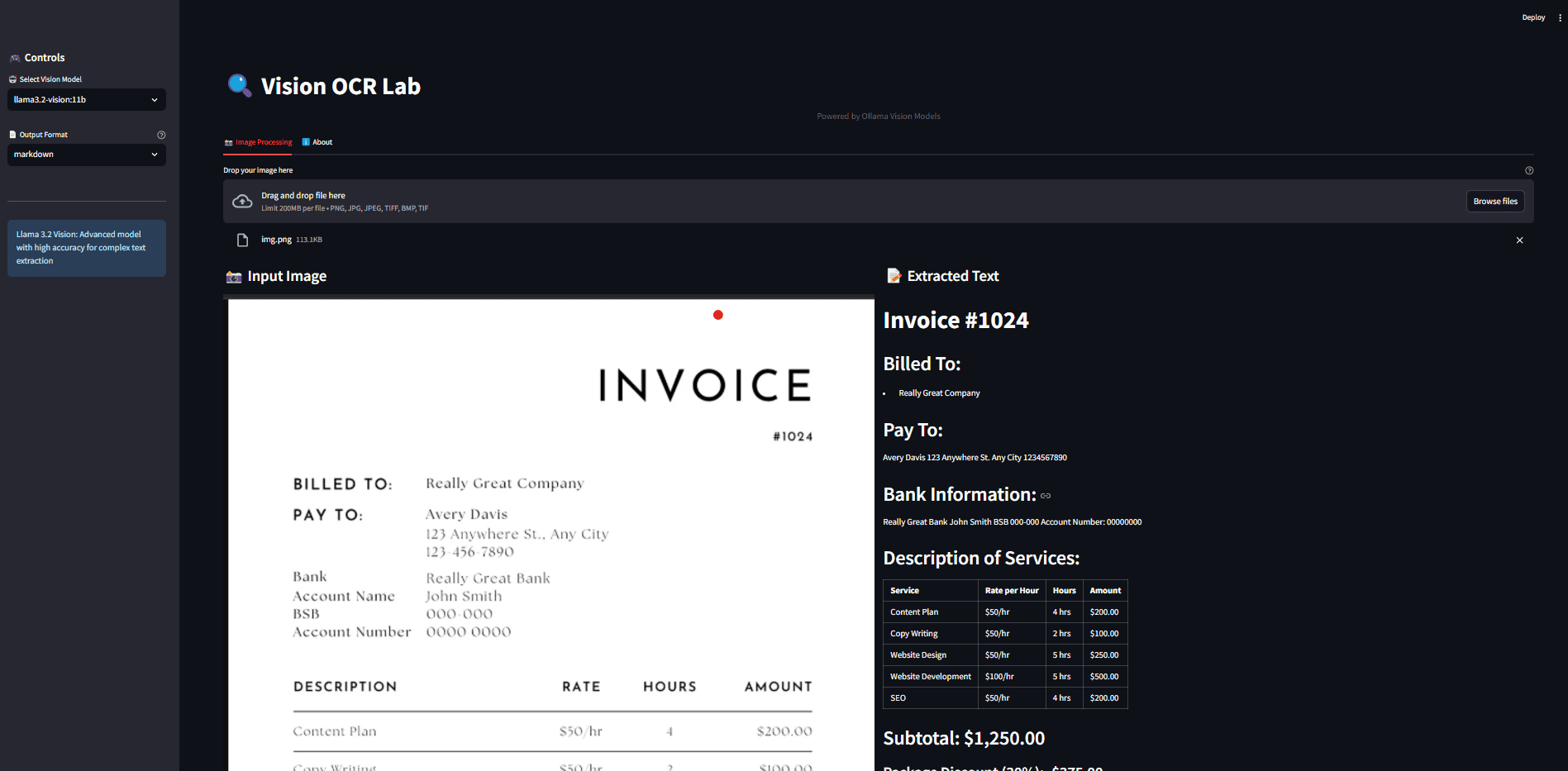
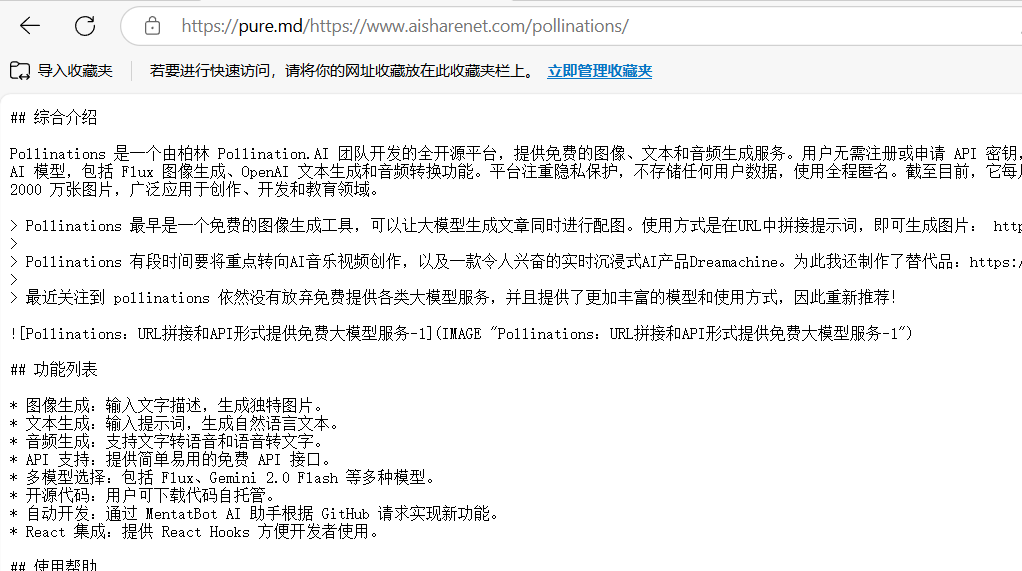
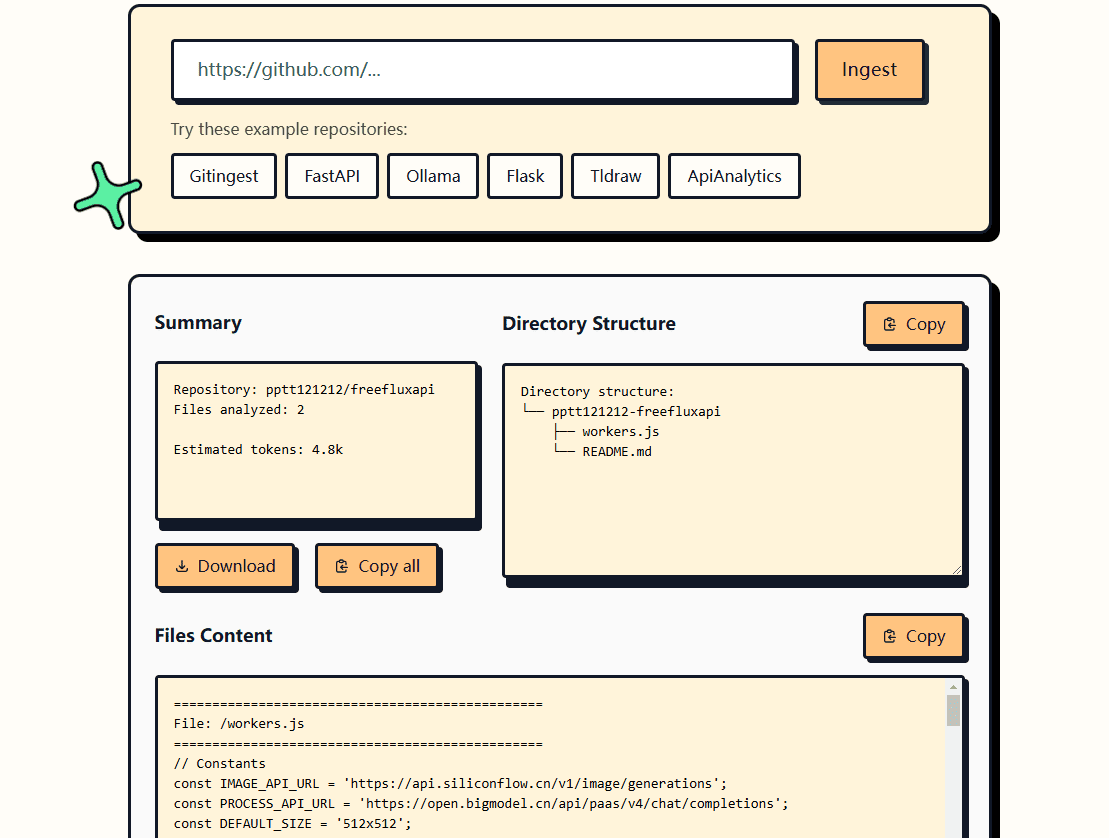
