
PDF Craft: преобразование отсканированных документов PDF в Markdown с открытым исходным кодом

Общее введение
PDF Craft - это инструмент с открытым исходным кодом, предназначенный для сканирования PDF-файлов книг и преобразования их в формат Markdown. Он разработан лабораторией oomol-lab и размещен на GitHub для пользователей, которые любят организовывать свои электронные книги. Инструмент работает через локальную модель искусственного интеллекта и не требует подключения к интернету, что защищает конфиденциальность и облегчает работу. Он извлекает основной текст из отсканированных документов, удаляет различные элементы, такие как заголовки и колонтитулы, и создает чистый файл в формате Markdown, который особенно подходит для упорядочивания старых книг или исследовательских материалов.

Список функций
- Конвертируйте отсканированные книги PDF в формат Markdown с поддержкой встроенной обработки.
- Извлечение основного содержимого и автоматическая фильтрация заголовков, колонтитулов и номеров страниц.
- Работайте с текстом на разных страницах и сохраняйте связность предложений.
- Поддержка иллюстраций и скриншотов таблиц, встроенных в файлы Markdown.
- Используйте искусственный интеллект для анализа расположения страниц и организации текста в порядке чтения.
- Возможность расширения до формата EPUB для создания файлов электронных книг.
Использование помощи
PDF Craft специализируется на сканировании книг из PDF в Markdown. Здесь подробно описаны шаги по установке и использованию, которые помогут вам быстро начать работу.
Процесс установки
- Подготовка среды
Вам понадобится компьютер с установленной версией Python 3.8 или выше. Убедитесь, что на жестком диске достаточно места для хранения моделей ИИ. - Код загрузки
Откройте терминал и введите команду Clone Project:
git clone https://github.com/oomol-lab/pdf-craft.git
Затем перейдите к каталогу:
cd pdf-craft
- Установка зависимостей
Введите следующую команду для установки необходимых библиотек:
pip install -r requirements.txt
Если у вас есть GPU, вы можете добавить поддержку CUDA:
pip install torch --extra-index-url https://download.pytorch.org/whl/cu117
- Получение модели
При первом запуске инструмент автоматически загрузит модель AI (например, DocLayout-YOLO). Сохраняя сеть открытой, модель будет сохранена в<model_dir_path>(может быть задано в коде).
рабочий процесс
Преобразование в Markdown
- Подготовить PDF
Поместите отсканированные PDF-файлы книг в папку, например/path/to/pdf/book.pdf. - преобразование во время выполнения
Введите в терминал следующий код:
from pdf_craft import PDFPageExtractor, MarkDownWriter
extractor = PDFPageExtractor(device="cpu", model_dir_path="/path/to/model/dir/path")
with MarkDownWriter(markdown_path="/path/to/output.md", image_dir="images", encoding="utf-8") as md:
for block in extractor.extract(pdf="/path/to/pdf/book.pdf"):
md.write(block)
device="cpu": Работает на центральном процессоре. Поддержка GPU читаетdevice="cuda:0".markdown_path: Путь к выходному файлу Markdown.image_dir: Каталог сохраненных иллюстраций.
- Посмотреть результаты
Когда закончите, откройте/path/to/output.mdПроверьте содержимое. Иллюстрации автоматически сохраняются вimagesПапка.
Функциональное управление
- извлечение текста
Инструмент распознает отсканированные страницы, удаляет верхние и нижние колонтитулы и сохраняет только основной текст. Вам не нужно вручную убирать беспорядок. - межстраничная обработка
Если предложение усекается разрывом страницы, PDF Craft автоматически соединяет его, чтобы обеспечить плавное перетекание текста. - Встраивание иллюстраций
Изображения или таблицы в отсканированных книгах будут сфотографированы и вставлены в Markdown. Вы можете найти их вimagesпапку, чтобы найти их.
наконечник
- Качество сканирования PDF должно быть четким, иначе распознавание может быть ошибочным.
- При первом запуске модель будет загружена, после чего она станет доступна в автономном режиме.
- Если он работает медленно, попробуйте использовать GPU-ускорение или уменьшить количество страниц.
сценарий применения
- Упорядочить старые книги
У вас есть отсканированные PDF-файлы старых книг, которые вы хотите преобразовать в Markdown для редактирования. PDF Craft поможет избавиться от беспорядка и создать чистые файлы. - Преобразование исследовательских данных
Ученым необходимо преобразовать отсканированные документы в Markdown, чтобы делать заметки. Инструмент сохраняет текст и иллюстрации для удобства цитирования. - Производство электронных книг
Вы хотите превратить отсканированные PDF-файлы в редактируемые документы в формате Markdown. PDF Craft предлагает простые решения.
QA
- Поддерживает ли он только сканирование PDF-файлов?
В основном оптимизирован для сканированных книжных PDF-файлов. Обычные текстовые PDF-файлы будут работать, но, вероятно, не так хорошо, как сканированные документы. - Что делать с изображениями после преобразования?
Изображение сохраняется в виде скриншота в указанную папку, а ссылка автоматически встраивается в Markdown. - Почему первый запуск медленный?
Потому что вам нужно загрузить модель ИИ. После этого игра становится быстрее.
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи

