Think&Cite: Повышение точности цитирования текста с помощью методов древовидного поиска

рефераты
Хотя большие языковые модели (LLM) работают хорошо, они склонны к галлюцинациям и созданию фактологически неточной информации. Эта проблема послужила стимулом для работы над созданием атрибутивного текста, который побуждает LLM генерировать контент, содержащий подтверждающие доказательства. В этой статье мы предлагаем новую структуру под названием Think&Cite и формулируем генерацию атрибутивного текста как многоэтапную задачу рассуждения с интегрированным поиском. В частности, мы предлагаем Self-Guided Monte Carlo Tree Search (SG-MCTS), который использует способность LLM к саморефлексии, чтобы размышлять о промежуточных состояниях MCTS, тем самым направляя процесс расширения дерева. Для обеспечения надежной и всесторонней обратной связи мы ввели модель вознаграждения за прогресс (PRM), которая измеряет прогресс поиска дерева от корневого узла до текущего состояния как с точки зрения генерации, так и с точки зрения атрибутов. Мы провели обширные эксперименты на трех наборах данных, и результаты показали, что наш метод значительно превосходит базовый метод.
1 Введение
Крупномасштабные языковые модели (LLM) (Zhao et al., 2023) отлично справляются со многими задачами обработки естественного языка. Несмотря на эти достижения, ЛЛМ часто генерируют ответы, содержащие иллюзорную и неточную информацию (Ji et al., 2023; Huang et al., 2023; Zhang et al., 2023). Эта проблема ставит под угрозу их надежность и, что более важно, доверие пользователей к LLM. Для повышения надежности LLM была предложена новая парадигма генерации - генерация атрибутивного текста, которая позволяет LLM генерировать ответы, содержащие внутритекстовые цитаты для предоставления доказательств (Gao et al., 2023b), как показано на рисунке 1.

Рисунок 1. Получив вопрос, модель генерирует текст, приводя отрывки из корпуса в качестве подтверждающих доказательств.
Большинство существующих работ (Slobodkin et al., 2024; Sun et al., 2024; Fierro et al., 2024) просто предлагают LLM предоставить цитаты при генерации текста. Кроме того, в других работах (Li et al., 2024; Huang et al., 2024) предпринимаются попытки точной настройки LLM на больших объемах контролируемых обучающих данных, содержащих текст с аннотированными цитатами. Несмотря на эти недавние попытки, разработка LLM, которые учатся генерировать достоверный контент с надежными цитатами, остается нерешенной задачей. Во-первых, существующие методы используют авторегрессионную парадигму генерации, которую можно охарактеризовать как "систему 1", быстрый и инстинктивный способ мышления, но недостаточно точный (Kahneman, 2011). В результате любая промежуточная ошибка генерации (например, искажение или неверное цитирование) может привести к неправильному окончательному ответу. Вдохновленные исследованиями сложных рассуждений (Zhang et al., 2024; Wang et al., 2024), мы стремились разработать модель парадигмы "Система 2" для цитирования внешних доказательств, которая требует более глубокого, тщательного и логического мышления (Kahneman, 2011). Во-вторых, генерация атрибутивного текста часто предполагает создание длинного текста. Лю и др. (2023) обнаружили, что длинные ответы на существующие LLM часто содержат неподтвержденные утверждения и неточные цитаты. Мы утверждаем, что отсутствие явного планирования генерации в предыдущих работах сдерживает прогресс таких систем.
В этой статье мы представляем Think&Cite, новый фреймворк для интеграции поисковых алгоритмов в генерацию атрибутивного текста. Мы концептуализируем задачу генерации как многоступенчатую проблему вывода, в которой модель генерирует предложение на каждом шаге с помощью итеративной парадигмы "думай-выражай-ссылка". Чтобы улучшить этот генеративный процесс, мы предлагаем самонаводящийся поиск по дереву Монте-Карло (SG-MCTS), который расширяет классический MCTS с помощью двух инноваций. Во-первых, наш подход использует способность LLM к саморефлексии для размышления о промежуточных состояниях MCTS в реальном времени, тем самым направляя процесс расширения дерева и активно избегая неадекватных путей вывода. Это контрастирует с предыдущими работами, которые в основном размышляют о конечном результате или полной траектории. Во-вторых, мы предлагаем модель вознаграждения за прогресс (PRM), которая измеряет прогресс поиска дерева от корневого узла до текущего состояния как с точки зрения генерации, так и с точки зрения атрибутов. В отличие от оценки только отдельных шагов, модель вознаграждения, основанная на прогрессе, обеспечивает надежную и всестороннюю оценку для управления процессом поиска MCTS.
Насколько нам известно, мы впервые применили алгоритм древовидного поиска к задаче генерации атрибутивного текста. Мы провели обширные эксперименты на трех наборах данных, чтобы подтвердить эффективность нашего подхода. Результаты показывают, что наша модель значительно превосходит предыдущие подсказки и тонко настроенные базовые модели.
2 Похожие работы
Генерация текста с атрибуцией. Большие языковые модели (БЯМ) используются для генерации текстов с атрибуцией благодаря своим превосходным возможностям генерации языка (Gao et al., 2023b; Huang et al., 2024; Sun et al., 2024; Li et al., 2024; Slobodkin et al., 2024). БЯМ для генерации текстов с атрибуцией можно в целом разделить на две категории. Генерируемые работы можно условно разделить на две категории. Первый тип предполагает тонкую настройку LLM с помощью обучения предпочтениям (Li et al., 2024) и обучения с подкреплением (Huang et al., 2024), которые учат LLM генерировать поддерживающие и релевантные цитаты, чтобы получить более высокое вознаграждение. Однако этот подход зависит от человека, который должен собрать высококачественные наборы данных с аннотированными внутритекстовыми ссылками. Другой класс работ напрямую обучает LLM генерировать текст с атрибуциями через планирование атрибуции и генерации (Slobodkin et al., 2024) или использование внешнего валидатора для управления генерацией (Sun et al., 2024). Однако при таком подходе текст и цитаты генерируются авторегрессионным способом, где любая неточная промежуточная генерация чревата неудачей в последующем процессе. В отличие от этого, наш подход предлагает самонаводящийся поиск по дереву с прогрессивным вознаграждением для рассмотрения нескольких путей.
