
TPO-LLM-WebUI: ИИ-фреймворк, в котором можно ввести вопрос и обучить модель выдавать результаты в режиме реального времени

Общее введение
TPO-LLM-WebUI - это инновационный проект, открытый компанией Airmomo на GitHub, который позволяет оптимизировать большие языковые модели (LLM) в режиме реального времени с помощью интуитивно понятного веб-интерфейса. Он использует фреймворк TPO (Test-Time Prompt Optimization), полностью прощаясь с утомительным процессом традиционной тонкой настройки, и напрямую оптимизирует вывод модели без обучения. После того как пользователь вводит вопрос, система использует модели вознаграждения и итеративную обратную связь, позволяя модели динамически развиваться в процессе рассуждений, делая ее все умнее и умнее и улучшая качество вывода на 50%. Будь то полировка технической документации или создание ответов на вопросы безопасности, этот легкий и эффективный инструмент обеспечивает мощную поддержку разработчикам и исследователям.


Список функций
- Эволюция в реальном времени: Оптимизация вывода на этапе умозаключений, чем больше его используют, тем больше он отвечает потребностям пользователя.
- Тонкая настройка не требуется: Отказ от обновления весов модели и непосредственное улучшение качества генерации.
- Совместимость с несколькими моделями: Поддержка загрузки различных базовых моделей и моделей вознаграждений.
- Динамическое выравнивание предпочтений: Регулировка производительности на основе обратной связи по вознаграждению для приближения к ожиданиям человека.
- Визуализация рассуждений: Демонстрируйте процесс итераций оптимизации для облегчения понимания и отладки.
- Легкий и эффективный: Вычисления отличаются низкой стоимостью и простотой развертывания.
- Открытый исходный код и гибкость: Предоставляет исходный код и поддерживает пользовательскую разработку.
Использование помощи
Процесс установки
Для развертывания TPO-LLM-WebUI требуется базовая настройка среды. Ниже приведены подробные шаги, которые помогут пользователям быстро приступить к работе.
1. Подготовка среды
Убедитесь, что следующие инструменты установлены:
- Python 3.10: Основная операционная среда.
- Git: Используется для получения кода проекта.
- Графический процессор (рекомендуется): Графические процессоры NVIDIA ускоряют вычисления.
Создайте виртуальную среду:
Используйте Конди:
conda create -n tpo python=3.10
conda activate tpo
или собственные инструменты Python:
python -m venv tpo
source tpo/bin/activate # Linux/Mac
tpo\Scripts\activate # Windows
Загрузите и установите зависимости:
git clone https://github.com/Airmomo/tpo-llm-webui.git
cd tpo-llm-webui
pip install -r requirements.txt
Установите TextGrad:
TPO опирается на TextGrad, который требует дополнительной установки:
cd textgrad-main
pip install -e .
cd ..
2. Модель конфигурации
Вам нужно вручную загрузить базовую и бонусную модели:
- базовая модельКак
deepseek-ai/DeepSeek-R1-Distill-Qwen-32B(Обнимает лицо) - моделирование стимуловКак
sfairXC/FsfairX-LLaMA3-RM-v0.1(Обнимает лицо)
Поместите модель в указанную директорию (например./model/HuggingFace/), и вconfig.yamlУстановите путь в
3. Запустите службу vLLM
пользоваться vLLM Базовая модель хостинга. Возьмем для примера 2 графических процессора:
