MiDashengLM - модель понимания звука от Xiaomi с открытым исходным кодом

Что такое MiDashengLM
MiDashengLM - это крупная модель Xiaomi с открытым исходным кодом для эффективного понимания звука, с особыми параметрами версии MiDashengLM-7B, ориентированная на обработку и понимание звука. Модель построена на основе аудиокодера Xiaomi Dasheng и декодера Qwen2.5-Omni-7B Thinker, что позволяет объединить понимание речи, окружающего звука и музыки. Модель обладает превосходной эффективностью вывода и является первой Токен Учебные данные MiDashengLM полностью открыты, поддерживают как академическое, так и коммерческое использование и обеспечивают мощную поддержку для улучшения опыта мультимодального взаимодействия.
Ключевые особенности MiDashengLM
- Преобразование аудиоконтента в текст: Модель переводит различные виды аудио, такие как голоса, звуки природы или музыку, в текстовые описания, которые помогают людям быстро понять, что на самом деле происходит в аудио.
- Определите категории аудиозаписей: Модель может определить, является ли фрагмент аудио речью, окружающим звуком, музыкой и т. д., как и маркировать аудио, чтобы его было легче использовать в различных сценариях.
- распознавание речи: Преобразует сказанное человеком в текст, поддерживает несколько языков и особенно подходит для использования в голосовых помощниках или смарт-устройствах.
- Аудио вопросы и ответы: Отвечает на вопросы, основанные на аудиоконтенте, например, спрашивает "Что это был за звук?" в машине, и модель отвечает.
- мультимодальное взаимодействие: Способность понимать аудио и другую информацию (например, текст, изображения) в сочетании друг с другом, что позволяет более разумно и естественно взаимодействовать с устройствами.
Адрес официального сайта MiDashengLM
- Репозиторий GitHub:: https://github.com/xiaomi-research/dasheng-lm
- Библиотека моделей HuggingFace:: https://huggingface.co/mispeech/midashenglm-7b
- Технические документы:: https://github.com/xiaomi-research/dasheng-lm/blob/main/technical_report/MiDashengLM_techreport.pdf
- Демонстрация опыта работы в режиме онлайн:: https://huggingface.co/spaces/mispeech/MiDashengLM-7B
Как использовать MiDashengLM
- Опыт работы в ИнтернетеПосетите демонстрацию онлайн-опыта MiDashengLM.
- Загрузка аудиофайлов: Загрузите аудиофайл (поддерживаемые форматы: WAV, MP3 и т. д.).
- Ожидание обработки: После загрузки аудиозаписи модель автоматически обрабатывает ее и генерирует результаты.
- Посмотреть результаты: После завершения обработки просмотрите результаты описания или классификации, созданные моделью.
Основные преимущества компании MiDashengLM
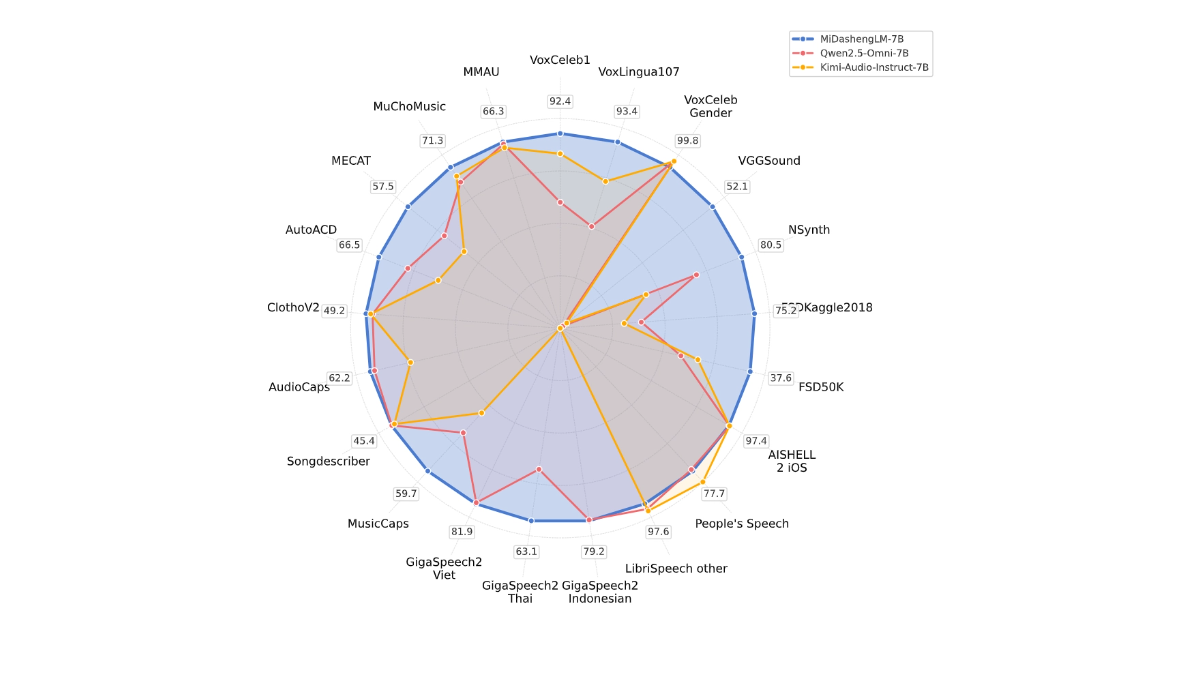
- Эффективная работа с выводамиЭффективность вычислений MiDashengLM чрезвычайно высока, задержка первого маркера очень мала, а пропускная способность значительно повышена, что делает его пригодным для сценариев взаимодействия в реальном времени.
- Мощное восприятие звука: позволяет единообразно понимать широкий спектр аудио, включая речь, окружающий звук и музыку, избегая ограничений традиционных методов.
- Данные и модели с открытым исходным кодомУчебные данные и модели полностью открыты, что облегчает исследования и вторичное развитие разработчиков и поддерживает как академическое, так и коммерческое использование.
- Широкий спектр сценариев применения: Применяется в различных областях, таких как "умная кабина", "умный дом", голосовой помощник, создание аудиоконтента, образование и обучение.
- Оптимизация технологий: Основанный на оптимизированной конструкции аудиокодера и декодера, MiDashengLM справляется со сложными аудиозадачами, снижая при этом вычислительную нагрузку.
- Стратегии обучения: Стратегия обучения, основанная на выравнивании общих аудиоописаний и многоэкспертном анализе, гарантирует, что модель усвоит глубокие семантические ассоциации аудио и улучшит обобщение.
Люди, для которых предназначен МиДашэнЛМ
- Исследователи искусственного интеллекта: Модель предоставляет исследователям модели понимания звука с открытым исходным кодом и учебные данные для содействия исследованиям и инновациям в смежных областях.
- Разработчики интеллектуальных устройств: Для команд, разрабатывающих такие продукты, как "умные" кабины, "умные" дома, голосовые помощники и т. д., модель быстро интегрируется в продукт, чтобы улучшить опыт взаимодействия.
- Создатели аудиоконтента: Создатели аудиоматериалов используют модели для автоматического создания аудиоописаний и этикеток, чтобы повысить эффективность создания контента.
- Преподаватели и учащиеся: в области изучения языка и музыкального образования, помогая обратной связью по произношению и теоретическими рекомендациями, чтобы помочь учащимся лучше усвоить знания.
- бизнес-пользователь: Эффективное решение для предприятий, которым необходима функциональность понимания звука, поддерживающая коммерческое использование и позволяющая разрабатывать продукты и оптимизировать услуги.
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи


Нет комментариев...