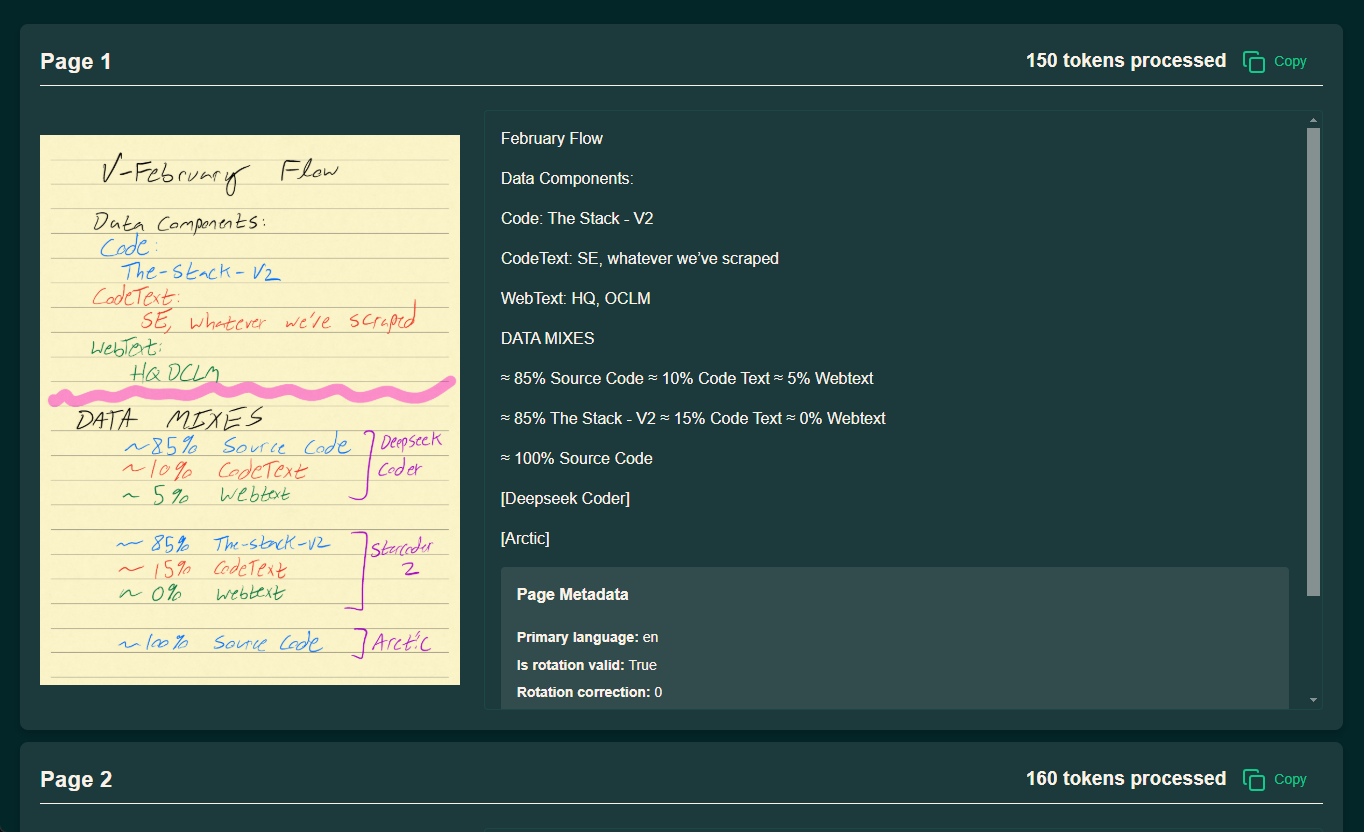
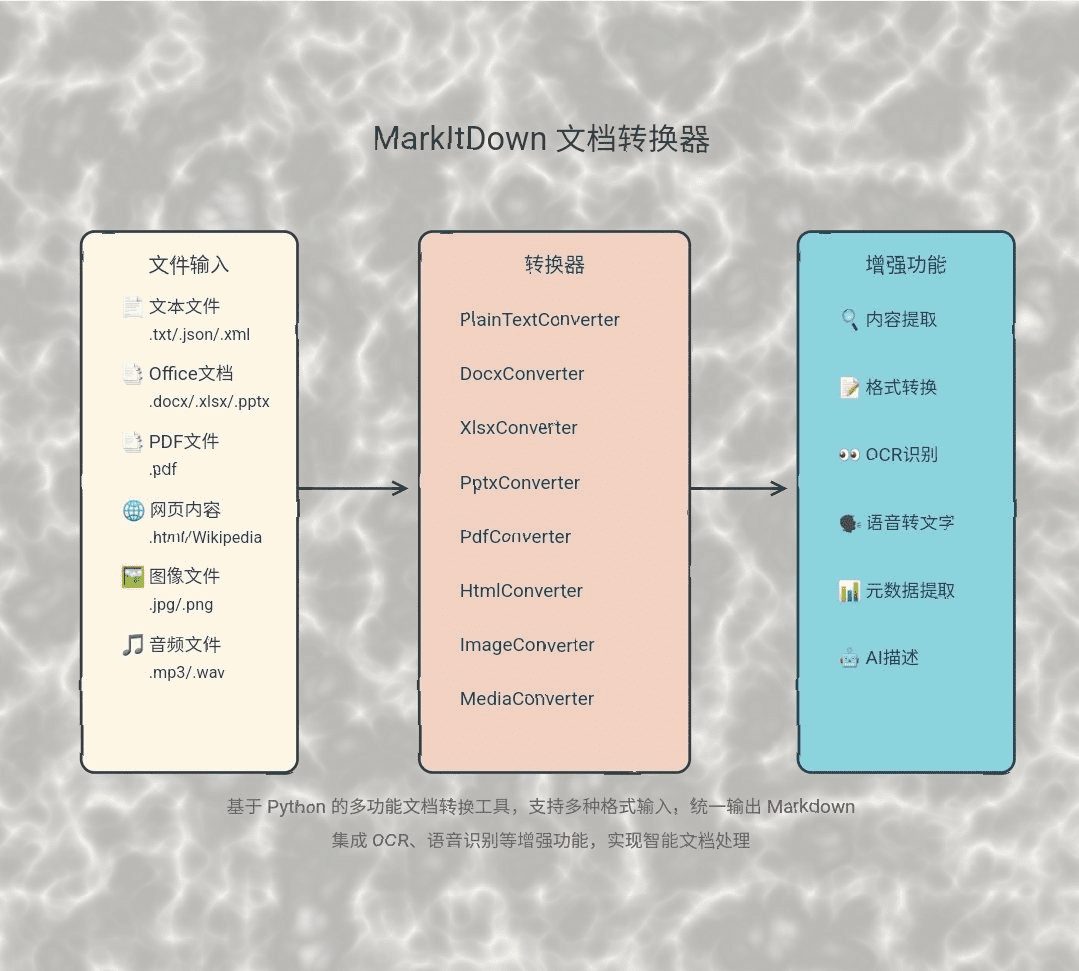
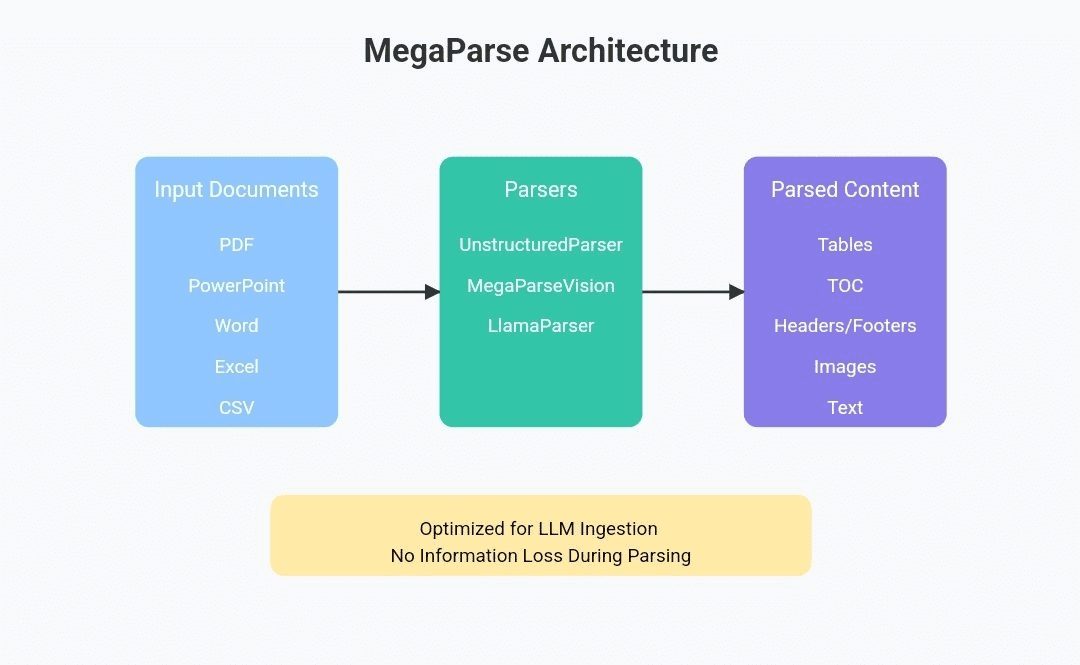
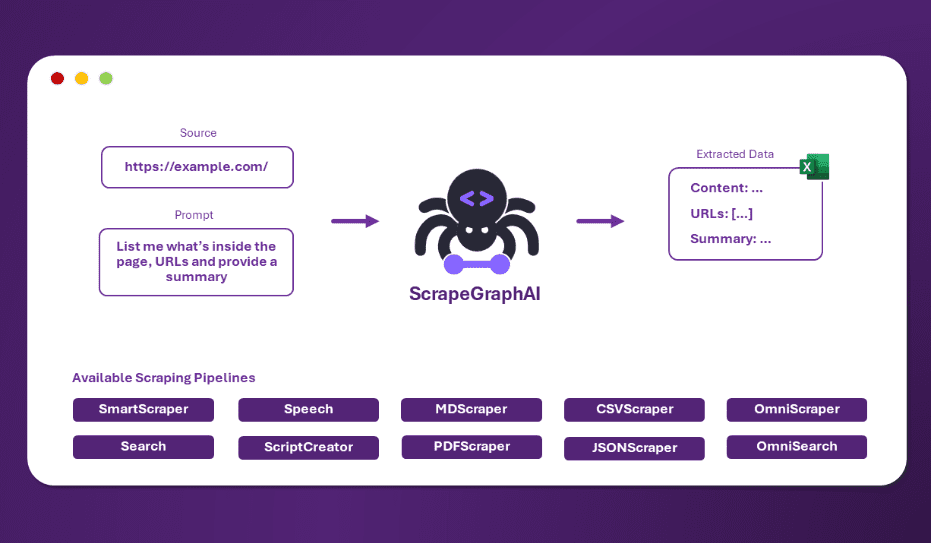
