vLLM: механизм вывода и обслуживания LLM для эффективного использования памяти

Общее введение
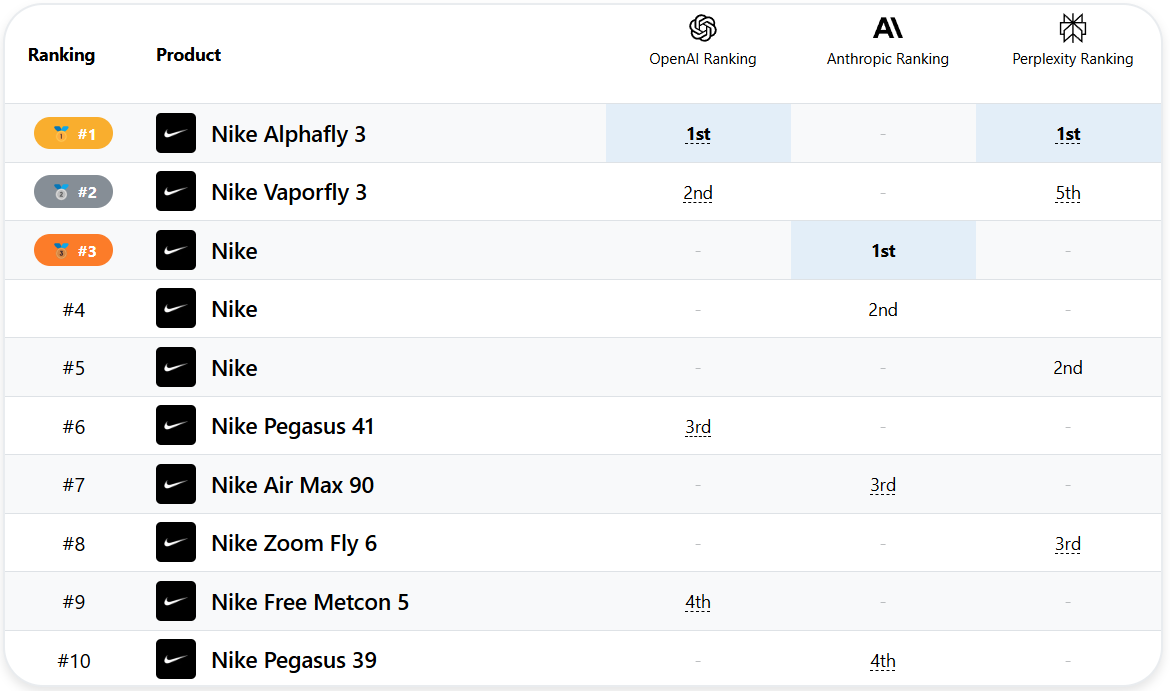
vLLM - это высокопроизводительный и эффективный с точки зрения памяти механизм рассуждений и сервисов, предназначенный для моделирования больших языков (LLM). Первоначально разработанный в лаборатории Sky Computing Lab Калифорнийского университета в Беркли, в настоящее время он является проектом сообщества, в котором участвуют как ученые, так и промышленники. vLLM призван обеспечить быстрые, простые в использовании и экономически эффективные сервисы рассуждений LLM с поддержкой широкого спектра аппаратных платформ, включая CUDA, ROCm, TPU и другие. Среди его ключевых особенностей - оптимизированные циклы выполнения, кэширование префиксов без лишних затрат и улучшенная мультимодальная поддержка.

Список функций
- High Throughput Reasoning: поддержка массивно-параллельных рассуждений, что значительно повышает скорость рассуждений.
- Эффективная память: сократите использование памяти и повысьте эффективность работы модели за счет оптимизации управления памятью.
- Поддержка нескольких аппаратных средств: совместимость с CUDA, ROCm, TPU и другими аппаратными платформами для гибкого развертывания.
- Нулевое кэширование префиксов: сокращение дублирующих вычислений и повышение эффективности выводов.
- Мультимодальная поддержка: поддержка нескольких типов ввода, таких как текст, изображение и т. д., для расширения сценариев применения.
- Сообщество с открытым исходным кодом: поддерживается научными и промышленными кругами, постоянно обновляется и оптимизируется.
Использование помощи
Процесс установки
- Клонируйте репозиторий проекта vLLM:
git clone https://github.com/vllm-project/vllm.git
cd vllm
- Установите зависимость:
pip install -r requirements.txt
- Выберите подходящий Dockerfile для сборки в зависимости от аппаратной платформы:
docker build -f Dockerfile.cuda -t vllm:cuda .
Руководство по использованию
- Запустите службу vLLM:
python -m vllm.serve --model <模型路径>
- Отправляет запрос на обоснование:
import requests
response = requests.post("http://localhost:8000/infer", json={"input": "你好,世界!"})
print(response.json())
Детальное управление функциями
- Высокопроизводительные рассуждения: Благодаря распараллеливанию задачи рассуждений vLLM может обрабатывать большое количество запросов за короткий промежуток времени в сценариях с высокой интенсивностью работы.
- Эффективная память: vLLM использует оптимизированную стратегию управления памятью для уменьшения занимаемой памяти, что делает его пригодным для работы в средах с ограниченными ресурсами.
- Поддержка нескольких аппаратных средств: Пользователи могут выбрать нужный Dockerfile для сборки в зависимости от конфигурации оборудования и гибко развернуть его на разных платформах.
- Кэширование префиксов с нулевыми накладными расходами: Кэшируя результаты префиксных вычислений, vLLM сокращает количество повторных вычислений и повышает эффективность выводов.
- мультимодальная поддержка: vLLM поддерживает не только ввод текста, но и различные типы ввода, например, изображения, что расширяет возможности применения.
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи



Нет комментариев...