MOSS-Speech - Большая модель преобразования речи в речь с открытым исходным кодом Фуданьского университета

Что такое MOSS-Speechs
MOSS-Speech - это большая модель преобразования речи в речь (Speech-to-Speech) с открытым исходным кодом, разработанная командой профессора Цю Сипэна из Фуданьского университета. Она преодолевает традиционную обработку речи, не нуждаясь в текстовых подсказках, и напрямую воспринимает и генерирует речь, которая может улавливать такие нетекстовые элементы, как интонация и эмоции, делая речевое взаимодействие более естественным. Модель разработана на основе предварительно обученного текстового LLM, а благодаря модальному наслоению и двухэтапному предварительному обучению она объединяет возможности понимания и генерации речи, поддерживает ввод и вывод как речи, так и текста, а также реализует кросс-модальное взаимодействие. MOSS-Speech использует передовую технологию кодирования речи, которая позволяет модели понимать смысл речи при ее сжатии. Замороженная стратегия предварительного обучения позволяет реализовать возможности обработки речи, сохраняя при этом исходные возможности LLM.
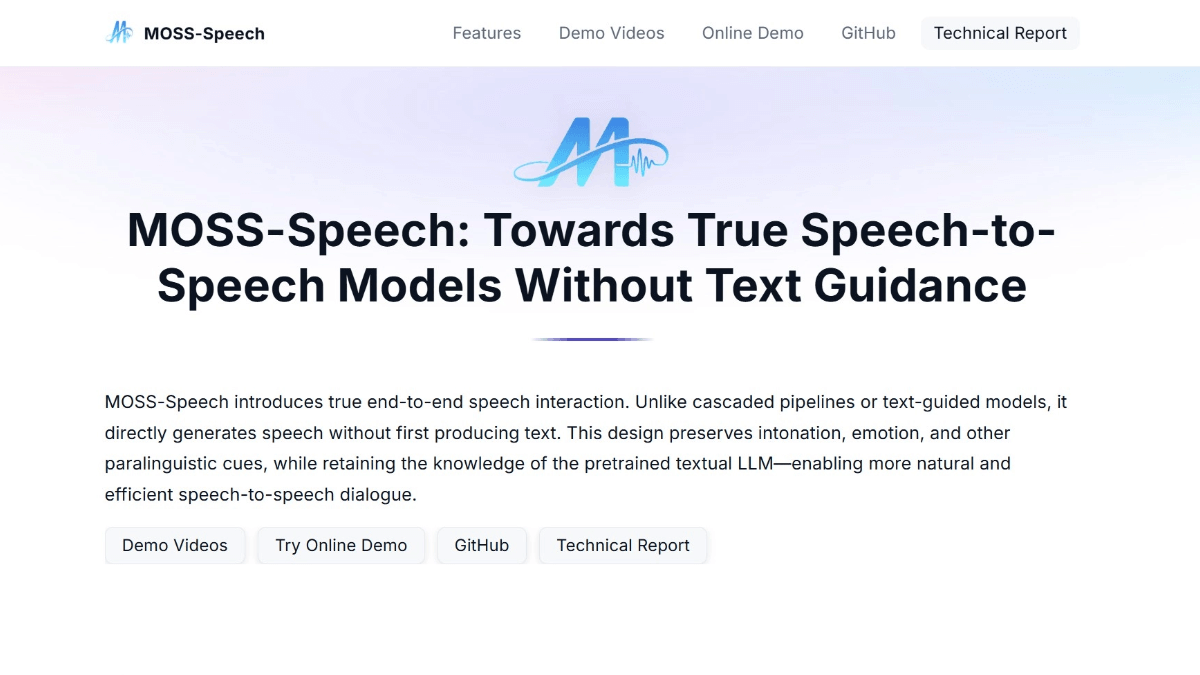
Особенности MOSS-Speechs
- Прямое взаимодействие голоса и речи: Не требует преобразования текста, напрямую обрабатывает голосовой ввод и генерирует голосовой вывод, поддерживая естественный и плавный голосовой диалог.
