
Как выбрать подходящую модель эмбеддинга?

Retrieval Augmented Generation (RAG) - это класс приложений в генеративном ИИ (GenAI), который поддерживает использование собственных данных для расширения знаний модели LLM (например, ChatGPT).
RAG Обычно используются три различные модели ИИ, а именно модель Embedding, модель Rerankear и модель Big Language. В этой статье мы расскажем о том, как выбрать подходящую модель Embedding в зависимости от типа данных, а также языка или конкретной области (например, юридической).
1. Текстовые данные: рейтинг МТЭБ
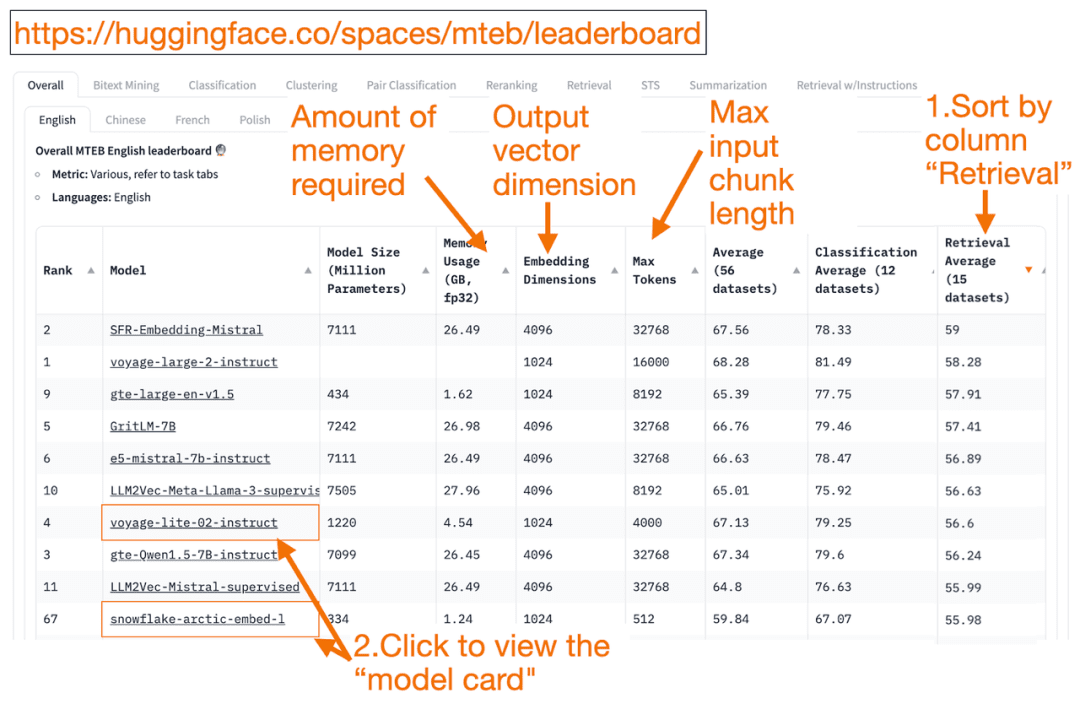
HuggingFace Таблица лидеров МТЭБ это универсальный список моделей для встраивания текста! Вы можете узнать среднюю производительность каждой модели.
Вы можете отсортировать столбец "Retrieval Average" в порядке убывания, так как это лучше всего подходит для задачи векторного поиска. Затем найдите модель с наивысшим рейтингом и наименьшим объемом памяти.
- Размерность вектора встраивания - это длина вектора, т.е. y в f(x)=y, который будет выведен моделью.
- величайший Токен Число - это длина блока входного текста, т.е. x в f(x)=y, который вы можете ввести в модель.
В дополнение к прохождению Поиск Помимо сортировки задач, вы также можете отфильтровать их по следующим критериям:
- Язык: поддерживаются французский, английский, китайский, польский. (например: task=поиск.
Язык=китайский)
- Тексты в правовом поле.
(например, задача=поиск, язык=право)
Стоит отметить, что, поскольку некоторые обучающие данные появились в открытом доступе совсем недавно, некоторые из моделей встраивания в MTEB могут бытьна первый взгляд подходящийОднако на самом деле неподходящие модели с завышенным рейтингом могут работать по-другому. В результате HuggingFace опубликовалблог (заимствованное слово)В нем описаны ключевые моменты для определения достоверности рейтинга модели. После нажатия на ссылку модели (называемую "карточкой модели"):
- Ищите блоги и статьи, в которых рассказывается о том, как модели обучаются и оцениваются. Внимательно изучите язык, данные и задачи, используемые для обучения моделей. Также обратите внимание на модели, созданные известными компаниями. Например, на карточке модели voyage-lite-02-instruct вы увидите другие модели VoyageAI, но не эту. Это подсказка! Эта модель является чрезмерно подходящей и не должна использоваться!
- На скриншоте ниже я попробую новую модель "snowflake-arctic-embed-1" от Snowflake, потому что она имеет высокий рейтинг, достаточно мала, чтобы работать на моем ноутбуке, и содержит ссылки на блоги и статьи на карточке модели.
Преимущество использования HuggingFace в том, что если вам нужно изменить модель после выбора модели Embedding, вам просто нужно изменить имя_модели в коде!
import torch
from sentence_transformers import SentenceTransformer
# Initialize torch settings
torch.backends.cudnn.deterministic = True
DEVICE = torch.device('cuda:3' if torch.cuda.is_available() else 'cpu')
# Load the model from Huggingface
model_name = "WhereIsAI/UAE-Large-V1" # Just change model_name to use a different model!
encoder = SentenceTransformer(model_name, device=DEVICE)
# Get the model parameters and save for later
EMBEDDING_DIM = encoder.get_sentence_embedding_dimension()
MAX_SEQ_LENGTH_IN_TOKENS = encoder.get_max_seq_length()
# Print model parameters
print(f"model_name: {model_name}")
print(f"EMBEDDING_DIM: {EMBEDDING_DIM}")
print(f"MAX_SEQ_LENGTH: {MAX_SEQ_LENGTH_IN_TOKENS}")

