
Обновление видео Tongyi Wanxiang, обновленный VBench, поддержка видео для генерации китайского языка, полное вытягивание текстуры объектива

Грядет ли технологический прорыв в видеогенерации AI, когда 2025 год только начался?
Сегодня утром модель генерации видео Tongyi Wanphase от Ali объявила о серьезном обновлении до версии 2.1.
Существует две версии новой модели, а именноTomix 2.1 Extreme и Professional, первый из которых ориентирован на высокую производительность, а второй - на высокую выразительность..
Согласно представлению, в этот раз Tongyi Wanxiang всесторонне улучшил общую производительность модели, особенно в обработке сложных движений, восстановлении реальных физических законов, улучшении текстуры фильма и оптимизации инструкций для выполнения, что открывает новые возможности для художественного творчества AI.
Давайте посмотрим на эффект генерации видео и узнаем, сможет ли он вас удивить.
Возьмем для примера классический "стейк". Вы видите, что текстура стейка хорошо видна, поверхность покрыта тонким слоем жира, который блестит, а лезвие медленно режет вдоль мышечных волокон, делая мясо упругим и насыщенным деталями. 
Pроман: В ресторане мужчина режет стейк, от которого идет горячий пар. На крупном плане мужчина держит острый нож в правой руке, кладет нож на стейк и режет его по центру. Человек одет в черное с белым лаком на руках, фон - боке с белой тарелкой с желтой едой и коричневым столом.
А затем посмотрите на эффект генерации персонажа крупным планом: выражение лица маленькой девочки, движения рук и тела очень естественны и скоординированы, ветер, развевающий волосы, также соответствует законам движения.

Заглавие:Милая девушка стоит в цветочном кусте, прижав руки к сердцу, а вокруг нее танцуют маленькие сердечки. Она одета в розовое платье, ее длинные волосы развеваются на ветру, а улыбка очень милая. На заднем плане - весенний сад с распустившимися цветами и ярким солнечным светом. Реалистичная HD-съемка, крупный план, мягкий естественный свет.
Достаточно ли сильна модель, чтобы набрать еще один балл. В настоящее время на VBench Leaderboard, окончательном списке обзоров видеогенераторов, модельОбновленный Tongyi Wanxiang достиг вершины списка с общим баллом 84,7%, опередив такие отечественные и зарубежные модели генерации видео, как Gen3, Pika и CausVid... Похоже, что конкурентный ландшафт в области видеогенерации переживает очередную волну перемен.
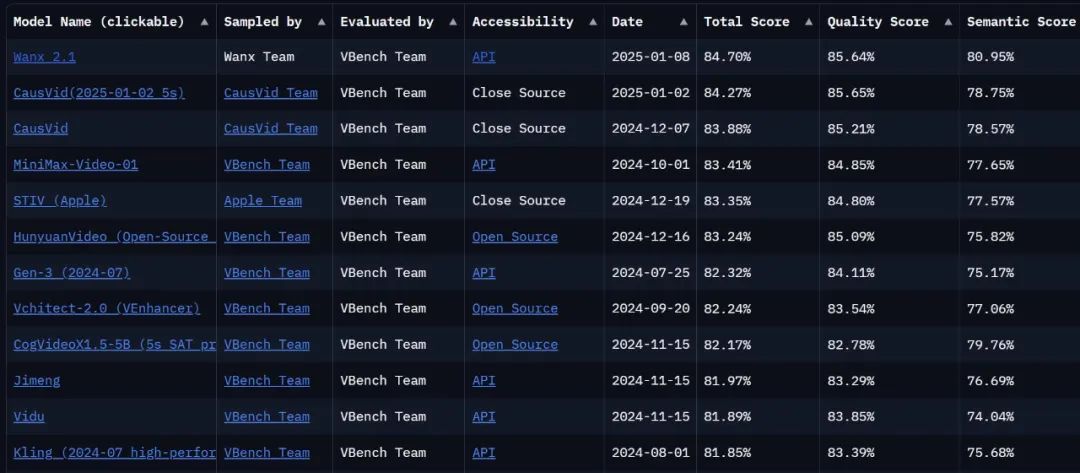
Ссылка на список: https://huggingface.co/spaces/Vchitect/VBench_Leaderboard
С этого момента пользователи смогут использовать модели последнего поколения на сайте Tongyi Wanxiang. Аналогичным образом разработчики могут вызывать API больших моделей в AliCloud Bai Lian.
Адрес официального сайта: https://tongyi.aliyun.com/wanxiang/
личный опытПовышенная выразительность и возможность играть со шрифтами со спецэффектами
В последнее время наблюдается стремительная итерация больших моделей для генерации видео, достигла ли новая версия Tongyi Wanxiang уровня улучшения поколения? Мы провели несколько реальных тестов.
Видео ИИ теперь может писать.
Во-первых, видео, созданные искусственным интеллектом, наконец-то могут попрощаться с "призрачным" копирайтингом.
Ранее основные модели генерации видео с помощью искусственного интеллекта, представленные на рынке, не могли точно генерировать китайский и английский языки, так как на месте, где должен быть текст, оказывалась куча неразборчивого мусора. Теперь эта проблема отрасли решена с помощью Tongyi Wanxiang 2.1.
Он сталПервая модель генерации видео, поддерживающая генерацию китайского текста, а также эффекты английского и китайского текстов..
Теперь пользователи могут генерировать текст и анимацию с кинематографическими эффектами, просто введя короткое текстовое описание.
Например, котенок печатает перед компьютером, и на экране появляются семь больших слов "Работа или еда".

