Локальное развертывание Vanna: эффективные преобразования Text2SQL с легкостью

Vanna - это высоко оцененный фреймворк Text2SQL с открытым исходным кодом, который преобразует естественный язык в запросы SQL. В этой статье подробно рассказывается о том, как развернуть Vanna локально и объединить ее с базой данных MySQL и Deepseek Модели настроены и протестированы, чтобы помочь вам быстро начать работу с инструментом. Все операции основаны на реальных испытаниях, чтобы гарантировать, что шаги понятны и выполнимы.
Настройка среды Python
Чтобы запустить Vanna, вам сначала нужно стабильное окружение Python. Вот пошаговое руководство по настройке Vanna на примере Miniconda3.
Установка Miniconda3
- Загрузите установочный пакет:
wget https://repo.continuum.io/miniconda/Miniconda3-latest-Linux-x86_64.sh - Выполните сценарий установки:
sh Miniconda3-latest-Linux-x86_64.sh - Настройте переменные окружения:
vim /etc/profileДобавьте его в файл:
export PATH="/data/apps/miniconda3/bin:$PATH"Сохраните и обновите конфигурацию:
source /etc/profile - Если вам нужно удалить программу, вы можете просто удалить каталог установки:
rm -rf /data/apps/miniconda3/
Создание виртуальной среды
- Создайте среду Python 3.10:
conda create -n test python=3.10 - Активируйте среду (она должна вступить в силу на новом терминале или после перезагрузки):
conda activate test - Другие распространенные команды:
- Выход из окружения:
conda deactivate - Просмотр информации об окружающей среде:
conda info --env
- Выход из окружения:
После выполнения описанных выше шагов у вас есть автономная виртуальная среда Python, которая закладывает основу для развертывания Vanna.
