Ovis: модель визуального и текстового выравнивания для точного обратного распространения слов-подсказок к изображениям

Общее введение
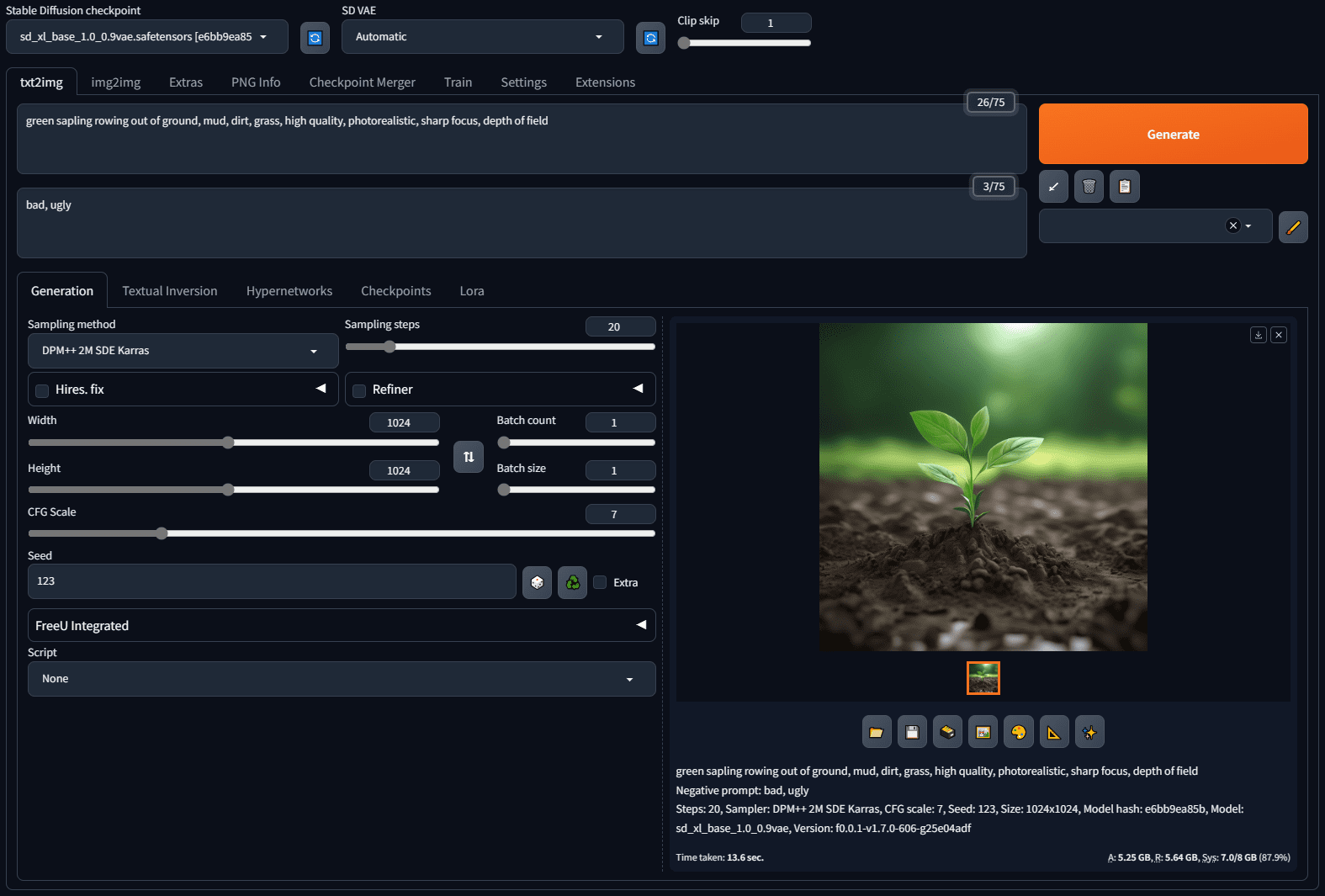
Ovis (Open VISion) - это мультимодальная модель большого языка (MLLM) с открытым исходным кодом, разработанная командой AIDC-AI Международной группы цифровой торговли Alibaba и размещенная на GitHub. Она использует инновационную технику выравнивания структурных вкраплений для эффективного объединения визуальных и текстовых данных, поддерживая мультимодальные входные данные, такие как изображения, текст и видео, и генерируя соответствующий выходной контент. В марте 2025 года компания Ovis выпустила семейство Ovis2 (шкалы параметров от 1B до 34B), которое отличается превосходной миниатюрностью, расширенными возможностями вывода и способностью обрабатывать изображения и видео высокого разрешения. Проект, ориентированный на разработчиков и исследователей, предоставляет подробную документацию и код, ориентирован на сотрудничество с открытым исходным кодом и уже завоевал популярность в сообществе.