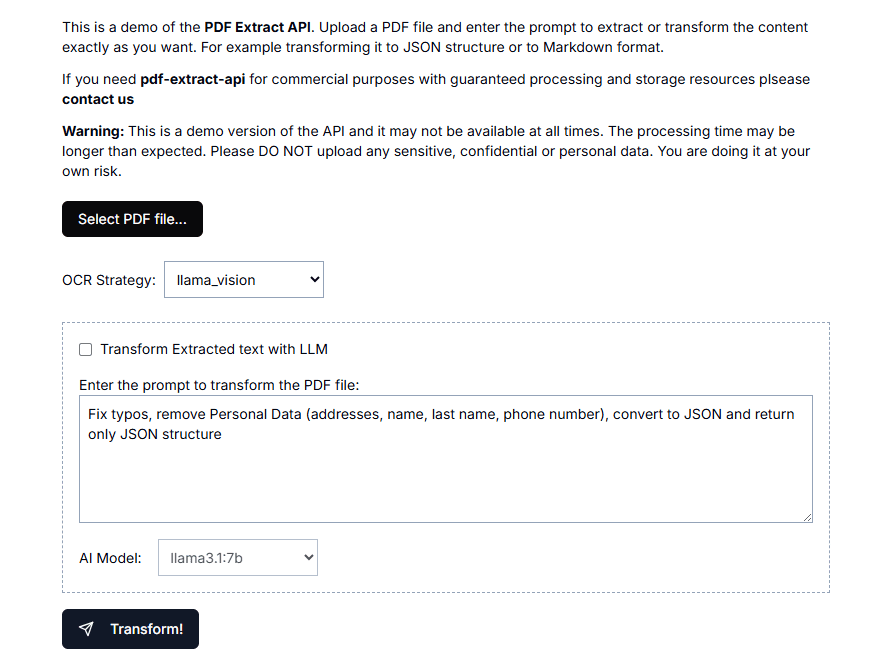
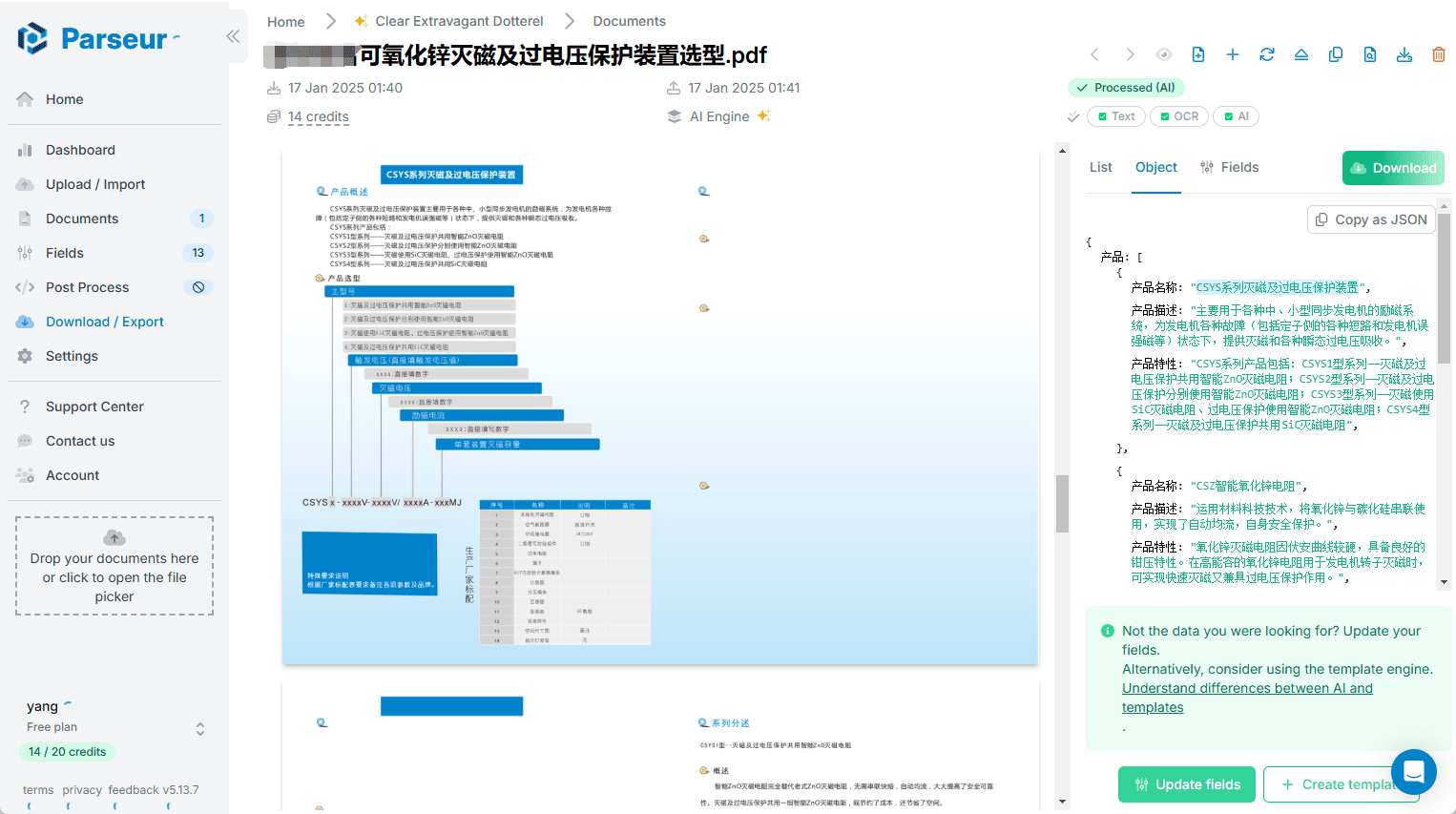
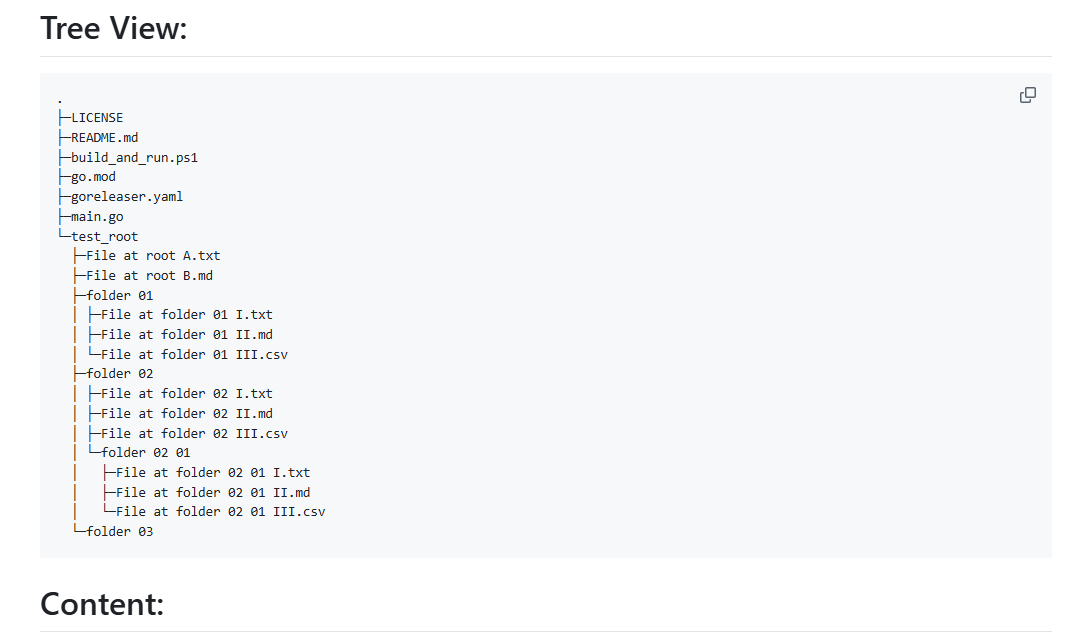