LLM с древовидным поиском: интеграция алгоритмов древовидного поиска с LLM привлекает значительное внимание. В недавних исследованиях изучалось использование методов древовидного поиска для повышения производительности LLM в процессе вывода (Zhang et al., 2024; Wang et al., 2024; Ye and Ng, 2024).Sutton (2019) подчеркнул превосходство масштабирования в обучении и поиске над другими методами. Эмпирические данные также свидетельствуют о том, что увеличение времени вычислений может значительно улучшить производительность ОДУ без необходимости дополнительного обучения (Brown et al., 2024; Snell et al., 2024).Поиск (Hart et al., 1968) и поиск по дереву Монте-Карло (MCTS) (Browne et al., 2012) используются в качестве методов планирования для улучшения производительности LLM при решении сложных задач вывода. Эти алгоритмы поиска широко используются в обучении с подкреплением (Silver et al., 2017) и во многих реальных приложениях, таких как AlphaGo (Silver et al., 2016). В нашей работе мы впервые применили алгоритм поиска по дереву (т. е. поиск по дереву Монте-Карло) для решения задачи генерации текста с атрибуцией. Кроме того, мы предлагаем самонаводящийся MCTS, который опирается на рефлексивную способность LLM для улучшения расширения дерева.
3 Формулировка проблемы
Предлагаемая нами схема позволяет использовать предварительно обученный LLM Mθ Генерирование ответов с внутритекстовыми ссылками, которые служат доказательством содержания вывода, называется генерацией текста с атрибуцией (Слободкин и др., 2024; Gao et al., 2023a).
Формально, если задан входной вопрос x и корпус текстовых отрывков D, то модель Mθ Необходимо сгенерировать ответ y = (y 1 , ... , y T ), ответ состоит из T предложений, где каждое предложение yt Ссылки на список параграфов из D, обозначаемые как Ct = {C t,1 , ... , C t,m } Ввиду предельной выгоды от объединения большего количества ссылок (Gao et al., 2023b), в данной работе мы допускаем до трех ссылок на одно предложение (m ≤ 3), и они заключены в квадратные скобки, например, [1][2]. Мы также фокусируемся на наукоемких сценариях, где проблема включает знания о мире и где большинство предложений в LLM содержат несколько фактов и требуют подтверждающих цитат в качестве доказательства. Следуя предыдущим работам (Gao et al., 2023b; Piktus et al., 2021), мы разделили корпус D на абзацы по 100 слов для поиска, что облегчает проверку человеком и не вносит слишком много нерелевантной информации.
Используя итеративную парадигму "думай-выражай-цитируй", мы предлагаем Self-Guided Monte Carlo Tree Search (SG-MCTS), который расширяет классический MCTS за счет двух инноваций. Чтобы улучшить этот генеративный процесс, мы предлагаем Self-Guided Monte Carlo Tree Search (SG-MCTS), который расширяет классическую MCTS за счет двух инноваций. Во-первых, наш подход использует саморефлексивные возможности LLM, чтобы в режиме реального времени размышлять о промежуточных состояниях MCTS, тем самым направляя процесс расширения дерева и заблаговременно избегая недостаточных путей умозаключений. Это противоположно предыдущим работам, в которых отражался в основном конечный результат или полная траектория. Во-вторых, мы предлагаем модель вознаграждения за прогресс (PRM) для измерения прогресса в поиске дерева от корневого узла до текущего состояния с точки зрения двух аспектов, т. е. прогресса генерации и прогресса атрибуции. По сравнению с оценкой только отдельных шагов, модель вознаграждения, основанная на прогрессе, может обеспечить надежную и всестороннюю оценку для руководства процессом поиска MCTS.
Насколько нам известно, мы впервые применили алгоритм древовидного поиска к задаче генерации текста с атрибуцией. Мы провели обширные эксперименты на трех наборах данных, чтобы проверить эффективность нашего подхода. Результаты показывают, что наша модель значительно превосходит предыдущие базовые модели, основанные на подсказках и точной настройке.

Рисунок 2: Общая схема предлагаемого нами подхода Think&Cite.
4 Методология
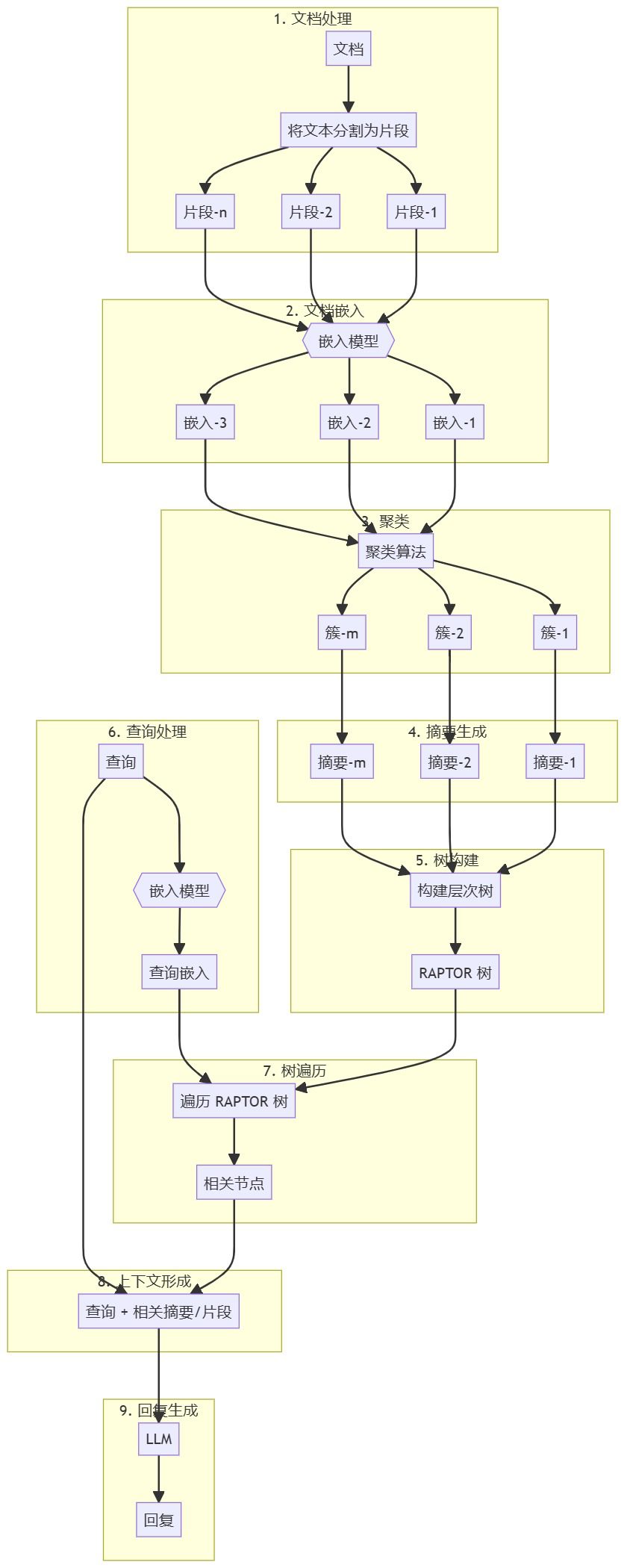
Предлагаемый фреймворк THINK&CITE построен на языковом агенте для генерации атрибутивного текста, который использует Self-Guided Monte Carlo Tree Search (SG-MCTS) для планирования и поиска нескольких генеративных путей, а также Progress Reward Modelling (PRM) для обеспечения асимптотически тонких сигналов о процессе поиска. На рисунке 2 показана общая архитектура нашего подхода.
