
PP-OCRv5 - модель ИИ с открытым исходным кодом от Baidu для распознавания текста нового поколения

Что такое PP-OCRv5
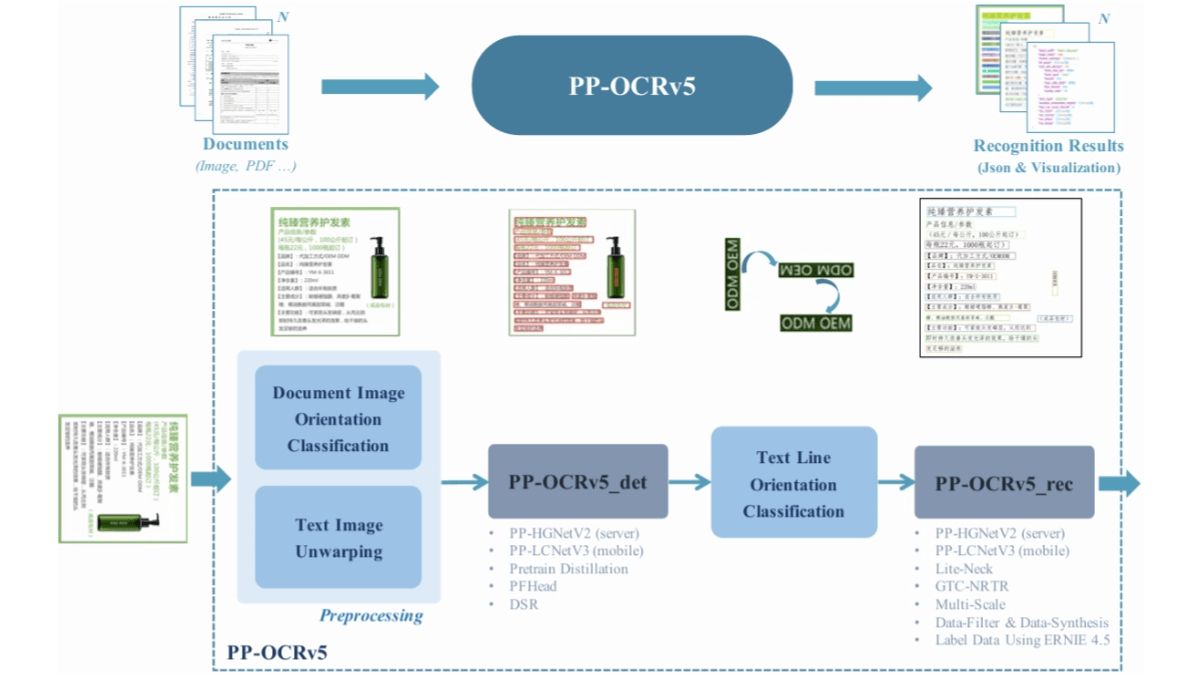
PP-OCRv5 - это последнее поколение модели ИИ для распознавания текста, выпущенное компанией Baidu. Благодаря облегченной конструкции и объему памяти всего 0,07 ББ она подходит для эффективной работы на центральных процессорах и пограничных устройствах и может обрабатывать более 370 символов в секунду. Модель поддерживает пять типов текста, включая упрощенный китайский, традиционный китайский, английский, японский и пиньинь, и может распознавать более 40 языков, что делает ее пригодной для обработки многоязычных документов. PP-OCRv5 использует модульный двухфазный процесс, включающий четыре основных компонента: предварительную обработку изображения, обнаружение текста, классификацию направления текстовой строки и распознавание текста. По сравнению с PP-OCRv4 точность распознавания рукописного китайского текста, распознавания старинного текста, вертикального текста, распознавания уединенных символов и распознавания рукописного английского текста повысилась на 13,8%, 43%, 71%, 96% и 118% соответственно.PP-OCRv5 обновила основу процесса предварительной обработки изображений, который включает четыре основных компонента: предварительную обработку изображений, классификацию направления текстовой строки и распознавание текста. OCRv5 модернизировал опорную сеть, принял архитектуру с двумя ветвями и оптимизировал стратегию построения данных, объединив механизм внимания и потери CTC, чтобы получить высококачественные аннотированные данные из документов, таких как PDF и электронные книги.
Особенности PP-OCRv5
- Легкая конструкция: Благодаря объему ссылок всего 0,07 ББ он подходит для эффективной работы на центральных процессорах и пограничных устройствах, а мобильная версия может обрабатывать более 370 символов в секунду на процессорах Intel Xeon Gold 6271C, обеспечивая быструю обработку больших объемов текстовых данных.
- Поддержка нескольких языковОн поддерживает пять типов текста: упрощенный китайский, традиционный китайский, английский, японский и пиньинь, и может распознавать более 40 языков, что подходит для обработки многоязычных документов и удовлетворяет потребности в распознавании текста в различных языковых средах.