- Понимание и генерирование речи: Способность понимать семантику, интонацию и эмоции в речи и создавать речь с эмоциями и интонацией делает общение более ярким и естественным.
- кросс-модальное взаимодействиеОн поддерживает двустороннее взаимодействие между голосом и текстом, пользователи могут выбрать голосовой или текстовый ввод, а модель будет выводить данные в соответствующем режиме, чтобы удовлетворить потребности различных сценариев.
- многосценарное приложение: Применяется в интеллектуальных голосовых помощниках, устройствах голосового взаимодействия и т.д., чтобы обеспечить пользователям эффективное и естественное голосовое взаимодействие и повысить интерактивную производительность устройства.
- Мощные возможности моделирования речи: Отличные результаты при моделировании речи и выполнении заданий разговорного теста, способность обрабатывать сложную речевую информацию, обеспечивать точное понимание речи и выдавать результаты.
Основные преимущества MOSS-Speechs
- Истинное моделирование преобразования речи в речь: Обработка речевого ввода и вывода напрямую, без преобразования текста, сохраняя естественные характеристики и эмоциональную выразительность речи.
- Бимодальная поддержка родныхОн поддерживает голосовое и текстовое взаимодействие, и пользователи могут выбирать методы ввода и вывода в соответствии со своими потребностями, обеспечивая гибкую кросс-модальную коммуникацию.
- Передовая технология кодирования речи: Специальная система кодирования используется для понимания смысла речи с сохранением ее акустических характеристик, что повышает точность и естественность голосового взаимодействия.
- Замораживание предтренировочных стратегий: Сохраняя мощные возможности рассуждений и запасы знаний, присущие текстовым LLM, мы ввели возможности понимания и генерации речи для эффективной передачи знаний и слияния модальностей.
- Отличная производительность: продемонстрировал свои возможности в области понимания и генерации речи, достигнув ведущих результатов в задачах моделирования речи и разговорных викторин.
- Богатые сценарии примененияОн подходит для интеллектуальных голосовых помощников, устройств голосового взаимодействия и т.д., обеспечивая пользователям более естественный и эффективный опыт голосового взаимодействия и удовлетворяя разнообразные практические требования.
Что представляет собой официальный сайт MOSS-Speechs?
- Веб-сайт проекта:: https://moss-speech.open-moss.com/
- Репозиторий Github:: https://github.com/OpenMOSS/MOSS-Speech
- Библиотека моделей HuggingFace:: https://huggingface.co/collections/OpenMOSS-Team/moss-speech
- Технический документ arXiv:: https://arxiv.org/pdf/2510.00499
- Демонстрация опыта работы в режиме онлайн:: https://huggingface.co/spaces/OpenMOSS-Team/MOSS-Speech
Люди, для которых предназначены MOSS-Speechs
- производитель интеллектуальных устройствMOSS-Speech можно интегрировать в "умные" колонки, "умные" автомобильные системы и другие устройства, чтобы расширить возможности голосового взаимодействия с продуктом.
- разработчик программного обеспечения: Возможность разрабатывать приложения для голосового взаимодействия, такие как голосовые помощники, голосовое обслуживание клиентов и т. д., используя их API или открытый исходный код.
- исследователь искусственного интеллекта: Может быть использован для изучения передовых технологий в области распознавания речи, синтеза речи и мультимодального взаимодействия.
- Корпоративные клиенты: Подходит для предприятий, нуждающихся в эффективных решениях для голосового взаимодействия, таких как центры обслуживания клиентов, "умные дома" и другие сферы.
- постоянный пользователь: Вы можете напрямую использовать голосовые помощники или устройства, разработанные на основе MOSS-Speech, чтобы пользоваться более естественными и удобными услугами голосового взаимодействия.
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи


Нет комментариев...