Список функций
- Поддержка мультимодального ввода: Работает с несколькими типами ввода, такими как изображения, текст, видео и т.д.
- Визуальное выравнивание текста: Генерируйте текстовые описания, которые точно соответствуют содержанию изображения или видео.
- Обработка изображений высокого разрешения: Оптимизировано для поддержки изображений высокого разрешения и сохранения деталей.
- Анализ видео и мультиграфов: Поддерживает последовательную обработку последовательностей видеокадров и нескольких изображений.
- Улучшенные навыки мышления: Улучшение логического мышления с помощью настройки инструкций и обучения DPO.
- Поддержка многоязычного распознавания текста: Распознавание и обработка многоязычного текста изображений.
- Несколько вариантов моделей: Модели с параметрами от 1B до 34B доступны для различного оборудования.
- Количественная поддержка версий: например, модель GPTQ-Int4 для снижения операционного порога.
- Интеграция интерфейса Gradio: Обеспечьте интуитивно понятный интерфейс для взаимодействия с Интернетом.
Использование помощи
Процесс установки
Установка Ovis зависит от специфических сред и библиотек Python, как описано ниже:
- Подготовка к защите окружающей среды
- Убедитесь, что Git и Anaconda установлены.
- Клонируйте репозиторий Ovis:
git clone git@github.com:AIDC-AI/Ovis.git - Создайте и активируйте виртуальную среду:
conda create -n ovis python=3.10 -y conda activate ovis
- Зависимая установка
- Перейдите в каталог проектов:
cd Ovis - Установите зависимости (на основе
requirements.txt):pip install -r requirements.txt - Установите пакет Ovis:
pip install -e . - (Необязательно) Установка библиотек ускорения (например, Flash Attention):
pip install flash-attn==2.7.0.post2 --no-build-isolation
- Перейдите в каталог проектов:
- Экологическая валидация
- Проверьте версию PyTorch (рекомендуется 2.4.0):
python -c "import torch; print(torch.__version__)"
- Проверьте версию PyTorch (рекомендуется 2.4.0):
Как использовать Ovis
Ovis поддерживает как работу с командной строкой, так и с интерфейсом Gradio:
рассуждения из командной строки
- Подготовка моделей и исходных данных
- Загрузите модель с сайта Hugging Face (например, Ovis2-8B):
git clone https://huggingface.co/AIDC-AI/Ovis2-8B - Подготовьте исходные файлы, например, изображения
example.jpgи запрос "Опишите эту картину".