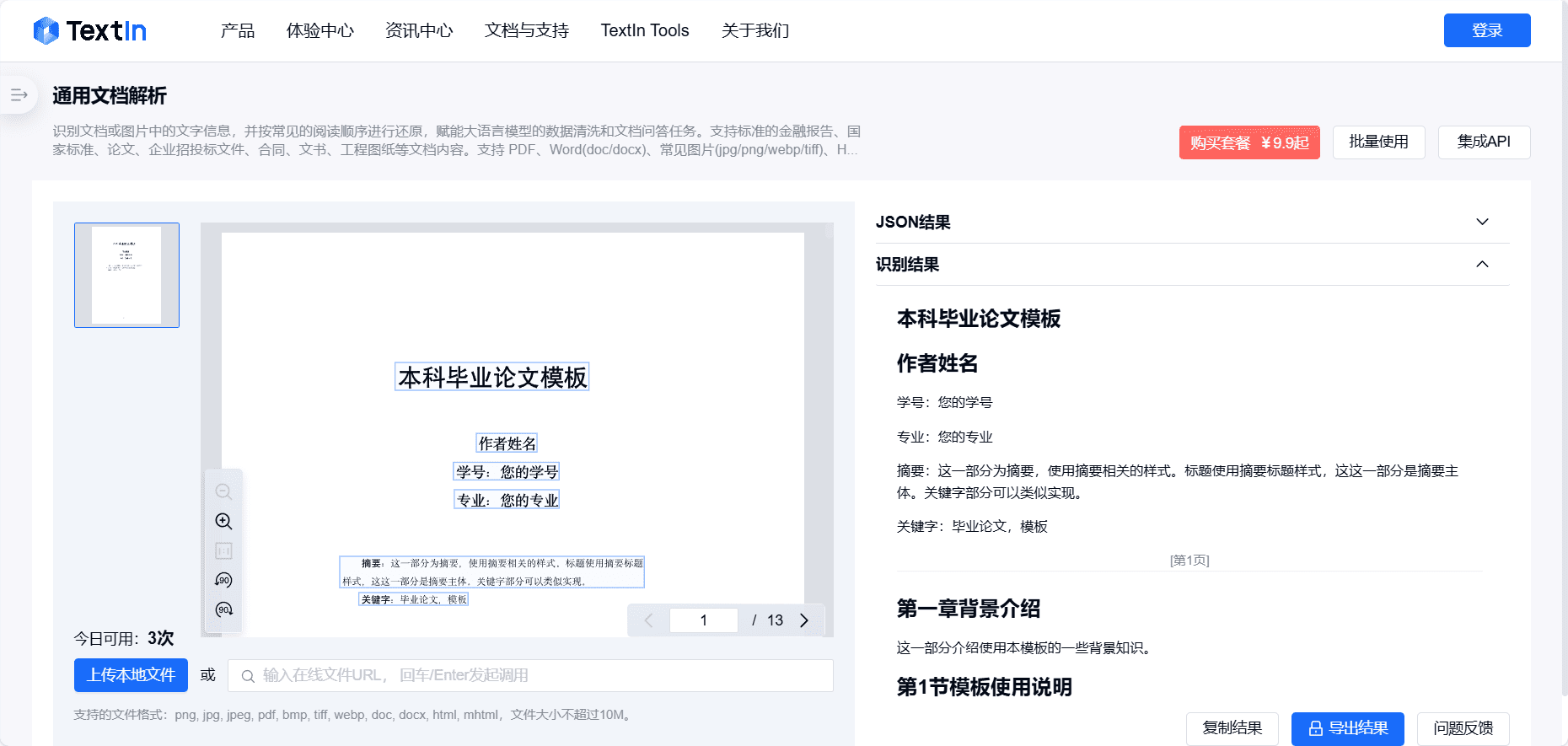
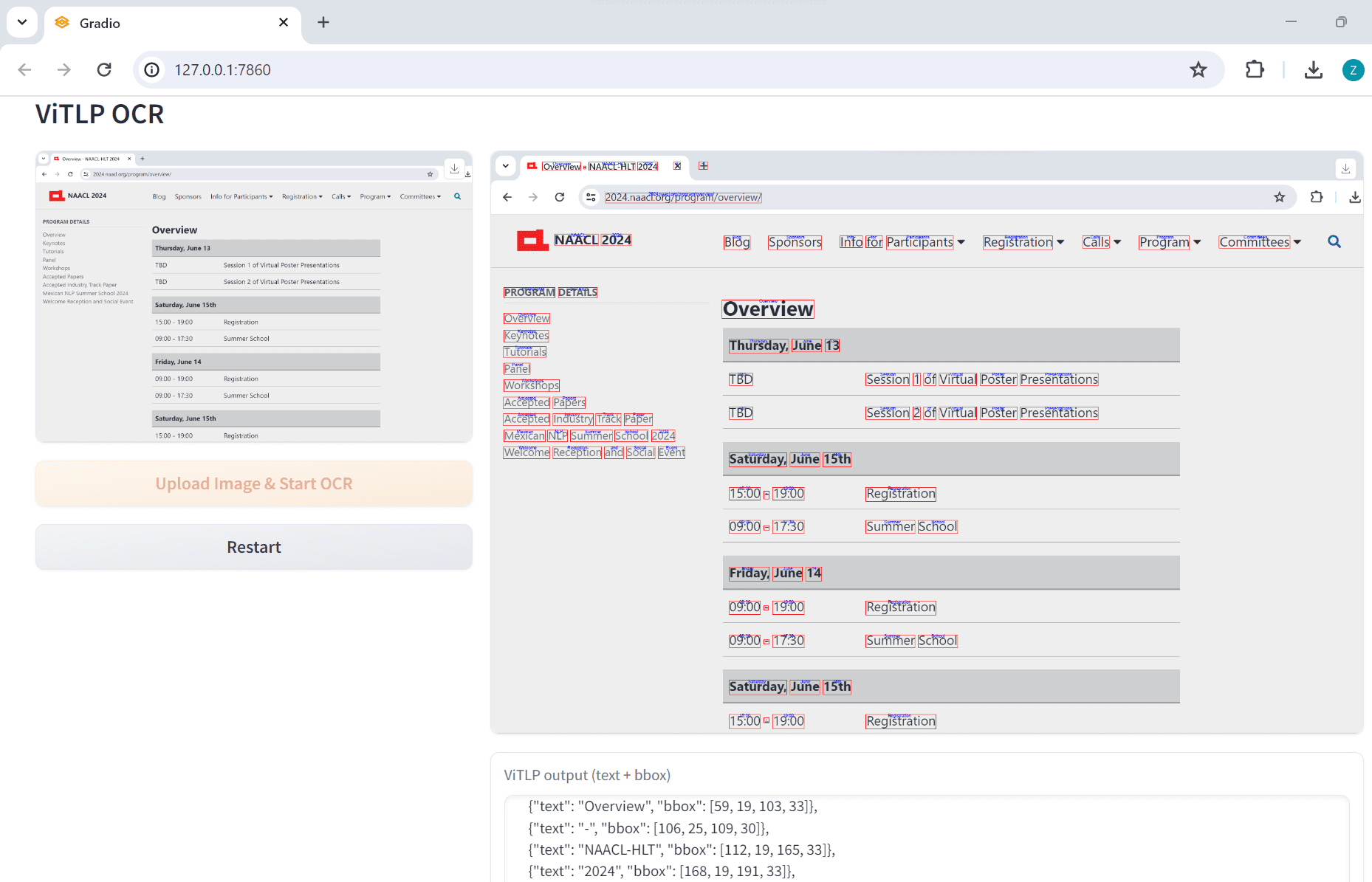
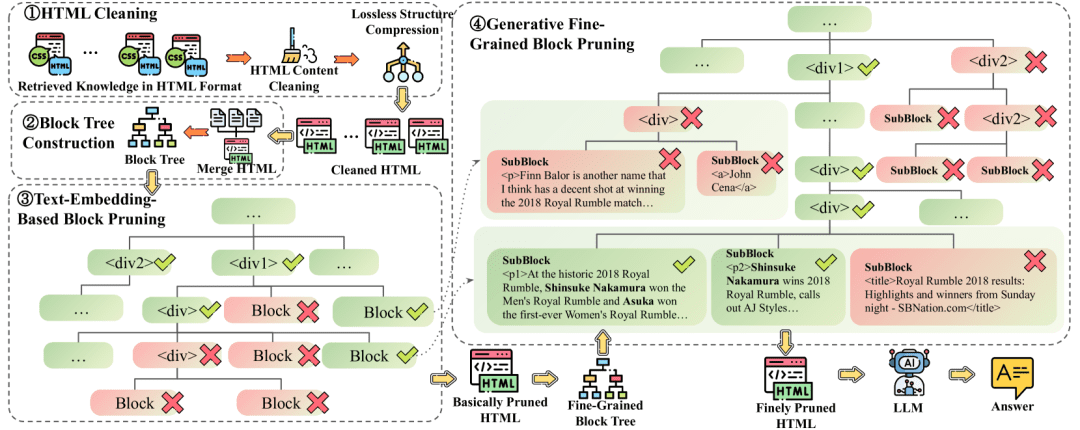
