
Сложные задачи олимпиадного уровня: обзор 7 основных контрольных работ по математике для LLM в Китае

Математические способности, включающие в себя вывод формул, построение логических цепочек и абстрактное мышление, уже давно считаются ключевой областью для проверки возможностей искусственного интеллекта (ИИ), в частности крупномасштабных языковых моделей (LLM). Это связано не только с проверкой вычислительной мощности, но и с более глубоким изучением способности модели рассуждать, понимать и решать сложные проблемы.
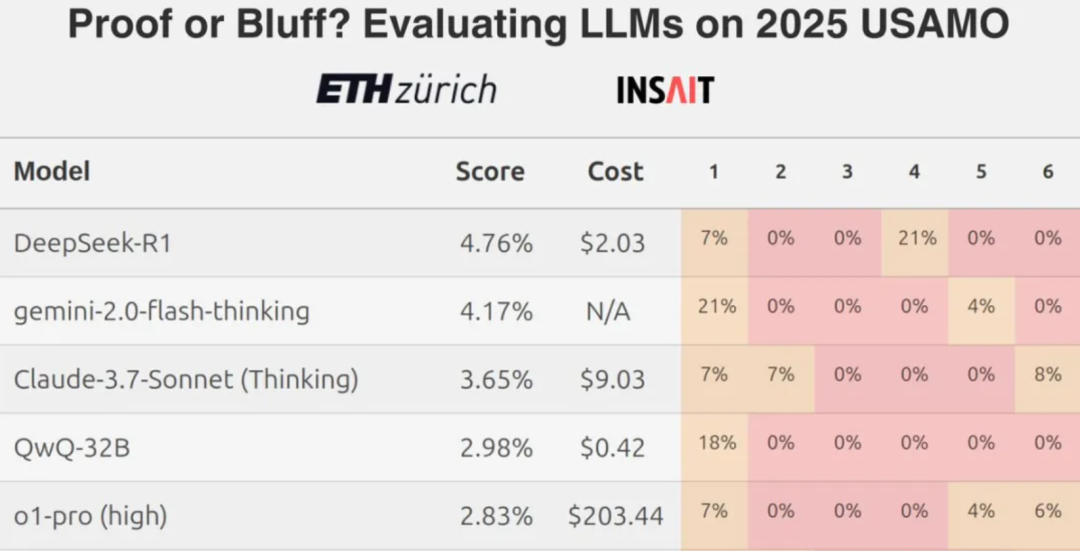
Однако недавние результаты, полученные командой из ETH Zurich, показывают, что даже лучшие модели больших языков (LLM) обычно показывают низкие результаты, когда сталкиваются со сложными математическими конкурсными вопросами, такими как задачи уровня Математической олимпиады США, что побуждает к дискуссии об истинных возможностях современных LLM в плане строгих математических рассуждений.
В связи с этим возникает естественный вопрос: насколько хорошо эти модели справляются с математическими задачами, сформулированными на китайском языке? В данном обзоре было отобрано в общей сложности семь основных или новых крупномасштабных языковых моделей из страны и из-за рубежа, чтобы сравнить их математические способности с помощью задач из Alibaba Global Maths Competition и Китайской математической олимпиады.
В испытаниях участвуют такие модели, как:
- Отечественные модели:
DeepSeek R1, иHunyuan T1, иTongyi Qwen-32B(оригинальный текст)通义QwQ-32B),YiXin-Distill-Qwen-72B - Международное моделирование:
Grok 3 beta, иGemini 2.0 Flash Thinking, иo3-mini
Общая оценка работы
Тест состоит из 10 вопросов высокого уровня сложности, всего 13 вопросов с оценкой. Критерии оценки: 1 балл за полную правильность, 0,5 балла за частичную правильность и отсутствие баллов за ошибки.