4.1 Агент генерации атрибутивного текста
Вдохновленные предыдущими работами (Yao et al., 2022; Chen et al., 2023), мы разрабатываем лингвистического агента для решения задачи генерации текста с атрибуцией, который выполняет итеративный процесс "думать-вербализовать-цитировать", используя возможности LLM в области умозаключений и планирования.
Итеративное мышление-вербализация-цитирование. Чтобы сгенерировать t-е предложение, агент сначала активно думает о следующем генерируемом образце (например, теме контента или аннотации) в виде поискового запроса q t Затем агент использует инструмент поиска для получения наиболее релевантных топ-K абзацев D из заданного корпуса D с помощью операции "Поиск" (т. е. "Поиск: {запрос}"). Затем агент использует инструмент поиска для получения наиболее релевантных топ-K абзацев D из данного корпуса D с помощью операции "Поиск" (т. е. "Поиск: {запрос}"). t . На основе найденных отрывков агент с помощью операции Generate (т. е. "Generate: {sentence}") ссылается на текст из Dt Список параграфов Ct чтобы выразить предложение y t . Исторический запрос, найденные абзацы, сгенерированные предложения и цитаты (обозначенные как H = {(q i , D i , y i , C i )}^t^ i=1 ) будет использоваться как контекст для следующего шага мышления и выражения. Если агент считает задачу решенной, он может вывести "End", чтобы завершить процесс. Таким образом, агент может продуманно планировать и извлекать различную информацию, динамически учитывать изменения в фокусе содержания по мере генерации, в отличие от предыдущих работ, которые опирались на статичные эталонные корпорации (Слободкин и др., 2024; Huang et al. ..., 2024), отличается. Более того, эта парадигма схожа с недавними работами по итеративной генерации с использованием поиска (Jiang et al., 2023; Shao et al., 2023), но отличается тем, что наша работа требует от модели прогнозирования содержания чертежей для следующего поколения, чтобы извлечь релевантную информацию и тщательно выбрать подходящие ссылки, чтобы объединить их в соответствующих местах в генерируемом тексте.
4.2 Самостоятельный поиск по дереву Монте-Карло
Мы формулируем генерацию текста с атрибуцией как многошаговую задачу вывода, в которой модель вдумчиво относится к атрибуции текста. Древовидный поиск Монте-Карло стал эффективным поисковым алгоритмом для многих задач принятия решений (Silver et al., 2016; Ye et al., 2021). В данной работе мы предлагаем самонаводящийся поиск по дереву Монте-Карло (SG-MCTS), который использует способность LLM к саморефлексии для управления процессом поиска в MCTS. Предыдущие работы (Shinn et al., 2023; Zhou et al., 2024; Yu et al., 2024) обычно отражают конечный результат или полную траекторию, что является неэффективным и разреженным. В отличие от этого, наш подход направлен на критику и осмысление промежуточного состояния MCTS, чтобы направлять расширение дерева в режиме реального времени и активно игнорировать ошибочные пути генерации.
Как правило, MCTS основывается на модели стратегии πθ Постройте дерево поиска T, которое обычно является LLM M θ . В этом дереве узел st = [q t , D t , y t , C t ] обозначает состояние t-го уровня дерева, включая поисковый запрос q t D t Предложения с выражением yt и процитированные параграфы C t . Корневой узел s0 = [x] обозначает входную задачу. На каждой итерации SG-MCTS выполняет четыре шага: выбор, расширение, управляемое отражением, оценка и обратное распространение.
Фаза выбора. Фаза выбора направлена на определение узла s из дерева поиска Tt для последующего расширения. Алгоритм Upper Confidence Constraint (UCT), применяемый к деревьям (Kocsis and Szepesvári, 2006), используется для выбора лучшего узла с наибольшей оценкой UCT:
UCT(s t ) = V(s t ) + w √(ln N(p) / N(s)) t )) (1)
где V(s t ) оценивается на этапе оценки st Функция ценности (ожидаемое вознаграждение), N(s t ) - это сt количество посещений, w - вес контрольной разведки, а p - st родительского узла.
Фаза расширения, управляемая отражением. На этапе расширения путем генерации множества узлов-преемников s t+1 Узлы расширяются с помощью процесса think-verbalize-cite, который расширяет выбранные узлы s t На этапе Think сначала создается чертеж в виде поискового запроса q̂. t+1 Он извлекает тему и содержание следующего предложения, которое будет использовано для извлечения параграфа D̂. t+1 . Однако на этапе расширения модель стратегии может ошибаться, например, генерировать неспецифические или нерелевантные запросы, что может затруднить последующий поиск доказательств и в конечном итоге привести к неправильному формированию предложений. Поэтому мы вводим Отражение шаг, на котором модель стратегии основывается на вопросе x и полученном отрывке D̂t+1 Рефлексивное исследование q̂t+1 для выявления ошибок:
u = M θ (q̂ t+1 , D̂ t+1 , x), (2)
где текст размышлений u содержит предложения по определенным аспектам поиска, например, что запрос должен быть более сфокусирован на теме поиска. На основе размышлений модель стратегии переформулирует новый запрос qt+1 чтобы получить соответствующий параграф D t+1 ::
q t+1 , Dt+1 = M θ (u, q̂ t+1 , D̂ t+1 , H), (3)
где H - след истории. Обратите внимание, что вышеописанный процесс может повторяться до тех пор, пока модель не определит, что найденные доказательства являются подтверждающими, или пока не будет достигнуто максимальное количество итераций. Наконец, шаги Verbalize и Cite извлекаются из Dt+1 Сгенерируйте следующее предложение y t+1 и с точными цитатами C t+1 ::
y t+1 , Ct+1 = M θ (q t+1 , D t+1 , H). (4)
Новый узел состоит из запроса, полученного корпуса, сгенерированного предложения и цитируемого абзаца, обозначаемых st+1 = [q t+1 , D t+1 , y t+1 , C t+1 ] По сравнению с простыми расширениями в типичных MCTS, наш подход улучшает дефектные узлы расширения, чтобы избежать низкокачественной генерации. Поскольку деревья MCTS строятся инкрементально, улучшение качества следующей операции позволяет модели прокладывать более благоприятные пути в широком пространстве поиска, тем самым улучшая общее качество поиска в дереве.