Развертывание и настройка Vanna
Когда среда Python готова, перейдем к основной настройке Vanna. Приведенные ниже операции относятся к официальной документации (https://vanna.ai/docs/) и используют базу данных MySQL в качестве примера.
Конфигурация подключения к базе данных
Сначала убедитесь, что вы можете правильно войти в базу данных, указав учетную запись MySQL, пароль и порт. После проверки успешного соединения откройте страницу конфигурации MySQL в официальной документации Vanna (выберите MySQL в левой строке меню). На странице будет показан пример кода подключения, как показано ниже:
Основываясь на информации о вашей базе данных, настройте параметры в коде (например, хост, пользователь, пароль и т. д.), чтобы обеспечить бесперебойное подключение Vanna.
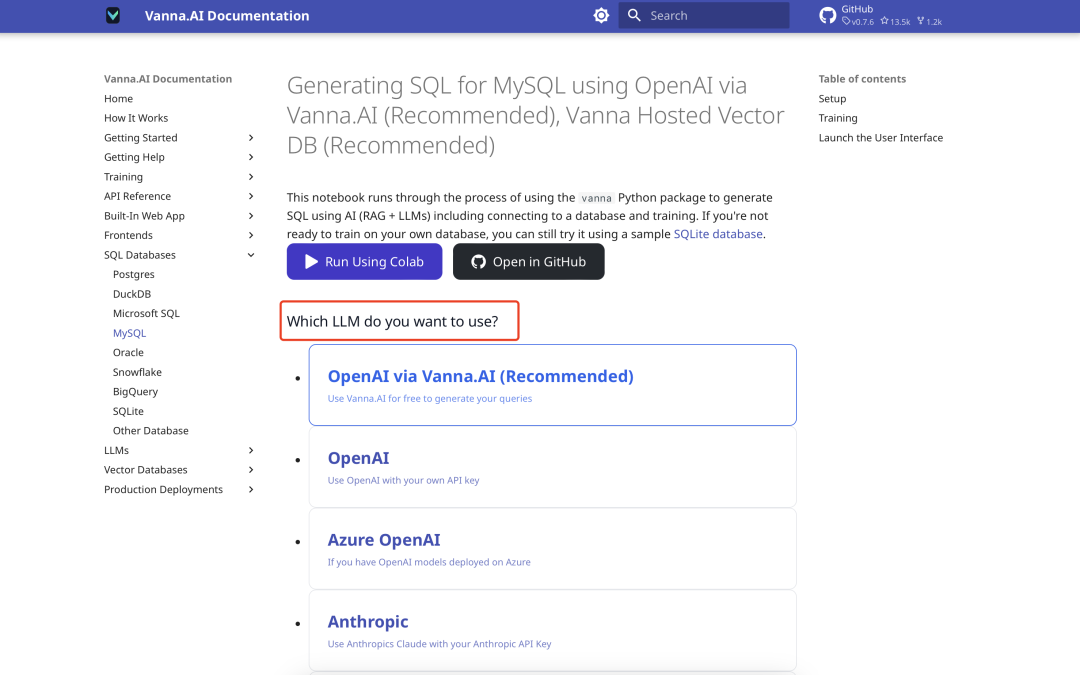
Выбор языковой модели
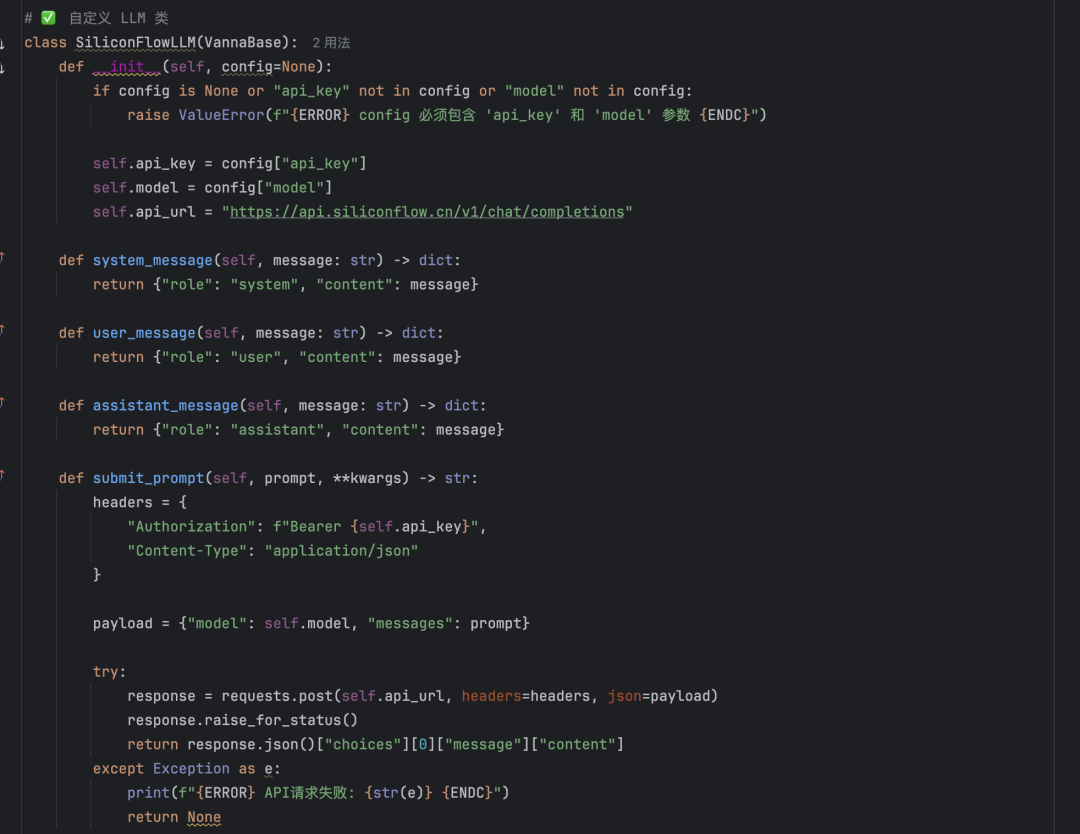
Vanna поддерживает различные большие языковые модели (LLM). На официальной странице предлагается выбрать модель, например Оллама или вызовы API. В качестве примера здесь показана модель Deepseek для потоков на основе кремния.
- Опыт Олламы: Попытки развертывания квантифицированной модели Deepseek-7b были предприняты с неудовлетворительными результатами, поэтому рекомендуется отказаться от этого варианта.
- API Deepseek: Вызов моделей Deepseek через потоки in silico работает лучше. Однако обратите внимание, что для использования моделей, которые официально не поддерживаются, требуются пользовательские классы LLM. См. проект с открытым исходным кодом Vanna Мистраль реализации (mistral.py), создайте класс, адаптированный для Deepseek, соответствующим образом.