В ролике, созданном Тонги Ваньсяном, кот сидит за рабочим столом и серьезно играет на клавиатуре и мышке, похожей на современную пишущую машинку, а всплывающие субтитры в сочетании с автоматически генерируемым саундтреком придают всей картине более остроумный вид.
Затем из маленького оранжевого квадратика выплывает английское слово "Synced".

Будь то китайский или английский язык, Tongyi Wanxiang делает все правильно, без опечаток и "призрачного письма".
Кроме того, он поддерживает применение шрифтов в различных сценариях, которыеВ том числе шрифты для спецэффектов, плакатные шрифты и шрифты, отображаемые в реальных сценариях..
Например, возле Эйфелевой башни на берегу Сены в воздухе расцветают яркие фейерверки, а по мере приближения камеры розовое число "2025" постепенно увеличивается, пока не заполнит весь кадр.

Энергичное движение больше не является "жутким"
Сложные движения персонажей когда-то были "кошмаром" для моделей генерации видео ИИ, и в прошлом видео, сгенерированные ИИ, либо имели летающие руки и ноги, либо превращались в живого человека, либо имели странные движения, которые "поворачивались только вокруг, но не головой". 
Благодаря оптимизации алгоритмов и обучению данных, Tongyi Wanxiang может добиться стабильной и сложной генерации движений в различных сценариях, особенно в отношении крупномасштабных движений конечностей и точного вращения конечностей, а брейк-данс, сгенерированный на картинке выше, очень шелковистый и плавный.
В то же время на созданном ниже видеоролике движения человека при беге плавны и естественны, левая и правая ноги не различаются и не вывернуты. Кроме того, он уделяет пристальное внимание деталям: каждый раз, когда пальцы ног человека касаются земли, они оставляют след и слегка приподнимают мелкий песок.