Общая корректность каждой модели в этом тесте выглядит следующим образом:

Детальное распределение баллов показывает разницу в производительности между моделями:
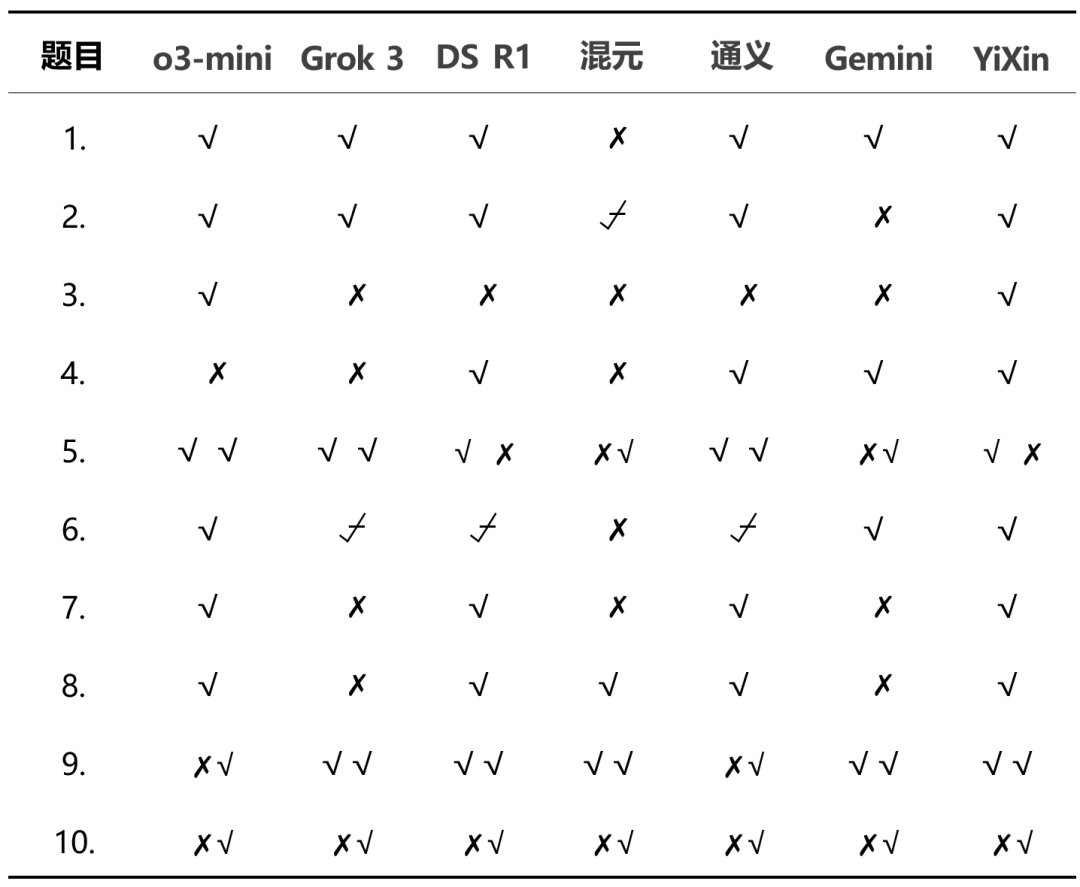
Из общих результатов.o3-mini ответить пением YiXin-Distill-Qwen-72B отлично справились с этим тестом, продемонстрировав сильные навыки решения математических задач. Показатели других моделей варьировались.
Далее приведены конкретные ответы на некоторые вопросы теста.
Детали измерения
Раунд 1: Проблема перемен
Вопрос: У дедушки есть 60 долларов, и он идет в супермаркет, чтобы купить овощи на 20 долларов, как кассир может выдать дедушке сдачу?
Анализ: Это базовый прикладной арифметический вопрос, который проверяет понимание моделью жизненных сценариев и базовых навыков подсчета денег.
Результаты:o3-mini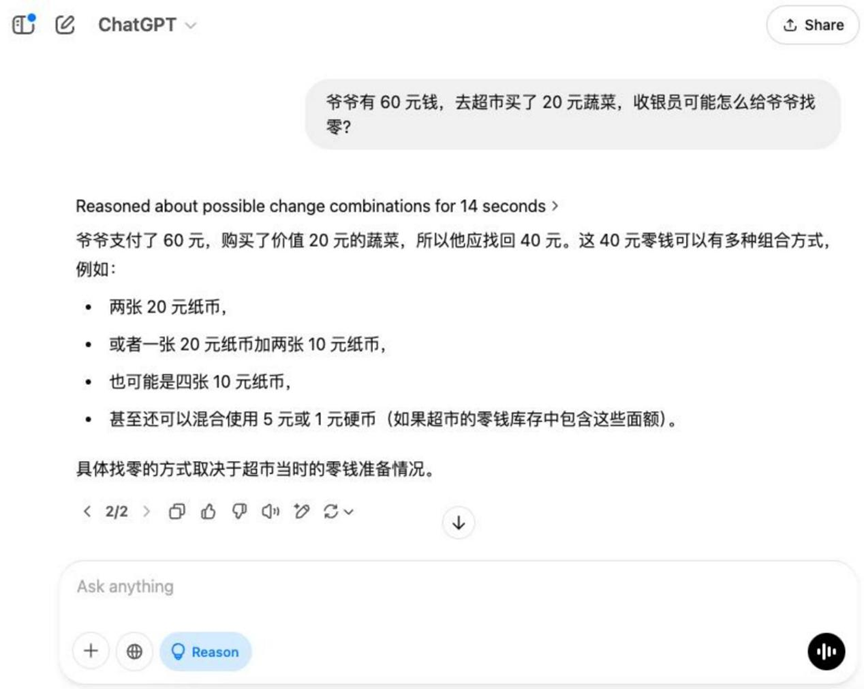
Grok 3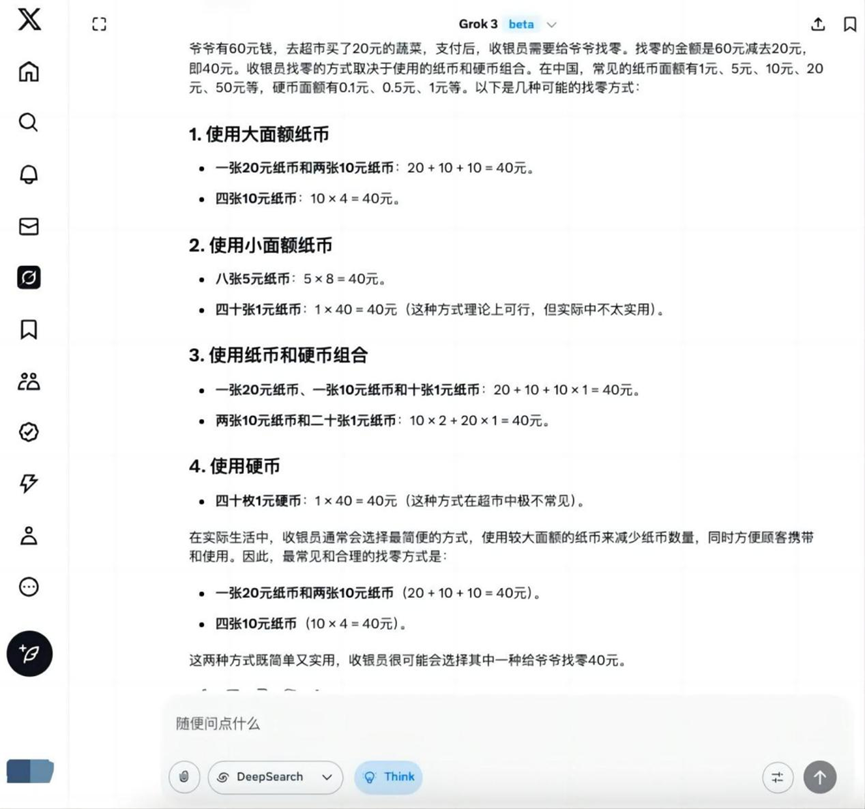
Hunyuan T1
Gemini 2.0 Flash Thinking
YiXin-Distill-Qwen-72B
На эту основную тему, в дополнение к Hunyuan T1 За исключением этого, остальные модели дают правильное решение для нахождения нуля.
Раунд 2: Расчет расстояний, пройденных пешком, и методологические оценки
Вопрос: Сяо Мин и Сяо Хуа ходят в школу каждый день. Мин проходит 48 метров в минуту, а Хуа - 55 метров в минуту. Дом Сяомина находится в 384 метрах от школы. Сяохуа требуется на 4 минуты больше времени, чем Мину, чтобы добраться от дома до школы. Как далеко находится дом Сяохуа от школы? Какой из следующих методов неверен и почему?
Метод 1: 55 × 4 = 220 (метров), 384 + 220 = 604 (метров)
Метод 2: 384 / 48 = 8 (минут), 55 × (8 + 4) = 660 (метров)
Анализ: Этот вопрос сочетает в себе вычисление путевых задач и логическое мышление, требуя от модели не только вычислить правильный ответ, но и уметь анализировать правильность или неправильность заданного решения, проверяя многоступенчатость рассуждений и логическую проницательность.