vllm serve /model/HuggingFace/deepseek-ai/DeepSeek-R1-Distill-Qwen-14B
--dtype auto
--api-key token-abc123
--tensor-parallel-size 2
--max-model-len 59968
--port 8000
После того как служба будет запущена, прослушайте http://127.0.0.1:8000.
4. Запуск WebUI
Запустите веб-интерфейс в новом терминале:
python gradio_app.py
доступ к браузеру http://127.0.0.1:7860Ниже приведен список наиболее популярных и востребованных продуктов, представленных на рынке.
Основные функции
Функция 1: Инициализация модели
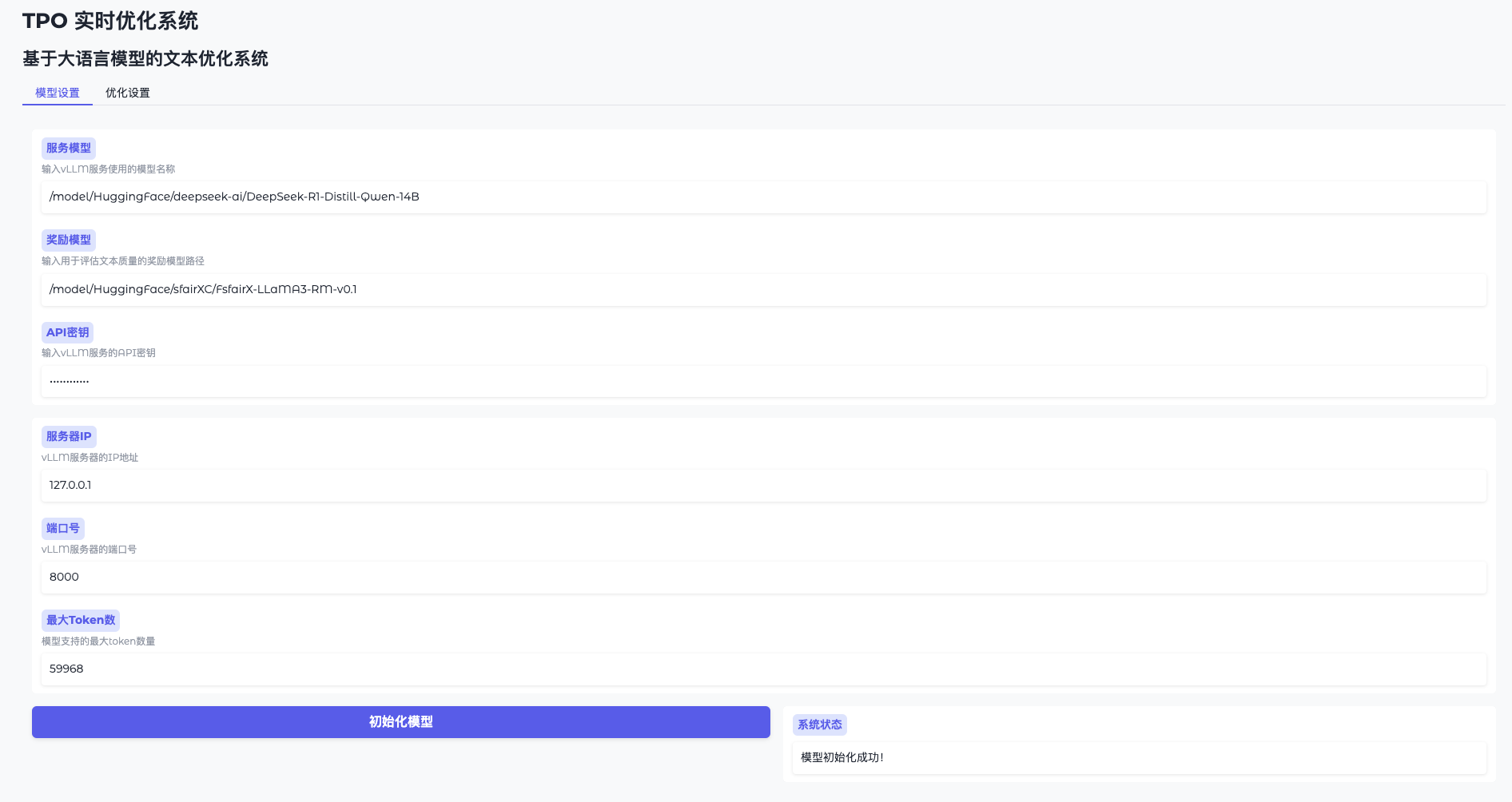
- Открыть настройки модели
Перейдите в WebUI и нажмите "Настройки модели". - Подключение к vLLM
Введите адрес (например.http://127.0.0.1:8000) и ключ (token-abc123). - Загрузка модели вознаграждения
Укажите путь (например./model/HuggingFace/sfairXC/FsfairX-LLaMA3-RM-v0.1Нажмите "Инициализировать" и подождите 1-2 минуты. - Подтверждение готовности
Интерфейс выдаст сообщение "Модель готова", и вы сможете продолжить.
Функция 2: Оптимизация производительности в режиме реального времени
- Переключить страницу оптимизации
Перейдите в раздел "Оптимизация настроек". - Вопросы ввода
Введите такой текст, как "Прикоснитесь к этому техническому документу". - Операционная оптимизация
Нажмите кнопку "Начать оптимизацию", и система сгенерирует несколько результатов-кандидатов и итеративно улучшит их. - Посмотрите на процесс эволюции
На странице результатов отображается исходный и оптимизированный результат с постепенным повышением качества.
Особенность 3: оптимизация режима сценария
Если вы не используете WebUI, вы можете запустить сценарий:
python run.py
--data_path data/sample.json
--ip 0.0.0.1
--port 8000
--server_model /model/HuggingFace/deepseek-ai/DeepSeek-R1-Distill-Qwen-14B
--reward_model /model/HuggingFace/sfairXC/FsfairX-LLaMA3-RM-v0.1
--tpo_mode tpo
--max_iterations 2
--sample_size 5
Результаты оптимизации сохраняются в logs/ Папка.
Подробное описание специальных возможностей
Попрощайтесь с тонкой настройкой, развивайтесь в режиме реального времени
- процедура::
- Введите вопрос, и система сгенерирует первоначальный ответ.
- Вознаграждайте за оценку модели и обратную связь, чтобы направить следующую итерацию.
- После нескольких итераций результат становится "умнее", а качество значительно улучшается.
- доминирование: Экономьте время и арифметические действия, оптимизируя в любое время без обучения.
Чем больше вы его используете, тем умнее он становится.
- процедура::
- Используйте одну и ту же модель несколько раз с разными исходными данными для решения разных задач.
- Система накапливает опыт на основе каждого отзыва, и результат лучше соответствует потребностям.
- доминирование: Динамическое обучение предпочтениям пользователей для достижения лучших результатов в долгосрочной перспективе.
предостережение
- требования к оборудованиюРекомендуемые 16 ГБ видеопамяти или более, несколько GPU должны обеспечить свободные ресурсы.
export CUDA_VISIBLE_DEVICES=2,3Назначение. - Решение проблем: Если видеопамять переполнена, уменьшите значение
sample_sizeили проверьте заполненность GPU. - Поддержка общества: Обратитесь за помощью к GitHub README или Issues.
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи

Нет комментариев...