Экран конфигурации выглядит следующим образом:
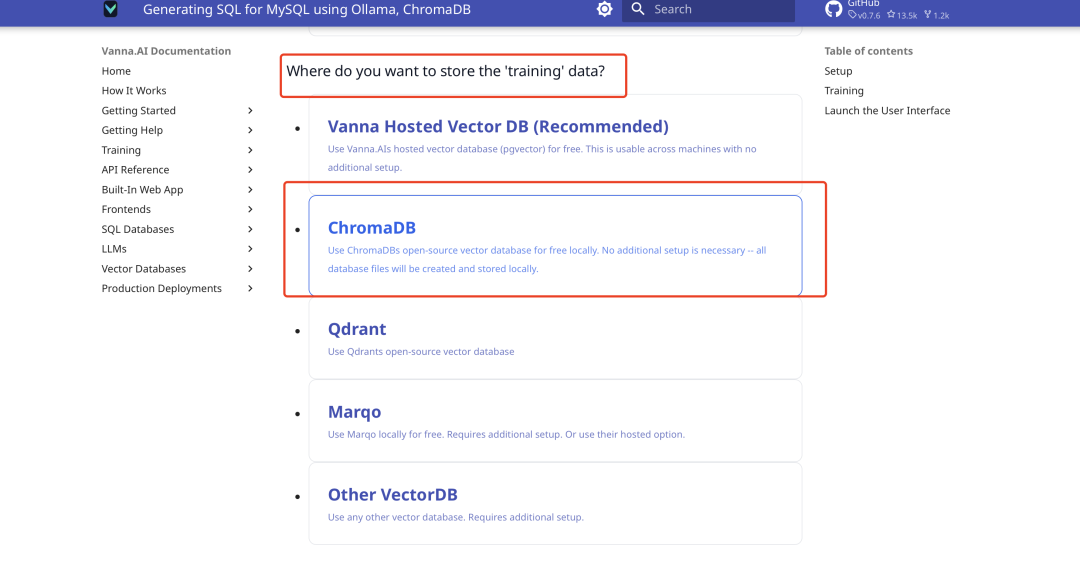
Настройка базы данных векторов
Vanna по умолчанию интегрирует ChromaDB в качестве небольшой векторной базы данных, дополнительная установка не требуется. Официальная документация сгенерирует код в соответствии с вашим выбором, как показано ниже:
Установка зависимостей и подготовка кода
- Установите Vanna и его зависимости в активированную виртуальную среду:
pip install vanna - Создайте
.pyфайл, скопируйте в него официальный сгенерированный код. Ниже приведен пример фрагмента кода для адаптации MySQL и Deepseek (вам необходимо настроить параметры в соответствии с реальной ситуацией):from vanna.remote import VannaDefault vn = VannaDefault(model='deepseek', api_key='your_api_key') vn.connect_to_mysql(host='localhost', dbname='test_db', user='root', password='your_password', port=3306)
обучение данным
Vanna поддерживает три типа обучающих данных: операторы SQL, документация на продукт и описание структуры таблиц базы данных. Здесь мы рекомендуем использовать описание структуры таблицы, эффект более интуитивный. Этапы обучения выглядят следующим образом:
- Подготовьте данные о структуре таблицы (например, файл DDL).