Заметка: золотые солнечные лучи на сверкающем море на закате, красивый молодой человек, бегущий по пляжу, устойчивый трекинг-кадр.
Зеркальное отражение, как у мастеров кинематографа.
Великий режиссер Спилберг однажды сказал, что секрет хорошего фильма кроется в языке камеры. Для того чтобы создать потрясающие кадры, кинематографисты ненавидят подниматься в небо и летать над стенами. 
Но в наш век искусственного интеллекта "снять" фильм стало гораздо проще.
Достаточно ввести простую текстовую команду, например, объектив влево, объектив дальше, объектив вперед и т.д., и Tongyi Wanxiang сможетАвтоматический вывод разумного видео в соответствии с основным содержанием видео и потребностями камеры..
Набираем Prompt: рок-группа играет на лужайке перед домом, по мере продвижения камера фокусируется на гитаристе, одетом в кожаную куртку, с длинными грязными волосами, раскачивающимися в такт. Пальцы гитариста быстро перебирают струны, а остальные участники группы на заднем плане отдают все свои силы.

полное представление обо всем 2.1 Инструкции были строго соблюдены. Видео начинается со страстной игры гитариста и барабанщика, и по мере того, как камера медленно приближается, фон размывается и увеличивается, чтобы подчеркнуть манеру поведения и движения рук гитариста.
Длинные текстовые команды не теряются
Чтобы видео, созданные искусственным интеллектом, были потрясающими, необходимы точные текстовые подсказки.
Однако иногда большая модель имеет ограниченную память, и, сталкиваясь с текстовыми командами, содержащими различные переключения сцен, взаимодействия персонажей и сложные действия, она склонна терять детали или путаться в логическом порядке.
Новый Tongyi Manxiang - это большой шаг вперед в плане длинных текстовых инструкций, которым нужно следовать.
Заглавие: Мотоциклист мчится по узкой городской улице на огромной скорости, уклоняясь от мощного взрыва в соседнем здании, пламя яростно ревет, отбрасывая яркое оранжевое свечение, а обломки и осколки металла разлетаются в воздухе, добавляя хаоса на месте происшествия. Велосипедист, одетый в темную экипировку, согнувшись и крепко держась за руль, сосредоточенно мчится вперед на бешеной скорости, не обращая внимания на бушующий позади огонь. Густой черный дым, оставшийся после взрыва, заполняет воздух, окутывая фон апокалиптическим хаосом. Однако всадник остается неумолимым, пробираясь сквозь хаос с точностью и экстремальностью кинематографа, сверхмелкими деталями, захватывающим, 3D и слаженным действием.

В приведенном выше пространном текстовом описании узкие улочки, яркое пламя, клубы черного дыма, летящие обломки и всадники в темном снаряжении ...... - все это детали, запечатленные Тунъи Мэнсяном.
Tongyi Wanxiang также обладает более мощной способностью объединять концепции, чтобы точно понять множество различных идей, элементов или стилей и объединить их вместе для создания совершенно нового видеоконтента.
Образ старика в костюме, вылезшего из яйца и широко раскрывшимися глазами смотрящего в камеру на беловолосого старика, в сочетании со звуком кукареканья петуха выглядит довольно уморительно.

Специализируется на рисовании маслом мультфильмов и других стилей
Новая версия Tongyi Manphase также генерирует кинематографические видеоизображения и имеет хорошую поддержку различных художественных стилей, таких как мультфильм, цветное кино, 3D, картины маслом, классический стиль и т.д.
Посмотрите на этого милого маленького 3D-анимированного монстра, который стоит на виноградной лозе и танцует вокруг.

