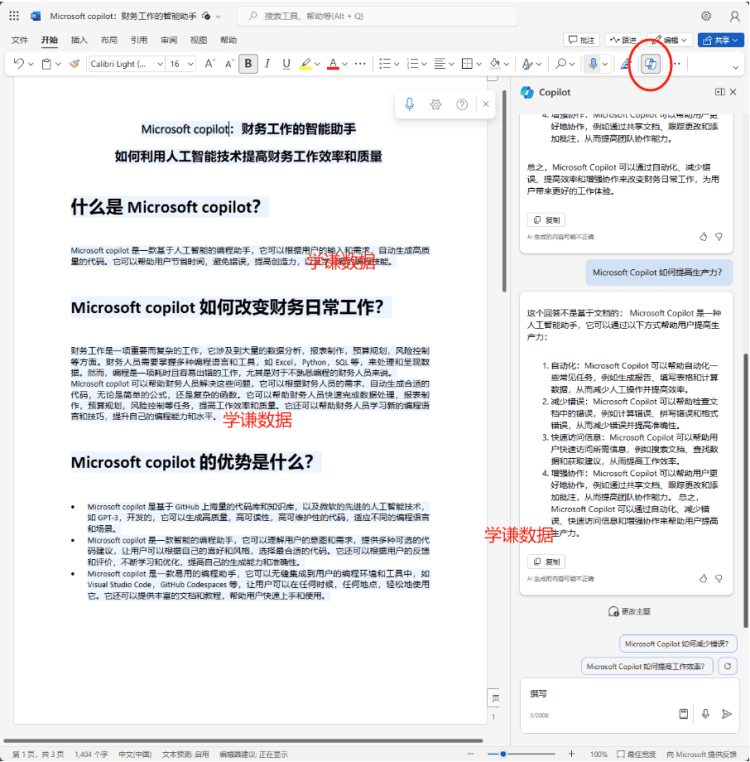
Нативные приложения RAG с DeepSeek R1 и Ollama

краткое содержание
В этом документе подробно описано, как использовать DeepSeek R1 и Оллама Создание локализованных приложений RAG (Retrieval Augmented Generation). Это также первый шаг в процессе Создание локального приложения RAG с помощью LangChain Дополнение.
Мы продемонстрируем весь процесс реализации на примерах, включая обработку документов, хранение векторов, вызов моделей и другие ключевые шаги. В этом учебном пособии используется DeepSeek-R1 1.5B в качестве базовой языковой модели. Учитывая, что различные модели имеют свои собственные характеристики и производительность, читатели могут выбрать другие подходящие модели для реализации в соответствии с реальными потребностями RAG Система.
Примечание: Этот документ содержит основные фрагменты кода и подробные объяснения. Полный код можно найти по адресу ноутбук .
предварительная подготовка
Сначала нам нужно загрузить Ollama и настроить среду.
В GitHub-репозитории Ollama представлено подробное описание, которое вкратце можно изложить следующим образом.
Шаг1, скачать Оллама.
загрузка и дважды щелкните, чтобы запустить приложение Ollama.

Шаг 2: проверьте установку.
В командной строке введите ollamaЕсли появится следующее сообщение, значит, Ollama успешно установлена.

Шаг 3. Вытяните модель.
- В командной строке см. Список моделей Оллама ответить пением Список моделей встраивания текста Вытягивание модели. В этом учебнике мы берем
deepseek-r1:1.5bответить пениемnomic-embed-textПример.- ввод командной строки
ollama pull deepseek-r1:1.5bСоздание общих моделей больших языков с открытым исходным кодомdeepseek-r1:1.5b; (При вытягивании моделей может работать медленно. Если произошла ошибка вытягивания, вы можете повторно ввести команду для вытягивания) - ввод командной строки
ollama pull nomic-embed-textтянуть Модель встраивания текстаnomic-embed-text.
- ввод командной строки
- Когда приложение запущено, все модели автоматически попадают в каталог
localhost:11434На старте. - Обратите внимание, что при выборе модели необходимо учитывать возможности вашего локального оборудования, эталонный объем видеопамяти для данного учебника
CPU Memory > 8GB.
Шаг 4. Разверните модель.
В окне командной строки выполните следующую команду для развертывания модели.
ollama run deepseek-r1:1.5b

Также можно запустить модель развертывания непосредственно из командной строки, например
ollama run deepseek-r1:1.5b.