- Используйте официально предоставленный код обучения:
vn.train(ddl="CREATE TABLE employees (id INT, name VARCHAR(255), salary INT)") - Процесс обучения показан ниже:
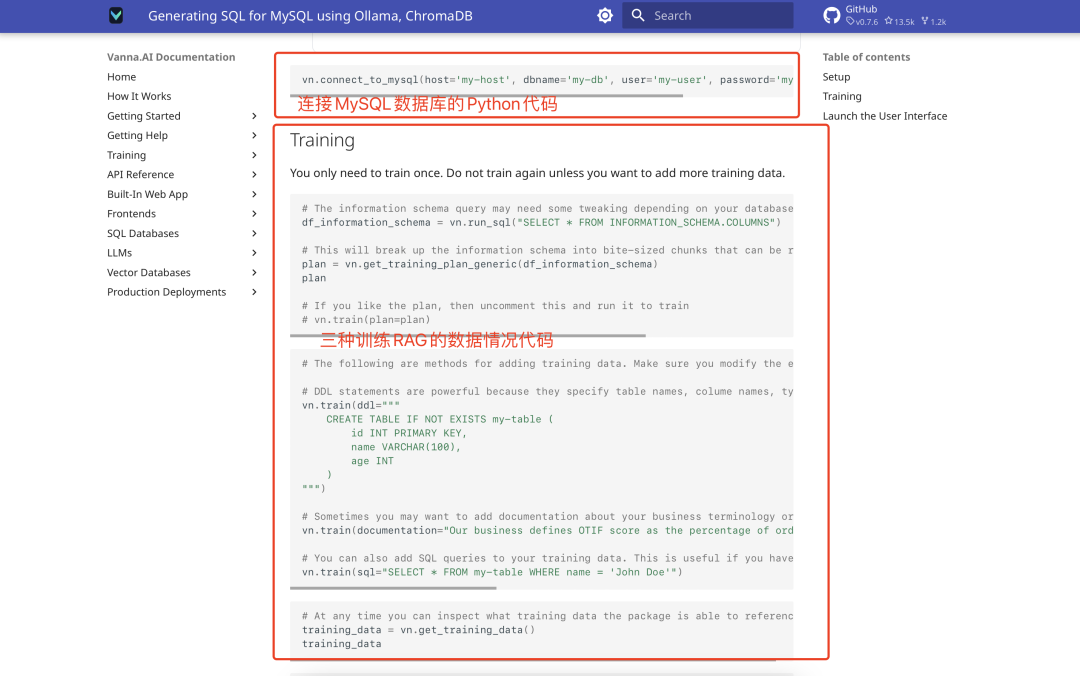
Показаны дополнительные результаты обучения:
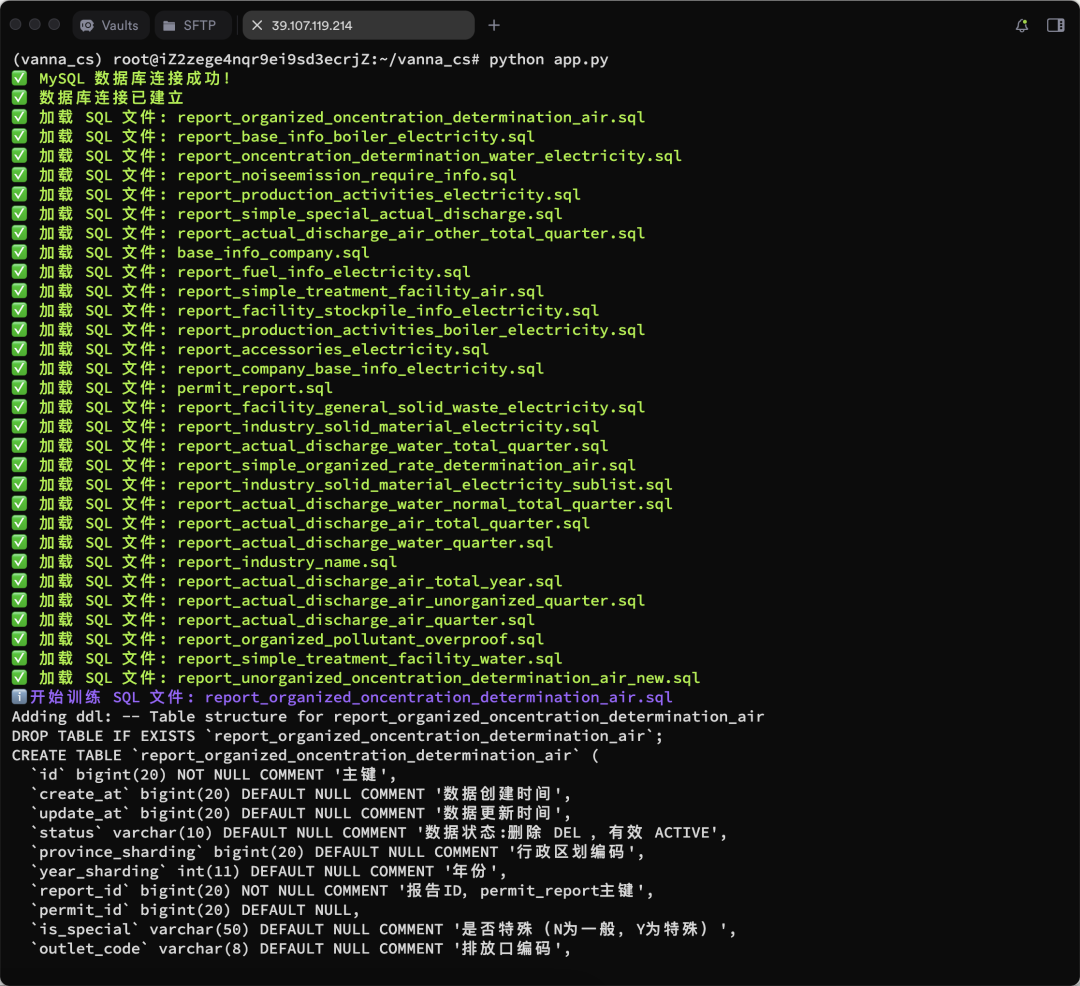
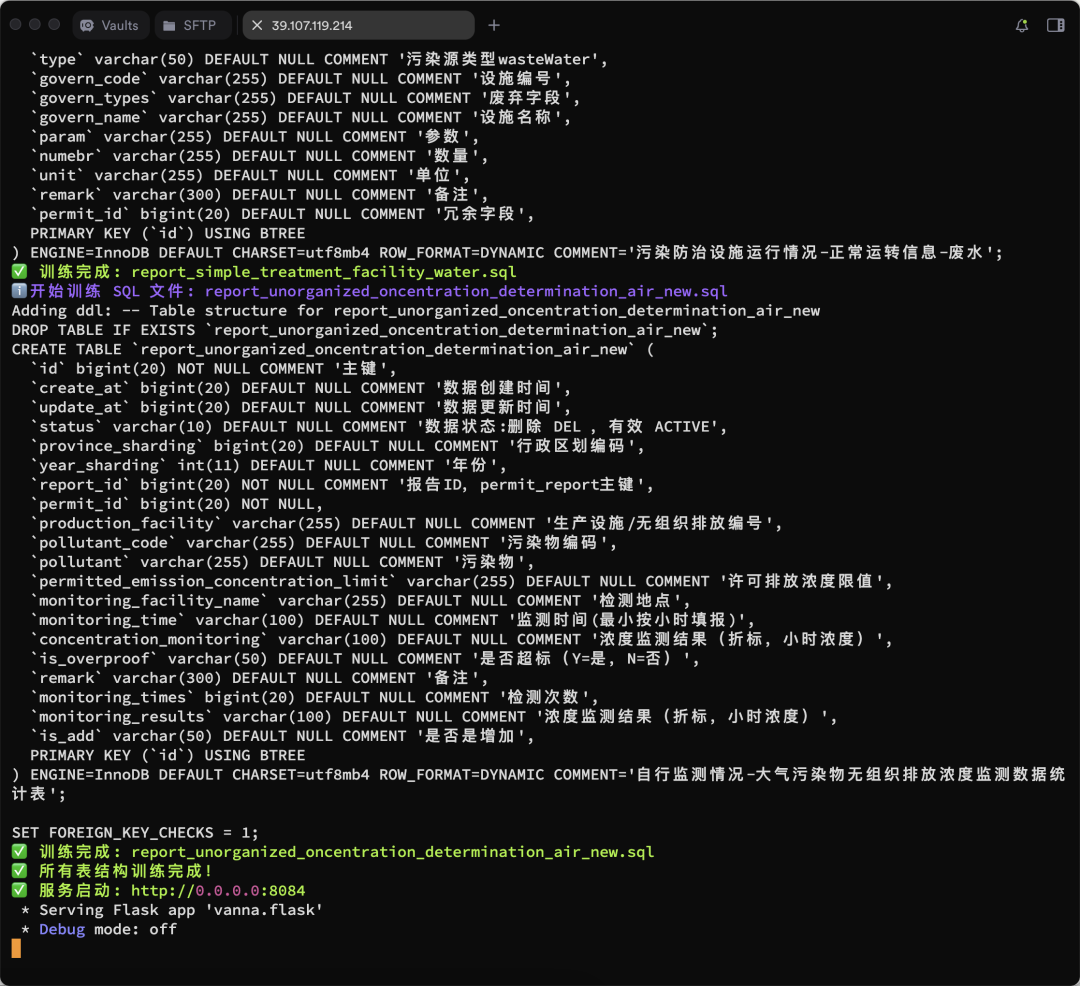