Фаза оценки. Фаза оценки направлена на использование модели вознаграждения за прогресс (см. раздел 4.3) для вычисления нового узла расширения st+1 Ожидаемое вознаграждение R(s t+1 ). Оценка прогресса включает в себя два аспекта: генерирование и атрибуцию. Генерирование стимулов прогресса Rg Измерение количества предложений, созданных к настоящему времени y 1 , ... , yt+1 качество текста. Наделение Прогресс Вознаграждение Ra Оценка сгенерированных предложений y 1 , ... , yt+1 и процитированные параграфы C 1 , ... , Ct+1 согласованность атрибуции между ними. Наконец, общая награда рассчитывается как сумма двух: R(s t+1 ) = R g + R a .
Фаза обратного распространения. На этапе обратного распространения новый узел st+1 Вознаграждение за R(s t+1 ) передается обратно в родительский узел s t который обновляет каждый узел на пути от корневого узла к его родителю s 0 , s 1 , ... , st Функция ценности
N новый (s i ) = N старый (s i ) + 1, 0 ≤ i ≤ t (5)
V новый (s i ) = (V старый (s i )N старый (s i ) + R(s t+1 )) / N новый (s i ) (6)
где N старый (s i ) и V старый (s i ) являются узлами si ранее использовавшихся функций подсчета и значения.
4.3 Модель вознаграждения за прогресс
Предыдущие модели вознаграждения за результат (Cobbe et al., 2021; Hosseini et al., 2024) и модели вознаграждения за процесс (Lightman et al., 2024; Dai et al., 2024) были сосредоточены на оценке конечного результата или промежуточных шагов. В данной работе мы предлагаем, чтобы после выполнения следующего шага поиск по дереву измерений от корня s0 до состояния st+1 Прогресс. Поскольку текст с атрибуцией включает в себя текстовый контент и ссылки на него, мы разработали два аспекта вознаграждения за прогресс - вознаграждение за прогресс генерации и вознаграждение за прогресс атрибуции - для оценки качества сгенерированного текстового контента и релевантности ссылок, соответственно.
4.3.1 Создание стимулов для прогресса
При прямой оптимизации предпочтений (DPO) (Rafailov et al., 2023) логарифмические соотношения на уровне маркеров можно интерпретировать как
неявное вознаграждение на уровне маркеров в рамках формулы обучения с подкреплением (RL) с максимальной энтропией. Поэтому мы предлагаем использовать существующую модель выравнивания DPO для оценки генерации следующего предложения yt+1 Сгенерированные предложения y1:t+1 = y 1 , ... , yt+1 Оценка качества R g .
В частности, мы определяем марковский процесс принятия решений (MDP) на уровне предложения, где состояние st = (x, y 1 , ... , y t ) обозначает входные данные и предложения, сгенерированные на данный момент, а начальное состояние s0 = x - это входная задача. Действие at = yt+1 обозначает следующее предложение, которое должно быть сгенерировано. Таким образом, задача оптимизации RLHF может быть переписана как задача RL с максимальной энтропией на уровне предложений:
E наπθ(-|st)~ [∑^T^t=1 r'(s t , a t )] + βE s0x~ [H(π θ (-|s 0 ))],
где функция вознаграждения r' на уровне предложения может быть вычислена как:
r'(s t , a t ) = { βlog π ссылка (a t |s t ), если st+1 это не конец линии
{ r'(y|x) + βlog π ссылка (a t |s t ) Если s t+1 Это конец очереди.
Формула максимальной энтропии RL выводит оптимальную функцию стоимости V и функцию Q как:
Q(s t , a t ) = r'(s t , a t ) + V(s t+1 ),
V(s t ) = log ∑a exp(Q(s t , a)), когда t ≤ T .
Таким образом, оптимальная политика π определяется как:
⇒ βlog π(a t |s t ) = Q(s t , a t ) - V(s t ),
⇒ βlog (π(a t |s t ) / π ссылка (a t |s t )) = V(s t+1 ) - V(s t ).
Это побудило нас использовать стратегию DPO для получения частичной суммы вознаграждений, чтобы сформулировать частичные ответы y1:t+1 Стимулы прогресса для R g ::
∑^t^k=0 βlog (π(a k |s k ) / π ссылка (a k |s k )) = V(s t+1 ) - V(s 0 ),
⇒ R g (y 1:t+1 ) = ∑^t^k=0 wk log (π(y k+1 |x, y 1:k ) / π ссылка (y k+1 |x, y 1:k )),
где y1:k обозначает y 1 , ... , y k wk = 1 / (t+1) - это вес каждого коэффициента логарифмического правдоподобия на уровне предложения.
4.3.2 Награды за прогресс атрибутов
Мы используем две метрики цитирования, применяемые в предыдущей работе (Gao et al., 2023b), - citation recall и precision - для представления вознаграждения за прогресс в атрибуции R a .
В частности, отзыв на цитату измеряет частичный ответ y1:t+1 предложений, которые могут быть подкреплены соответствующим цитируемым отрывком. Мы использовали модель NLI (Honovich et al., 2022), чтобы проверить, могут ли процитированные отрывки вывести ответы модели. Для каждого предложения yi (1 ≤ i ≤ t + 1), мы будем Ci Процитированные отрывки соединяются в посылку и порожденное предложение yi как предположения для модели NLI. Мы устанавливаем значение citation recall равным 1, если посылка содержит предположение, и 0 в противном случае. citation precision оценивает процент ссылок, которые поддерживают соответствующее предложение. Для расчета точности мы используем ту же модель NLI, что и выше. Для каждой цитаты c i,j Если (1) Ci Все ссылки в y содержат сгенерированное предложение yi и (2) Ci \ {c i,j } без предложения y i В противном случае оценка точности устанавливается на 0. Мы вычисляем оценку точности (0 или 1) для каждой цитаты и усредняем ее по всем цитатам. Наконец, мы вычисляем оценку F1 как приписанное вознаграждение за прогресс R a (y 1:t+1 , C 1 , ... , C t+1 ), чтобы обеспечить сбалансированную метрику качества атрибуции между сгенерированными предложениями и цитируемыми отрывками.