Результаты:DeepSeek R1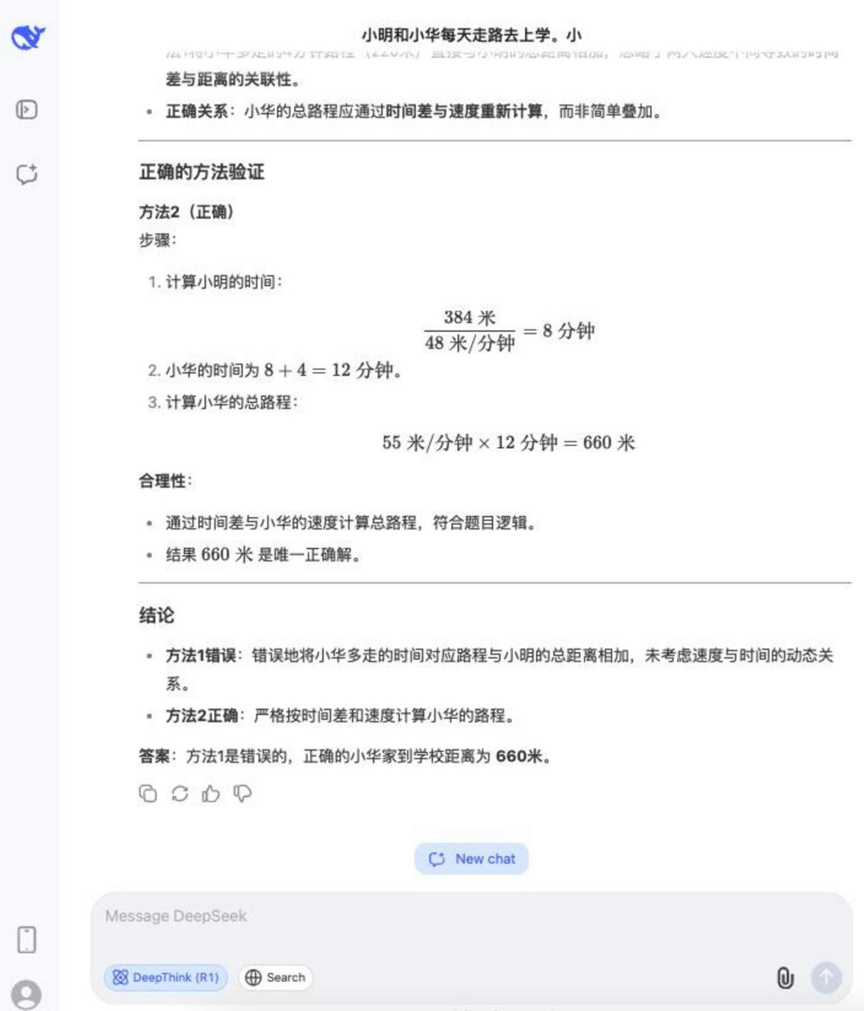
Tongyi Qwen-32B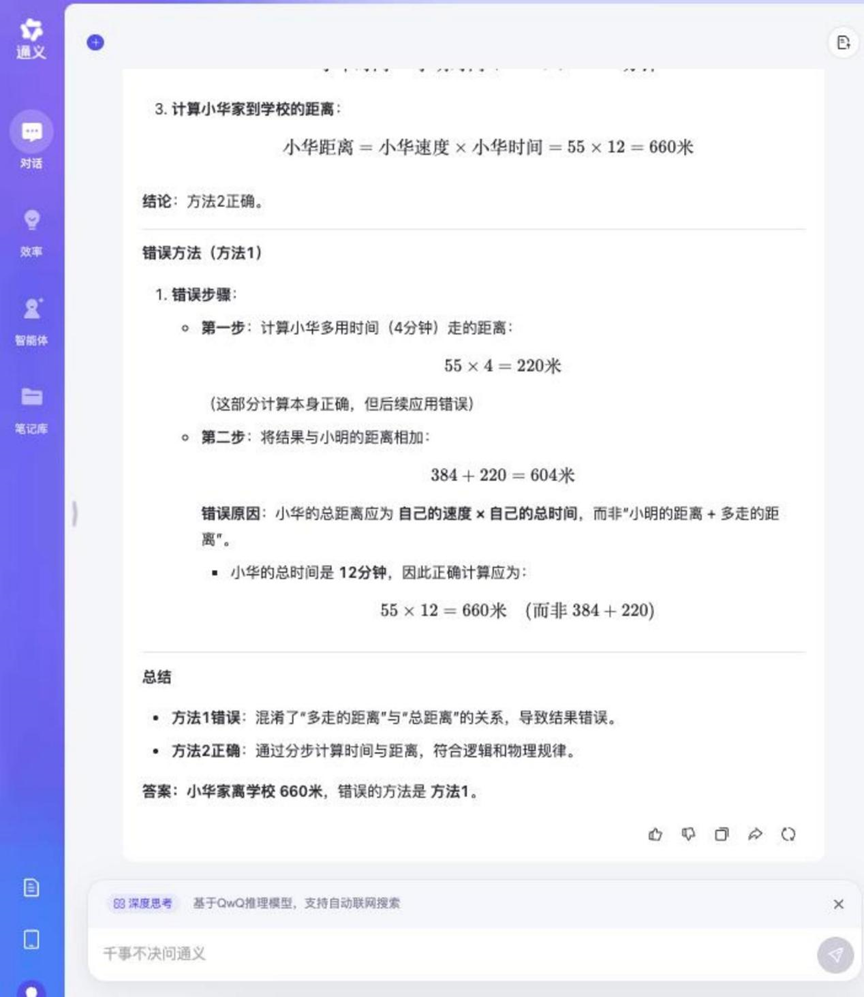
YiXin-Distill-Qwen-72B
Процесс рассуждения над этим вопросом был довольно долгим, но большинство моделей, участвовавших в тесте, смогли ответить на него правильно и определить неверный метод.