Запуск веб-интерфейса
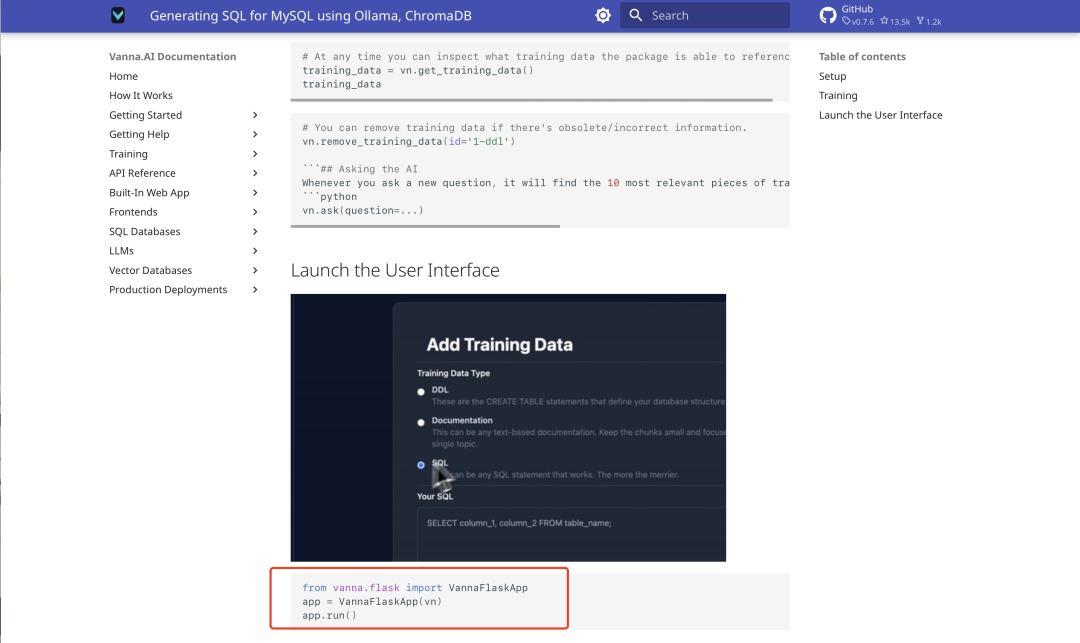
После завершения обучения запустите следующий код Flask API, чтобы запустить веб-интерфейс Vanna:
from vanna.flask import VannaFlaskApp
app = VannaFlaskApp(vn)
app.run()
Доступ к локальному адресу (обычно http://127.0.0.1:5000), вы можете делать SQL-запросы через интерфейс.
Отображение эффекта запроса