Задача: пушистый, счастливый маленький зеленый монстр тити стоит на ветке виноградной лозы и счастливо поет, поверните камеру против часовой стрелки.
Кроме того, он поддерживает различные соотношения сторон, включая 1:1, 3:4, 4:3, 16:9 и 9:16, что позволяет лучше адаптировать его к различным конечным устройствам, таким как телевизоры, компьютеры и мобильные телефоны. 
Исходя из вышеприведенного представления, мы уже можем сделать некоторую творческую работу, используя Tongyi Manxiang для преобразования вдохновения в "реальность".
Разумеется, в этой серии достижений AliCloud усовершенствовал базовую модель генерации видео.
Базовая модель значительно оптимизированаСтруктура, обучение, оценка и всестороннее "преображение".
19 сентября прошлого года на конференции Yunqi Conference компания AliCloud выпустила модель генерации видео Tongyi Wanphase, которая позволяет генерировать видео высокого разрешения для кино и телевидения. Будучи полностью самостоятельно разработанной моделью генерации визуальных эффектов AliCloud, она использует технологию Diffusion + Трансформатор Архитектура поддерживает задачи класса генерации изображений и видео и обеспечивает лучшие в отрасли возможности визуального генерирования благодаря множеству инноваций в модельных фреймворках, обучающих данных, методах аннотирования и дизайне продукта.
В этой усовершенствованной модели команда Tongyi Wanxiang (далее именуемая "команда") далееСамостоятельная разработка эффективных архитектур VAE и DiT, усовершенствованный для моделирования пространственно-временных контекстных связей, что значительно оптимизирует генерацию.
Flow Matching - это появившийся в последние годы фреймворк для обучения генеративных моделей, который проще в обучении, достигает сравнимого или даже лучшего качества, чем диффузионные модели за счет Continuous Normalising Flow, и имеет более высокую скорость вывода, и постепенно применяется в области генерации видео. Например, в ранее выпущенной Meta видеомодели Movie Gen используется Flow Matching.
Для выбора методов обучения Tongyi Wanxiang 2.1 используетСхема согласования потоков на основе линейных траекторий шумаОн был тщательно проработан для данного фреймворка, что позволило улучшить сходимость модели, качество генерации и эффективность.