Раунд 3: Проблема геометрической окклюзии (невидимые башни)
Вопрос: В городе есть 6 башен, расположенных в точках A, B, C, D, E и F. Несколько студентов объединяются в туристическую группу, чтобы отправиться в свободное путешествие по городу. Через некоторое время каждый из студентов понимает, что может видеть только 4 башни, расположенные в точках A, B, C и D, но не башни, расположенные в точках E и F. Известно, что положения студентов и башен считаются точками одной плоскости и что эти точки не совпадают друг с другом, и что любые 3 точки A, B, C, D, E и F не имеют общей прямой. Единственная возможность не увидеть башню - это если линия видимости перекрыта другой башней. Например, если ученик находится в точке P, которая расположена совместно с точками A и B, а точка A находится на отрезке прямой PB, то он не сможет увидеть башню, расположенную в точке B. Спросите: каково максимальное количество учеников, которые могут быть в этой группе путешественников? a. 3 b. 4 c. 6 d. 12
Анализ: Это сложный геометрический и логический вопрос, включающий вопросы видимости, окклюзии и конфигурации набора точек, который требует высокого уровня пространственного воображения и логического мышления в модели.
Результаты:o3-mini
DeepSeek R1
YiXin-Distill-Qwen-72B
Сложность вопросов значительно возросла. В этом раунде тестирования только o3-mini ответить пением YiXin-Distill-Qwen-72B успешно решены, остальные модели не дали правильного ответа.
Раунд 4: Проблемы вероятности (Тигры и тигрята)
Вопрос: Во время Праздника весны одна из молочных компаний запустила акцию "Китайский Новый год вслепую": каждая коробка молока поставляется с "красным пакетом", на котором изображен "Тигр" "Шенг" Вэй" - один из трех рисунков. Собрав два "Тигра", "Шенг" и "Вэй", можно составить семейный портрет "Тигр Тигр Шенг Вэй". Как только мероприятие было запущено, оно стало хитом Netflix и привлекло к участию множество людей. Известны следующие условия: узоры на красных пакетах распределены случайным образом независимо друг от друга и не могут быть отличимы друг от друга. Вероятность появления трех узоров "Тигр", "Шенг" и "Вэй" равна 1/3. Вопрос: Чтобы собрать полный набор "Тигр Тигр Шенг Вэй Вопрос: Сколько пакетов молока в среднем нужно купить, чтобы собрать полный набор семейных фотографий "Тигр, тигр, могучий"?