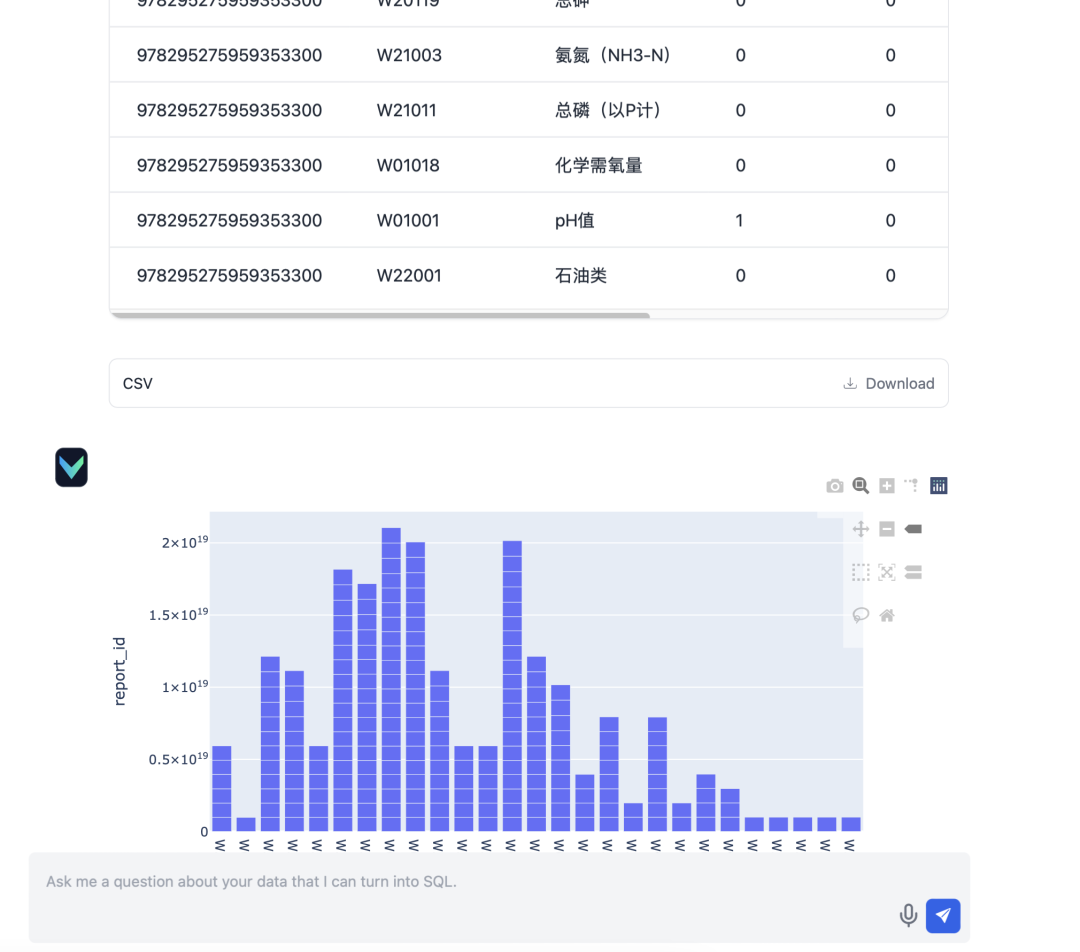
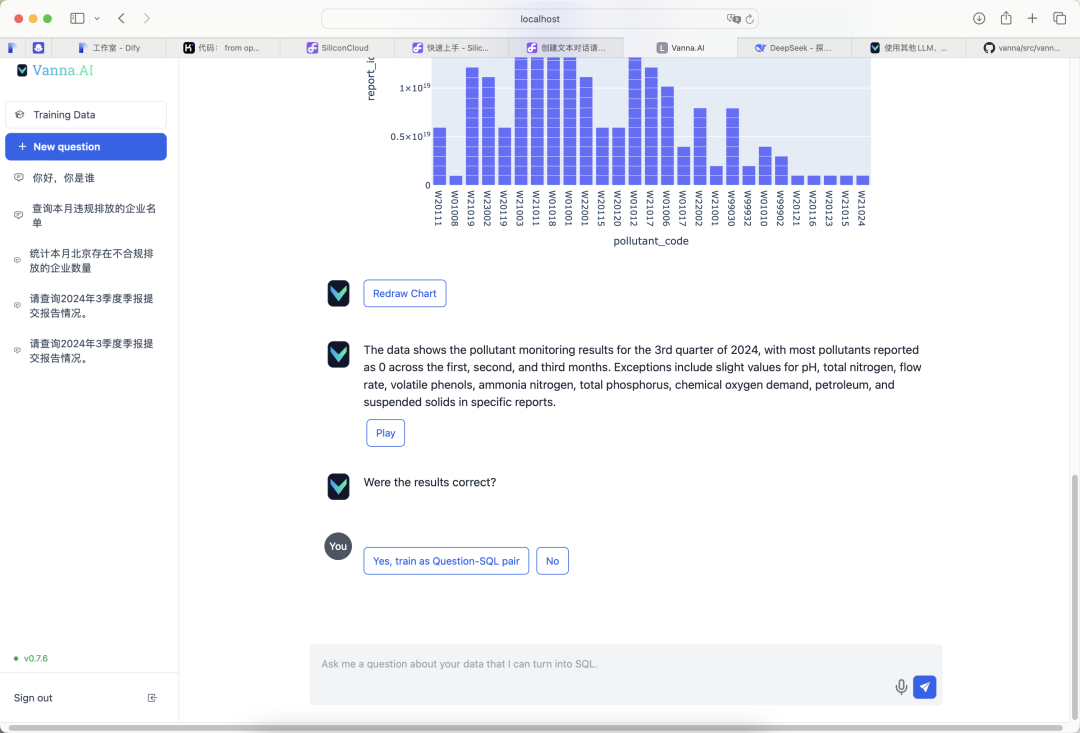
После развертывания функциональность Vanna's Q&A работала удовлетворительно. Вот несколько реальных результатов тестирования:
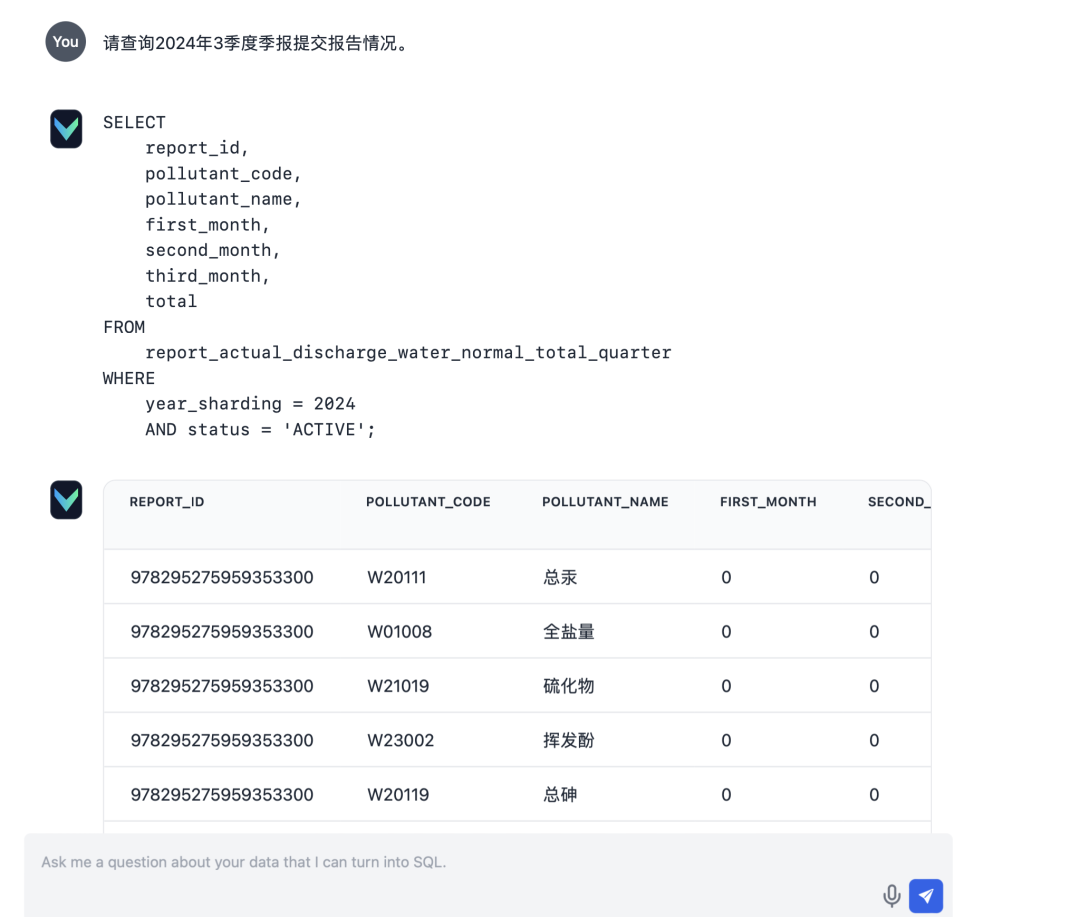
- Вводная часть: "Пожалуйста, поинтересуйтесь статусом сдачи отчетов для квартального отчета за мартовский квартал 2024 года".

- Ввод: "Количество статистических данных"
- Вход: "Статистика загрязняющих веществ"
Резюме и рекомендации
Следуя этим шагам, вы сможете успешно развернуть Vanna локально и реализовать эффективную функциональность Text2SQL в сочетании с моделями MySQL и Deepseek. По сравнению с другими инструментами, Vanna имеет очевидные преимущества в простоте использования и эффективности. Новичкам рекомендуется отдавать предпочтение использованию табличных структур для обучения данных и настраивать конфигурацию языковой модели в соответствии с реальными потребностями.
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи




Нет комментариев...