OuteTTS: экспериментальная модель преобразования текста в речь, TTS, реализованная с использованием подхода чистого языкового моделирования

Общее введение
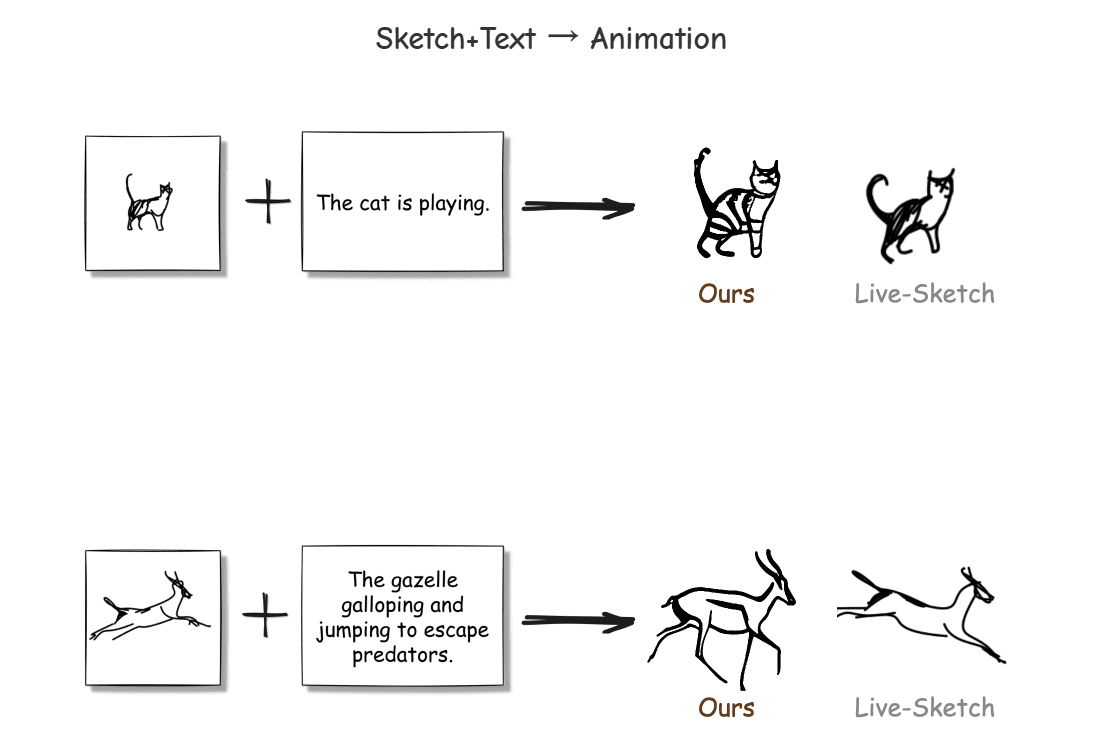
OuteTTS - это экспериментальная модель преобразования текста в речь (TTS), которая использует подход чистого языкового моделирования для генерации высококачественной речи. В отличие от традиционных систем TTS, OuteTTS не требует внешних адаптеров или сложных архитектур. Модель основана на архитектуре LLaMa и поддерживает функцию клонирования речи, которая позволяет генерировать речь со случайными характеристиками диктора. OuteTTS нацелена на достижение эффективного синтеза речи с помощью простой архитектуры, подходящей для широкого спектра сценариев применения.
OuteTTS-0.1-350M - это шаг вперед в упрощении синтеза текста в речь. OuteTTS-0.1-350M доказывает, что высококачественная речь может быть сгенерирована с помощью чисто лингвистического подхода к моделированию.
Список функций
- преобразование текста в речь: Преобразует набранный текст в естественную, плавную речь.
- клонирование речи: Создавайте пользовательские динамики, ссылаясь на аудиофайлы и генерируя соответствующую речь.
- Поддержка нескольких моделейПоддерживаются: модель Hugging Face и модель GGUF.
- Воспроизведение и сохранение аудио: Созданный голос можно воспроизвести напрямую или сохранить в виде аудиофайла.
- Температура и повторное наказание: Управление разнообразием и плавностью генерируемой речи с помощью регулировки параметров температуры и штрафа за повторы.
Использование помощи
Процесс установки
- Установка OuteTTS::
pip install outettsВажно: Для поддержки GGUF необходимо вручную установить
llama-cpp-python. Посетите llama-cpp-python Получите специальные инструкции по установке.
Использование
- Инициализация интерфейса::
from outetts.v0_1.interface import InterfaceHF, InterfaceGGUF # 使用 Hugging Face 模型初始化接口 interface = InterfaceHF("OuteAI/OuteTTS-0.1-350M") # 或者使用 GGUF 模型初始化接口 # interface = InterfaceGGUF("path/to/model.gguf") - Создание выходных данных TTS::
output = interface.generate( text="Hello, am I working?", temperature=0.1, repetition_penalty=1.1, max_length=4096 ) - Воспроизведение и сохранение сгенерированного аудио::
# 播放生成的音频 output.play() # 保存生成的音频到文件 output.save("output.wav")
клонирование речи
- Создание пользовательских колонок::
speaker = interface.create_speaker( "path/to/reference.wav", "reference text matching the audio" ) - Сохранение и загрузка колонок::
# 保存说话人到文件 interface.save_speaker(speaker, "speaker.pkl") # 从文件加载说话人 speaker = interface.load_speaker("speaker.pkl") - Генерация TTS с помощью пользовательской речи::
output = interface.generate( text="This is a cloned voice speaking", speaker=speaker, temperature=0.1, repetition_penalty=1.1, max_length=4096 )
параметризация
- Температура: Регулирует разнообразие генерируемой речи. Более низкие температуры (например, 0,1) генерируют более детерминированные результаты, в то время как более высокие температуры (например, 0,7) генерируют более разнообразные результаты.
- Штраф за повторение (repetition_penalty): Контролирует уровень повторов в генерируемой речи. Более высокий штраф за повторение (например, 1,1) уменьшает генерацию дублирующего контента.
Выполнив описанные выше действия, пользователи смогут легко установить и использовать модель OuteTTS для преобразования текста в речь и клонирования речи. Подробные настройки параметров и примеры использования помогут пользователям генерировать высококачественную речь в соответствии с их конкретными потребностями.
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи


Нет комментариев...