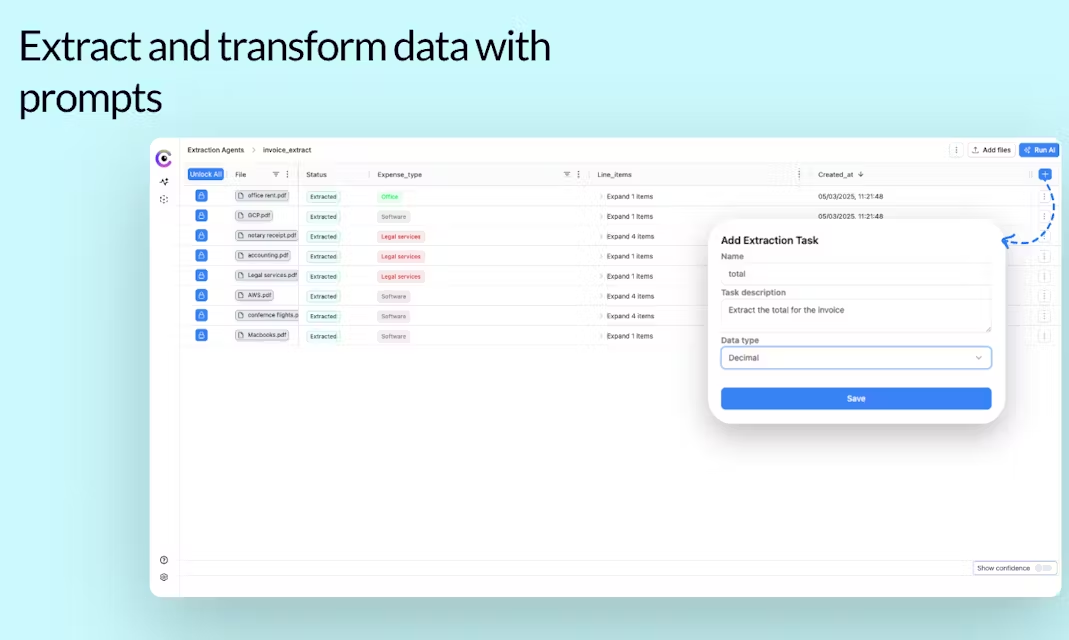
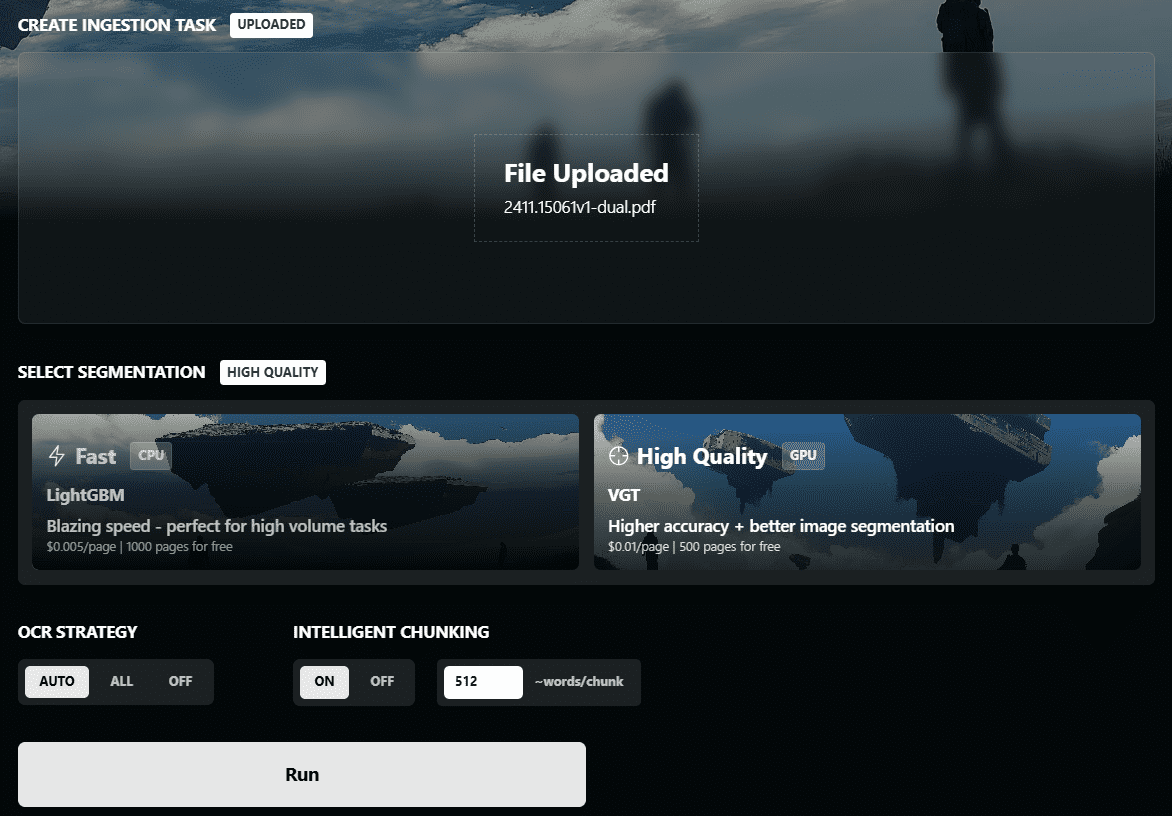
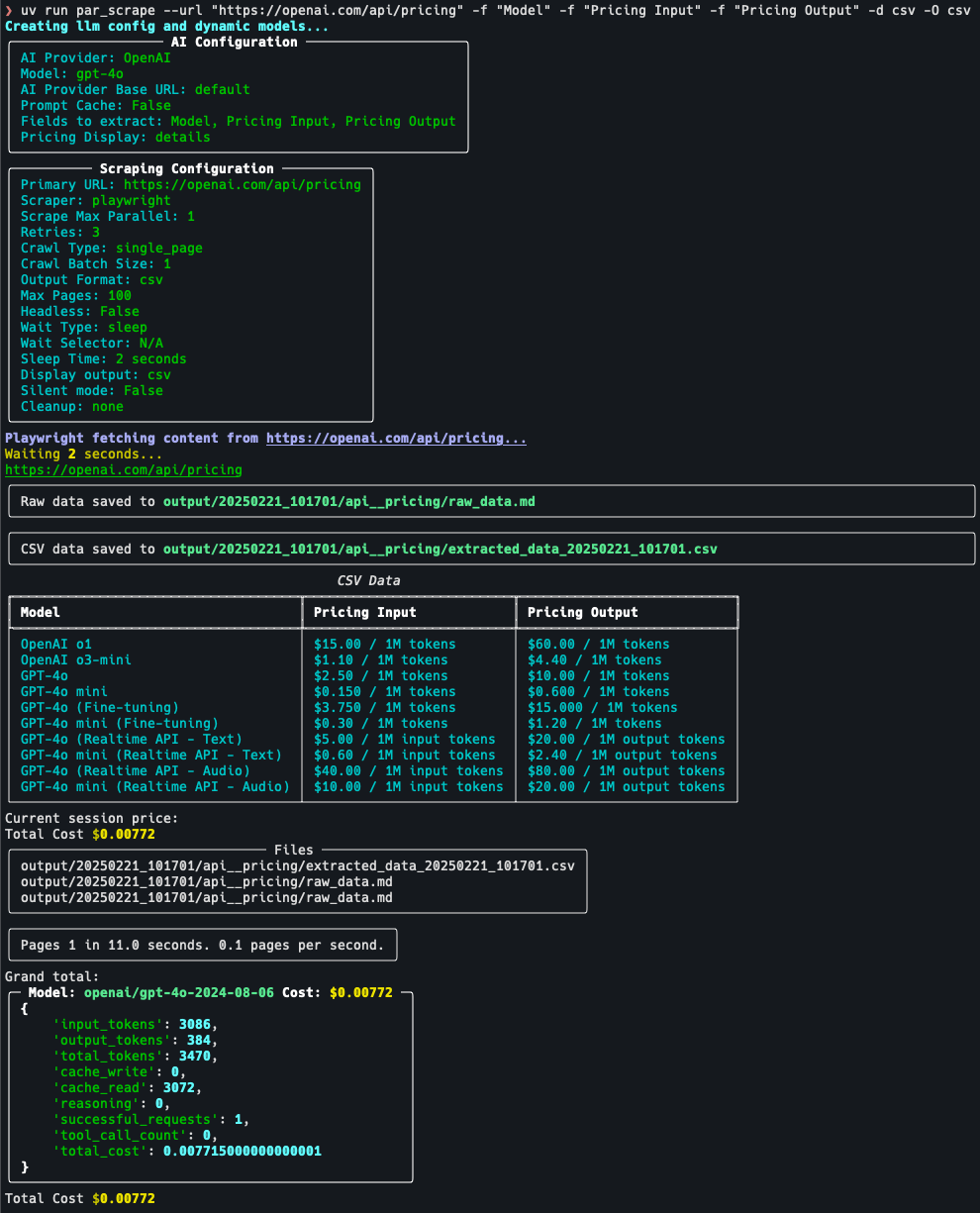
