые параметры, этот путь называется PEFT (Parameter-Efficient Fine Tuning).
q2: Какие проблемы возникают при использовании техники полнообъемного БПФ с тонкой настройкой для больших моделей
FFT также приносит некоторые проблемы, наиболее значимые, две основные из которых следующие:
- Проблема 1: Стоимость обучения будет выше, поскольку количество параметров для тонкой настройки такое же, как и для предварительного обучения;
- Проблема 2: Катастрофическое забывание (Catastrophic Forgetting), когда тонкая настройка с использованием конкретных обучающих данных может улучшить производительность в этой области, но при этом ухудшить способность работать в других областях, в которых производительность была высокой.
q3: Какие проблемы решает PEFT (Parameter-Efficient Fine Tuning) для больших моделей?
Основная проблема, которую хочет решить PEFT, - это две вышеупомянутые проблемы FFT, и PEFT также является более распространенной программой тонкой настройки в настоящее время. С точки зрения источника обучающих данных, а также метода обучения, существует несколько технических путей для тонкой настройки больших моделей:
- Технический маршрут 1: Supervised Fine Tuning SFT (Supervised Fine Tuning), эта схема фокусируется на тонкой настройке больших моделей с помощью данных, помеченных вручную, используя традиционный подход к машинному обучению с супервизией;
- Технический маршрут II: обучение с подкреплением и человеческой обратной связью (RLHF), основная особенность этой схемы заключается в том, чтобы ввести человеческую обратную связь, путем обучения с подкреплением, в тонкую настройку большой модели, чтобы результаты, генерируемые большой моделью, в большей степени соответствовали некоторым ожиданиям человека;
- Технологический маршрут III: Reinforcement Learning with AI Feedback (RLAIF), принцип примерно похож на RLHF, но источником обратной связи является ИИ. Здесь пытаются решить проблему эффективности системы обратной связи, поскольку сбор человеческих отзывов, относительно говоря, будет стоить дороже и менее эффективен.
Разные перспективы классификации - это просто разные акценты, а тонкая настройка одной и той же большой модели не ограничивается конкретным сценарием, а может включать в себя несколько сценариев вместе. Конечная цель тонкой настройки - максимально расширить возможности большой модели в конкретной области, сохранив при этом контроль над затратами.
Чему учатся большие модели LLM, когда выполняют операции SFT?
- Предварительное обучение -> предварительное обучение на большом количестве данных без контроля для получения базовой модели -> использование предварительно обученной модели в качестве отправной точки для SFT и RLHF.
- SFT --> Выполните обучение SFT на контролируемых наборах данных и далее оптимизируйте модель, используя контролируемые сигналы, такие как контекстная информация --> Используйте модель, обученную SFT, в качестве отправной точки для RLHF.
- RLHF --> Обучение с подкреплением, использующее обратную связь с человеком для оптимизации модели, чтобы она лучше соответствовала его намерениям и предпочтениям --> Оценка и проверка модели, обученной RLHF, и внесение необходимых корректировок.
шаг 1: построение обучающих данных для тонкой настройки большой модели
- Введение: Как построить учебные данные?
- Практические навыки:
- [Крупномасштабные модели (LLM) Методология LLM для создания данных SFT]
Шаг 2: Тонкая настройка инструкций большой модели
- Введение: Как построить учебные данные?
- Практические навыки:
- [Продолжение предварительного обучения больших моделей (LLM)].
- [Тонкая настройка инструкций LLM].
- [LLMs Reward Model Training Глава]
- Обучение с подкреплением для больших моделей (LLM) - Учебная глава PPO
- Обучение с подкреплением для больших моделей (LLM) - Учебная глава DPO
Модуль 4: Поиск документов
Зачем вам нужен поиск документов?
Поиск документов - основная задача RAG, и ее эффективность имеет решающее значение для последующей работы. Хотя можно повысить качество ответа модели, если вспомнить фрагменты документов, связанные с вопросом пользователя, из хранилища документов с помощью векторного вспоминания и одновременно ввести их в LLM. Обычно для запоминания документов используется непосредственно вопрос пользователя. Однако очень часто вопрос пользователя является очень разговорным и нечетко описанным, что влияет на качество векторного запоминания и, следовательно, на отклик модели. В этой главе представлены некоторые проблемы и соответствующие решения в процессе поиска документов.
шаг 1: поиск документов по отрицательной выборке
- ВВЕДЕНИЕ: Во всех видах поисковых задач для обучения качественной поисковой модели часто требуется выборка высококачественных отрицательных примеров из большого набора образцов-кандидатов вместе с положительными примерами.
- Практические навыки:
- [Document Retrieval - Negative Sample Sample Mining]
шаг 2: стратегия оптимизации поиска документов
- Введение: стратегии оптимизации поиска документов
- Практические навыки:
- Поиск документов - Стратегии оптимизации поиска документов
Модуль V: Реранкер
Зачем вам нужен Reranker?
Базовое приложение RAG состоит из четырех ключевых технических компонентов:
- Модели встраивания: используются для преобразования внешних документов и пользовательских запросов в векторы встраивания
- векторная база данных: Используется для хранения векторов встраивания и выполнения поиска по сходству векторов (извлечение наиболее релевантных Top-K частей информации).