Tongyi Wanxiang 2.1 Схема архитектуры генерации видео
Для видео VAE команда разработала инновационную схему видеокодека, объединив механизм кэширования и каузальную свертку.. Среди них механизм кэширования позволяет сохранять необходимую информацию при обработке видео, тем самым сокращая повторные вычисления и повышая эффективность вычислений; каузальная свертка позволяет улавливать временные особенности видео и адаптироваться к постепенным изменениям видеоконтента.
Вместо прямого процесса декодирования E2E для длинных видео реализация заменяет прямой процесс декодирования E2E для длинных видео, разбивая видео на фрагменты и кэшируя промежуточные функции, так что использование видеокарты зависит только от размера фрагментов, независимо от длины исходного видео, что позволяет модели эффективно кодировать и декодировать видео 1080P неограниченной длины. Команда утверждает, что эта ключевая технология обеспечивает жизнеспособный путь для обучения видео произвольной длины.
На следующем рисунке показано сравнение результатов различных моделей VAE. С точки зрения вычислительной эффективности модели (кадр/задержка) и восстановления сжатия видео (пиковое отношение сигнал/шум, PSNR), VAE, принятая Tongyi Wanxiang, достигает следующих результатов без доминирующих параметровЛучшее в отрасли качество сжатия и восстановления видео.
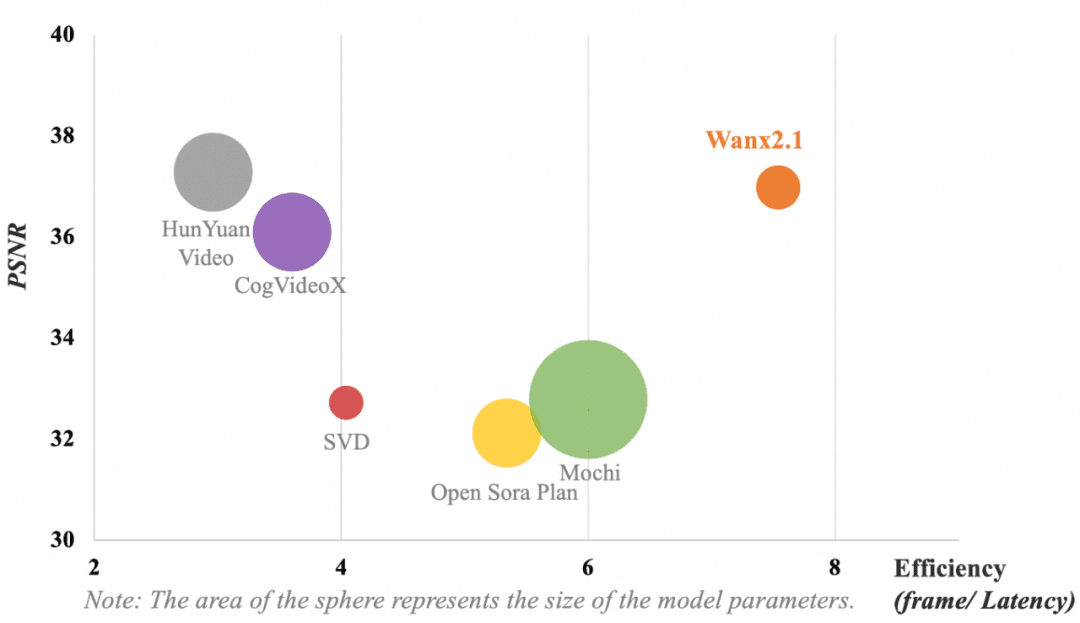
Примечание: Область круга обозначает размер параметра модели.
Основной целью команды разработчиков DiT (Diffusion Transformer) было достижение мощных возможностей пространственно-временного моделирования при сохранении эффективности процесса обучения. Для этого потребовалось внести ряд инновационных изменений.
Во-первых, чтобы улучшить возможности моделирования пространственно-временных отношений, команда применяет механизм пространственно-временного полного внимания, что позволяет модели более точно имитировать сложную динамику реального мира. Во-вторых, внедрение механизма разделения параметров позволяет эффективно снизить стоимость обучения и одновременно повысить производительность. Кроме того, команда оптимизировала работу по встраиванию текста, используя механизм перекрестного внимания для встраивания текстовых признаков, что позволяет добиться лучшей управляемости текстом и снизить вычислительные требования.
Благодаря этим улучшениям и попыткам структура DiT обобщенной универсальной фазы достигает более выраженного превосходства в сходимости при тех же вычислительных затратах.
Помимо инноваций в архитектуре модели, командаНекоторые оптимизации были сделаны в области обучения и вывода сверхдлинных последовательностей, конвейера построения данных и оценки моделей, а такжечто позволяет модели эффективно решать сложные генеративные задачи с повышенной эффективностью.
Как эффективно тренироваться с миллионами сверхдлинных последовательностей
При работе со сверхдлинными визуальными последовательностями большие модели часто сталкиваются с проблемами на разных уровнях, такими как вычисления, память, стабильность обучения, задержка вывода, и поэтому для их решения требуются эффективные решения.
Для этого команда объединила характеристики рабочей нагрузки новой модели и аппаратную производительность обучающего кластера, чтобы разработать распределенную, оптимизированную по памяти стратегию обучения для оптимизации производительности обучения при условии гарантии времени итерации модели, и в итогеДостигнуто лучшее в отрасли значение MFU и эффективное обучение 1 млн сверхдлинных последовательностей.
С одной стороны, команда внедряет инновационную стратегию распределенного обучения, используя 4D параллельное обучение с DP, FSDP, RingAttention и Ulysses, что повышает как производительность обучения, так и масштабируемость распределения. С другой стороны, для оптимизации памяти команда использует иерархическую стратегию оптимизации памяти, чтобы оптимизировать память активации и решить проблему фрагментации памяти на основе объема вычислений и коммуникаций, вызванных длиной последовательности.
Кроме того, оптимизация вычислений может повысить эффективность обучения моделей и сэкономить ресурсы. Поэтому команда использует FlashAttention3 для пространственно-временного расчета полного внимания и выбирает подходящую стратегию CP для разбиения, принимая во внимание вычислительную производительность обучающих кластеров разного размера. В то же время команда устраняет вычислительную избыточность для некоторых ключевых модулей, а также снижает накладные расходы на доступ и повышает вычислительную эффективность за счет эффективной реализации ядра. Что касается файловой системы, то команда в полной мере использует характеристики чтения/записи высокопроизводительной файловой системы в учебном кластере AliCloud и повышает производительность чтения/записи с помощью срезов Save/Load.