5 экспериментов
5.1 Экспериментальная установка
Наборы данных. Для оценки мы используем эталонный тест ALCE (Gao et al., 2023b), состоящий из трех наборов данных: (1) ASQA (Stelmakh et al., 2022) - набор данных для оценки качества, содержащий неоднозначные вопросы, требующие нескольких ответов, охватывающих различные аспекты; (2) QAMPARI (Amouyal et al. 2022), фактологический набор данных QA, в котором ответ на каждый вопрос представляет собой список сущностей, извлеченных из различных отрывков; и (3) ELI5 (Fan et al., 2019), длинный набор данных QA, содержащий вопросы "как/почему/что". Для ASQA и QAMPARI на большинство вопросов можно ответить через Википедию, поэтому в качестве корпуса мы используем снимок Википедии от 2018/12/20. Для ELI5, поскольку его вопросы тематически разнообразны, мы используем Sphere (Piktus et al., 2021) (отфильтрованную версию Common Crawl) в качестве корпуса. Следуя Гао и др. (2023b), мы используем GTR (Ni et al., 2022) для Википедии и Sphere. BM25 (Robertson et al., 2009) для извлечения первых 100 отрывков в качестве корпуса для каждого вопроса. Более подробную информацию см. в Приложении A.
Метрики оценки. Мы используем метрики оценки из оригинального эталонного теста ALCE. Для оценки корректности результатов мы используем показатели точного соответствия (EM) Recall из ASQA, Recall-5 из QAMPARI и Statement Recall из ELI5, чтобы измерить процент "золотых" ответов (ключевых фрагментов информации) в результатах. Далее мы рассчитываем Precision как метрику корректности для набора данных QAMPARI, чтобы измерить процент правильных ответов. Для оценки качества цитирования мы вычисляем Citation Recall (процент предложений в выводе, которые можно вывести из цитируемых ими отрывков) и Citation Precision (процент цитат, которые могут помочь поддержать предложения в выводе).
Базовый уровень. Мы сравниваем наш подход с подходом, основанным на ChatGPT и GPT-40 сравниваются со следующими базовыми показателями:
Ваниль RAG Модель была непосредственно проинструктирована генерировать ответы на основе заданных первых 5 абзацев и соответствующим образом их цитировать. Мы используем контекстное обучение с двумя презентациями (Brown et al., 2020).
Резюме/фрагмент RAG представляет собой краткое изложение или фрагмент абзаца, а не полный текст. Модель будет генерировать ответы с цитатами на основе первых 10 резюме или фрагментов абзацев.
Interact позволяет модели получить доступ к полному тексту определенных параграфов в методе Summary/Snippet RAG. Модель может представить действие "Check: Document [1] [2]", чтобы получить полный текст соответствующего документа.
Встроенный поиск позволяет модели запросить действие "Поиск: {запрос}", чтобы получить наиболее релевантные параграфы из 100 лучших. Этот метод похож на наш в том, что он действует как прямое сравнение.
ReRank случайным образом выбирает четыре ответа для каждого вопроса и выбирает лучший ответ на основе метрики цитирования.
Приведенный выше базовый вариант был применен и оценен в оригинальном эталонном тесте ALCE, о чем сообщается в (Gao et al., 2023b). Кроме того, мы сравниваем наш подход с предыдущими работами по генерации текстов с атрибуцией.FG-Reward (Huang et al., 2024) предлагает использовать мелкозернистые вознаграждения в качестве обучающих сигналов для точной настройки LLaMA-2-7B (Touvron et al., 2023) на генерацию атрибутируемых ответов.VTG (Sun et al., 2024) использует изменяющиеся воспоминания и двухслойный валидатор для генерации атрибутируемых ответов.VTG (Sun et al., 2024) использует изменяющиеся воспоминания и двухслойный валидатор для генерации атрибутируемых ответов. 2024) использовал изменяющиеся воспоминания и двухслойный валидатор для управления генеративной моделью (т. е. text-davinci-003).APO (Li et al., 2024) собрал набор данных пар предпочтений и применил оптимизацию предпочтений к LLaMA-2-13B для генерации текста с атрибуцией.
Детали реализации. Для оценки эффективности нашего подхода мы используем LLaMA-3.1-8B-Instruct и GPT-40 в качестве моделей стратегий. Для моделей вознаграждения мы используем модель DPO, Llama-3-8B-SFR-Iterative-DPO-R¹, для вычисления генеративного вознаграждения за прогресс и модель NLI, T5-XXL-TRUE-NLI-Mixture (Honovich et al., 2022), для вычисления атрибутивного вознаграждения за прогресс. Для каждого поискового запроса мы извлекаем 3 лучших отрывка из корпуса в качестве ссылок-кандидатов D t . В алгоритме UCT (уравнение 1) вес w равен 0,2. Для SG-MCTS мы расширяем три дочерних узла для каждого родительского узла, устанавливаем максимальный уровень дерева 6 и максимальное количество итераций для MCTS 30.
5.2 Основные результаты
В таблице 1 приведены результаты работы нашего метода и базовой версии на трех наборах данных.
Во-первых, можно заметить, что три метода Retrieval Augmented Generation (RAG) демонстрируют умеренную производительность, хотя использование резюме или фрагментов может улучшить корректность. Однако это улучшение происходит за счет качества цитирования, так как информация об абзацах сильно сжимается. ReRank приводит к последовательному улучшению качества цитирования в трех наборах данных (например, ванильный RAG улучшает запоминание цитат с 73,61 TP3T до 84,81 TP3T в ASQA). В качестве прямого сравнения, Inline Search похож на наш подход, но работает хуже по сравнению с другими базовыми вариантами. Это объясняется тем, что поисковые запросы просто запрашиваются без учета качества и релевантности доказательств.