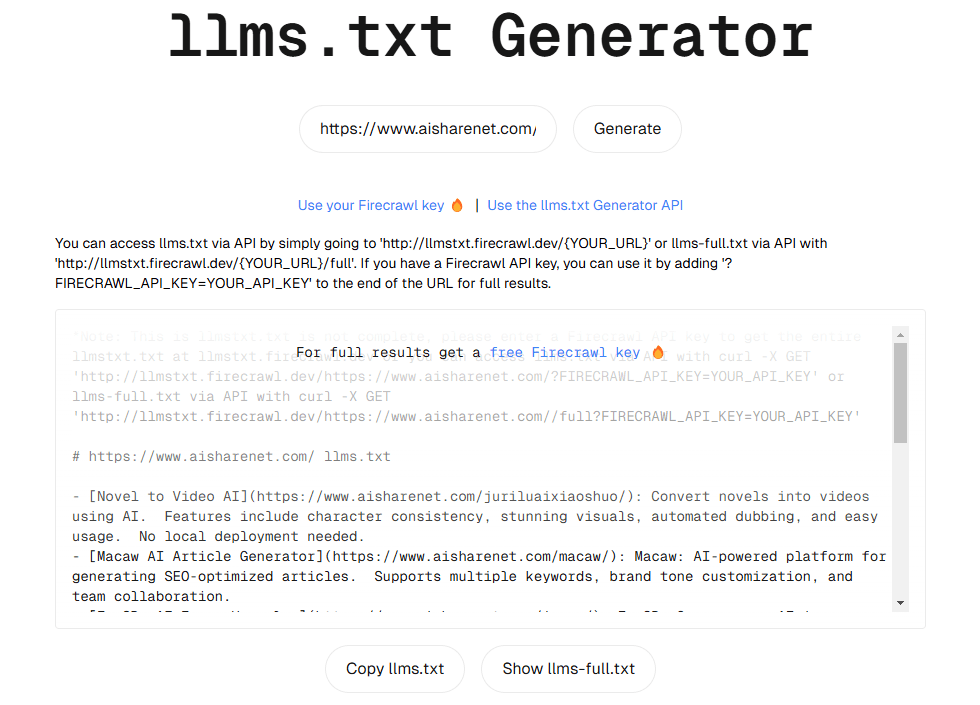
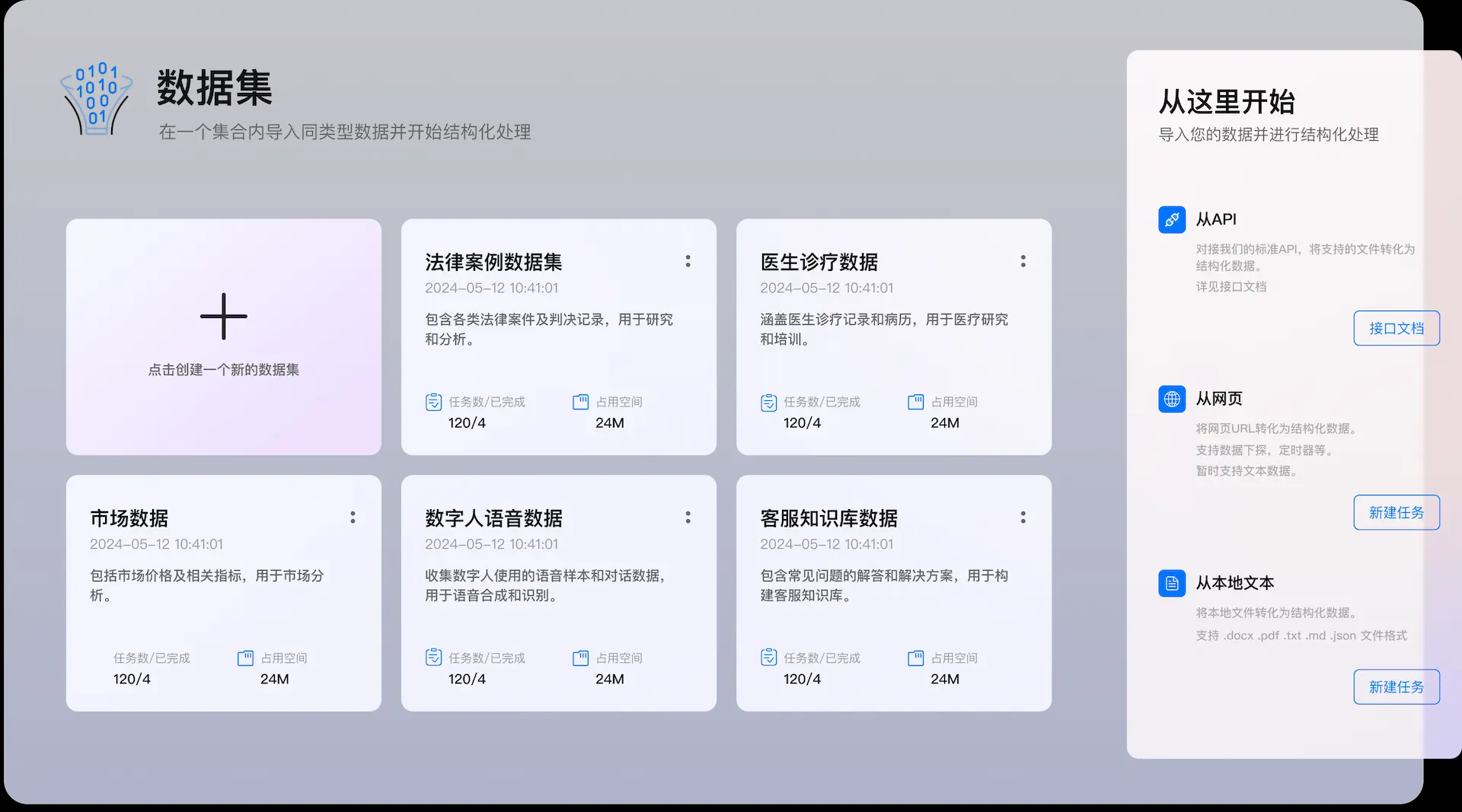
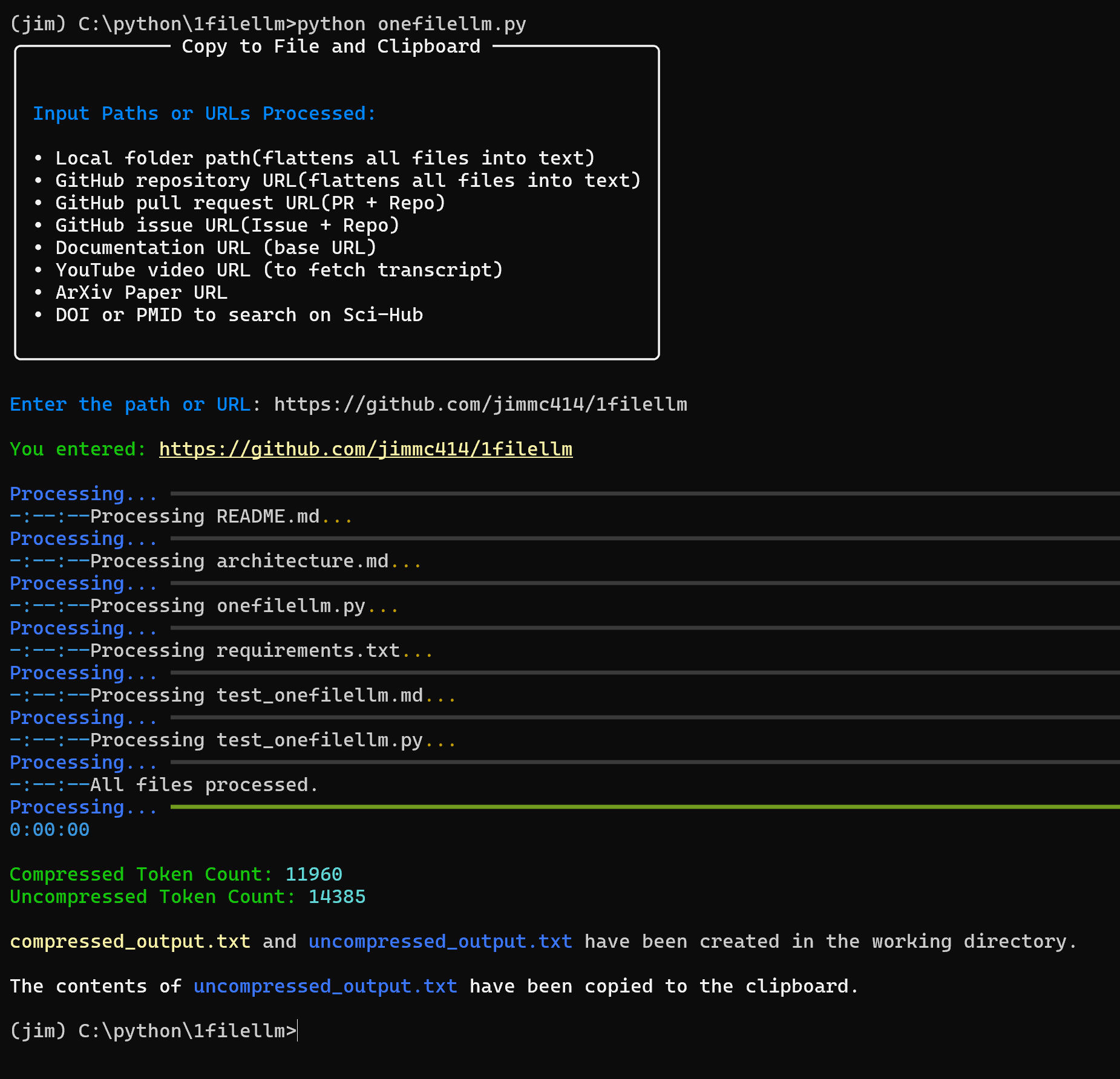
API Reader: инструмент для извлечения веб-контента, преобразование HTML в Markdown
Общее представление Проект Jina AI's Reader - это инструмент с открытым исходным кодом (Reader open source address), который принимает любой URL, добавляя префикс https://r.jina.ai/转换成适合大型语言模型 (Large Languag...