Анализ: Это типичная задача коллекционера (вариант задачи коллекционера Coupon), которая требует использования теории вероятности и вычисления ожиданий, и проверяет способность модели работать с вероятностными моделями и выполнять математические вычисления ожиданий.
Результаты:DeepSeek R1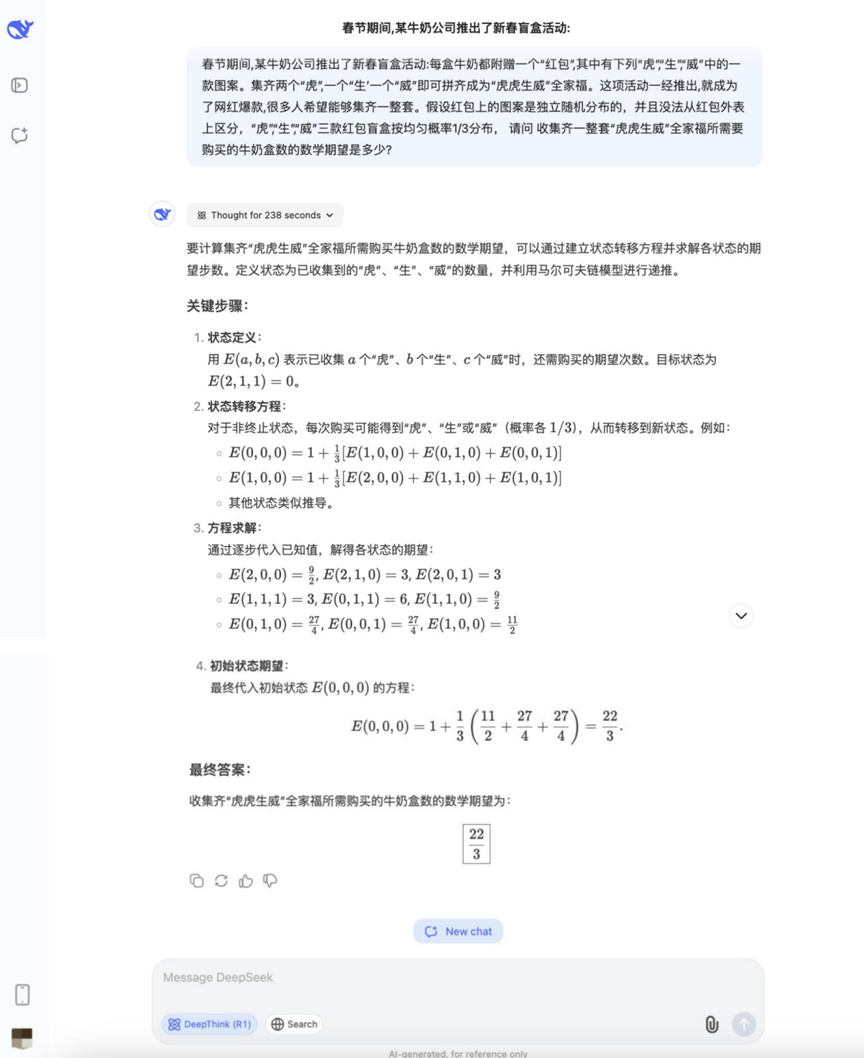
Hunyuan T1
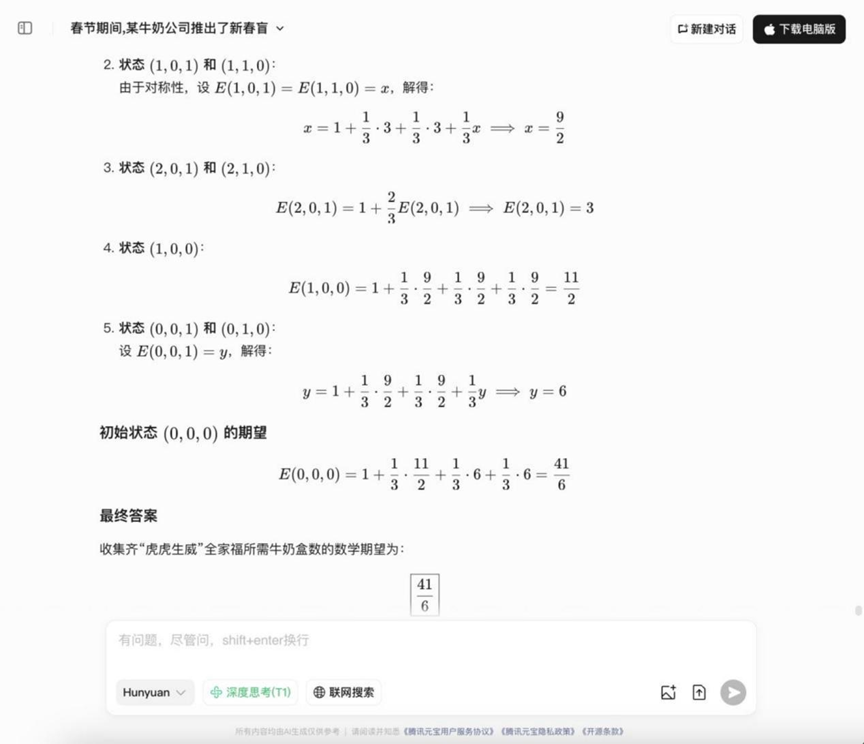
YiXin-Distill-Qwen-72B
Ответы на вопросы о вероятности в этом раунде начали расходиться: некоторые модели смогли правильно перечислить идеи и рассчитать их.
Раунд 5: Геометрия и планирование пути (Игры-бои)
Описание проблемы Изображение:
Анализ: Эта задача сочетает в себе геометрию, системы координат или сетки, кратчайший путь/оптимальные стратегии, и может потребовать от модели понимания графической информации и выполнения пространственных рассуждений и планирования.
Результаты:o3-mini: Успешное решение
YiXin-Distill-Qwen-72B: Частично верно

Этот этап тестирования требует более высокой степени интеграции моделей, при этом около половины протестированных моделей были обработаны полностью корректно.
Раунд 6: Задачи на доказательство теории чисел (поиск минимальных нефакторов)
Описание проблемы Изображение:
Анализ: Переходя в сферу вопросов доказательства, которые требуют строгих логических выводов и глубокого понимания концепций теории чисел, эти вопросы являются прямой проверкой способности модели к абстрактным рассуждениям.
Результаты:o3-mini
YiXin-Distill-Qwen-72B

В отечественном моделированииYiXin-Distill-Qwen-72B Лучше справился с вопросами по доказательству. Вопросы на доказательство были значительно сложнее для модели.
Раунд 7: Функции и задачи на отображение (отображение на единичном круге)
Описание проблемы Изображение:
Анализ: В этом вопросе рассматриваются понятия функций, отображений и единичного круга в высшей математике, а также проверяется способность модели понимать и применять абстрактные математические определения.
