MuseV+Muse Talk: полная система генерации цифрового человеческого видео | портрет в видео | поза в видео | синхронизация губ

Общее введение
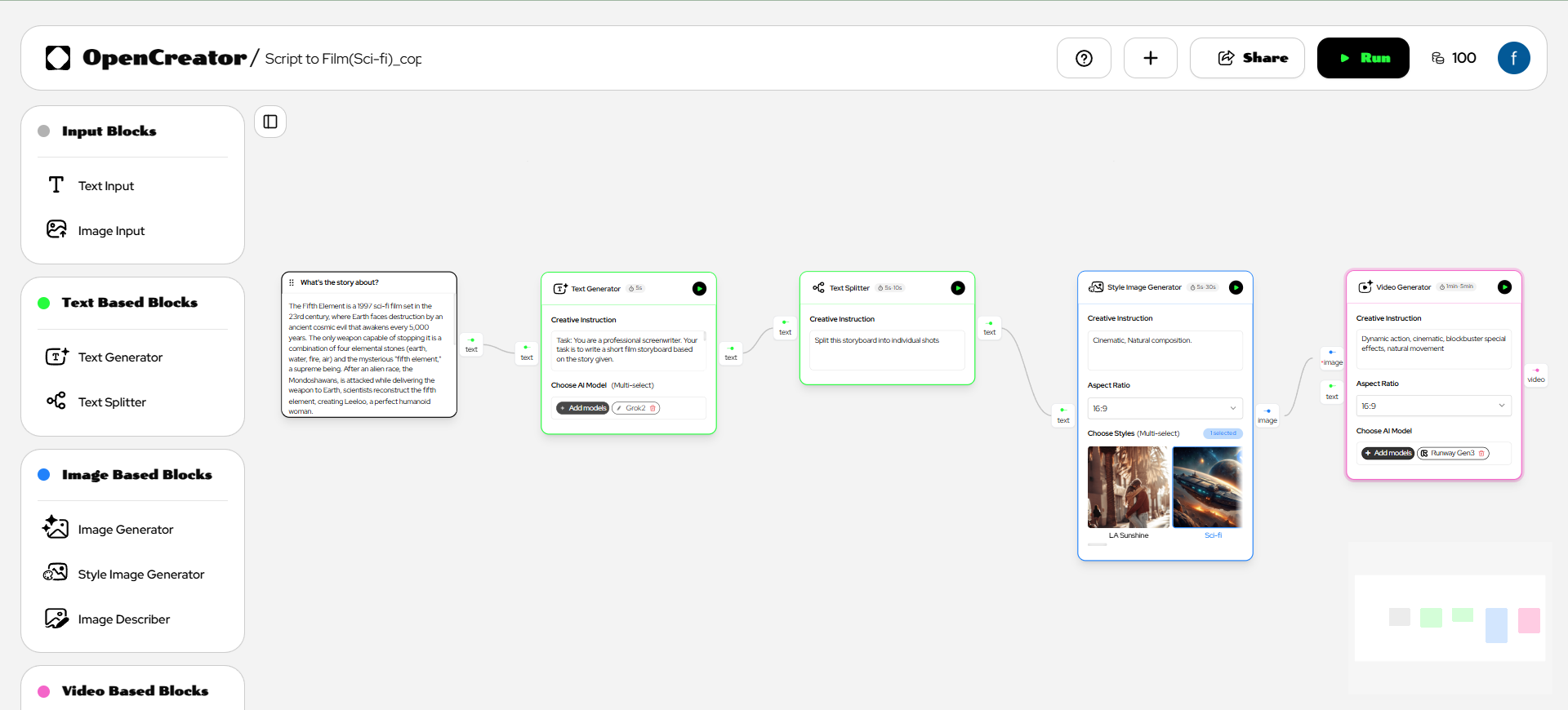
MuseV - это публичный проект на GitHub, предназначенный для создания аватарных видео неограниченной длины и высокой достоверности. Он основан на технологии диффузии и предоставляет различные возможности, такие как Image2Video, Text2Image2Video, Video2Video и другие. Подробно описана структура модели, примеры использования, краткое руководство, скрипты вывода и благодарности.
MuseV - это система создания видеороликов с виртуальными людьми, основанная на диффузионной модели и обладающая следующими возможностями:
Она поддерживает генерацию изображений бесконечной длины с использованием новой визуальной условно-параллельной схемы разрядки без проблемы накопления ошибок, особенно для сцен с фиксированным положением камеры.
Предоставляется предварительно обученная модель для создания видео аватаров, обученная на наборе данных о типах персонажей.
Поддерживает преобразование изображений в видео, текста в изображения и видео в видео.
Совместим с экосистемой создания графики Stable Diffusion, включая base_model, lora, controlnet и другие.
Поддержка нескольких технологий создания эталонных изображений, включая IPAdapter, ReferenceOnly, ReferenceNet, IPAdapterFaceID.
Позже мы также выпустим учебный код.

Список функций
Создание видео неограниченной длины
Высокоточные виртуальные изображения человека
Универсальная поддержка: Image2Video, Text2Image2Video, Video2Video
Четкая структура модели и примеры использования
Быстрый старт и сценарии рассуждений
Использование помощи
Посещайте репозитории GitHub для получения обновлений и загружаемых ресурсов
Для первоначальной настройки проекта следуйте руководству по быстрому запуску
Создайте видеоконтент, используя предоставленные сценарии вывода
Комбинированный метод использования:
Метод 1: запись живого видео + Muse Talk
Метод 2: Изображение + MuseV + Muse Talk
готовый продукт
Из зацикленного видео сделайте аниме-персонажа говорящим, у мультяшного персонажа отсутствуют губы, что делает его речь странной, в следующий раз замените изображение на "губы", желательно "реальных людей". 45 секунд видео в официальном Подождите около 15 минут, чтобы получить тестовое окружение.
Заставить видео говорить в рабочих процессах ComfyUI
Мы запускаем MuseTalk MuseTalk - это высококачественная модель синхронизации рта в реальном времени (30fps+ на NVIDIA Tesla V100). MuseTalk может применяться с входным видео, например, генерируемым MuseV, в качестве комплексного решения для аватаров.

MuseV Online Experience / Пакет установки в один клик для Windows
Модель синхронизации рта компаньона MuseV MuseTalk
Ссылка: https://pan.quark.cn/s/ed896ceda5c8
Код для извлечения: JygA
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие посты



Нет комментариев...