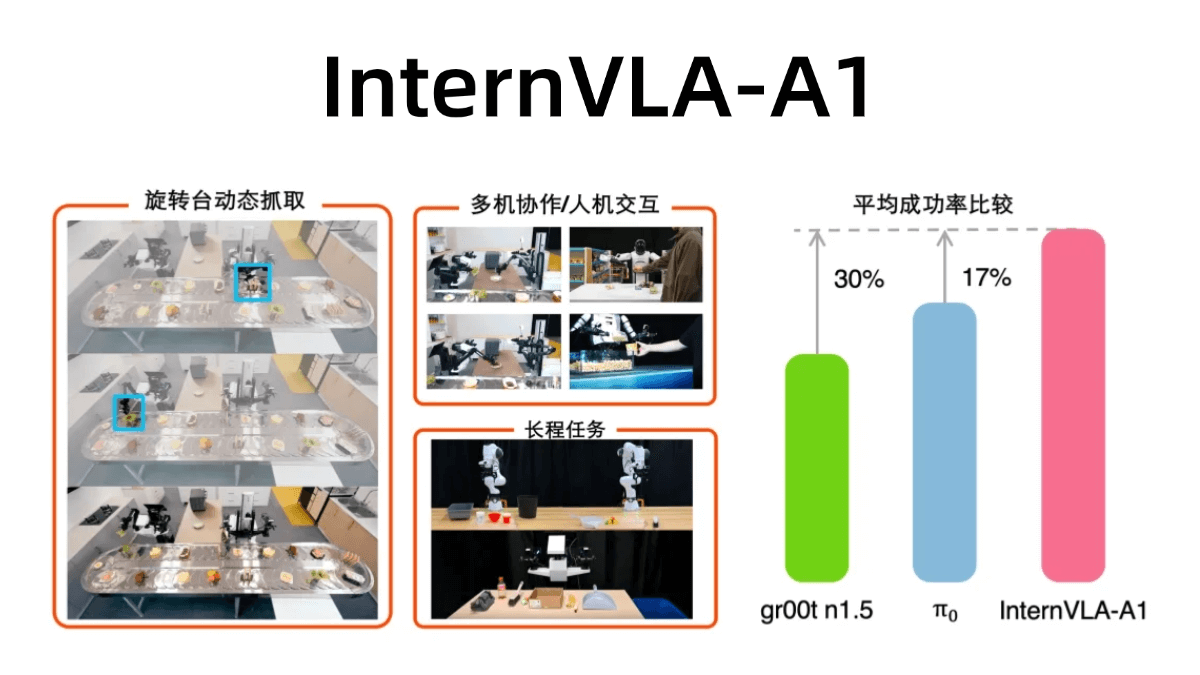

Нет комментариев...