Стратегия параллельного распределенного обучения 4D
В то же время команда выбрала схему поэтапного использования памяти, чтобы решить проблемы OOM, вызванные предварительной выборкой данных из загрузчика, разгрузкой процессора и сохранением контрольной точки во время обучения. Кроме того, для обеспечения стабильности обучения команда использовала интеллектуальное планирование, обнаружение медленных машин и возможности самовосстановления учебных кластеров AliCloud для автоматического определения неисправных узлов и быстрого перезапуска задач.
Внедрение автоматизации при построении данных и оценке моделей
Обучение крупных моделей генерации видео невозможно без высококачественных данных в масштабе и эффективной оценки моделейПервый обеспечивает обучение модели различным сценариям, сложным пространственно-временным зависимостям и улучшает обобщение, составляя краеугольный камень обучения модели; второй помогает контролировать работу модели, чтобы она лучше достигала ожидаемых результатов, становясь флюгером обучения модели.
Что касается построения данных, команда создала автоматизированный конвейер построения данных с высоким качеством в качестве критерия, который в значительной степени соответствует распределению человеческих предпочтений с точки зрения визуального качества, качества движения и т.д., так что высококачественные видеоданные могут быть автоматически построены с высоким разнообразием, сбалансированным распределением и другими характеристиками.
Для оценки моделей команда разработала обширный набор автоматизированных метрик, включающий более двух десятков параметров, таких как эстетическая оценка, анализ движений и соблюдение команд, а также наняла и обучила профессиональных оценщиков, способных согласовывать свои действия с предпочтениями человека. Благодаря эффективной обратной связи с этими метриками процесс итерации и оптимизации модели значительно ускорился.
Можно сказать, что синергетические инновации в нескольких аспектах, таких как архитектура, обучение и оценка, позволили обновленной модели генерации видео Tongyi Wanphase добиться значительных улучшений в реальном опыте.
Моменты GPT-3 для создания видеоСколько еще осталось?
С февраля прошлого года OpenAI Сора С момента своего появления модель генерации видео стала самой конкурентной областью в мире технологий. От отечественных до зарубежных стартапов и технологических гигантов запускают свои собственные инструменты для генерации видео. Однако по сравнению с генерацией текста, ИИ видео представляет собой более чем один уровень сложности для достижения степени приемлемости.
Если, как говорит генеральный директор OpenAI Сэм Альтман, Sora представляет собой момент GPT-1 в грандиозной модели генерации видео, то на его основе мы сможем достичь точного контроля над текстовыми командами и возможности регулировать ракурсы и положение камеры для обеспечения согласованности персонажей. Если на этой основе мы добьемся точного управления ИИ с помощью текстовых команд, регулируемых ракурсов и положения камеры, последовательного создания персонажей и других возможностей генерации видео, а также добавим уникальную способность ИИ быстро менять стили и сцены, то вскоре мы сможем увидеть новый "момент GPT-3".
С точки зрения пути развития технологий, модель генерации видео - это процесс проверки законов масштабирования. По мере совершенствования возможностей базовой модели ИИ будет все лучше понимать команды человека и сможет создавать все более реалистичное и разумное окружение.
С практической точки зрения, ждать уже не приходится: с прошлого года люди, работающие в сфере короткометражного видео, анимации и даже кино и телевидения, начали использовать ИИ для творческих поисков. Если мы сможем преодолеть ограничения реальности и сделать ранее невообразимые вещи с помощью ИИ видеогенерации, то новый виток изменений в индустрии не за горами.
Теперь, похоже, Тунъи Мэнсян сделал первый шаг.
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи



Нет комментариев...