Во-вторых, благодаря тонкой настройке LLM на контролируемых обучающих данных с аннотированными цитатами, FG-Reward и APO демонстрируют повышенное качество цитирования в наборах данных ASQA и ELI5, но не улучшают производительность в QAMPARI. Кроме того, VTG использует генеративный валидатор и валидатор в памяти для оценки логической поддержки доказательств, что приводит к высокому качеству цитирования (например, отзыв цитат 86,71 TP3T в ASQA). Однако точно настроенные LLM ограничены качеством и количеством контролируемых обучающих данных, когда для ссылки на правильный источник требуется значительная стоимость подтверждающих доказательств. Кроме того, эти методы все еще опираются на авторегрессионную генерацию, которая является быстрым, но менее точным способом мышления. Следовательно, любые промежуточные ошибки генерации (например, искажения или неадекватное цитирование) приведут к проблемам с окончательным ответом.
| ASQA | КАМПАРИ | ELI5 | |
|---|---|---|---|
| Корректность | Цитировать | Корректность | Цитировать |
| EM Rec. | Rec. | Прек. | Отзыв-5 |
| ChatGPT | |||
| Ваниль RAG | 40.4 | 73.6 | 72.5 |
| w/ ReRank | 40.2 | 84.8 | 81.6 |
| Резюме RAG | 43.3 | 68.9 | 61.8 |
| w/ Interact | 39.1 | 73.4 | 66.5 |
| Сниппет RAG | 41.4 | 65.3 | 57.4 |
| с/Взаимодействие | 41.2 | 64.5 | 57.7 |
| Встроенный поиск | 32.4 | 58.3 | 58.2 |
| GPT-40 | |||
| Ваниль RAG | 41.3 | 68.5 | 75.6 |
| w/ ReRank | 42.1 | 83.4 | 82.3 |
| Резюме RAG | 46.5 | 70.2 | 67.2 |
| w/ Interact | 48.1 | 73.1 | 72.8 |
| Сниппет RAG | 45.1 | 68.9 | 66.5 |
| с/Взаимодействие | 45.2 | 67.8 | 66.7 |
| Встроенный поиск | 40.3 | 65.7 | 66.9 |
| FG-Reward | 40.1 | 77.8 | 76.3 |
| VTG | 41.5 | 86.7 | 80.0 |
| APO | 40.5 | 72.8 | 69.6 |
| Наши (LLaMA) | 45.2 | 82.3 | 80.6 |
| Наши (GPT-40) | 50.1 | 89.5 | 87.1 |
Таблица 1: Результаты оценки генерации атрибутивного текста на трех наборах данных. "Rec." и "Prec." - сокращения для recall и precision. Жирным и подчеркнутым шрифтом выделены лучший и второй лучшие результаты в каждом наборе данных, соответственно.
Think&Cite формулирует задачу создания текста атрибутов как многоэтапную задачу рассуждения и вводит медленный и целенаправленный режим размышления для поиска наилучшего решения. Предлагая самонаводящийся алгоритм MCTS, Think&Cite использует способность LLM к саморефлексии для управления процессом расширения дерева. Кроме того, предложенная модель вознаграждения за прогресс может обеспечить всестороннюю и надежную обратную связь, чтобы помочь модели найти лучшие ответы.
5.3 Дальнейший анализ
Мы сообщаем о дальнейшем анализе нашего метода на ASQA с использованием GPT-40, поскольку мы получили аналогичные результаты и на других наборах данных.
Исследование абляции. Чтобы подтвердить эффективность предложенного нами фреймворка, мы проанализировали его ключевые элементы дизайна для абляции. Мы разработали четыре варианта: (1) w/o SG-MCTS устраняет самонаводящуюся MCTS и напрямую генерирует ответы шаг за шагом; (2) w/o Reflection устраняет шаг отражения и использует ванильный алгоритм MCTS; (3) w/o GP Reward устраняет необходимость генерировать вознаграждение за прогресс R g ; (4) без награды за AP Убраны награды за прогресс в наделении R a Результаты представлены в таблице 2. Результаты приведены в таблице 2. Все варианты работают хуже, чем оригинальный метод, что говорит об эффективности каждого компонента. В частности, производительность w/o SG-MCTS значительно хуже, что говорит о том, что интеграция поискового алгоритма в генерацию текста с атрибуцией очень полезна. Использование ванильной MCTS (w/o Reflection) приводит к ухудшению качества цитирования из-за введения ложных ссылок без рефлексии на найденные результаты. Аналогично, как w/o GP Reward, так и w/o AP Reward приводят к худшим показателям, что говорит о важности как генерации, так и проверки качества цитирования.
| Метод | Корректность | Цитировать |
|---|---|---|
| EM Rec. | Rec. | Прек. |
| Think&Cite | 50.1 | 89.5 |
| w/oSG-MCTS | 42.1 | 78.2 |
| w/oReflection | 46.5 | 83.6 |
| w/oGPReward | 47.1 | 86.2 |
| w/oAPReward | 46.7 | 81.3 |
Самоанализ и моделирование. В каждой симуляции SG-MCTS выполняет четыре ключевых шага и использует саморефлексию для улучшения качества промежуточных состояний в расширении путем критики и улучшения запросов на ошибки. Чтобы проверить эффективность отражения, мы сравнили производительность между увеличением максимального количества симуляций и увеличением максимального количества операций отражения. Сначала мы изменили максимальное количество симуляций на {10, 20, 30, 40} и зафиксировали максимальное количество отражений на 10. Аналогичным образом мы изменили максимальное количество отражений на {5, 10, 15, 20} и зафиксировали максимальное количество симуляций на 30. На рисунке 3 показаны оценки F1, основанные на показателях recall и precision. На рисунке видно, что увеличение числа симуляций и числа отражений улучшает производительность генерации текста с атрибуцией. Это ожидаемо, так как более обширное исследование повышает вероятность нахождения правильной генерации. Однако большее количество шагов отражения может "перемудрить" модель, внести шум и привести к снижению производительности. SG-MCTS превосходит ванильную MCTS без отражения, потому что в родительском узле может происходить неправильный поиск, в результате чего процесс рассуждения в расширенном дочернем узле продолжается по неправильному пути. Шаг отражения улучшает некорректный поиск из-за недостаточного количества запросов, тем самым позволяя последующему исследованию проходить более точно.

Рисунок 3: Результаты ASQA по количеству симуляций (слева) и количеству шагов отражения (справа).
Анализ гиперпараметров. Два гиперпараметра являются критическими для корректности и качества цитирования: каждый запрос qt Количество найденных параграфов |D t | и расширенные дочерние узлы при поиске по дереву st+1 Количество найденных абзацев. Как показано на рисунке 4, качество цитирования может быть первоначально улучшено за счет увеличения количества найденных абзацев. Однако дальнейшее увеличение числа абзацев сверх определенного порога приводит к ухудшению производительности, главным образом потому, что объединение большего числа абзацев вносит шум, который негативно влияет на надежность генерируемого контента. С другой стороны, мы наблюдаем, что увеличение количества расширенных узлов приводит к постоянному улучшению, хотя впоследствии это улучшение стабилизируется. Поскольку расширение большего числа узлов приводит к большим вычислительным затратам, мы извлекаем три дочерних узла для каждого родительского узла.