2. данные изображения: ResNet50
Иногда вы можете искать изображения, похожие на введенное. Например, вы можете искать больше изображений кошек породы скоттиш-фолд. В этом случае вы можете загрузить фотографию кошки породы скоттиш-фолд и попросить поисковую систему найти похожие изображения.
ResNet50 это популярная модель CNN, первоначально обученная компанией Microsoft в 2015 году на данных ImageNet.
Аналогично, дляПоиск видеоВ этом случае ResNet50 все равно может преобразовать видео в векторы встраивания. Затем выполняется поиск сходства между статичными видеокадрами, и наиболее похожее видео возвращается пользователю как лучшее совпадение.
3. Аудиоданные: PANNs
Подобно поиску изображений, вы также можете искать похожие аудиозаписи на основе входных аудиоклипов.
PANNs(Pre-trained Audio Neural Networks) обычно используются в качестве моделей встраивания для поиска аудио, поскольку PANN предварительно обучены на больших наборах аудиоданных и отлично справляются с такими задачами, как классификация и маркировка аудио.
4. мультимодальные изображения и текстовые данные:
SigLIP или Unum
В последние годы появилось множество моделей встраивания, обученных на смеси неструктурированных данных (текст, изображения, аудио или видео). Эти модели способны отражать семантику нескольких типов неструктурированных данных одновременно в одном и том же векторном пространстве.
Мультимодальная модель Embedding поддерживает поиск изображений по тексту, генерирование текстовых описаний для изображений или поиск изображений.
OpenAI будет запущен в 2021 году CLIP это стандартная модель встраивания. Но поскольку она была сложна в использовании, так как требовала от пользователей тонкой настройки, к 2024 году Google представил SigLIP(Sigmoidal-CLIP). Модель достигла хороших показателей при использовании подсказки "нулевой выстрел".
Небольшие модели LLM сегодня становятся все более популярными. Это связано с тем, что такие модели не требуют больших облачных кластеров и могут работать на ноутбуках. Маленькие модели занимают меньше памяти, имеют меньшую задержку и работают быстрее, чем большие модели.Unum Представлены мультимодальные модели мини-эмбдинга.
5. мультимодальные текстовые, аудио- и видеоданные
Большинство мультимодальных систем RAG "текст-аудио" используют мультимодальные генеративные LLM, которые сначала преобразуют звук в текст, генерируют пары "звук-текст", а затем преобразуют текст в векторы встраивания. Затем вы можете использовать RAG для извлечения текста, как обычно. На последнем этапе текст снова преобразуется в звук.
OpenAI Шепот может транскрибировать речь в текст. Кроме того, OpenAI's Передача текста в речь (TTS) Модели также могут конвертировать текст в аудио.
Мультимодальная система RAG, работающая по принципу "текст-видео", использует аналогичный подход: сначала видео отображается в текст, преобразуется в вектор Embedding, выполняется поиск по тексту и возвращается видео в качестве результата поиска.
OpenAI Сора Текст может быть преобразован в видео. Как и в Dall-e, вы даете текстовые подсказки, а LLM генерирует видео. Sora также может генерировать видео из неподвижных изображений или других видео.
Milvus уже интегрировал основную модель Embedding, и мы приглашаем вас испытать ее:https://milvus.io/docs/embeddings.md
консультация
Таблица лидеров MTEB: https://huggingface.co/spaces/mteb/leaderboard
Лучшие практики МТЭБ: https://huggingface.co/blog/lyon-nlp-group/mteb-leaderboard-best-practices
Поиск похожих изображений: https://milvus.io/docs/image_similarity_search.md
Поиск видео по картинкам: https://milvus.io/docs/video_similarity_search.md
Похожие аудиозаписи: https://milvus.io/docs/audio_similarity_search.md
Поиск текстовых изображений: https://milvus.io/docs/text_image_search.md
2024 SigLIP (sigmoid loss CLIP) Бумага: https://arxiv.org/pdf/2401.06167v1
Мультимодальная модель встраивания Unum:
https://github.com/unum-cloud/uform
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи



Нет комментариев...