Результаты:o3-mini
YiXin-Distill-Qwen-72B
Около половины моделей смогли правильно решить эту задачу с использованием абстрактных отображений.
Раунд 8: Комбинаторные задачи оптимизации (Максимальный треугольник)
Вопрос: В пространстве существует 1989 точек, любые три из которых не имеют общей прямой. Эти точки разделены на 30 групп, в каждой из которых разное количество точек. Треугольник можно построить, взяв в качестве вершины точку из любых трех групп. Вопрос: Как распределить количество точек в каждой группе так, чтобы количество образовавшихся треугольников было максимальным?
Анализ: Это оптимизационная задача по комбинаторной математике, которая требует от модели понимания принципов комбинаторного счета и нахождения оптимальной стратегии распределения, что предполагает более сложное математическое моделирование и оптимизационные идеи.
Результаты:o3-mini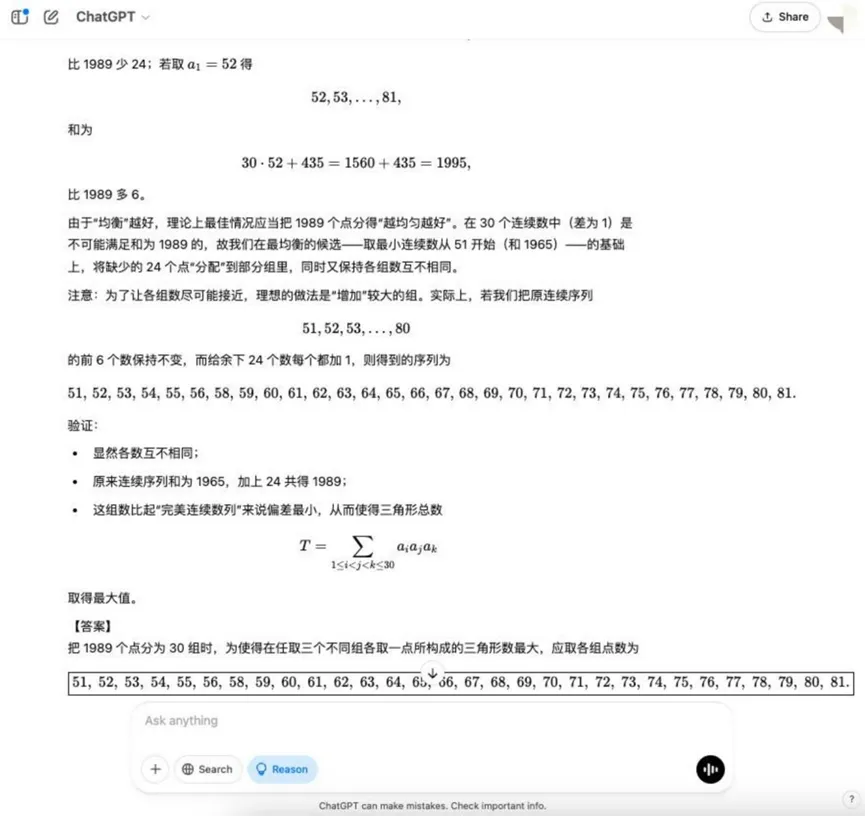
YiXin-Distill-Qwen-72B

Комбинаторные оптимизационные задачи еще больше повышают сложность и предъявляют повышенные требования к математическим стратегиям и вычислительным навыкам модели.
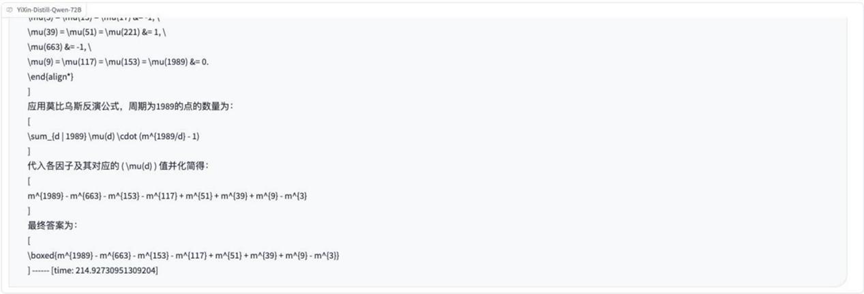
Раунд 9: Задачи по теории чисел (цепочки коэффициентов)
Описание проблемы Изображение:
Анализ: Снова задействованы теоретико-числовые понятия, проверяющие понимание и применение в модели таких отношений, как факториалы и интегралы, что может потребовать конструктивных доказательств или подсчетов.
Результаты:o3-mini: Частично верно
YiXin-Distill-Qwen-72B: Абсолютно верно.

YiXin-Distill-Qwen-72B Солидное выступление на эту счетную тему.