Обратите внимание, что следующие шаги не требуются, если вы хотите развернуть модели DeepSeek R1 только с помощью Ollama.
Шаг 5. Установите зависимости.
# langchain_community
pip install langchain langchain_community
# Chroma
pip install langchain_chroma
# Ollama
pip install langchain_ollama
С этим покончено, давайте приступим к созданию пошагового решения на основе LangChain, Ollama и DeepSeek R1 Ниже приводится подробное описание этапов реализации. Этапы реализации подробно описаны ниже.
1. загрузка документов
Загрузите PDF-документы и разрежьте их на текстовые блоки подходящего размера.
from langchain_community.document_loaders import PDFPlumberLoader
file = "DeepSeek_R1.pdf"
# Load the PDF
loader = PDFPlumberLoader(file)
docs = loader.load()
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
all_splits = text_splitter.split_documents(docs)
2. Инициализация хранилища векторов
Используйте базу данных Chroma для хранения векторов документов и настройте модель встраивания, предоставляемую Ollama.
from langchain_chroma import Chroma
from langchain_ollama import OllamaEmbeddings
local_embeddings = OllamaEmbeddings(model="nomic-embed-text")
vectorstore = Chroma.from_documents(documents=all_splits, embedding=local_embeddings)
3. Построение цепных выражений
Создайте шаблоны моделей и реплик для построения цепочек обработки.
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_ollama import ChatOllama
model = ChatOllama(
model="deepseek-r1:1.5b",
)
prompt = ChatPromptTemplate.from_template(
"Summarize the main themes in these retrieved docs: {docs}"
)
# 将传入的文档转换成字符串的形式
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
chain = {"docs": format_docs} | prompt | model | StrOutputParser()
question = "What is the purpose of the DeepSeek project?"
docs = vectorstore.similarity_search(question)
chain.invoke(docs)
4. QA с поиском
Интеграция функций поиска и вопросов и ответов.
from langchain_core.runnables import RunnablePassthrough
RAG_TEMPLATE = """
You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.
<context>
{context}
</context>
Answer the following question:
{question}"""
rag_prompt = ChatPromptTemplate.from_template(RAG_TEMPLATE)
retriever = vectorstore.as_retriever()
qa_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| rag_prompt
| model
| StrOutputParser()
)
question = "What is the purpose of the DeepSeek project?"
# Run
qa_chain.invoke(question)
резюме
В этом руководстве подробно рассказывается о том, как создать локализованное приложение RAG с помощью DeepSeek R1 и Ollama. Полная функциональность достигается за четыре основных шага:
- обработка файлов : Используйте PDFPlumberLoader для загрузки PDF-документов и RecursiveCharacterTextSplitter для нарезки текста на фрагменты соответствующего размера.
- векторное хранение : Система векторного хранения данных, использующая базу данных Chroma и модель встраивания Олламы для обеспечения основы для последующего поиска по сходству.
- Создание цепи : Разработайте и внедрите цепочку обработки, которая объединяет обработку документов, шаблоны подсказок и модельные ответы в сквозной процесс.
- Реализация RAG : Интегрируя функции поиска и вопросов и ответов, реализована полноценная система генерации с расширенным поиском, способная отвечать на запросы пользователей, основанные на содержании документов.
С помощью этого руководства вы сможете быстро создать свою собственную локальную систему RAG и усовершенствовать ее в соответствии с вашими реальными потребностями. Рекомендуется опробовать различные модели и конфигурации параметров на практике, чтобы получить максимальную отдачу.
Примечание: С помощью таких инструментов, как streamlit или FastAPI, можно развернуть локальное приложение RAG как веб-сервис, что позволяет расширить спектр сценариев применения.
Хранилище также предоставляет
app.pyвы можете запустить этот файл напрямую, чтобы запустить веб-сервис. Документация Создание системы RAG с помощью DeepSeek R1 и Ollama. Примечание: Перед выполнением этого кода предварительно запустите службу Ollama.
Страница диалога выглядит следующим образом:

© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи


Нет комментариев...