- Высокоточное распознаваниеПо сравнению с PP - OCRv4 точность распознавания рукописного китайского текста, распознавания старинного текста, вертикального текста, распознавания уединенных символов и распознавания рукописного английского текста повысилась на 13,81 TP3T, 431 TP3T, 711 TP3T, 961 TP3T и 1 181 TP3T, соответственно. более точно распознавать различные типы текстов.
- Точное позиционирование текста: Предоставление точных координат границ текстовых строк является ключевым требованием для извлечения структурированных данных и контент-анализа, а также помогает в последующей обработке и анализе текста.
- Одномодельное многоязычное распознаваниеЭто первая в отрасли сверхлегкая (<100 М) модель с открытым исходным кодом, поддерживающая пять типов текста в одной модели. Она обеспечивает бесшовное распознавание пяти типов текста благодаря единой архитектуре модели, устраняя необходимость развертывания независимых моделей для разных типов текста, упрощая процесс развертывания, а также повышая общую точность и скорость распознавания.
- Высокая адаптивность к сложным сценариям: Он поддерживает распознавание различных сложных сценариев, таких как сложный почерк на китайском и английском языках, вертикальный текст и редкие иероглифы, и может работать с различными сложными форматами и содержанием текста, что повышает универсальность и практичность модели.
- Модернизация магистральной сети: Используется двухветвистая архитектура с PP - HGNetV2 в качестве основы, где одна ветвь использует обучение на основе внимания для улучшения моделирования последовательности, а другая ветвь фокусируется на эффективном выводе с использованием потерь CTC. Обе ветви взаимодействуют друг с другом во время обучения, но во время предсказания используются только легкие ветви, что обеспечивает точность и скорость.
- Оптимизация стратегий построения данных: Комбинируйте традиционные модели с ERNIE - 4.5 - VL - 424B - A47B для автоматического аннотирования и фильтрации высококачественных образцов почерка, включая редкие символы, созданные путем синтеза. Крупномасштабные аннотированные данные из документов, таких как PDF-файлы и электронные книги, получены с помощью автоматического синтаксического анализа и фильтрации расстояния между правками, что закладывает прочную основу для общей производительности модели.
Основные преимущества PP-OCRv5
- Легкая конструкция: Количество параметров модели составляет всего 0,07 Б, что обеспечивает более высокую производительность на центральных процессорах и пограничных устройствах. Мобильная версия может обрабатывать более 370 символов в секунду на процессоре Intel Xeon Gold 6271C.
- Высокоточное распознавание: Превосходит визуальные языковые модели общего назначения, такие как Gemini 2.5 Pro, Qwen2.5-VL и GPT-4o, в бенчмарках для OCR, включая рукописные и печатные китайские и английские тексты, а также тексты на пиньинь.
- Поддержка нескольких языковОн поддерживает пять типов текста: упрощенный китайский, традиционный китайский, английский, японский и пиньинь, и может распознавать более 40 языков.
- Точное позиционирование текста: Предоставление точных координат границ текстовых строк является ключевым требованием для извлечения структурированных данных и анализа контента.
Что представляет собой официальный сайт PP-OCRv5?
- Веб-сайт проекта:: https://huggingface.co/blog/baidu/ppocrv5
- Библиотека моделей HuggingFace:: https://huggingface.co/collections/PaddlePaddle/pp-ocrv5-684a5356aef5b4b1d7b85e4b
Для кого предназначен PP-OCRv5?
- Разработчики предприятий: Предприятия, которым необходимо интегрировать высокоэффективные функции распознавания текста в свои бизнес-системы, например, в финансовой, медицинской и образовательной отраслях, могут использовать его в таких сценариях, как разбор договоров, оцифровка медицинских карт и исправление экзаменационных работ.
- (научный) исследователь: Исследователи, занимающиеся компьютерным зрением, обработкой естественного языка и другими областями искусственного интеллекта, могут использовать PP-OCRv5 для академических исследований и сравнения моделей.
- разработчик программного обеспеченияРазработчики приложений, требующих функциональности распознавания текста, таких как мобильные приложения, настольные программы и т. д., могут быстро интегрировать PP-OCRv5 для достижения функциональности.
- Аналитик данных: Аналитики данных, которым необходимо извлекать структурированные данные из большого количества документов для быстрой обработки и анализа текстовых данных.
- педагог: Преподаватели, которым необходимо обрабатывать и анализировать рукописные тексты, такие как задания и контрольные работы учеников, могут использовать его для автоматической коррекции и анализа содержания.
- файловый менеджерДля архивистов, ответственных за управление и оцифровку большого количества бумажных документов, и может использоваться для быстрой идентификации и категоризации документов.
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи


Нет комментариев...