Раунд 10: Геометрические задачи (точки равной площади)
Описание проблемы Изображение:
Анализ: Последний вопрос был геометрическим и включал в себя вычисления площадей, траекторий движения точек или доказательства существования, проверяя геометрическую интуицию модели, алгебраические операции и логическое мышление.
Результаты:o3-mini
DeepSeek R1
YiXin-Distill-Qwen-72B

Итоговые вопросы по геометрии также показали различия между моделями в их способности решать сложные геометрические задачи.
Наблюдения и анализ
Основываясь на этой проверке математических способностей китайцев на ряде больших языковых моделей, можно сделать следующие выводы:
- Значительно улучшилось моделирование базовых математических навыков: По сравнению с более ранними моделями, нынешнее поколение LLM демонстрирует значительное улучшение в решении математических задач с многошаговыми рассуждениями, таких как геометрия, вероятность и некоторые открытые прикладные задачи. Это можно объяснить увеличением размера модели, большим количеством обучающих данных и использованием техник улучшения рассуждений, таких как "цепочки мыслей".
- Существуют различия в стилях решения проблем: Разные модели ведут себя по-разному с точки зрения уровня детализации процесса решения.
o3-mini,Grok 3 beta,Tongyi Qwen-32BВывод относительно лаконичен, а шаги по созданию выводов просты.DeepSeek R1,Hunyuan T1,YiXin-Distill-Qwen-72BТенденция демонстрировать более подробные мыслительные процессы, иногда включающие шаги по осмыслению и коррекции, более "многословна", но это может помочь проследить логику их рассуждений.Gemini 2.0 Flash ThinkingПроцесс решения задач не только длительный, но и использует в основном английский язык, что говорит о том, что он может быть относительно плохо обучен на китайском математическом корпусе.
- Устойчивость к ошибкам ввода: В ходе тестирования было замечено, что даже при наличии незначительных ошибок в обозначениях или неровностей в описании задачи некоторые модели все равно способны правильно понять смысл вопроса и ответить на него, демонстрируя определенную устойчивость. Однако это не означает, что модели всегда могут игнорировать ошибки, и ошибки в критической информации все равно могут привести к неудачному ответу.
- Будущие усовершенствования: специализация и интеграция инструментов: Несмотря на очевидный прогресс, все еще есть возможности для повышения точности текущего LLM при решении сложных математических задач, особенно в сложных конкурсных вопросах и сценариях, требующих строгих доказательств. Будущие пути совершенствования могут включать в себя:
- Интеграция внешних вычислительных машин: Недостатки LLM в плане точных вычислений и символьных операций компенсируются обращением к инструментам символьных вычислений, таким как Wolfram Alpha.
- Эксклюзивная тонкая настройка домена: Создание высококачественных наборов данных с тонкой настройкой для математической логики, конкретных отраслей математики (например, алгебры, геометрии, теории вероятностей), а также укрепление моделей для экспертных рассуждений и глубины знаний.
- Интерактивное обучение и пересмотр: Разработайте механизмы, которые позволят пользователю направлять процесс решения, указывать на ошибки и позволят модели динамически корректировать стратегию решения.
- Совет пользователям:
- Студенты: LLM можно использовать для помощи в обучении, быстро проверяя решения и ответы на основные вопросы. Однако при решении сложных или творческих задач следует опасаться того, что модель может "нести чушь" (т. е. уверенно давать неправильный ответ).
- Педагоги: При использовании обучения с помощью ИИ необходимо разрабатывать вопросы, которые с большей вероятностью проверят глубокое понимание и навыки независимого мышления учащихся, чтобы они не полагались на модели для получения поверхностных ответов.
- Разработчик: При применении LLM для решения математических задач границы задачи и требования к решению должны быть уточнены путем оптимизации Prompt Engineering, чтобы уменьшить количество неэффективных рассуждений или "мозгового штурма" со стороны модели из-за нечеткого понимания.
В заключение следует отметить, что применение крупномасштабных языковых моделей в математике постепенно переходит от исследовательской стадии к практической. Будущее направление развития моделей будет заключаться в поиске лучшего баланса между имитацией гибкости человеческого мышления и обеспечением строгости математической логики.
Примечания:
Лучшие исполнители в этом обзоре YiXin-Distill-Qwen-72B Информация о модели выглядит следующим образом:
- Стандартная версия: https://huggingface.co/YiXin-AILab/YiXin-Distill-Qwen-72B
- Количественное издание AWQ: https://huggingface.co/YiXin-AILab/YiXin-Distill-Qwen-72B-AWQ
- Требования к ресурсам для локального развертывания: 72B Standard Edition требует примерно 8 видеокарт класса NVIDIA 4090; AWQ Quantitative Edition может работать на 2 картах того же класса.
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи



Нет комментариев...