- Проектирование подсказок: исходные данные для объединения вопросов пользователя и извлеченных контекстов в более крупные модели
- Моделирование большого языка (LLM): для генерации ответов
Описанная выше базовая архитектура RAG эффективно решает проблему создания LLM "иллюзий" и генерирования ненадежного контента. Однако некоторым корпоративным пользователям требуются более сложные архитектуры для обеспечения контекстной релевантности и точности вопросов и ответов. Проверенным и популярным подходом является интеграция Reranker в приложения RAG.
Что такое реранкер?
Реранкер является важной частью экосистемы информационного поиска (IR) для оценки результатов поиска и их переупорядочивания с целью повышения релевантности запроса. В приложениях RAG реранкер в основном используется после получения результатов векторного запроса (ANN), что позволяет более эффективно определять семантическую релевантность между документами и запросами, более тонко переранжировать результаты и в конечном итоге улучшить качество поиска.
шаг 1: Часть реранкера
- Теоретические исследования:
- Поиск документации RAG - раздел реранкера
- Практические навыки:
- [Reranker - глава bge-reranker].
Модуль 6: Поверхности для оценки RAG
Зачем мне нужно пересматривать RAG?
В процессе изучения и оптимизации RAG (Retrieval Augmentation Generators - генераторы расширения поиска) вопрос о том, как эффективно оценить их работу, стал критически важным.
шаг 1: обзор RAG
- Теоретические исследования:
- [RAG Review]
Модуль 7: Проект с открытым исходным кодом RAG Рекомендуемое обучение
Зачем мне нужно рекомендованное обучение по проекту RAG с открытым исходным кодом?
После того как вы ознакомились с различными процессами RAG, вот несколько рекомендуемых проектов с открытым исходным кодом RAG, которые помогут большим мальчикам освоиться и научиться.
Рекомендации по проекту с открытым исходным кодом RAG - Статья RAGFlow
- Введение: RAGFlow - это движок с открытым исходным кодом Retrieval-Augmented Generation (RAG), построенный на глубоком понимании документов. RAGFlow предоставляет оптимизированный набор рабочих процессов RAG для организаций и частных лиц всех размеров, в сочетании с большой языковой моделью (LLM) для обеспечения надежных RAGFlow - это оптимизированный рабочий процесс RAG для организаций и частных лиц любого размера в сочетании с большой языковой моделью (LLM) для обеспечения надежных вопросов, ответов и обоснованных цитат для широкого спектра сложных форматов данных.
- Проектное обучение:
- Рекомендации по проекту RAG - RagFlow Часть I - развертывание RagFlow в докере
- Рекомендация проекта RAG - RagFlow Часть (2) - Построение базы знаний RagFlow]
- Рекомендации по проекту RAG - RagFlow Часть III - Выбор поставщика модели RagFlow
- Рекомендация проекта RAG - RagFlow Часть (4) - Диалог RagFlow]
- Рекомендация проекта RAG - RagFlow Часть (V) - RAGFlow Api Access (to) оллама (например)]
- Рекомендация проекта RAG - RagFlow Часть (VI) - Изучение исходного кода RAGFlow
Рекомендации по проекту с открытым исходным кодом RAG - QAnything
- Введение: QAnything (Question and Answer based on Anything) - это локальная система вопросов и ответов базы знаний, разработанная для поддержки широкого спектра форматов файлов и баз данных, позволяющая устанавливать и использовать ее в автономном режиме. Используя QAnything, вы можете просто удалять локально хранящиеся файлы любого формата и получать точные, быстрые и надежные ответы.QAnything в настоящее время поддерживает следующие форматы файлов базы знаний: PDF (pdf) , Word (docx) , PPT (pptx) , XLS (xlsx) , Markdown (md) , Email (eml) , TXT (pptx) , TXT (pptx) . (eml) , TXT (txt), изображения (jpg, jpeg, png), CSV (csv), веб-ссылки (html) и так далее.
- Проектное обучение:
- [Рекомендации по проекту с открытым исходным кодом RAG... QAnything [Фрагмент письма]
Рекомендации по проекту с открытым исходным кодом RAG - статья ElasticSearch-Langchain
- ВВЕДЕНИЕ: Вдохновленный проектом langchain-ChatGLM, поскольку Elasticsearch может выполнять смешанные запросы в текстовом и векторном виде и более широко используется в бизнес-сценариях, этот проект заменяет Faiss на Elasticsearch в качестве хранилища знаний и использует Langchain+Chatglm2 для реализации интеллектуальной викторины на основе Интеллектуальные вопросы и ответы на основе собственной базы знаний с использованием Langchain+Chatglm2.
- Проектное обучение:
- [LLMs Getting Started] Эффективность 🤖ElasticSearch-Langchain-Chatglm2 на основе локальной базы знаний]
Рекомендации по проекту RAG с открытым исходным кодом - статья Лангшайн-Чатчат
- Введение: Langchain-Chatchat (ранее Langchain-ChatGLM) QA-приложение с локальным LLM на основе знаний (как ChatGLM) | Langchain-Chatchat (ранее langchain-ChatGLM), локальный LLM на основе знаний (как ChatGLM) QA-приложение с langchain
- Проектное обучение:
- [LLMs Getting Started] Эффективный 🤖Langchain-Chatchat на основе местной базы знаний]
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи


Нет комментариев...