Рисунок 4: Результаты ASQA по количеству абзацев (слева) и количеству расширенных узлов (справа).
5.4 Тематические исследования
Чтобы облегчить понимание всего рабочего процесса нашего метода, мы провели качественный анализ в ASQA. Пример приведен в Приложении C. На протяжении всего процесса поиска LLM рассматривает входную задачу как корневой узел и постепенно расширяет дерево поиска, чтобы достичь состояния завершения. Как показано на рисунке, сначала модель генерирует запрос (например, "Расположение близлежащих природных достопримечательностей Ганнисона"), чтобы получить отрывки. Поскольку отрывок не содержит достоверной информации, необходимой для ответа на вопрос, модель размышляет и предлагает новый запрос (например, "Места расположения природных достопримечательностей Ганнисона") для извлечения. На основе найденных абзацев модель генерирует предложения и ссылается на второй и третий абзацы (например, "[2][3]"). Следуя многоступенчатому процессу генерации, модель может глубоко продумать тему и выдать надежный контент с точными ссылками.
6 Заключение
В этой работе мы представляем Think&Cite, новый фреймворк для генерации атрибутивных текстов с интегрированным поиском по дереву. Think&Cite основан на итеративной парадигме генерации think-express-cite. Чтобы улучшить процесс генерации, мы предлагаем Self-Guided Monte Carlo Tree Search, который использует способность LLM к саморефлексии для критики и коррекции промежуточных состояний MCTS, чтобы направлять расширение дерева. Кроме того, мы предлагаем модель вознаграждения за прогресс для измерения прогресса в поиске деревьев и обеспечения надежной обратной связи. Обширные эксперименты на трех наборах данных показывают, что предложенный нами Think&Cite превосходит традиционные методы подсказки и тонкой настройки.
ограничения
Сфера применения наших экспериментов ограничена значительными вычислительными затратами древовидных методов поиска. В будущем можно будет исследовать более широкий спектр наборов данных для генерации атрибутивных текстов. В нашей модели для самостоятельной генерации используется древовидный поиск Монте-Карло. В дальнейшей работе можно будет исследовать другие алгоритмы поиска, чтобы оценить универсальность и устойчивость предложенной нами схемы.
приложение
Набор данных
Мы оцениваем наш подход на эталоне ALCE, состоящем из трех наборов данных. В частности, набор данных ASQA (Stelmakh et al., 2022) содержит 948 вопросов с ответами, которые можно найти в Википедии; набор данных QAMPARI (Amouyal et al., 2022) содержит 1 000 вопросов, основанных на Википедии; и набор данных ELI5 (Fan et al., 2019) содержит 1 000 вопросов, ответы на которые можно найти в Sphere (Piktus et al., 2021). Подробная информация об этих трех наборах данных приведена в таблице 3.
| набор данных | Корпус (# проездов) | Тип проблемы |
|---|---|---|
| ASQA | Википедия (21 миллион) | фактический |
| КАМПАРИ | Википедия (21 миллион) | Факты (табуляция) |
| ELI5 | Сфера (899 миллионов) | Почему/Как/Что |
B Советы
Мы поручили LLM выполнять самонаводящийся поиск по дереву для создания текстов атрибутов в манере обучения без использования образцов. Подсказки для контекстного обучения для наборов данных ASQA, QAMPARI и ELI5 представлены в таблицах 4, 5 и 6 соответственно. В этих подсказках мы сначала определили для LLM четыре операции в парадигме итеративного мышления-выражения-ссылки. Затем мы создали четыре контекстных примера, которые были выбраны таким образом, чтобы соответствовать эталону ALCE (Gao et al., 2023b).
C Тематические исследования

На рисунке 5 приведен пример из ASQA.
Ваша цель - написать точный, интересный и лаконичный ответ на заданный вопрос, используя только предоставленные результаты поиска и правильно их цитируя. Используйте честный и журналистский тон. Всегда указывайте ссылку на любой факт. Вы можете использовать четыре действия:
- """Поиск: ключевые слова""", который запрашивает некоторые ключевые слова и извлекает наиболее релевантные документы на основе истории поиска и генерации.
- """Reflect: ideas"""" и поразмышляйте над результатами поиска, если для ответа на вопрос не был получен достоверный документ.
- """Выход: предложение """которое выводит длинный ответ на основе найденного документа. В ответе правильно цитируется документ с использованием [1][2][3]. В каждом предложении цитируйте не менее одного и не более трех документов. Если предложение поддерживается несколькими документами, цитируется только наименее достаточное подмножество документов.
- """End""" завершает задание викторины.
Вот несколько примеров:
Вопрос : Кто установил рекорд по самому дальнему выстрелу?
Поиск : Рекорд по дальности выстрела
Документ[1] (Подпись: Дэвид Эйкерс) установил рекорд по самому длинному филд-голу, пробив мяч с 63 ярдов над перекладиной.
Документация[2] (Название: Дирк Боргоньоне) Дирк Боргоньоне, Дирк Рональд Боргоньоне (родился 9 января 1968 года) - бывший национальный...
Документ[3] (Название: Рассел Элксебен) против Университета Колорадо. Несмотря на ранние проблемы в игре, включая...
Размышление: Результаты поиска не дали достоверной информации для ответа на вопрос. Лучше поискать рекорд по самому длинному голу в НФЛ.
Поиск : Рекорд по самому длинному голу в НФЛ
Документ[4] (Название: Field Goal) в направлении собственной конечной зоны. Самый длинный филд-гол в истории НФЛ составляет 64 ярда - рекорд, установленный...
Документ [5] (Название: Field Goal Range) конечная зона на каждом конце) составляла всего 66 ярдов. Скаччиа, играя в мини-футбол, попытался пробить 64-ярдовый...
Документ[6] (Название: Дальность выстрелов) Это достижение не является официальным рекордом. Все вышеперечисленные выстрелы были успешными...
Выходные данные : Рекорд самого длинного филд-гола в игре НФЛ составляет 64 ярда, его установил Мэтт Пратер[4].
Поиск : Рекорд самого длинного выстрела на соревнованиях любого уровня, колледж
Документ[7] (Название: Field Goal) в направлении собственной конечной зоны. Самый длинный филд-гол в истории НФЛ составляет 64 ярда - рекорд, установленный...