- Загрузите модель с сайта Hugging Face (например, Ovis2-8B):
- рассуждения о беге
- Создание сценариев
run_ovis.py::import torch from PIL import Image from transformers import AutoModelForCausalLM # 加载模型 model = AutoModelForCausalLM.from_pretrained( "AIDC-AI/Ovis2-8B", torch_dtype=torch.bfloat16, multimodal_max_length=32768, trust_remote_code=True ).cuda() # 获取 tokenizer text_tokenizer = model.get_text_tokenizer() visual_tokenizer = model.get_visual_tokenizer() # 处理输入 image = Image.open("example.jpg") text = "描述这张图片" query = f"<image>\n{text}" prompt, input_ids, pixel_values = model.preprocess_inputs(query, [image]) attention_mask = torch.ne(input_ids, text_tokenizer.pad_token_id) # 生成输出 with torch.inference_mode(): output_ids = model.generate( input_ids.unsqueeze(0).cuda(), pixel_values=[pixel_values.cuda()], attention_mask=attention_mask.unsqueeze(0).cuda(), max_new_tokens=1024 ) output = text_tokenizer.decode(output_ids[0], skip_special_tokens=True) print("输出结果:", output) - Выполните скрипт:
python run_ovis.py
- Создание сценариев
- Посмотреть результаты
- Пример вывода: "На картинке изображена собака, стоящая в травянистом поле с голубым небом на заднем плане".
Работа с интерфейсом Gradio
- Начальные услуги
- Запустите его из каталога Ovis:
python ovis/serve/server.py --model_path AIDC-AI/Ovis2-8B --port 8000 - Ожидание загрузки, доступ
http://127.0.0.1:8000.
- Запустите его из каталога Ovis:
- работа интерфейса
- Загрузите фотографию в интерфейс.
- Введите подсказки, например "Что на этой картинке?". .
- Нажмите кнопку Отправить, чтобы просмотреть сгенерированные результаты.
Основные функции
Обработка изображений высокого разрешения
- процедура: Загрузите изображения высокого разрешения, и модель будет автоматически разбита на разделы (максимальное количество разделов - 9).
- взять: Подходит для таких задач, как анализ произведений искусства и интерпретация карт.
- Рекомендации по аппаратному обеспечениюНовейшее дополнение к ОС - 16 ГБ графической памяти, которая обеспечивает плавную работу.
Анализ видео и мультиграфов
- процедура::
- Подготовьте кадры видео или несколько изображений, например
[Image.open("frame1.jpg"), Image.open("frame2.jpg")]. - Измените код вывода в
pixel_valuesПараметр представляет собой список из нескольких изображений.
- Подготовьте кадры видео или несколько изображений, например
- взять: Анализ видеоклипов или последовательностей непрерывных изображений.
- Образец вывода: "Первый кадр - улица, второй - пешеход".
Поддержка многоязычного распознавания текста
- процедура: Загрузите изображения, содержащие текст на нескольких языках, и введите запрос "Извлечь текст из изображения".
- взять: Сканирование документов, перевод текста изображений.
- Примеры результатов: Извлечение смешанного китайского и английского текста и создание описаний.
Улучшенные навыки мышления
- процедура: Вводите сложные вопросы, такие как "Сколько людей на картинке? Пожалуйста, объясните шаг за шагом".
- взять:: Образование, задачи анализа данных.
- Образец вывода:: "На картинке два человека, первый шаг - наблюдение за одним человеком с левой стороны, второй шаг - наблюдение за вторым человеком с правой стороны".
предостережение
- требования к оборудованию: Ovis2-1B требует 4 ГБ видеопамяти, Ovis2-34B рекомендует использовать несколько GPU (48 ГБ+).
- Совместимость моделей: Поддержка основных LLM (например, Qwen2.5) и ViT (например, aimv2).
- Обратная связь с сообществом: Проблемы могут быть представлены на GitHub Issues.
Ovis2 Image Backpropagation Prompt Word One-Click Installer
На основе моделей Ovis2-4B и Ovis2-2B.
Кварк: https://pan.quark.cn/s/23095bb34e7c
Baidu: https://pan.baidu.com/s/12fWAbshwKY8OYcCcv_5Pkg?pwd=2727
Разархивируйте пароль и найдите его по адресу jian27.
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи


Нет комментариев...