Документация[8] (Название: Дальность выстрелов) На линии от 35 до 40 ярдов (при встречном ветре ближе) обычно пытаются сделать более рискованные...
Документ[9] (Название: Field goal range) NFL, и был запрещен NCAA с 1989 года) составляет 68 ярдов, принадлежит Фабрицио Скаччиа...
Выход: Однако рекорд самого длинного филд-гола на соревнованиях любого уровня составляет 69 ярдов, его пробил кикер колледжа Ове Йоханссон в 1976 году во время футбольного матча между Абилинским христианским университетом и Восточно-Техасским государственным университетом[8]. Конец.
Ваша цель - написать точный, интересный и лаконичный ответ на заданный вопрос, используя только предоставленные результаты поиска и правильно их цитируя. Используйте честный и журналистский тон. Всегда указывайте ссылку на любой факт. Вы можете использовать четыре действия:
- """Поиск: ключевые слова""", который запрашивает некоторые ключевые слова и извлекает наиболее релевантные документы на основе истории поиска и генерации.
- """Reflect: ideas"""" и поразмышляйте над результатами поиска, если для ответа на вопрос не был получен достоверный документ.
- """Выход: предложение """которое выводит длинный ответ на основе найденного документа. В ответе правильно цитируется документ с использованием [1][2][3]. В каждом предложении цитируйте не менее одного и не более трех документов. Если предложение поддерживается несколькими документами, цитируется только наименее достаточное подмножество документов.
- """End""" завершает задание викторины.
Вот несколько примеров:
Вопрос : Какие книги написал Невил Шут?
Поиск : Невилл Шут Темы Социальные расстройства
Документ[1] (Название: Невил Шут) Ранние стадии. Мои поздравления". Его репутация писателя привела к тому, что Министерство информации направило его в...
Документ [2] (Название: Невил Шут) Тема - преодоление социальных барьеров, таких как классовые ("Одинокая дорога" и "Привал"), расовые...
Документ[3] (Название: Невил Шут) Авиастроительная компания, Airspeed Ltd. Популярность его романов росла, но более известным он стал...
Выходные данные : Beyond the Black Stump [2], Lonely Road [2], Chessboard [2], In the Damp [2], Toolroom Trustee [2], Around the Bend [2].
Поиск : Невил Шют Простой стиль чтения
Документы[4] (Невил Шут) Авиастроительная компания, Airspeed Ltd. Популярность его романов росла, но более известным он стал...
Документ[5] (Шашка) Народ Бирмы", оба из которых занимают центральное место в сюжете книги. Шутт обеспокоен продажами книги...
Документация[6] (влажная) Он несколько раз использовал идею голосования в рассказе "Любопытная республика Гондор"...
Размышление: Результаты поиска не дали никакой полезной информации для ответа на вопрос. Лучше поискать книги Невила Шюта 1950-х годов.
Поиск : 1950-е книги Невила Шюта
Документ[7] (Невил Шут) Ранние стадии. Мои поздравления". Его репутация писателя заставила Министерство информации отправить его в...
Документ [8] (Невил Шут) Тема - преодоление социальных барьеров, таких как классовые ("Одинокая дорога" и "Привал"), расовые ("Шахматная доска")...
Документация[9] (Невил Шут) Авиастроительная компания, Airspeed Ltd. Популярность его романов росла, но более известным он стал...
Выходные данные : Малазан [7], Стивен Моррис [7].
закрыть
Ваша цель - написать точный, интересный и лаконичный ответ на заданный вопрос, используя только предоставленные результаты поиска и правильно их цитируя. Используйте честный и журналистский тон. Всегда указывайте ссылку на любой факт. Вы можете использовать четыре действия:
- """Поиск: ключевые слова""", который запрашивает некоторые ключевые слова и извлекает наиболее релевантные документы на основе истории поиска и генерации.
- """Reflect: ideas"""" и поразмышляйте над результатами поиска, если для ответа на вопрос не был получен достоверный документ.
- """Выход: предложение """которое выводит длинный ответ на основе найденного документа. В ответе правильно цитируется документ с использованием [1][2][3]. В каждом предложении цитируйте не менее одного и не более трех документов. Если предложение поддерживается несколькими документами, цитируется только наименее достаточное подмножество документов.
- """End""" завершает задание викторины.
Вот несколько примеров:
Вопрос : Что вызывает биполярное расстройство?
Поиск : Что такое биполярное расстройство?
Документ [1] (Название: Биполярное расстройство II типа) Исследования по установлению личных границ восприятия и поведения. Исследование предполагает следующее...
Документ [2] (Название: Биология биполярного расстройства) Предполагается, что участки мозга, расположенные в этих областях, являются механизмом возникновения биполярного расстройства...
Документ [3] (Название: Биология биполярного расстройства) независимо от полярности. Воспаление было зарегистрировано при биполярном расстройстве...
Размышление: Результаты поиска не дали достоверной информации для ответа на вопрос. Лучше поискать симптомы биполярного расстройства.
Поиск : Каковы симптомы биполярного расстройства? Как долго они длятся?
Документ [4] (Название: Биполярное расстройство | Определение в медицинском словаре) Биполярное расстройство | Определение биполярного расстройства...
Документ [5] (Название: Мания и биполярное расстройство) может варьироваться от депрессии до "очень счастливого" состояния за один день или даже за несколько дней, что...
Документ [6] (Название: For Individuals - Adam Schwartz) For Individuals 2014 Adam Schwartz Информация обширна и охватывает...
Выходные данные : Биполярное расстройство - это расстройство настроения, которое вызывает резкие перепады настроения, от эйфории до депрессии [4]. Перепады настроения могут длиться от нескольких дней до нескольких месяцев [5].
Поиск : Что вызывает биполярное расстройство?
Документ [7] (Название: Биполярное расстройство) Биполярное расстройство - это циклическое расстройство, при котором человек испытывает депрессию...
Документ [8] (Название: Симптомы депрессии и биполярного расстройства 2019 | Beat Depression) Симптомы депрессии и биполярного расстройства 2019.
Документация[9] (Название: Психические расстройства) может включать родительские факторы, в том числе отвержение родителями, недостаток родительского тепла...
ВНЕШНИЙ ВИД: Мы до сих пор не знаем точных факторов, способствующих развитию этого заболевания, но считается, что генетика является одним из основных факторов [7].
закрыть
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи




Нет комментариев...